 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data Generation for Grammatical Error Correction with Tagged Corruption Models
May 27, 2021
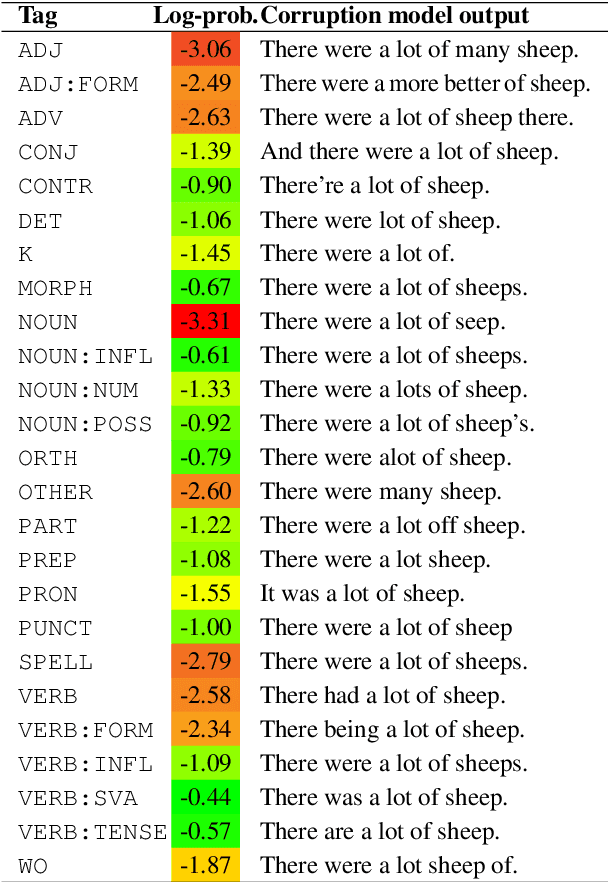
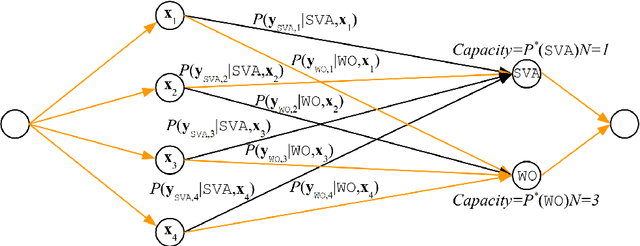

Synthetic data generation is widely known to boost the accuracy of neural grammatical error correction (GEC) systems, but existing methods often lack diversity or are too simplistic to generate the broad range of grammatical errors made by human writers. In this work, we use error type tags from automatic annotation tools such as ERRANT to guide synthetic data generation. We compare several models that can produce an ungrammatical sentence given a clean sentence and an error type tag. We use these models to build a new, large synthetic pre-training data set with error tag frequency distributions matching a given development set. Our synthetic data set yields large and consistent gains, improving the state-of-the-art on the BEA-19 and CoNLL-14 test sets. We also show that our approach is particularly effective in adapting a GEC system, trained on mixed native and non-native English, to a native English test set, even surpassing real training data consisting of high-quality sentence pairs.
