 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Diffusion Feature Refinement for Continuous Sign Language Recognition
May 05, 2023



In this work, we are dedicated to leveraging the denoising diffusion models' success and formulating feature refinement as the autoencoder-formed diffusion process. The state-of-the-art CSLR framework consists of a spatial module, a visual module, a sequence module, and a sequence learning function. However, this framework has faced sequence module overfitting caused by the objective function and small-scale available benchmarks, resulting in insufficient model training. To overcome the overfitting problem, some CSLR studies enforce the sequence module to learn more visual temporal information or be guided by more informative supervision to refine its representations. In this work, we propose a novel autoencoder-formed conditional diffusion feature refinement~(ACDR) to refine the sequence representations to equip desired properties by learning the encoding-decoding optimization process in an end-to-end way. Specifically, for the ACDR, a noising Encoder is proposed to progressively add noise equipped with semantic conditions to the sequence representations. And a denoising Decoder is proposed to progressively denoise the noisy sequence representations with semantic conditions. Therefore, the sequence representations can be imbued with the semantics of provided semantic conditions. Further, a semantic constraint is employed to prevent the denoised sequence representations from semantic corruption. Extensive experiments are conducted to validate the effectiveness of our ACDR, benefiting state-of-the-art methods and achieving a notable gain on three benchmarks.
High-order Spatial Interactions Enhanced Lightweight Model for Optical Remote Sensing Image-based Small Ship Detection
Apr 07, 2023



Accurate and reliable optical remote sensing image-based small-ship detection is crucial for maritime surveillance systems, but existing methods often struggle with balancing detection performance and computational complexity. In this paper, we propose a novel lightweight framework called \textit{HSI-ShipDetectionNet} that is based on high-order spatial interactions and is suitable for deployment on resource-limited platforms, such as satellites and unmanned aerial vehicles. HSI-ShipDetectionNet includes a prediction branch specifically for tiny ships and a lightweight hybrid attention block for reduced complexity. Additionally, the use of a high-order spatial interactions module improves advanced feature understanding and modeling