 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegFlow: Joint Learning for Video Object Segmentation and Optical Flow
Sep 20, 2017
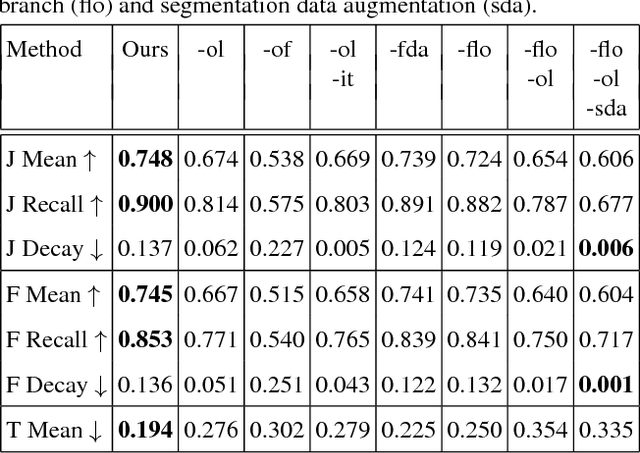
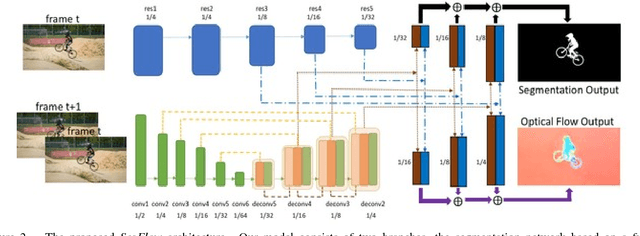
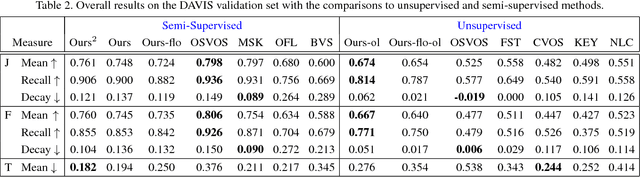
This paper proposes an end-to-end trainable network, SegFlow, for simultaneously predicting pixel-wise object segmentation and optical flow in videos. The proposed SegFlow has two branches where useful information of object segmentation and optical flow is propagated bidirectionally in a unified framework. The segmentation branch is based on a fully convolutional network, which has been proved effective in image segmentation task, and the optical flow branch takes advantage of the FlowNet model. The unified framework is trained iteratively offline to learn a generic notion, and fine-tuned online for specific objects. Extensive experiments on both the video object segmentation and optical flow datasets demonstrate that introducing optical flow improves the performance of segmentation and vice versa, against the state-of-the-art algorithms.
Learning to Segment Instances in Videos with Spatial Propagation Network
Sep 14, 2017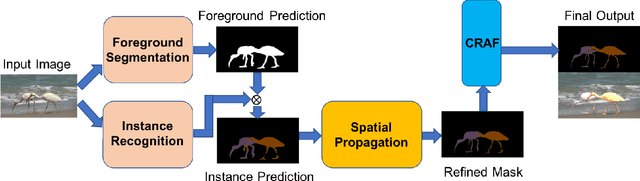
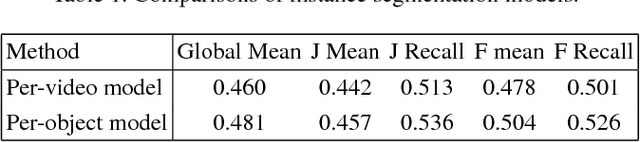
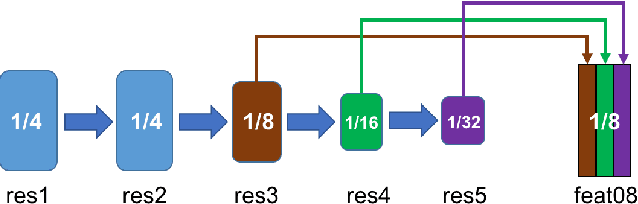
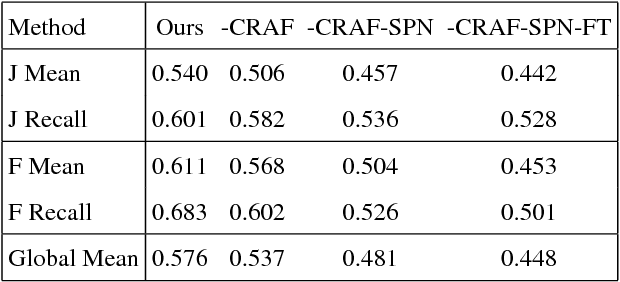
We propose a deep learning-based framework for instance-level object segmentation. Our method mainly consists of three steps. First, We train a generic model based on ResNet-101 for foreground/background segmentations. Second, based on this generic model, we fine-tune it to learn instance-level models and segment individual objects by using augmented object annotations in first frames of test videos. To distinguish different instances in the same video, we compute a pixel-level score map for each object from these instance-level models. Each score map indicates the objectness likelihood and is only computed within the foreground mask obtained in the first step. To further refine this per frame score map, we learn a spatial propagation network. This network aims to learn how to propagate a coarse segmentation mask spatially based on the pairwise similarities in each frame. In addition, we apply a filter on the refined score map that aims to recognize the best connected region using spatial and temporal consistencies in the video. Finally, we decide the instance-level object segmentation in each video by comparing score maps of different instances.
