 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditEmoTalk: Controllable Speech-Driven 3D Facial Animation with Continuous Expression Editing
Jan 15, 2026Speech-driven 3D facial animation aims to generate realistic and expressive facial motions directly from audio. While recent methods achieve high-quality lip synchronization, they often rely on discrete emotion categories, limiting continuous and fine-grained emotional control. We present EditEmoTalk, a controllable speech-driven 3D facial animation framework with continuous emotion editing. The key idea is a boundary-aware semantic embedding that learns the normal directions of inter-emotion decision boundaries, enabling a continuous expression manifold for smooth emotion manipulation. Moreover, we introduce an emotional consistency loss that enforces semantic alignment between the generated motion dynamics and the target emotion embedding through a mapping network, ensuring faithful emotional expression. Extensive experiments demonstrate that EditEmoTalk achieves superior controllability, expressiveness, and generalization while maintaining accurate lip synchronization. Code and pretrained models will be released.
MotionFlux: Efficient Text-Guided Motion Generation through Rectified Flow Matching and Preference Alignment
Aug 27, 2025



Motion generation is essential for animating virtual characters and embodied agents. While recent text-driven methods have made significant strides, they often struggle with achieving precise alignment between linguistic descriptions and motion semantics, as well as with the inefficiencies of slow, multi-step inference. To address these issues, we introduce TMR++ Aligned Preference Optimization (TAPO), an innovative framework that aligns subtle motion variations with textual modifiers and incorporates iterative adjustments to reinforce semantic grounding. To further enable real-time synthesis, we propose MotionFLUX, a high-speed generation framework based on deterministic rectified flow matching. Unlike traditional diffusion models, which require hundreds of denoising steps, MotionFLUX constructs optimal transport paths between noise distributions and motion spaces, facilitating real-time synthesis. The linearized probability paths reduce the need for multi-step sampling typical of sequential methods, significantly accelerating inference time without sacrificing motion quality. Experimental results demonstrate that, together, TAPO and MotionFLUX form a unified system that outperforms state-of-the-art approaches in both semantic consistency and motion quality, while also accelerating generation speed. The code and pretrained models will be released.
Sphere Face Model:A 3D Morphable Model with Hypersphere Manifold Latent Space
Dec 04, 2021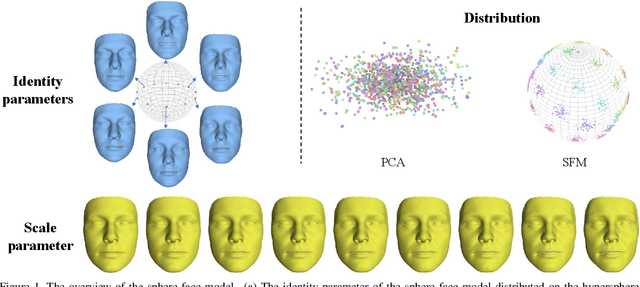
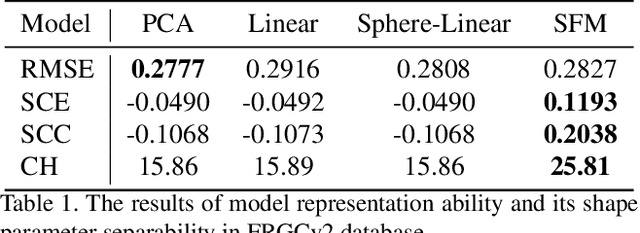
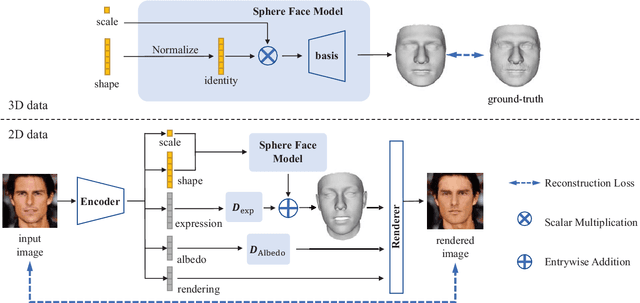
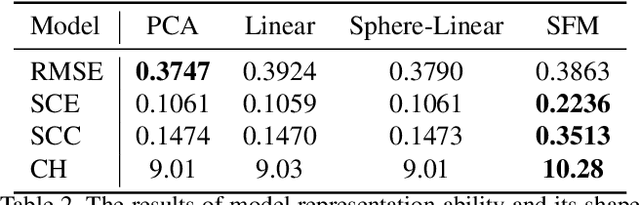
3D Morphable Models (3DMMs) are generative models for face shape and appearance. However, the shape parameters of traditional 3DMMs satisfy the multivariate Gaussian distribution while the identity embeddings satisfy the hypersphere distribution, and this conflict makes it challenging for face reconstruction models to preserve the faithfulness and the shape consistency simultaneously. To address this issue, we propose the Sphere Face Model(SFM), a novel 3DMM for monocular face reconstruction, which can preserve both shape fidelity and identity consistency. The core of our SFM is the basis matrix which can be used to reconstruct 3D face shapes, and the basic matrix is learned by adopting a two-stage training approach where 3D and 2D training data are used in the first and second stages, respectively. To resolve the distribution mismatch, we design a novel loss to make the shape parameters have a hyperspherical latent space. Extensive experiments show that SFM has high representation ability and shape parameter space's clustering performance. Moreover, it produces fidelity face shapes, and the shapes are consistent in challenging conditions in monocular face reconstruction.