ability. Our model is evaluated using the public Kaggle marine ship detection dataset and compared with multiple state-of-the-art models including small object detection models, lightweight detection models, and ship detection models. The results show that HSI-ShipDetectionNet outperforms the other models in terms of recall, and mean average precision (mAP) while being lightweight and suitable for deployment on resource-limited platforms.
DARTSRepair: Core-failure-set Guided DARTS for Network Robustness to Common Corruptions
Sep 21, 2022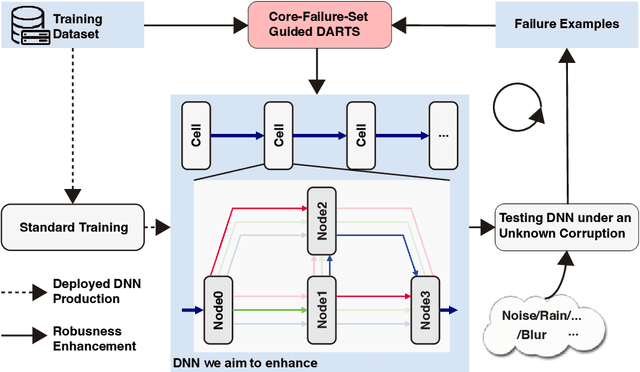

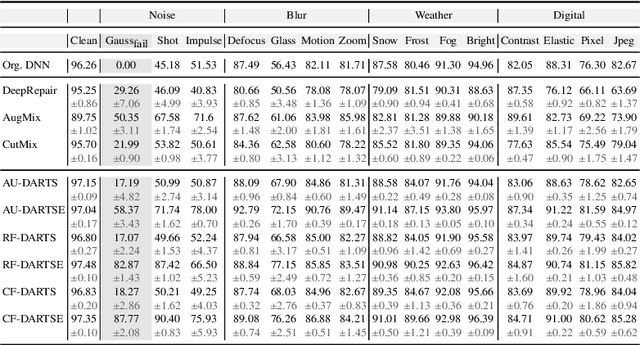
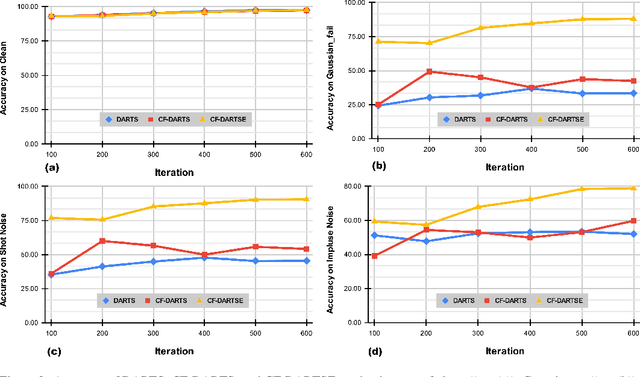
Network architecture search (NAS), in particular the differentiable architecture search (DARTS) method, has shown a great power to learn excellent model architectures on the specific dataset of interest. In contrast to using a fixed dataset, in this work, we focus on a different but important scenario for NAS: how to refine a deployed network's model architecture to enhance its robustness with the guidance of a few collected and misclassified examples that are degraded by some real-world unknown corruptions having a specific pattern (e.g., noise, blur, etc.). To this end, we first conduct an empirical study to validate that the model architectures can be definitely related to the corruption patterns. Surprisingly, by just adding a few corrupted and misclassified examples (e.g., $10^3$ examples) to the clean training dataset (e.g., $5.0 \times 10^4$ examples), we can refine the model architecture and enhance the robustness significantly. To make it more practical, the key problem, i.e., how to select the proper failure examples for the effective NAS guidance, should be carefully investigated. Then, we propose a novel core-failure-set guided DARTS that embeds a K-center-greedy algorithm for DARTS to select suitable corrupted failure examples to refine the model architecture. We use our method for DARTS-refined DNNs on the clean as well as 15 corruptions with the guidance of four specific real-world corruptions. Compared with the state-of-the-art NAS as well as data-augmentation-based enhancement methods, our final method can achieve higher accuracy on both corrupted datasets and the original clean dataset. On some of the corruption patterns, we can achieve as high as over 45% absolute accuracy improvements.
Semantic Visual Simultaneous Localization and Mapping: A Survey
Sep 14, 2022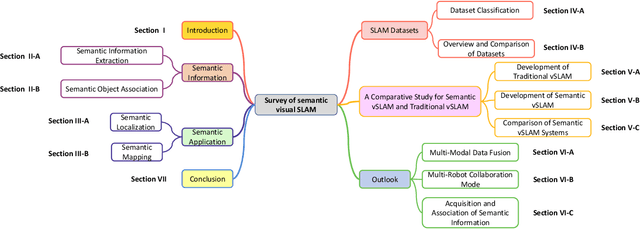
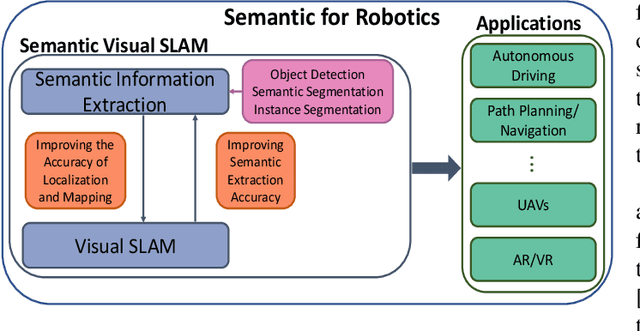

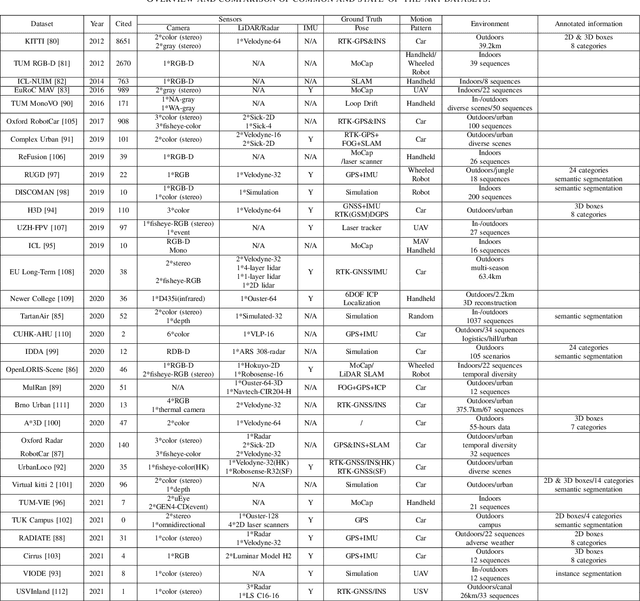
