 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaMCP: Incremental Regeneration via Spec-Aware Transformation for MCP servers
May 27, 2026The rapid development of LLMs coupled with the introduction of Model Context Protocol (MCP) has revolutionized how intelligent agents interact with APIs through deterministic and structured methods \cite{ModelContextProtocolIntro2025}. While some existing systems like AutoMCP attempt to automate a previously completely manual process of generating MCP servers, they fail to address the recurring challenge of maintaining synchronization between evolving enterprise-level APIs and their corresponding MCP toolset implementation \cite{mastouri2025makingrestapisagentready}. This paper introduces DeltaMCP, a specification-aware, incremental regeneration tool for enterprise-grade MCP servers. DeltaMCP enables developers to only update the affected tooling of MCP servers, given a new release of it's corresponding service's OpenAPI specification. Using Azure REST API specifications as the evaluation dataset, DeltaMCP is benchmarked against baseline full generation methods on generation quality and system performance. The results demonstrate the reduction in developer overhead through DeltaMCP whilst improving maintainability and version consistency. This research offers a scalable approach for enterprises seeking to maintain high-fidelity, up-to-date MCP server infrastructures for LLM-based systems.
PhenoYieldNet: Learning Crop-Aware Phenological Responses for Multi-Crop Yield Prediction
May 22, 2026Accurate crop yield prediction is crucial for sustainable agriculture and global food security. While existing methods are predominantly developed for single-crop prediction, they often struggle to generalize across diverse crop types, without addressing the unique crop phenological responses that are dynamically modulated by complex weather patterns. In this paper, we propose PhenoYieldNet, a multi-crop yield prediction framework that learns crop-specific phenology by explicitly modeling their responses with temporal drivers. Specifically, we develop a crop-aware temporal decoder consisting of a Crop Phenology Bank (CPB) and a Crop Phenology Attention (CPA) module. The CPB integrates a set of learnable embeddings, which leverage a query to guide the CPA module to learn the most relevant phenology patterns for the specific crop. And the CPA module explicitly captures multi-scale trend and variation components to construct temporal contexts, enabling the model to dynamically adjust the attention across different phenological stages. To learn robust and generalizable features for multi-crop prediction, the encoder is initialized with a pre-trained foundation model, and further adapted via a self-supervised Temporal Contrastive Adaptation strategy to align with agricultural temporal dynamics. Extensive experiments conducted on multi-crop datasets indicate that our proposed method significantly outperforms state-of-the-art methods, exhibiting strong generalization capabilities across different regions and crops.
Stable Attention Response for Reliable Precipitation Nowcasting
May 13, 2026Precipitation nowcasting remains challenging due to the highly localized, rapidly evolving, and heterogeneous nature of atmospheric dynamics. Although recent methods increasingly adopt attention-based architectures in both unimodal and multimodal settings, they mainly emphasize stronger representation learning and prediction capacity, while paying less attention to the stability of attention responses across samples. In this work, we show that cross-sample instability of attention-response energy is an important and previously underexplored source of forecasting unreliability. Empirically, inaccurate forecasts are associated with larger attention-response energy variance across heads and layers. Theoretically, we show that cross-sample variability can propagate through self-attention, and enlarge a lower bound on prediction error. Based on this insight, we propose HARECast, a Head-wise Attention Response Energy-regulated framework for precipitation nowcasting. HARECast explicitly models head-wise attention-response energy and stabilizes it through a group-wise regularization objective that reduces cross-sample fluctuations. The proposed formulation is generic and applicable to both unimodal and multimodal nowcasting architectures. We instantiate HARECast in a standard forecasting pipeline with reconstruction branches and a diffusion-based predictor, and evaluate it on commonly used benchmarks--SEVIR and MeteoNet. Experimental results demonstrate that HARECast achieves state-of-the-art performance.
OrthoEraser: Coupled-Neuron Orthogonal Projection for Concept Erasure
Mar 12, 2026Text-to-image (T2I) models face significant safety risks from adversarial induction, yet current concept erasure methods often cause collateral damage to benign attributes when suppressing selected neurons entirely. This occurs because sensitive and benign semantics exhibit non-orthogonal superposition, sharing activation subspaces where their respective vectors are inherently entangled. To address this issue, we propose OrthoEraser, which leverages sparse autoencoders (SAE) to achieve high-resolution feature disentanglement and subsequently redefines erasure as an analytical orthogonalization projection that preserves the benign manifold's invariance. OrthoEraser first employs SAE to decompose dense activations and segregate sensitive neurons. It then uses coupled neuron detection to identify non-sensitive features vulnerable to intervention. The key novelty lies in an analytical gradient orthogonalization strategy that projects erasure vectors onto the null space of the coupled neurons. This orthogonally decouples the sensitive concepts from the identified critical benign subspace, effectively preserving non-sensitive semantics. Experimental results on safety demonstrate that OrthoEraser achieves high erasure precision, effectively removing harmful content while preserving the integrity of the generative manifold, and significantly outperforming SOTA baselines. This paper contains results of unsafe models.