Reconstructing Recognizable 3D Face Shapes based on 3D Morphable Models
Apr 08, 2021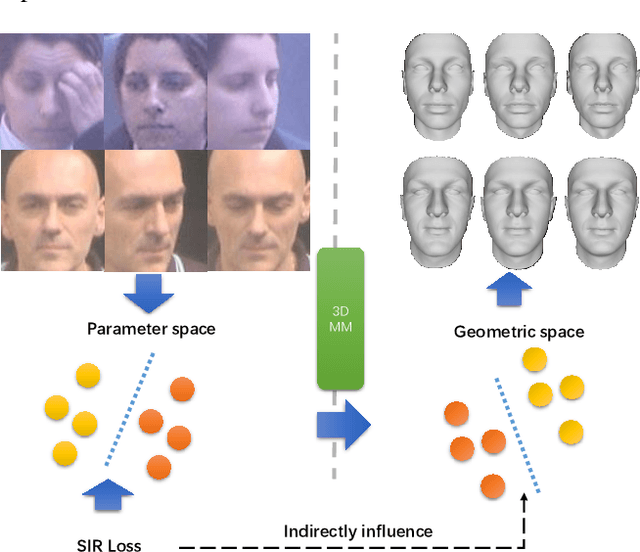
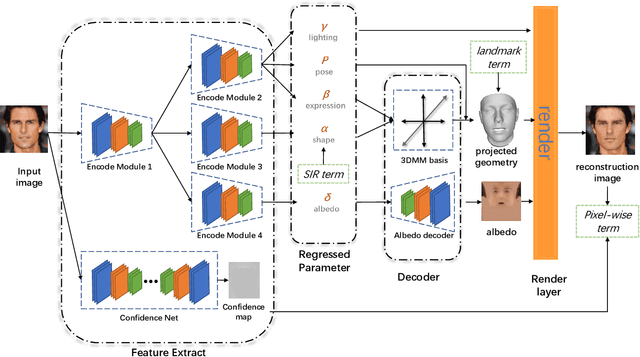

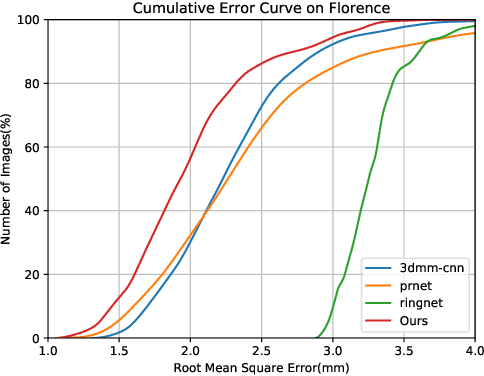
Many recent works have reconstructed distinctive 3D face shapes by aggregating shape parameters of the same identity and separating those of different people based on parametric models (e.g., 3D morphable models (3DMMs)). However, despite the high accuracy in the face recognition task using these shape parameters, the visual discrimination of face shapes reconstructed from those parameters is unsatisfactory. The following research question has not been answered in previous works: Do discriminative shape parameters guarantee visual discrimination in represented 3D face shapes? This paper analyzes the relationship between shape parameters and reconstructed shape geometry and proposes a novel shape identity-aware regularization(SIR) loss for shape parameters, aiming at increasing discriminability in both the shape parameter and shape geometry domains. Moreover, to cope with the lack of training data containing both landmark and identity annotations, we propose a network structure and an associated training strategy to leverage mixed data containing either identity or landmark labels. We compare our method with existing methods in terms of the reconstruction error, visual distinguishability, and face recognition accuracy of the shape parameters. Experimental results show that our method outperforms the state-of-the-art methods.