Visual Simultaneous Localization and Mapping (vSLAM) has achieved great progress in the computer vision and robotics communities, and has been successfully used in many fields such as autonomous robot navigation and AR/VR. However, vSLAM cannot achieve good localization in dynamic and complex environments. Numerous publications have reported that, by combining with the semantic information with vSLAM, the semantic vSLAM systems have the capability of solving the above problems in recent years. Nevertheless, there is no comprehensive survey about semantic vSLAM. To fill the gap, this paper first reviews the development of semantic vSLAM, explicitly focusing on its strengths and differences. Secondly, we explore three main issues of semantic vSLAM: the extraction and association of semantic information, the application of semantic information, and the advantages of semantic vSLAM. Then, we collect and analyze the current state-of-the-art SLAM datasets which have been widely used in semantic vSLAM systems. Finally, we discuss future directions that will provide a blueprint for the future development of semantic vSLAM.
Asymmetric Dual-Decoder U-Net for Joint Rain and Haze Removal
Jun 21, 2022


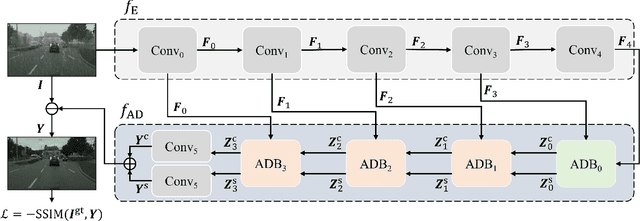
This work studies the joint rain and haze removal problem. In real-life scenarios, rain and haze, two often co-occurring common weather phenomena, can greatly degrade the clarity and quality of the scene images, leading to a performance drop in the visual applications, such as autonomous driving. However, jointly removing the rain and haze in scene images is ill-posed and challenging, where the existence of haze and rain and the change of atmosphere light, can both degrade the scene information. Current methods focus on the contamination removal part, thus ignoring the restoration of the scene information affected by the change of atmospheric light. We propose a novel deep neural network, named Asymmetric Dual-decoder U-Net (ADU-Net), to address the aforementioned challenge. The ADU-Net produces both the contamination residual and the scene residual to efficiently remove the rain and haze while preserving the fidelity of the scene information. Extensive experiments show our work outperforms the existing state-of-the-art methods by a considerable margin in both synthetic data and real-world data benchmarks, including RainCityscapes, BID Rain, and SPA-Data. For instance, we improve the state-of-the-art PSNR value by 2.26/4.57 on the RainCityscapes/SPA-Data, respectively. Codes will be made available freely to the research community.
