 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinship Identification through Joint Learning Using Kinship Verification Ensemble
Apr 20, 2020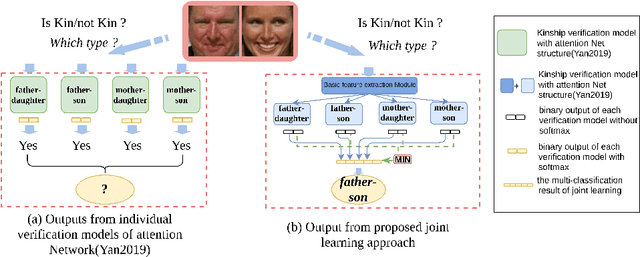
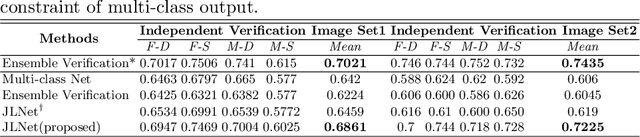
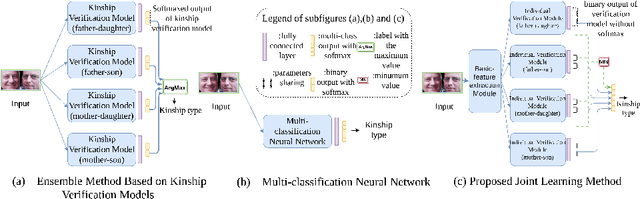
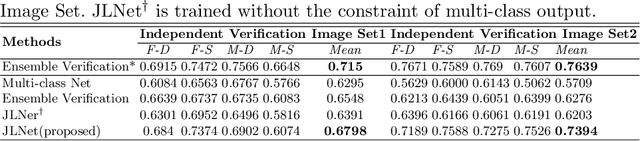
While kinship verification is a well-exploited task which only identifies whether or not two people are kins, kinship identification is the task to further identify the particular type of kinships and is not well exploited yet. We found that a naive extension of kinship verification cannot solve the identification properly. This is because the existing verification networks are individually trained on specific kinships and do not consider the context between different kinship types. Also, the existing kinship verification dataset has a biased positive-negative distribution, which is different from real-world distribution. To solve it, we propose a novel kinship identification approach through the joint training of kinship verification ensembles and a Joint Identification Module. We also propose to rebalance the training dataset to make it realistic. Rigorous experiments demonstrate an appealing performance on kinship identification task. It also demonstrates significant performance improvement of kinship verification when trained on the same unbiased data.
Learning to Dehaze From Realistic Scene with A Fast Physics Based Dehazing Network
Apr 18, 2020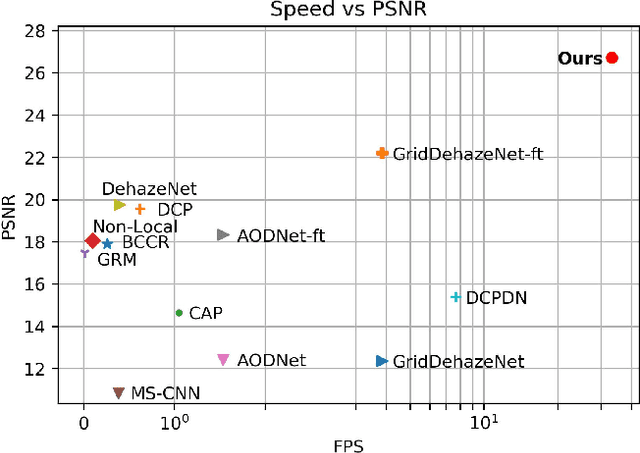


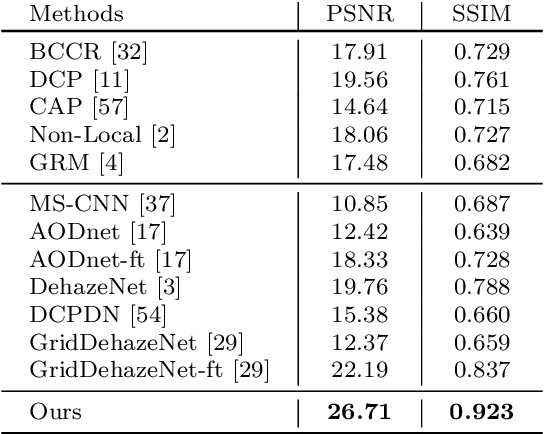
Dehaze is one of the popular computer vision research topics for long. A realtime method with reliable performance is highly desired for a lot of applications such as autonomous driving. In recent years, while learning based methods require datasets containing pairs of hazy images and clean ground truth references, it is generally impossible to capture this kind of data in real. Many existing researches compromise this difficulty to generate hazy images by rendering the haze from depth on common RGBD datasets using the haze imaging model. However, there is still a gap between the synthetic datasets and real hazy images as large datasets with high quality depth are mostly indoor and depth maps for outdoor are imprecise. In this paper, we complement the exiting datasets with a new, large, and diverse dehazing dataset containing real outdoor scenes from HD 3D videos. We select large number of high quality frames of real outdoor scenes and render haze on them using depth from stereo. Our dataset is more realistic than existing ones and we demonstrate that using this dataset greatly improves the dehazing performance on real scenes. In addition to the dataset, inspired by the physics model, we also propose a light and reliable dehaze network. Our approach outperforms other methods by a large margin and becomes the new state-of-the-art method. Moreover, the light design of the network enables our methods to run at realtime speed that is much faster than other methods.
