 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffFacto: Controllable Part-Based 3D Point Cloud Generation with Cross Diffusion
May 04, 2023



While the community of 3D point cloud generation has witnessed a big growth in recent years, there still lacks an effective way to enable intuitive user control in the generation process, hence limiting the general utility of such methods. Since an intuitive way of decomposing a shape is through its parts, we propose to tackle the task of controllable part-based point cloud generation. We introduce DiffFacto, a novel probabilistic generative model that learns the distribution of shapes with part-level control. We propose a factorization that models independent part style and part configuration distributions and presents a novel cross-diffusion network that enables us to generate coherent and plausible shapes under our proposed factorization. Experiments show that our method is able to generate novel shapes with multiple axes of control. It achieves state-of-the-art part-level generation quality and generates plausible and coherent shapes while enabling various downstream editing applications such as shape interpolation, mixing, and transformation editing. Project website: https://difffacto.github.io/
Long Range Pooling for 3D Large-Scale Scene Understanding
Jan 17, 2023Inspired by the success of recent vision transformers and large kernel design in convolutional neural networks (CNNs), in this paper, we analyze and explore essential reasons for their success. We claim two factors that are critical for 3D large-scale scene understanding: a larger receptive field and operations with greater non-linearity. The former is responsible for providing long range contexts and the latter can enhance the capacity of the network. To achieve the above properties, we propose a simple yet effective long range pooling (LRP) module using dilation max pooling, which provides a network with a large adaptive receptive field. LRP has few parameters, and can be readily added to current CNNs. Also, based on LRP, we present an entire network architecture, LRPNet, for 3D understanding. Ablation studies are presented to support our claims, and show that the LRP module achieves better results than large kernel convolution yet with reduced computation, due to its nonlinearity. We also demonstrate the superiority of LRPNet on various benchmarks: LRPNet performs the best on ScanNet and surpasses other CNN-based methods on S3DIS and Matterport3D. Code will be made publicly available.
SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
Sep 18, 2022
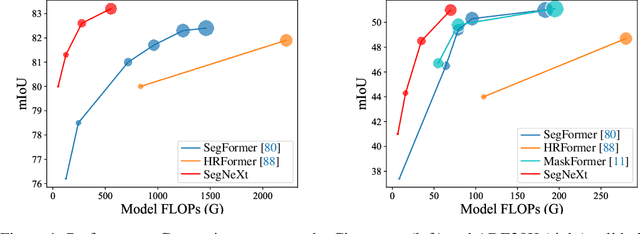
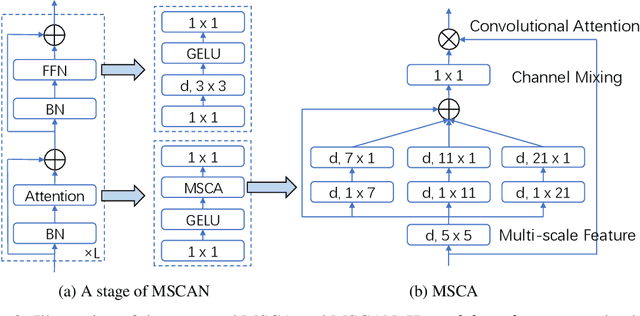
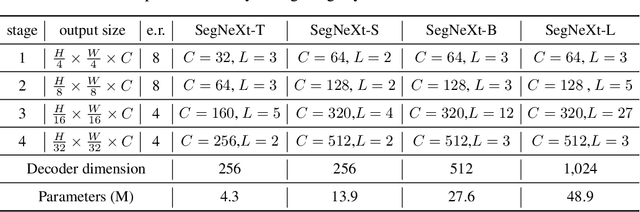
We present SegNeXt, a simple convolutional network architecture for semantic segmentation. Recent transformer-based models have dominated the field of semantic segmentation due to the efficiency of self-attention in encoding spatial information. In this paper, we show that convolutional attention is a more efficient and effective way to encode contextual information than the self-attention mechanism in transformers. By re-examining the characteristics owned by successful segmentation models, we discover several key components leading to the performance improvement of segmentation models. This motivates us to design a novel convolutional attention network that uses cheap convolutional operations. Without bells and whistles, our SegNeXt significantly improves the performance of previous state-of-the-art methods on popular benchmarks, including ADE20K, Cityscapes, COCO-Stuff, Pascal VOC, Pascal Context, and iSAID. Notably, SegNeXt outperforms EfficientNet-L2 w/ NAS-FPN and achieves 90.6% mIoU on the Pascal VOC 2012 test leaderboard using only 1/10 parameters of it. On average, SegNeXt achieves about 2.0% mIoU improvements compared to the state-of-the-art methods on the ADE20K datasets with the same or fewer computations. Code is available at https://github.com/uyzhang/JSeg (Jittor) and https://github.com/Visual-Attention-Network/SegNeXt (Pytorch).