Adaptively Customizing Activation Functions for Various Layers
Dec 17, 2021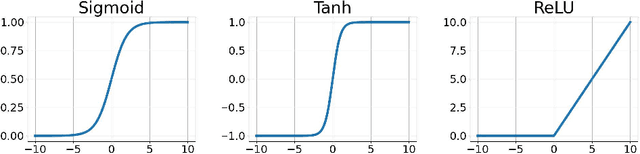



To enhance the nonlinearity of neural networks and increase their mapping abilities between the inputs and response variables, activation functions play a crucial role to model more complex relationships and patterns in the data. In this work, a novel methodology is proposed to adaptively customize activation functions only by adding very few parameters to the traditional activation functions such as Sigmoid, Tanh, and ReLU. To verify the effectiveness of the proposed methodology, some theoretical and experimental analysis on accelerating the convergence and improving the performance is presented, and a series of experiments are conducted based on various network models (such as AlexNet, VGGNet, GoogLeNet, ResNet and DenseNet), and various datasets (such as CIFAR10, CIFAR100, miniImageNet, PASCAL VOC and COCO) . To further verify the validity and suitability in various optimization strategies and usage scenarios, some comparison experiments are also implemented among different optimization strategies (such as SGD, Momentum, AdaGrad, AdaDelta and ADAM) and different recognition tasks like classification and detection. The results show that the proposed methodology is very simple but with significant performance in convergence speed, precision and generalization, and it can surpass other popular methods like ReLU and adaptive functions like Swish in almost all experiments in terms of overall performance.The code is publicly available at https://github.com/HuHaigen/Adaptively-Customizing-Activation-Functions. The package includes the proposed three adaptive activation functions for reproducibility purposes.
A Novel Patch Convolutional Neural Network for View-based 3D Model Retrieval
Sep 25, 2021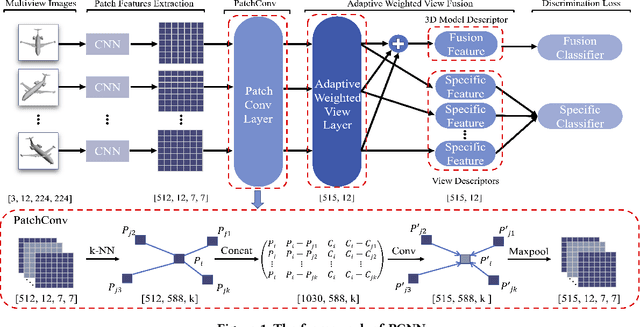
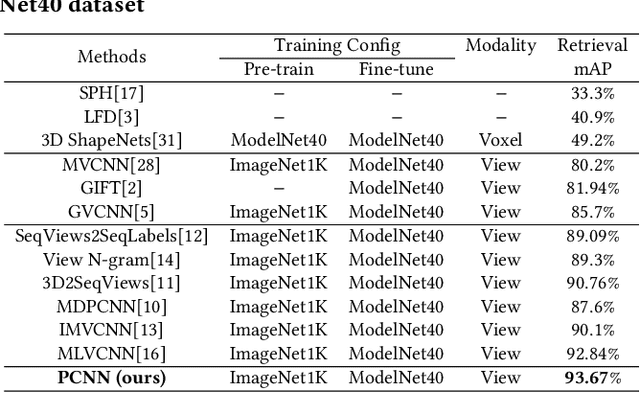
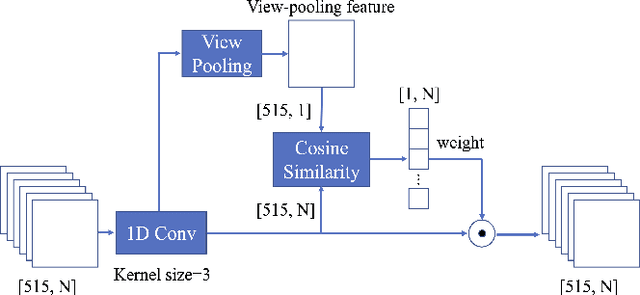
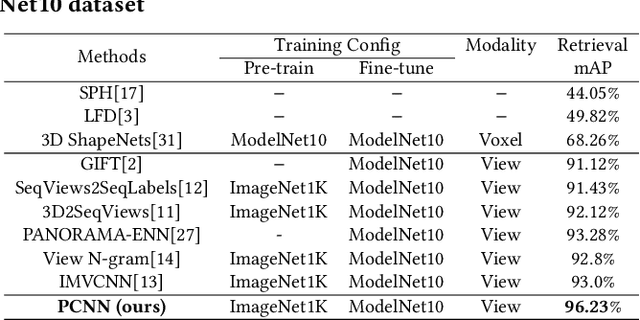
Recently, many view-based 3D model retrieval methods have been proposed and have achieved state-of-the-art performance. Most of these methods focus on extracting more discriminative view-level features and effectively aggregating the multi-view images of a 3D model, but the latent relationship among these multi-view images is not fully explored. Thus, we tackle this problem from the perspective of exploiting the relationships between patch features to capture long-range associations among multi-view images. To capture associations among views, in this work, we propose a novel patch convolutional neural network (PCNN) for view-based 3D model