SVDNet for Pedestrian Retrieval
Aug 06, 2017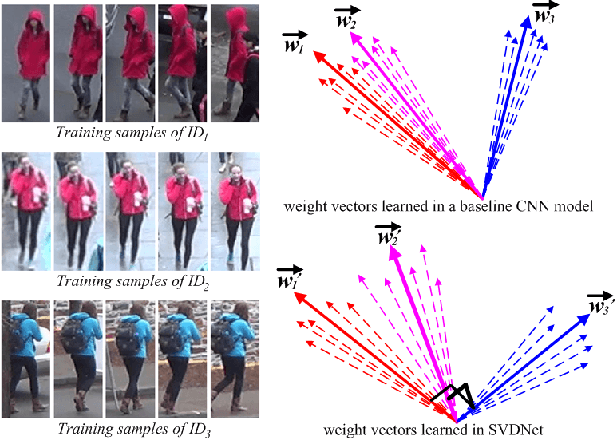
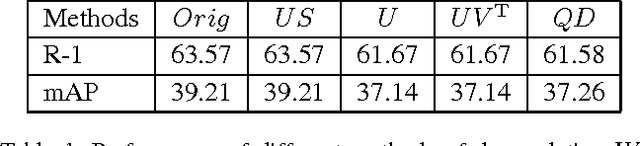
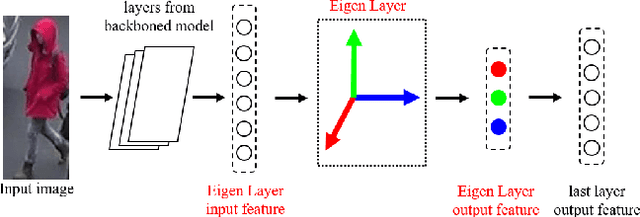
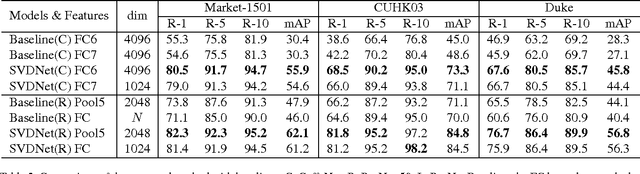
This paper proposes the SVDNet for retrieval problems, with focus on the application of person re-identification (re-ID). We view each weight vector within a fully connected (FC) layer in a convolutional neuron network (CNN) as a projection basis. It is observed that the weight vectors are usually highly correlated. This problem leads to correlations among entries of the FC descriptor, and compromises the retrieval performance based on the Euclidean distance. To address the problem, this paper proposes to optimize the deep representation learning process with Singular Vector Decomposition (SVD). Specifically, with the restraint and relaxation iteration (RRI) training scheme, we are able to iteratively integrate the orthogonality constraint in CNN training, yielding the so-called SVDNet. We conduct experiments on the Market-1501, CUHK03, and Duke datasets, and show that RRI effectively reduces the correlation among the projection vectors, produces more discriminative FC descriptors, and significantly improves the re-ID accuracy. On the Market-1501 dataset, for instance, rank-1 accuracy is improved from 55.3% to 80.5% for CaffeNet, and from 73.8% to 82.3% for ResNet-50.