DeepPortraitDrawing: Generating Human Body Images from Freehand Sketches
May 04, 2022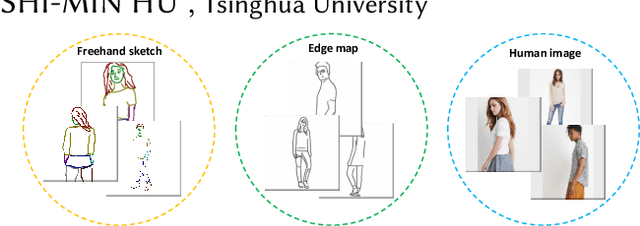
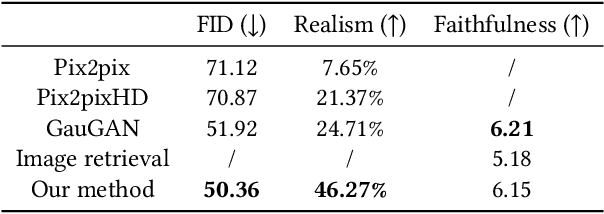
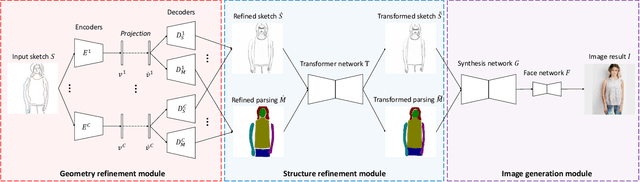
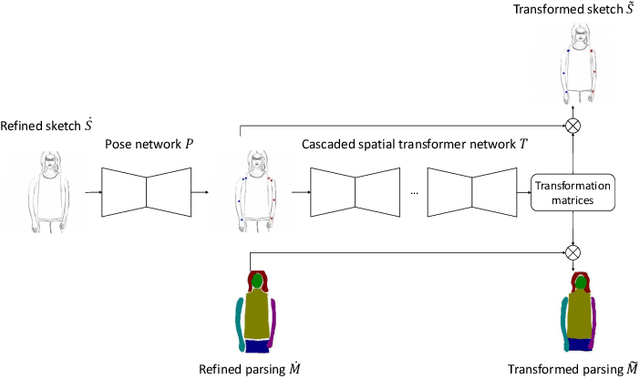
Researchers have explored various ways to generate realistic images from freehand sketches, e.g., for objects and human faces. However, how to generate realistic human body images from sketches is still a challenging problem. It is, first because of the sensitivity to human shapes, second because of the complexity of human images caused by body shape and pose changes, and third because of the domain gap between realistic images and freehand sketches. In this work, we present DeepPortraitDrawing, a deep generative framework for converting roughly drawn sketches to realistic human body images. To encode complicated body shapes under various poses, we take a local-to-global approach. Locally, we employ semantic part auto-encoders to construct part-level shape spaces, which are useful for refining the geometry of an input pre-segmented hand-drawn sketch. Globally, we employ a cascaded spatial transformer network to refine the structure of body parts by adjusting their spatial locations and relative proportions. Finally, we use a global synthesis network for the sketch-to-image translation task, and a face refinement network to enhance facial details. Extensive experiments have shown that given roughly sketched human portraits, our method produces more realistic images than the state-of-the-art sketch-to-image synthesis techniques.