Unsupervised Learning for Intrinsic Image Decomposition from a Single Image
Nov 22, 2019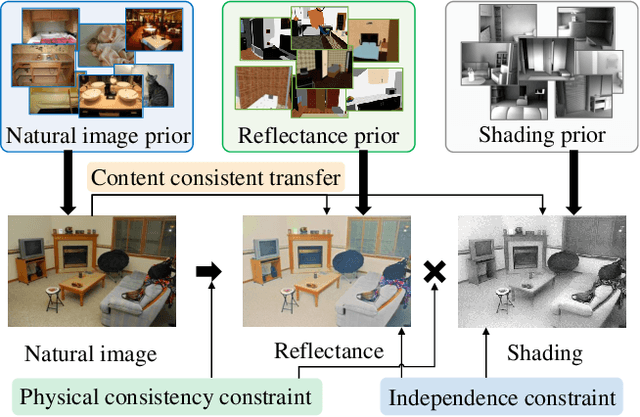
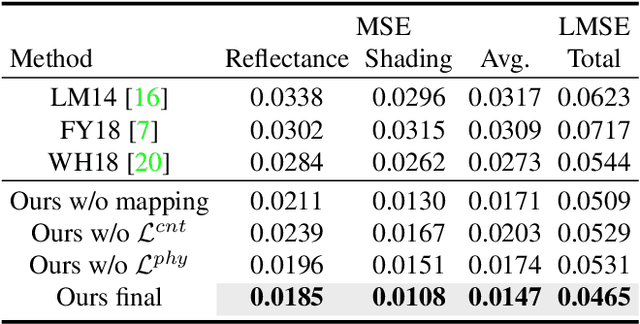
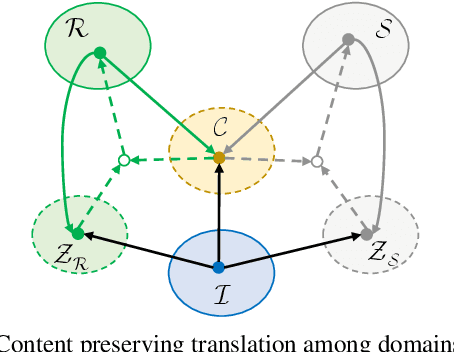
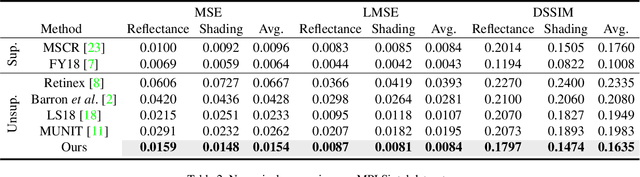
Intrinsic image decomposition, which is an essential task in computer vision, aims to infer the reflectance and shading of the scene. It is challenging since it needs to separate one image into two components. To tackle this, conventional methods introduce various priors to constrain the solution, yet with limited performance. Meanwhile, the problem is typically solved by supervised learning methods, which is actually not an ideal solution since obtaining ground truth reflectance and shading for massive general natural scenes is challenging and even impossible. In this paper, we propose a novel unsupervised intrinsic image decomposition framework, which relies on neither labeled training data nor hand-crafted priors. Instead, it directly learns the latent feature of reflectance and shading from unsupervised and uncorrelated data. To enable this, we explore the independence between reflectance and shading, the domain invariant content constraint and the physical constraint. Extensive experiments on both synthetic and real image datasets demonstrate consistently superior performance of the proposed method.