Learning Structured Semantic Embeddings for Visual Recognition
Jun 05, 2017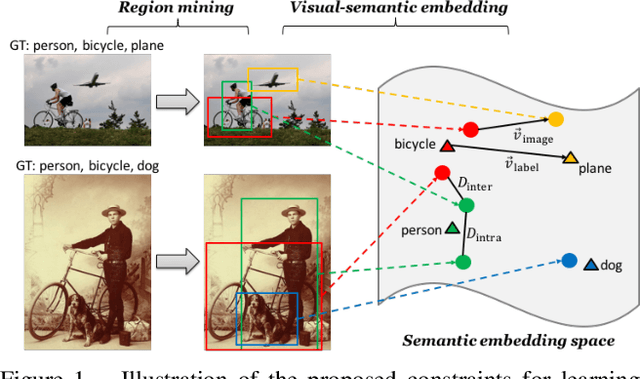
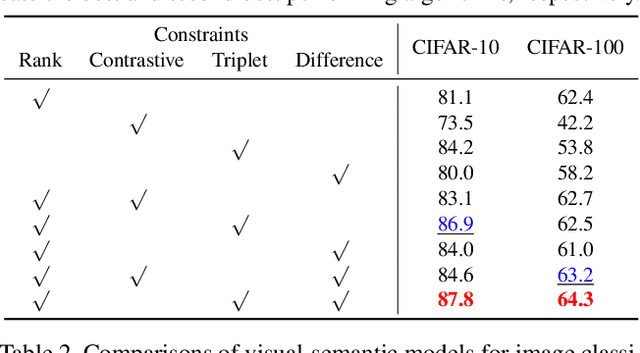
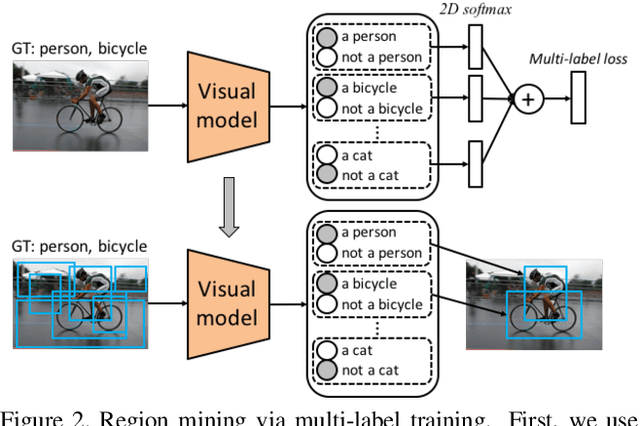
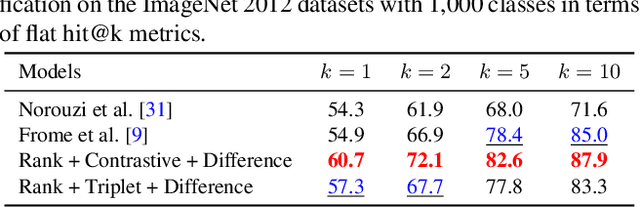
Numerous embedding models have been recently explored to incorporate semantic knowledge into visual recognition. Existing methods typically focus on minimizing the distance between the corresponding images and texts in the embedding space but do not explicitly optimize the underlying structure. Our key observation is that modeling the pairwise image-image relationship improves the discrimination ability of the embedding model. In this paper, we propose the structured discriminative and difference constraints to learn visual-semantic embeddings. First, we exploit the discriminative constraints to capture the intra- and inter-class relationships of image embeddings. The discriminative constraints encourage separability for image instances of different classes. Second, we align the difference vector between a pair of image embeddings with that of the corresponding word embeddings. The difference constraints help regularize image embeddings to preserve the semantic relationships among word embeddings. Extensive evaluations demonstrate the effectiveness of the proposed structured embeddings for single-label classification, multi-label classification, and zero-shot recognition.