Visual Attention Network
Mar 08, 2022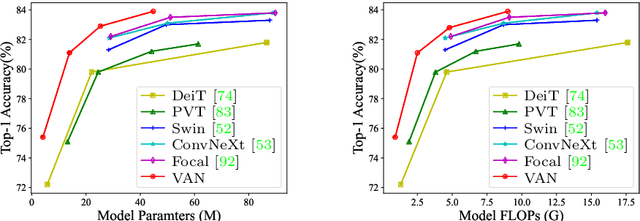

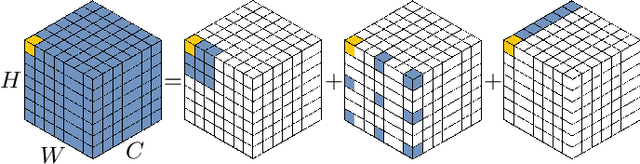

While originally designed for natural language processing tasks, the self-attention mechanism has recently taken various computer vision areas by storm. However, the 2D nature of images brings three challenges for applying self-attention in computer vision. (1) Treating images as 1D sequences neglects their 2D structures. (2) The quadratic complexity is too expensive for high-resolution images. (3) It only captures spatial adaptability but ignores channel adaptability. In this paper, we propose a novel large kernel attention (LKA) module to enable self-adaptive and long-range correlations in self-attention while avoiding the above issues. We further introduce a novel neural network based on LKA, namely Visual Attention Network (VAN). While extremely simple, VAN outperforms the state-of-the-art vision transformers and convolutional neural networks with a large margin in extensive experiments, including image classification, object detection, semantic segmentation, instance segmentation, etc. Code is available at https://github.com/Visual-Attention-Network.
NeRF-SR: High-Quality Neural Radiance Fields using Super-Sampling
Dec 03, 2021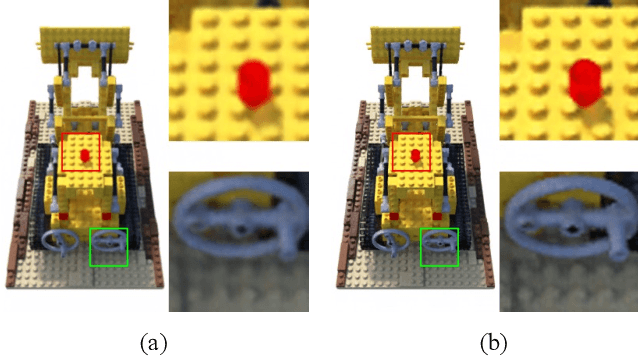

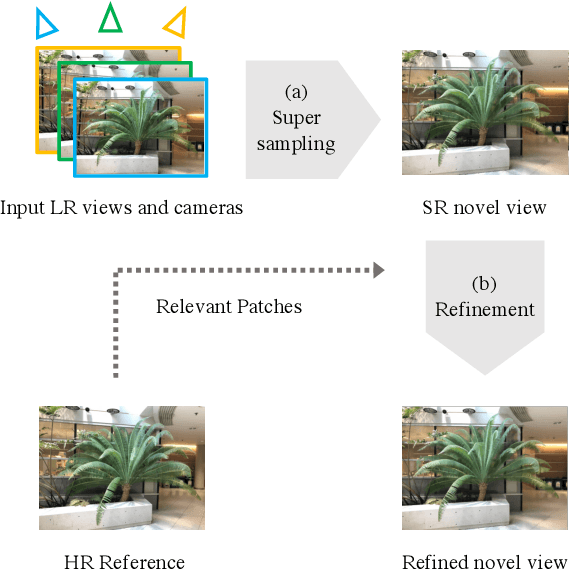
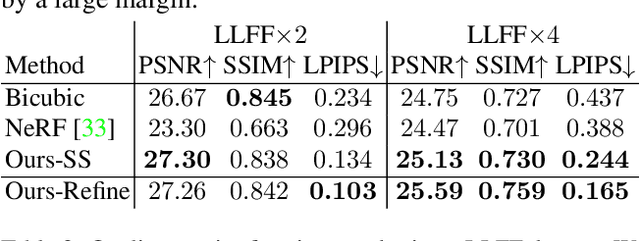
We present NeRF-SR, a solution for high-resolution (HR) novel view synthesis with mostly low-resolution (LR) inputs. Our method is built upon Neural Radiance Fields (NeRF) that predicts per-point density and color with a multi-layer perceptron. While producing images at arbitrary scales, NeRF struggles with resolutions that go beyond observed images. Our key insight is that NeRF has a local prior, which means predictions of a 3D point can be propagated in the nearby region and remain accurate. We first exploit it by a super-sampling strategy that shoots multiple rays at each image pixel, which enforces multi-view constraint at a sub-pixel level. Then, we show that NeRF-SR can further boost the performance of super-sampling by a refinement network that leverages the estimated depth at hand to hallucinate details from related patches on an HR reference image. Experiment results demonstrate that NeRF-SR generates high-quality results for novel view synthesis at HR on both synthetic and real-world datasets.