retrieval. Specifically, we first employ a CNN to extract patch features of each view image separately. Secondly, a novel neural network module named PatchConv is designed to exploit intrinsic relationships between neighboring patches in the feature space to capture long-range associations among multi-view images. Then, an adaptive weighted view layer is further embedded into PCNN to automatically assign a weight to each view according to the similarity between each view feature and the view-pooling feature. Finally, a discrimination loss function is employed to extract the discriminative 3D model feature, which consists of softmax loss values generated by the fusion lassifier and the specific classifier. Extensive experimental results on two public 3D model retrieval benchmarks, namely, the ModelNet40, and ModelNet10, demonstrate that our proposed PCNN can outperform state-of-the-art approaches, with mAP alues of 93.67%, and 96.23%, respectively.
Deep High-Resolution Representation Learning for Cross-Resolution Person Re-identification
May 25, 2021
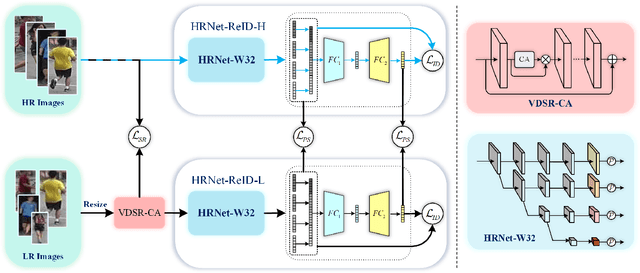
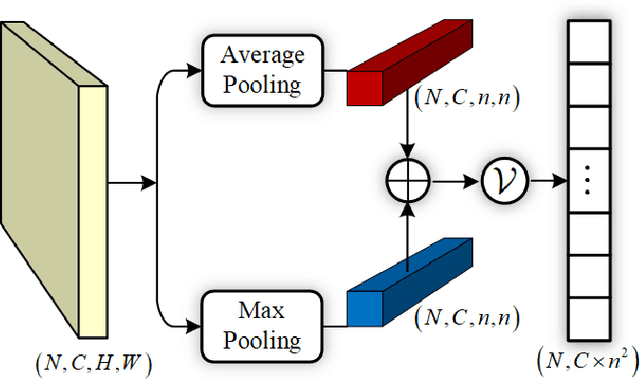
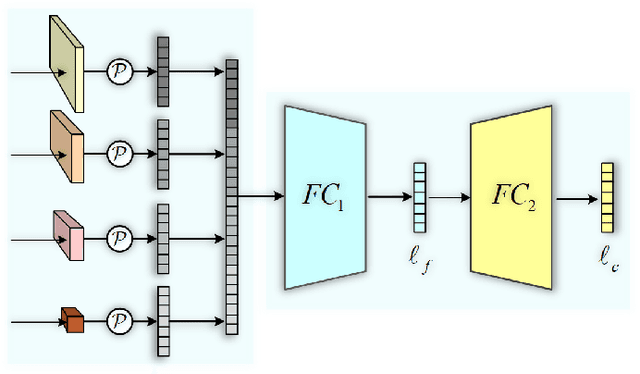
Person re-identification (re-ID) tackles the problem of matching person images with the same identity from different cameras. In practical applications, due to the differences in camera performance and distance between cameras and persons of interest, captured person images usually have various resolutions. We name this problem as Cross-Resolution Person Re-identification which brings a great challenge for matching correctly. In this paper, we propose a Deep High-Resolution Pseudo-Siamese Framework (PS-HRNet) to solve the above problem. Specifically, in order to restore the resolution of low-resolution images and make reasonable use of different channel information of feature maps, we introduce and innovate VDSR module with channel attention (CA) mechanism, named as VDSR-CA. Then we reform the HRNet by designing a novel representation head to extract discriminating features, named as HRNet-ReID. In addition, a pseudo-siamese framework is constructed to reduce the difference of feature distributions between low-resolution images and high-resolution images. The experimental results on five cross-resolution person datasets verify the effectiveness of our proposed approach. Compared with the state-of-the-art methods, our proposed PS-HRNet improves 3.4\%, 6.2\%, 2.5\%,1.1\% and 4.2\% at Rank-1 on MLR-Market-1501, MLR-CUHK03, MLR-VIPeR, MLR-DukeMTMC-reID, and CAVIAR datasets, respectively. Our code is available at \url{https://github.com/zhguoqing}.