Metric Learning in Codebook Generation of Bag-of-Words for Person Re-identification
Apr 11, 2017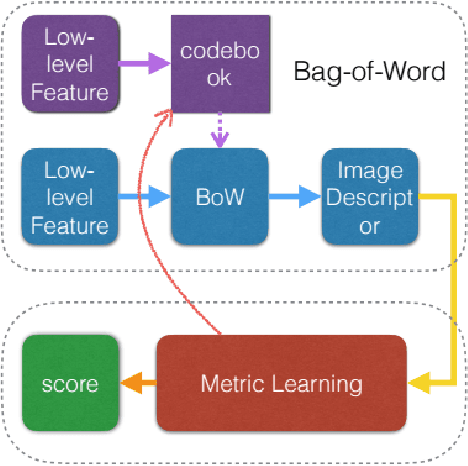
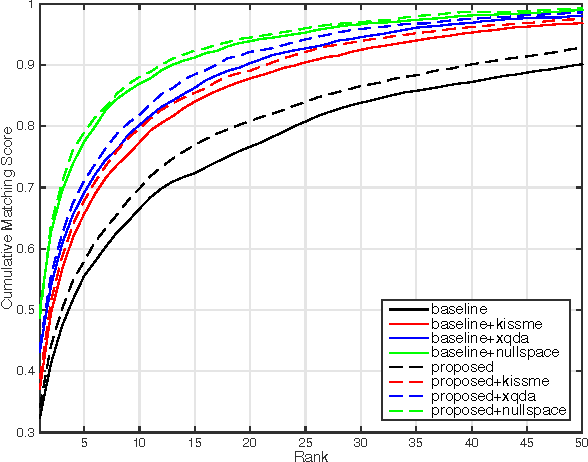
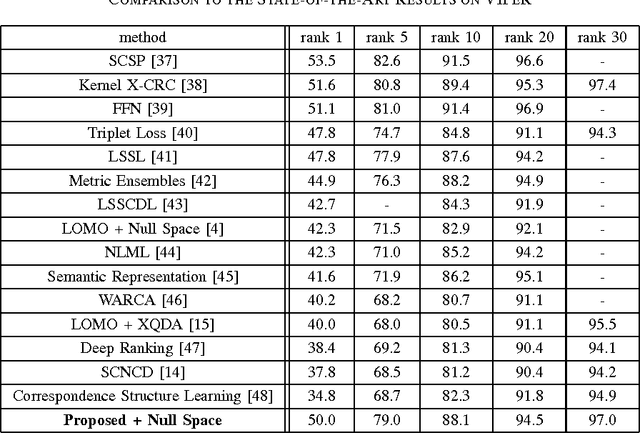
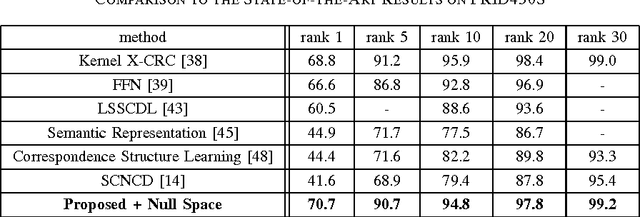
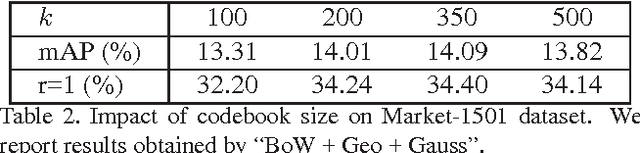
Person re-identification is generally divided into two part: first how to represent a pedestrian by discriminative visual descriptors and second how to compare them by suitable distance metrics. Conventional methods isolate these two parts, the first part usually unsupervised and the second part supervised. The Bag-of-Words (BoW) model is a widely used image representing descriptor in part one. Its codebook is simply generated by clustering visual features in Euclidian space. In this paper, we propose to use part two metric learning techniques in the codebook generation phase of BoW. In particular, the proposed codebook is clustered under Mahalanobis distance which is learned supervised. Extensive experiments prove that our proposed method is effective. With several low level features extracted on superpixel and fused together, our method outperforms state-of-the-art on person re-identification benchmarks including VIPeR, PRID450S, and Market1501.
Good Practice in CNN Feature Transfer
Apr 01, 2016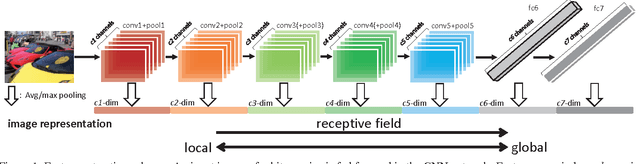

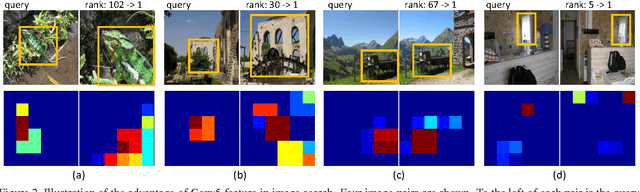

The objective of this paper is the effective transfer of the Convolutional Neural Network (CNN) feature in image search and classification. Systematically, we study three facts in CNN transfer. 1) We demonstrate the advantage of using images with a properly large size as input to CNN instead of the conventionally resized one. 2) We benchmark the performance of different CNN layers improved by average/max pooling on the feature maps. Our observation suggests that the Conv5 feature yields very competitive accuracy under such pooling step. 3) We find that the simple combination of pooled features extracted across various CNN layers is effective in collecting evidences from both low and high level descriptors. Following these good practices, we are capable of improving the state of the art on a number of benchmarks to a large margin.