CIRCLE: Convolutional Implicit Reconstruction and Completion for Large-scale Indoor Scene
Nov 25, 2021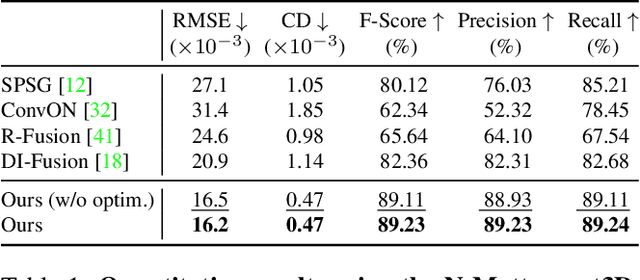
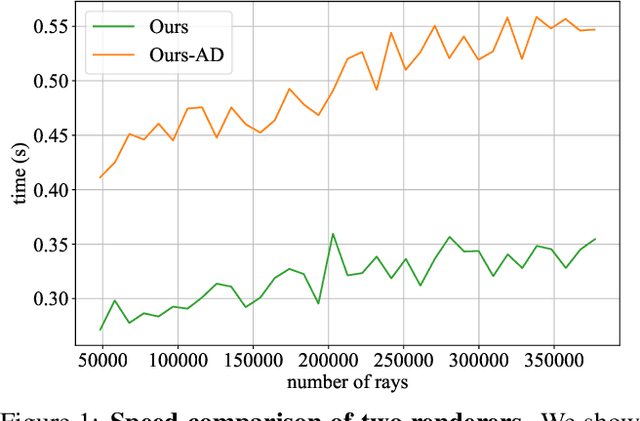
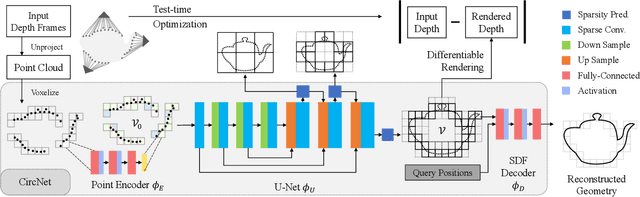
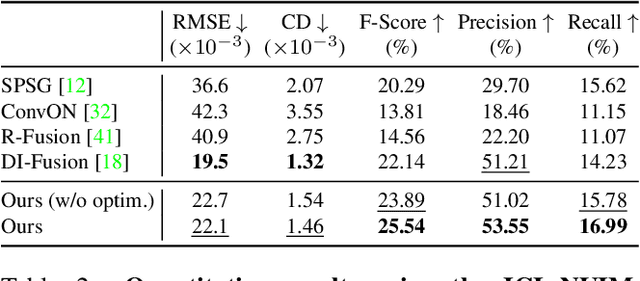
We present CIRCLE, a framework for large-scale scene completion and geometric refinement based on local implicit signed distance functions. It is based on an end-to-end sparse convolutional network, CircNet, that jointly models local geometric details and global scene structural contexts, allowing it to preserve fine-grained object detail while recovering missing regions commonly arising in traditional 3D scene data. A novel differentiable rendering module enables test-time refinement for better reconstruction quality. Extensive experiments on both real-world and synthetic datasets show that our concise framework is efficient and effective, achieving better reconstruction quality than the closest competitor while being 10-50x faster.
