 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeated-Up Softmax Embedding
Sep 11, 2018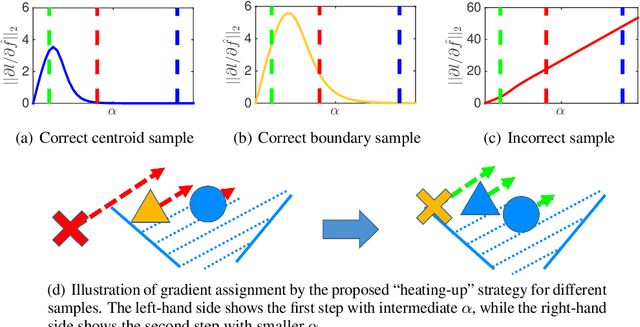
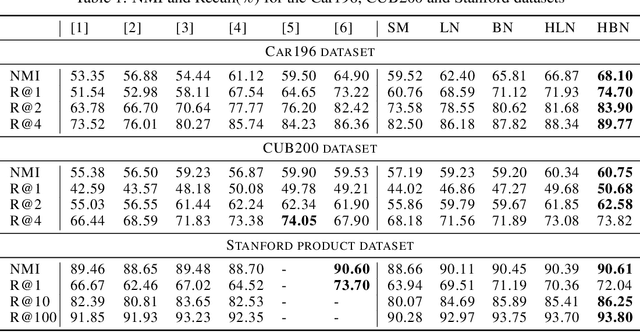
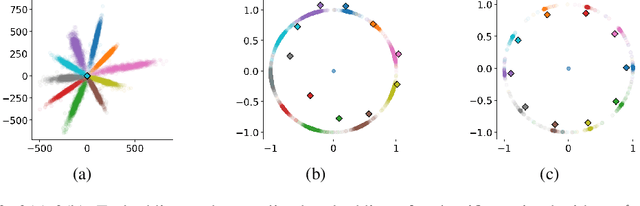
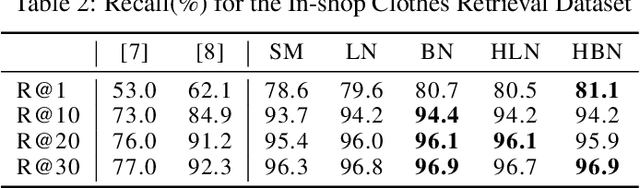
Metric learning aims at learning a distance which is consistent with the semantic meaning of the samples. The problem is generally solved by learning an embedding for each sample such that the embeddings of samples of the same category are compact while the embeddings of samples of different categories are spread-out in the feature space. We study the features extracted from the second last layer of a deep neural network based classifier trained with the cross entropy loss on top of the softmax layer. We show that training classifiers with different temperature values of softmax function leads to features with different levels of compactness. Leveraging these insights, we propose a "heating-up" strategy to train a classifier with increasing temperatures, leading the corresponding embeddings to achieve state-of-the-art performance on a variety of metric learning benchmarks.
Deep Transfer Network: Unsupervised Domain Adaptation
Mar 02, 2015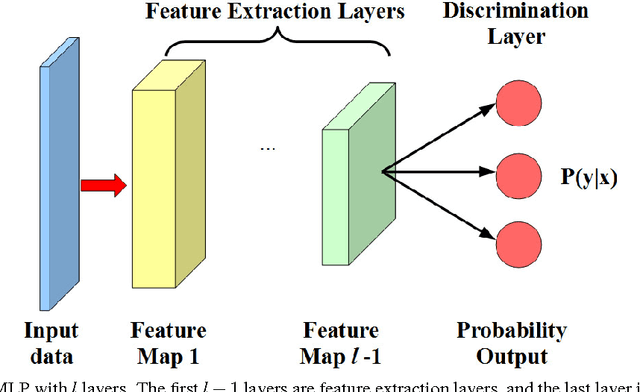
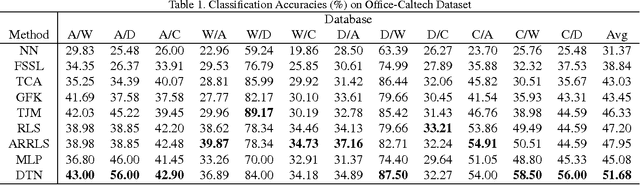

Domain adaptation aims at training a classifier in one dataset and applying it to a related but not identical dataset. One successfully used framework of domain adaptation is to learn a transformation to match both the distribution of the features (marginal distribution), and the distribution of the labels given features (conditional distribution). In this paper, we propose a new domain adaptation framework named Deep Transfer Network (DTN), where the highly flexible deep neural networks are used to implement such a distribution matching process. This is achieved by two types of layers in DTN: the shared feature extraction layers which learn a shared feature subspace in which the marginal distributions of the source and the target samples are drawn close, and the discrimination layers which match conditional distributions by classifier transduction. We also show that DTN has a computation complexity linear to the number of training samples, making it suitable to large-scale problems. By combining the best paradigms in both worlds (deep neural networks in recognition, and matching marginal and conditional distributions in domain adaptation), we demonstrate by extensive experiments that DTN improves significantly over former methods in both execution time and classification accuracy.