Hyperspectral City V1.0 Dataset and Benchmark
Aug 13, 2019



This document introduces the background and the usage of the Hyperspectral City Dataset and the benchmark. The documentation first starts with the background and motivation of the dataset. Follow it, we briefly describe the method of collecting the dataset and the processing method from raw dataset to the final release dataset, specifically, the version 1.0. We also provide the detailed usage of the dataset and the evaluation metric for submitted the result for the 2019 Hyperspectral City Challenge.
Semantic Guided Single Image Reflection Removal
Jul 30, 2019


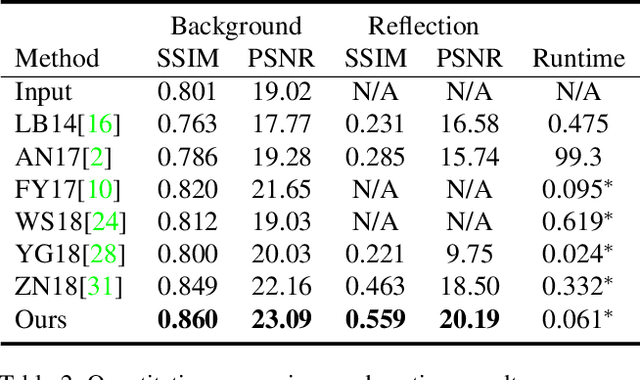
Reflection is common in images capturing scenes behind a glass window, which is not only a disturbance visually but also influence the performance of other computer vision algorithms. Single image reflection removal is an ill-posed problem because the color at each pixel needs to be separated into two values, i.e., the desired clear background and the reflection. To solve it, existing methods propose priors such as smoothness, color consistency. However, the low-level priors are not reliable in complex scenes, for instance, when capturing a real outdoor scene through a window, both the foreground and background contain both smooth and sharp area and a variety of color. In this paper, inspired by the fact that human can separate the two layers easily by recognizing the objects, we use the object semantic as guidance to force the same semantic object belong to the same layer. Extensive experiments on different datasets show that adding the semantic information offers a significant improvement to reflection separation. We also demonstrate the applications of the proposed method to other computer vision tasks.
Dunhuang Grottoes Painting Dataset and Benchmark
Jul 11, 2019



This document introduces the background and the usage of the Dunhuang Grottoes Dataset and the benchmark. The documentation first starts with the background of the Dunhuang Grotto, which is widely recognised as an priceless heritage. Given that digital method is the modern trend for heritage protection and restoration. Follow the trend, we release the first public dataset for Dunhuang Grotto Painting restoration. The rest of the documentation details the painting data generation. To enable a data driven fashion, this dataset provided a large number of training and testing example which is sufficient for a deep learning approach. The detailed usage of the dataset as well as the benchmark is described.