Multiway Non-rigid Point Cloud Registration via Learned Functional Map Synchronization
Nov 25, 2021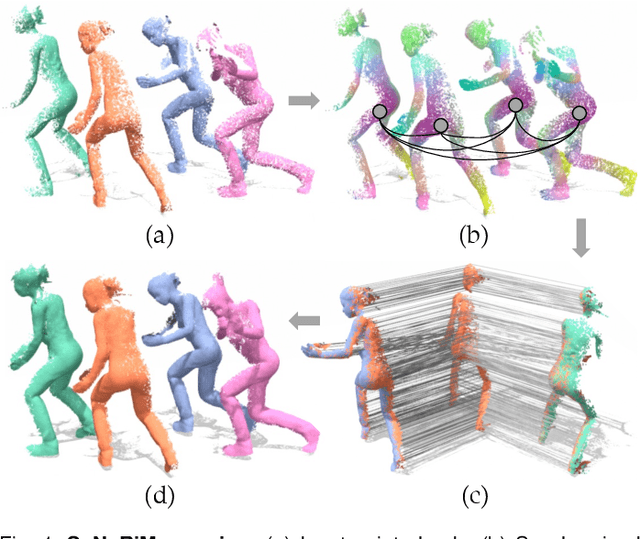
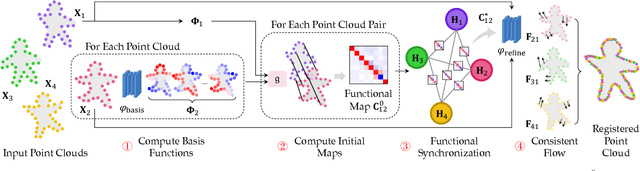
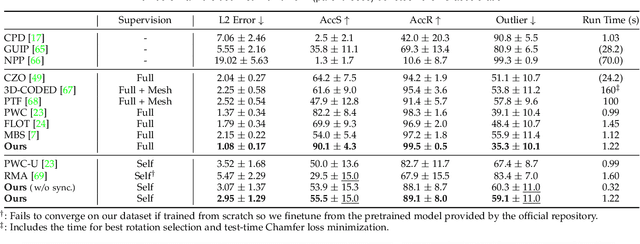
We present SyNoRiM, a novel way to jointly register multiple non-rigid shapes by synchronizing the maps relating learned functions defined on the point clouds. Even though the ability to process non-rigid shapes is critical in various applications ranging from computer animation to 3D digitization, the literature still lacks a robust and flexible framework to match and align a collection of real, noisy scans observed under occlusions. Given a set of such point clouds, our method first computes the pairwise correspondences parameterized via functional maps. We simultaneously learn potentially non-orthogonal basis functions to effectively regularize the deformations, while handling the occlusions in an elegant way. To maximally benefit from the multi-way information provided by the inferred pairwise deformation fields, we synchronize the pairwise functional maps into a cycle-consistent whole thanks to our novel and principled optimization formulation. We demonstrate via extensive experiments that our method achieves a state-of-the-art performance in registration accuracy, while being flexible and efficient as we handle both non-rigid and multi-body cases in a unified framework and avoid the costly optimization over point-wise permutations by the use of basis function maps.