Systematic Analysis of MCP Security
Aug 18, 2025The Model Context Protocol (MCP) has emerged as a universal standard that enables AI agents to seamlessly connect with external tools, significantly enhancing their functionality. However, while MCP brings notable benefits, it also introduces significant vulnerabilities, such as Tool Poisoning Attacks (TPA), where hidden malicious instructions exploit the sycophancy of large language models (LLMs) to manipulate agent behavior. Despite these risks, current academic research on MCP security remains limited, with most studies focusing on narrow or qualitative analyses that fail to capture the diversity of real-world threats. To address this gap, we present the MCP Attack Library (MCPLIB), which categorizes and implements 31 distinct attack methods under four key classifications: direct tool injection, indirect tool injection, malicious user attacks, and LLM inherent attack. We further conduct a quantitative analysis of the efficacy of each attack. Our experiments reveal key insights into MCP vulnerabilities, including agents' blind reliance on tool descriptions, sensitivity to file-based attacks, chain attacks exploiting shared context, and difficulty distinguishing external data from executable commands. These insights, validated through attack experiments, underscore the urgency for robust defense strategies and informed MCP design. Our contributions include 1) constructing a comprehensive MCP attack taxonomy, 2) introducing a unified attack framework MCPLIB, and 3) conducting empirical vulnerability analysis to enhance MCP security mechanisms. This work provides a foundational framework, supporting the secure evolution of MCP ecosystems.
F2Net: A Frequency-Fused Network for Ultra-High Resolution Remote Sensing Segmentation
Jun 09, 2025



Semantic segmentation of ultra-high-resolution (UHR) remote sensing imagery is critical for applications like environmental monitoring and urban planning but faces computational and optimization challenges. Conventional methods either lose fine details through downsampling or fragment global context via patch processing. While multi-branch networks address this trade-off, they suffer from computational inefficiency and conflicting gradient dynamics during training. We propose F2Net, a frequency-aware framework that decomposes UHR images into high- and low-frequency components for specialized processing. The high-frequency branch preserves full-resolution structural details, while the low-frequency branch processes downsampled inputs through dual sub-branches capturing short- and long-range dependencies. A Hybrid-Frequency Fusion module integrates these observations, guided by two novel objectives: Cross-Frequency Alignment Loss ensures semantic consistency between frequency components, and Cross-Frequency Balance Loss regulates gradient magnitudes across branches to stabilize training. Evaluated on DeepGlobe and Inria Aerial benchmarks, F2Net achieves state-of-the-art performance with mIoU of 80.22 and 83.39, respectively. Our code will be publicly available.
Span-level Emotion-Cause-Category Triplet Extraction with Instruction Tuning LLMs and Data Augmentation
Apr 13, 2025Span-level emotion-cause-category triplet extraction represents a novel and complex challenge within emotion cause analysis. This task involves identifying emotion spans, cause spans, and their associated emotion categories within the text to form structured triplets. While prior research has predominantly concentrated on clause-level emotion-cause pair extraction and span-level emotion-cause detection, these methods often confront challenges originating from redundant information retrieval and difficulty in accurately determining emotion categories, particularly when emotions are expressed implicitly or ambiguously. To overcome these challenges, this study explores a fine-grained approach to span-level emotion-cause-category triplet extraction and introduces an innovative framework that leverages instruction tuning and data augmentation techniques based on large language models. The proposed method employs task-specific triplet extraction instructions and utilizes low-rank adaptation to fine-tune large language models, eliminating the necessity for intricate task-specific architectures. Furthermore, a prompt-based data augmentation strategy is developed to address data scarcity by guiding large language models in generating high-quality synthetic training data. Extensive experimental evaluations demonstrate that the proposed approach significantly outperforms existing baseline methods, achieving at least a 12.8% improvement in span-level emotion-cause-category triplet extraction metrics. The results demonstrate the method's effectiveness and robustness, offering a promising avenue for advancing research in emotion cause analysis. The source code is available at https://github.com/zxgnlp/InstruDa-LLM.