Independent Reinforcement Learning for Weakly Cooperative Multiagent Traffic Control Problem
Apr 22, 2021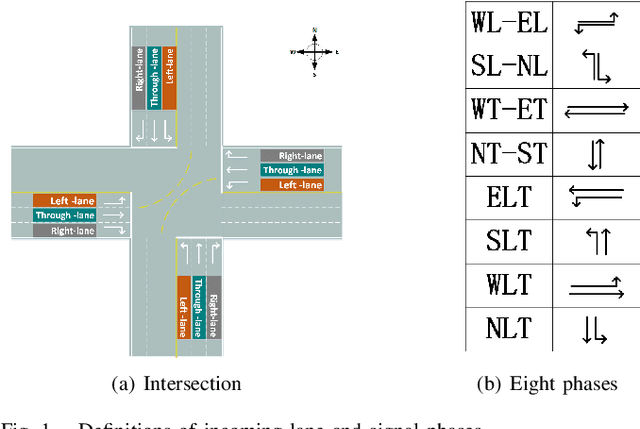
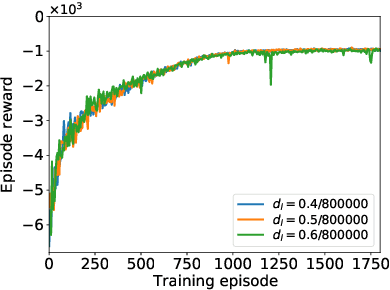

The adaptive traffic signal control (ATSC) problem can be modeled as a multiagent cooperative game among urban intersections, where intersections cooperate to optimize their common goal. Recently, reinforcement learning (RL) has achieved marked successes in managing sequential decision making problems, which motivates us to apply RL in the ASTC problem. Here we use independent reinforcement learning (IRL) to solve a complex traffic cooperative control problem in this study. One of the largest challenges of this problem is that the observation information of intersection is typically partially observable, which limits the learning performance of IRL algorithms. To this, we model the traffic control problem as a partially observable weak cooperative traffic model (PO-WCTM) to optimize the overall traffic situation of a group of intersections. Different from a traditional IRL task that averages the returns of all agents in fully cooperative games, the learning goal of each intersection in PO-WCTM is to reduce the cooperative difficulty of learning, which is also consistent with the traffic environment hypothesis. We also propose an IRL algorithm called Cooperative Important Lenient Double DQN (CIL-DDQN), which extends Double DQN (DDQN) algorithm using two mechanisms: the forgetful experience mechanism and the lenient weight training mechanism. The former mechanism decreases the importance of experiences stored in the experience reply buffer, which deals with the problem of experience failure caused by the strategy change of other agents. The latter mechanism increases the weight experiences with high estimation and `leniently' trains the DDQN neural network, which improves the probability of the selection of cooperative joint strategies. Experimental results show that CIL-DDQN outperforms other methods in almost all performance indicators of the traffic control problem.