Are we ready for a new paradigm shift? A Survey on Visual Deep MLP
Nov 23, 2021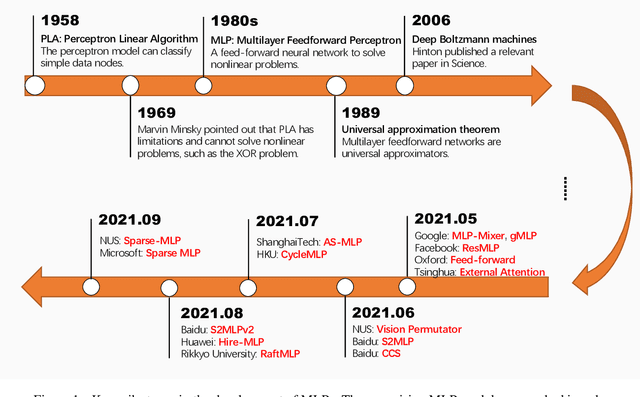

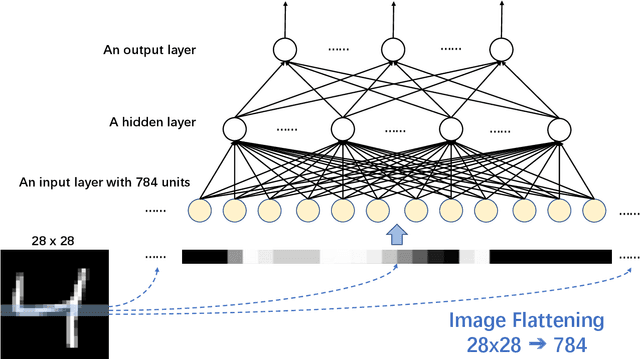
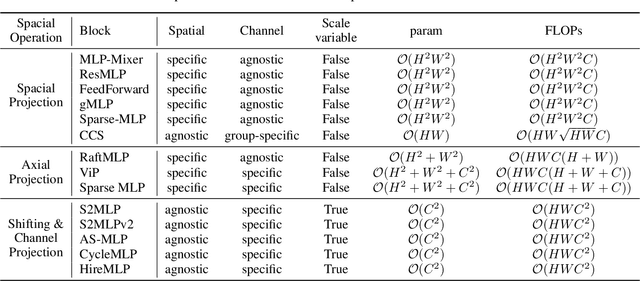
Multilayer perceptron (MLP), as the first neural network structure to appear, was a big hit. But constrained by the hardware computing power and the size of the datasets, it once sank for tens of years. During this period, we have witnessed a paradigm shift from manual feature extraction to the CNN with local receptive field, and further to the Transformer with global receptive field based on self-attention mechanism. And this year (2021), with the introduction of MLP-Mixer, MLP has re-entered the limelight and has attracted extensive research from the computer vision community. Compare to the conventional MLP, it gets deeper but changes the input from full flattening to patch flattening. Given its high performance and less need for vision-specific inductive bias, the community can't help but wonder, \emph{Will deep MLP, the simplest structure with global receptive field but no attention, become a new computer vision paradigm}? To answer this question, this survey aims to provide a comprehensive overview of the recent development of deep MLP models in vision. Specifically, we review these MLPs in detail, from the subtle sub-module design to the global network structure. We compare the receptive field, computational complexity, and other properties of different network designs in order to understand the development path of MLPs clearly. The investigation shows that MLPs' resolution-sensitivity and computational densities remain unresolved, and pure MLPs are gradually evolving towards CNN-like. We suggest that the current data volume and computational power are not ready to embrace pure MLPs, and artificial visual guidance remains important. Finally, we provide our viewpoint about open research directions and potential future works. We hope this effort will ignite further interest in the community and encourage better visual tailored design for the neural network in the future.