RI-MAE: Rotation-Invariant Masked AutoEncoders for Self-Supervised Point Cloud Representation Learning
Aug 31, 2024



Masked point modeling methods have recently achieved great success in self-supervised learning for point cloud data. However, these methods are sensitive to rotations and often exhibit sharp performance drops when encountering rotational variations. In this paper, we propose a novel Rotation-Invariant Masked AutoEncoders (RI-MAE) to address two major challenges: 1) achieving rotation-invariant latent representations, and 2) facilitating self-supervised reconstruction in a rotation-invariant manner. For the first challenge, we introduce RI-Transformer, which features disentangled geometry content, rotation-invariant relative orientation and position embedding mechanisms for constructing rotation-invariant point cloud latent space. For the second challenge, a novel dual-branch student-teacher architecture is devised. It enables the self-supervised learning via the reconstruction of masked patches within the learned rotation-invariant latent space. Each branch is based on an RI-Transformer, and they are connected with an additional RI-Transformer predictor. The teacher encodes all point patches, while the student solely encodes unmasked ones. Finally, the predictor predicts the latent features of the masked patches using the output latent embeddings from the student, supervised by the outputs from the teacher. Extensive experiments demonstrate that our method is robust to rotations, achieving the state-of-the-art performance on various downstream tasks.
DeFuzz: Deep Learning Guided Directed Fuzzing
Oct 23, 2020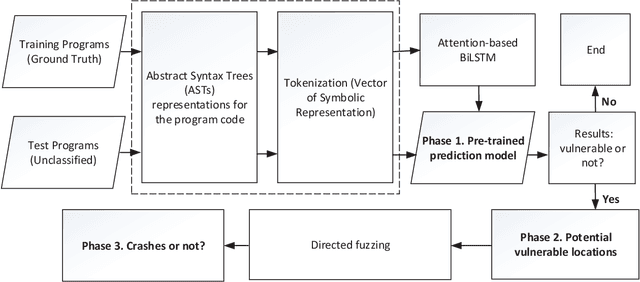

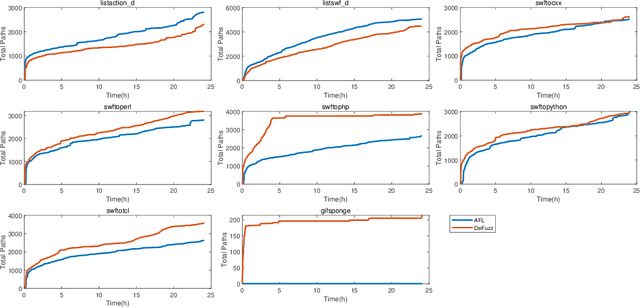
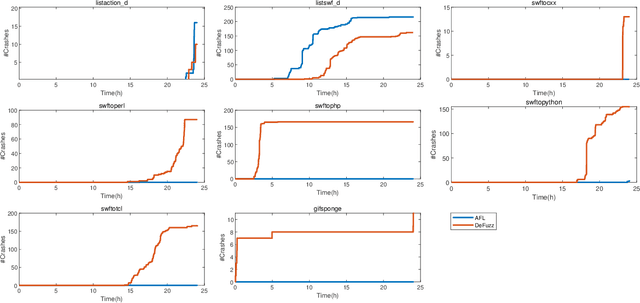
Fuzzing is one of the most effective technique to identify potential software vulnerabilities. Most of the fuzzers aim to improve the code coverage, and there is lack of directedness (e.g., fuzz the specified path in a software). In this paper, we proposed a deep learning (DL) guided directed fuzzing for software vulnerability detection, named DeFuzz. DeFuzz includes two main schemes: (1) we employ a pre-trained DL prediction model to identify the potentially vulnerable functions and the locations (i.e., vulnerable addresses). Precisely, we employ Bidirectional-LSTM (BiLSTM) to identify attention words, and the vulnerabilities are associated with these attention words in functions. (2) then we employ directly fuzzing to fuzz the potential vulnerabilities by generating inputs that tend to arrive the predicted locations. To evaluate the effectiveness and practical of the proposed DeFuzz technique, we have conducted experiments on real-world data sets. Experimental results show that our DeFuzz can discover coverage more and faster than AFL. Moreover, DeFuzz exposes 43 more bugs than AFL on real-world applications.