Hybrid Loss for Learning Single-Image-based HDR Reconstruction
Dec 18, 2018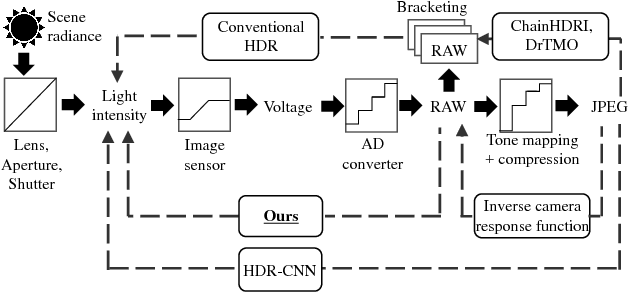
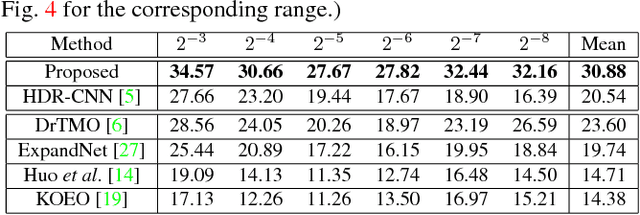
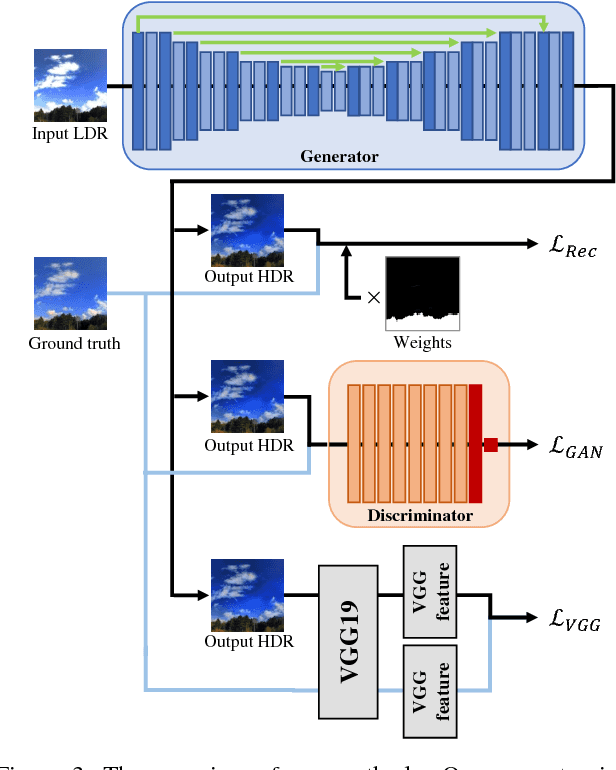
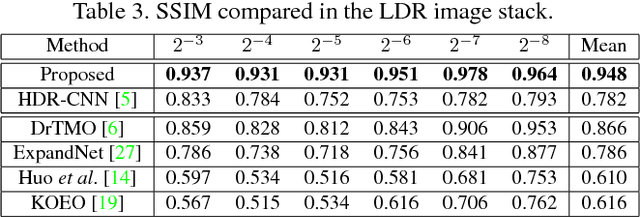
This paper tackles high-dynamic-range (HDR) image reconstruction given only a single low-dynamic-range (LDR) image as input. While the existing methods focus on minimizing the mean-squared-error (MSE) between the target and reconstructed images, we minimize a hybrid loss that consists of perceptual and adversarial losses in addition to HDR-reconstruction loss. The reconstruction loss instead of MSE is more suitable for HDR since it puts more weight on both over- and under- exposed areas. It makes the reconstruction faithful to the input. Perceptual loss enables the networks to utilize knowledge about objects and image structure for recovering the intensity gradients of saturated and grossly quantized areas. Adversarial loss helps to select the most plausible appearance from multiple solutions. The hybrid loss that combines all the three losses is calculated in logarithmic space of image intensity so that the outputs retain a large dynamic range and meanwhile the learning becomes tractable. Comparative experiments conducted with other state-of-the-art methods demonstrated that our method produces a leap in image quality.
Classification-Reconstruction Learning for Open-Set Recognition
Dec 17, 2018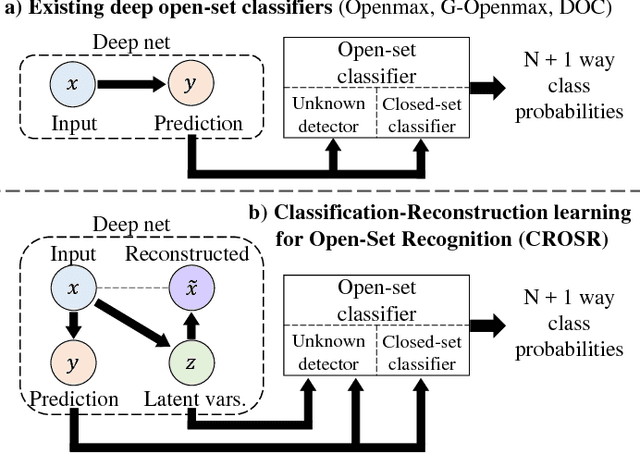
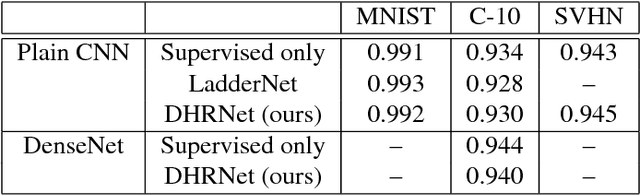
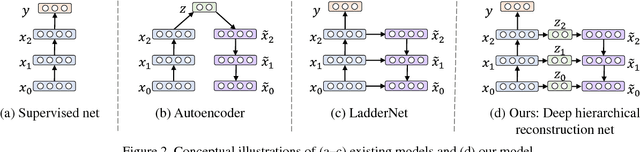
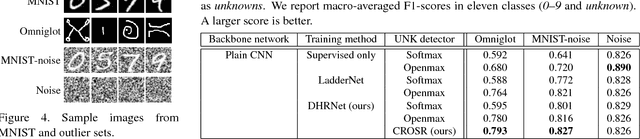
Open-set classification is a problem of handling `unknown' classes that are not contained in the training dataset, whereas traditional classifiers assume that only known classes appear in the test environment. Existing open-set classifiers rely on deep networks trained in a supervised manner on known classes in the training set; this causes specialization of learned representations to known classes and makes it hard to