Attention Mechanisms in Computer Vision: A Survey
Nov 15, 2021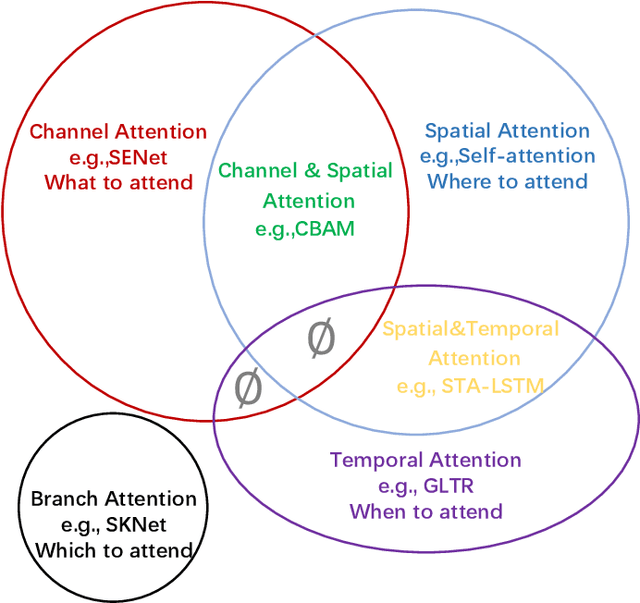

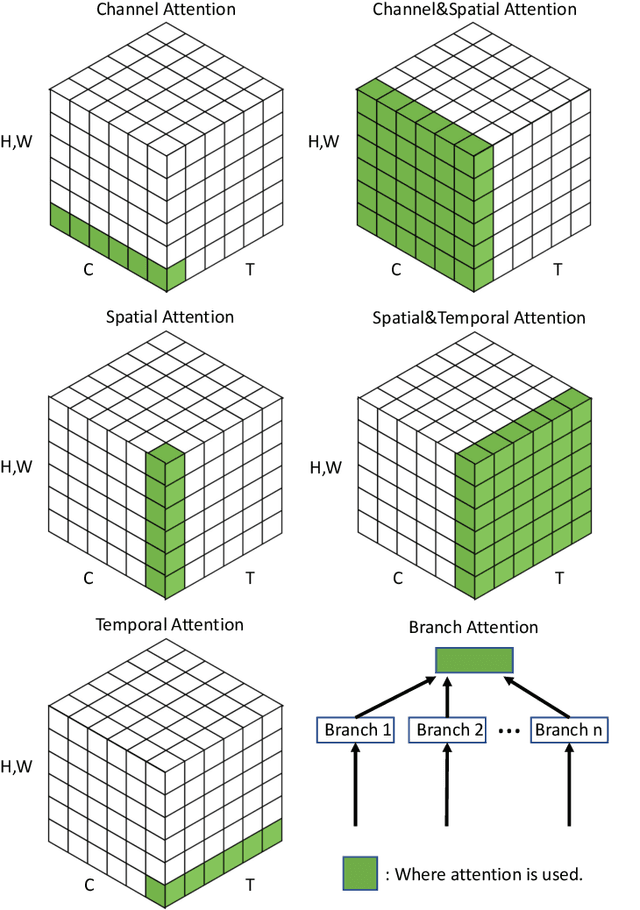
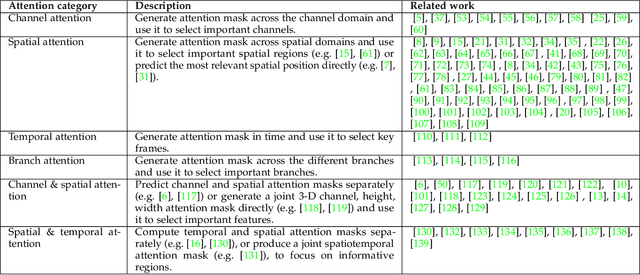
Humans can naturally and effectively find salient regions in complex scenes. Motivated by this observation, attention mechanisms were introduced into computer vision with the aim of imitating this aspect of the human visual system. Such an attention mechanism can be regarded as a dynamic weight adjustment process based on features of the input image. Attention mechanisms have achieved great success in many visual tasks, including image classification, object detection, semantic segmentation, video understanding, image generation, 3D vision, multi-modal tasks and self-supervised learning. In this survey, we provide a comprehensive review of various attention mechanisms in computer vision and categorize them according to approach, such as channel attention, spatial attention, temporal attention and branch attention; a related repository https://github.com/MenghaoGuo/Awesome-Vision-Attentions is dedicated to collecting related work. We also suggest future directions for attention mechanism research.