LAGNet: Logic-Aware Graph Network for Human Interaction Understanding
Nov 26, 2020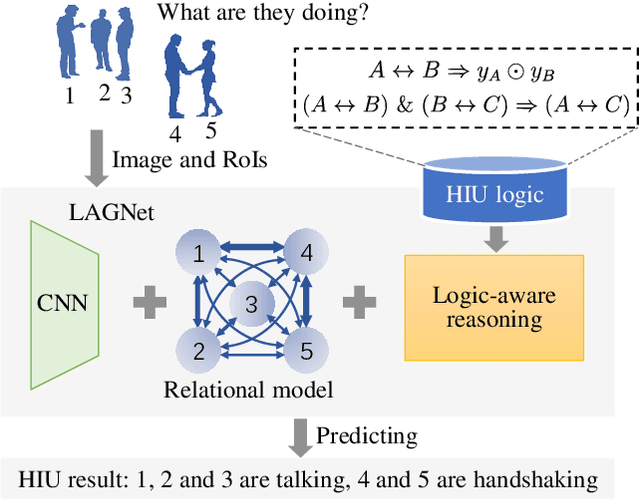
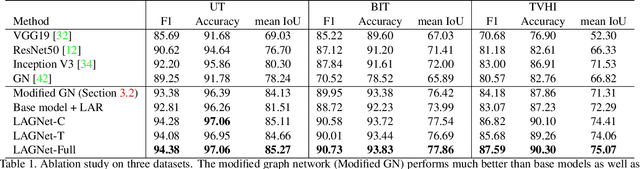
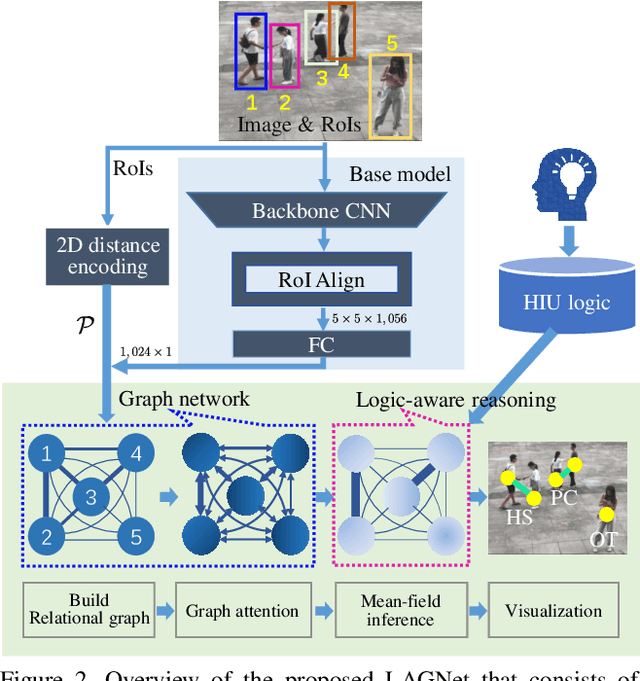

Compared with the progress made on human activity classification, much less success has been achieved on human interaction understanding (HIU). Apart from the latter task is much more challenging, the main cause is that recent approaches learn human interactive relations via shallow graphical representations, which is inadequate to model complicated human interactions. In this paper, we propose a deep logic-aware graph network, which combines the representative ability of graph attention and the rigorousness of logical reasoning to facilitate human interaction understanding. Our network consists of three components, a backbone CNN to extract image features, a graph network to learn interactive relations among participants, and a logic-aware reasoning module. Our key observation is that the first-order logic for HIU can be embedded into higher-order energy functions, minimizing which delivers logic-aware predictions. An efficient mean-field inference algorithm is proposed, such that all modules of our network could be trained jointly in an end-to-end way. Experimental results show that our approach achieves leading performance on three existing benchmarks and a new challenging dataset crafted by ourselves. Code is available at: https://git.io/LAGNet.