distinguish unknowns from knowns. In contrast, we train networks for joint classification and reconstruction of input data. This enhances the learned representation so as to preserve information useful for separating unknowns from knowns, as well as to discriminate classes of knowns. Our novel Classification-Reconstruction learning for Open-Set Recognition (CROSR) utilizes latent representations for reconstruction and enables robust unknown detection without harming the known-class classification accuracy. Extensive experiments reveal that the proposed method outperforms existing deep open-set classifiers in multiple standard datasets and is robust to diverse outliers.
Loss Guided Activation for Action Recognition in Still Images
Dec 11, 2018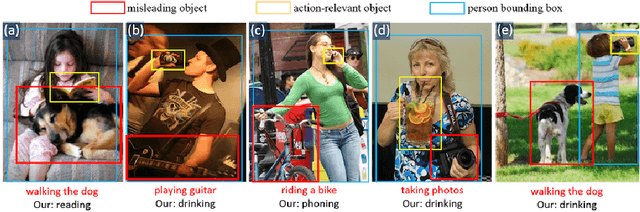

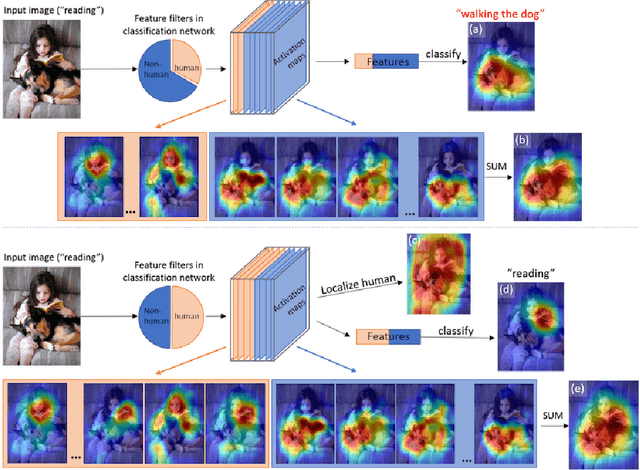

One significant problem of deep-learning based human action recognition is that it can be easily misled by the presence of irrelevant objects or backgrounds. Existing methods commonly address this problem by employing bounding boxes on the target humans as part of the input, in both training and testing stages. This requirement of bounding boxes as part of the input is needed to enable the methods to ignore irrelevant contexts and extract only human features. However, we consider this solution is inefficient, since the bounding boxes might not be available. Hence, instead of using a person bounding box as an input, we introduce a human-mask loss to automatically guide the activations of the feature maps to the target human who is performing the action, and hence suppress the activations of misleading contexts. We propose a multi-task deep learning method that jointly predicts the human action class and human location heatmap. Extensive experiments demonstrate our approach is more robust compared to the baseline methods under the presence of irrelevant misleading contexts. Our method achieves 94.06\% and 40.65\% (in terms of mAP) on Stanford40 and MPII dataset respectively, which are 3.14\% and 12.6\% relative improvements over the best results reported in the literature, and thus set new state-of-the-art results. Additionally, unlike some existing methods, we eliminate the requirement of using a person bounding box as an input during testing.