Person Re-Identification by Discriminative Selection in Video Ranking
Jan 23, 2016
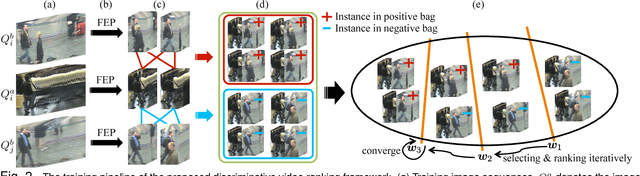
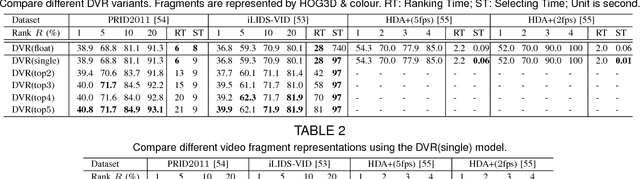
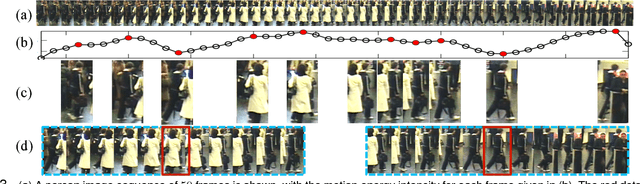
Current person re-identification (ReID) methods typically rely on single-frame imagery features, whilst ignoring space-time information from image sequences often available in the practical surveillance scenarios. Single-frame (single-shot) based visual appearance matching is inherently limited for person ReID in public spaces due to the challenging visual ambiguity and uncertainty arising from non-overlapping camera views where viewing condition changes can cause significant people appearance variations. In this work, we present a novel model to automatically select the most discriminative video fragments from noisy/incomplete image sequences of people from which reliable space-time and appearance features can be computed, whilst simultaneously learning a video ranking function for person ReID. Using the PRID$2011$, iLIDS-VID, and HDA+ image sequence datasets, we extensively conducted comparative evaluations to demonstrate the advantages of the proposed model over contemporary gait recognition, holistic image sequence matching and state-of-the-art single-/multi-shot ReID methods.
Deep Transfer Network: Unsupervised Domain Adaptation
Mar 02, 2015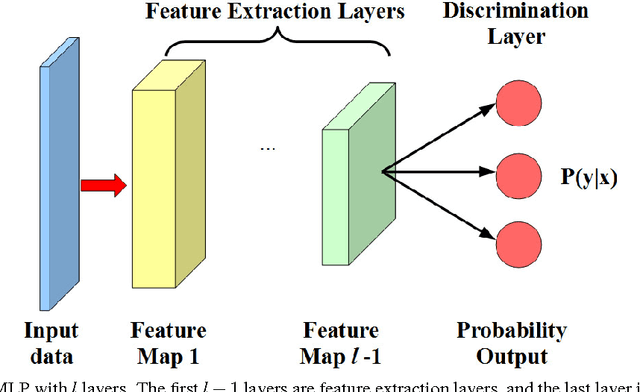
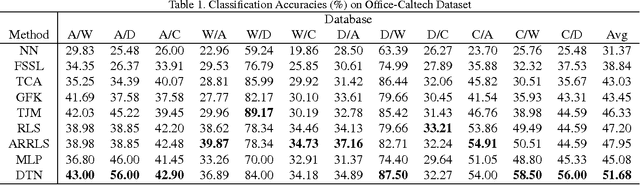

Domain adaptation aims at training a classifier in one dataset and applying it to a related but not identical dataset. One successfully used framework of domain adaptation is to learn a transformation to match both the distribution of the features (marginal distribution), and the distribution of the labels given features (conditional distribution). In this paper, we propose a new domain adaptation framework named Deep Transfer Network (DTN), where the highly flexible deep neural networks are used to implement such a distribution matching process. This is achieved by two types of layers in DTN: the shared feature extraction layers which learn a shared feature subspace in which the marginal distributions of the source and the target samples are drawn close, and the discrimination layers which match conditional distributions by classifier transduction. We also show that DTN has a computation complexity linear to the number of training samples, making it suitable to large-scale problems. By combining the best paradigms in both worlds (deep neural networks in recognition, and matching marginal and conditional distributions in domain adaptation), we demonstrate by extensive experiments that DTN improves significantly over former methods in both execution time and classification accuracy.