Detail Preserving Depth Estimation from a Single Image Using Attention Guided Networks
Sep 03, 2018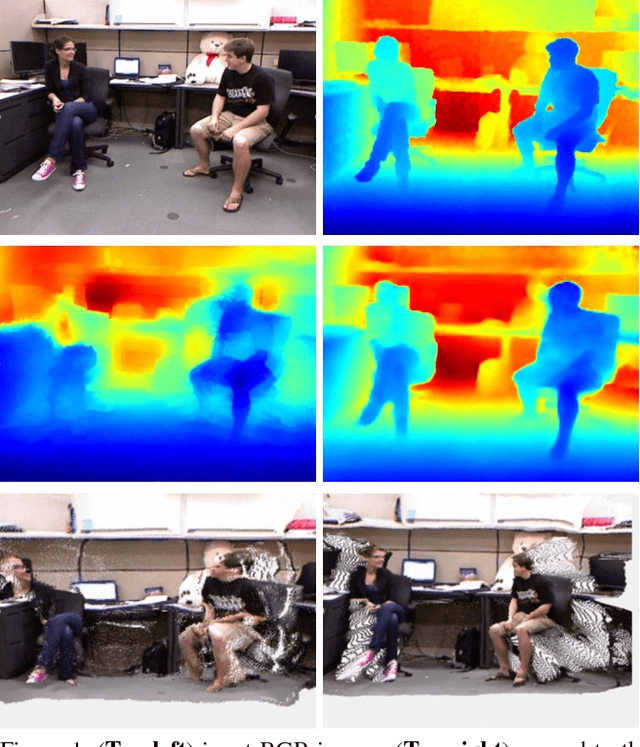
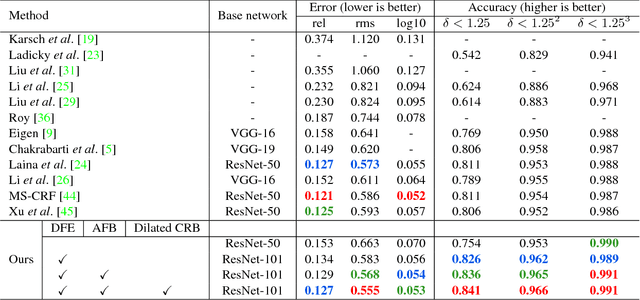
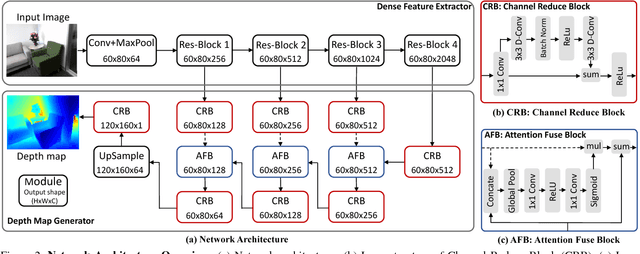
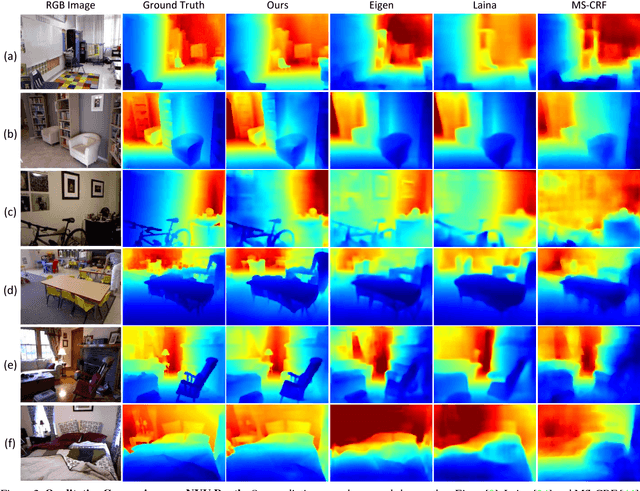
Convolutional Neural Networks have demonstrated superior performance on single image depth estimation in recent years. These works usually use stacked spatial pooling or strided convolution to get high-level information which are common practices in classification task. However, depth estimation is a dense prediction problem and low-resolution feature maps usually generate blurred depth map which is undesirable in application. In order to produce high quality depth map, say clean and accurate, we propose a network consists of a Dense Feature Extractor (DFE) and a Depth Map Generator (DMG). The DFE combines ResNet and dilated convolutions. It extracts multi-scale information from input image while keeping the feature maps dense. As for DMG, we use attention mechanism to fuse multi-scale features produced in DFE. Our Network is trained end-to-end and does not need any post-processing. Hence, it runs fast and can predict depth map in about 15 fps. Experiment results show that our method is competitive with the state-of-the-art in quantitative evaluation, but can preserve better structural details of the scene depth.