Person Re-identification Meets Image Search
Feb 07, 2015
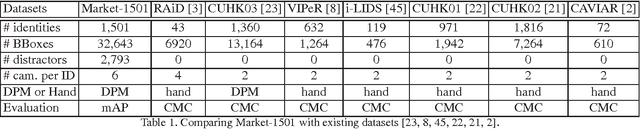
For long time, person re-identification and image search are two separately studied tasks. However, for person re-identification, the effectiveness of local features and the "query-search" mode make it well posed for image search techniques. In the light of recent advances in image search, this paper proposes to treat person re-identification as an image search problem. Specifically, this paper claims two major contributions. 1) By designing an unsupervised Bag-of-Words representation, we are devoted to bridging the gap between the two tasks by integrating techniques from image search in person re-identification. We show that our system sets up an effective yet efficient baseline that is amenable to further supervised/unsupervised improvements. 2) We contribute a new high quality dataset which uses DPM detector and includes a number of distractor images. Our dataset reaches closer to realistic settings, and new perspectives are provided. Compared with approaches that rely on feature-feature match, our method is faster by over two orders of magnitude. Moreover, on three datasets, we report competitive results compared with the state-of-the-art methods.
Beyond $χ^2$ Difference: Learning Optimal Metric for Boundary Detection
Jun 04, 2014
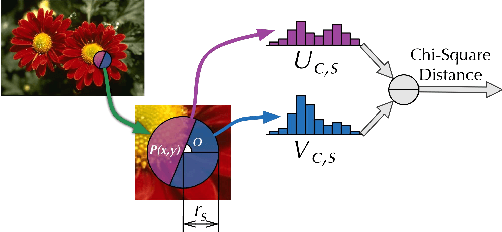
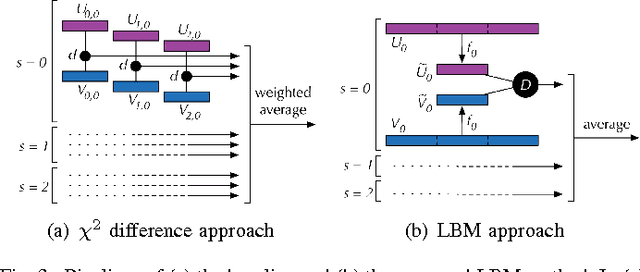
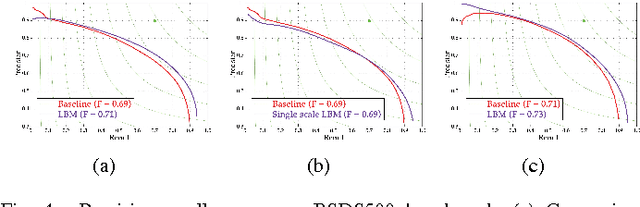
This letter focuses on solving the challenging problem of detecting natural image boundaries. A boundary usually refers to the border between two regions with different semantic meanings. Therefore, a measurement of dissimilarity between image regions plays a pivotal role in boundary detection of natural images. To improve the performance of boundary detection, a Learning-based Boundary Metric (LBM) is proposed to replace $\chi^2$ difference adopted by the classical algorithm mPb. Compared with $\chi^2$ difference, LBM is composed of a single layer neural network and an RBF kernel, and is fine-tuned by supervised learning rather than human-crafted. It is more effective in describing the dissimilarity between natural image regions while tolerating large variance of image data. After substituting $\chi^2$ difference with LBM, the F-measure metric of mPb on the BSDS500 benchmark is increased from 0.69 to 0.71. Moreover, when image features are computed on a single scale, the proposed LBM algorithm still achieves competitive results compared with \emph{mPb}, which makes use of multi-scale image features.