Lookup-Table Recurrent Language Models for Long Tail Speech Recognition
Apr 09, 2021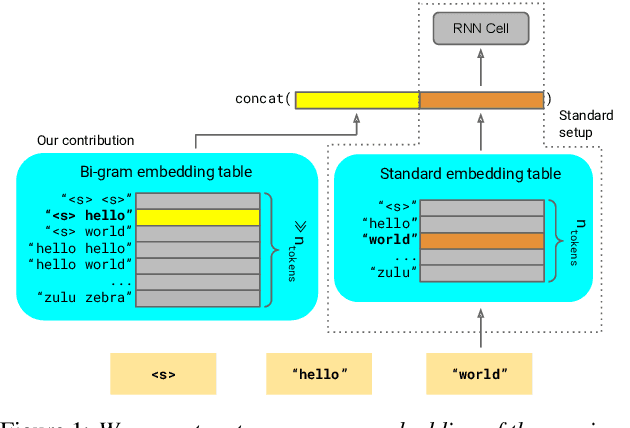
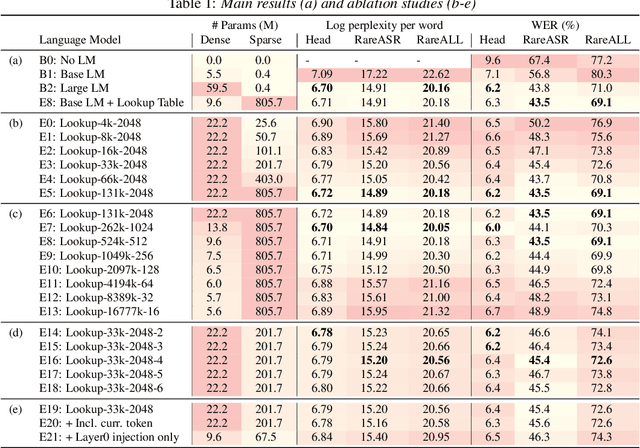
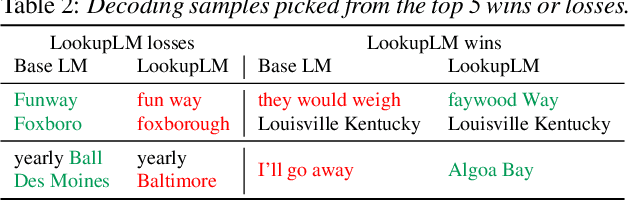

We introduce Lookup-Table Language Models (LookupLM), a method for scaling up the size of RNN language models with only a constant increase in the floating point operations, by increasing the expressivity of the embedding table. In particular, we instantiate an (additional) embedding table which embeds the previous n-gram token sequence, rather than a single token. This allows the embedding table to be scaled up arbitrarily -- with a commensurate increase in performance -- without changing the token vocabulary. Since embeddings are sparsely retrieved from the table via a lookup; increasing the size of the table adds neither extra operations to each forward pass nor extra parameters that need to be stored on limited GPU/TPU memory. We explore scaling n-gram embedding tables up to nearly a billion parameters. When trained on a 3-billion sentence corpus, we find that LookupLM improves long tail log perplexity by 2.44 and long tail WER by 23.4% on a downstream speech recognition task over a standard RNN language model baseline, an improvement comparable to a scaling up the baseline by 6.2x the number of floating point operations.
Seq2Edits: Sequence Transduction Using Span-level Edit Operations
Sep 23, 2020
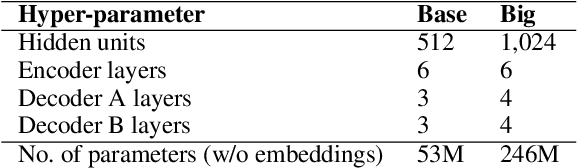
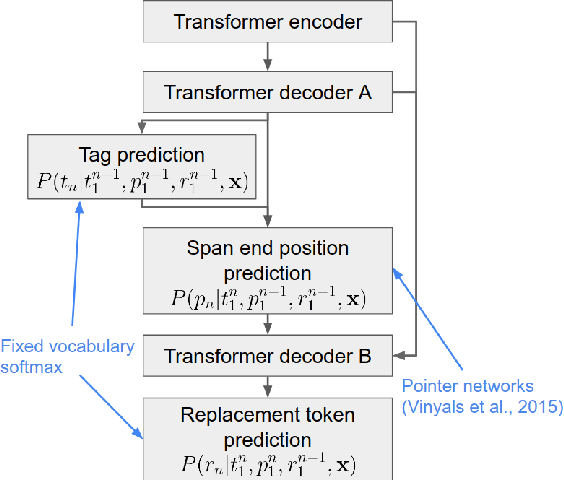
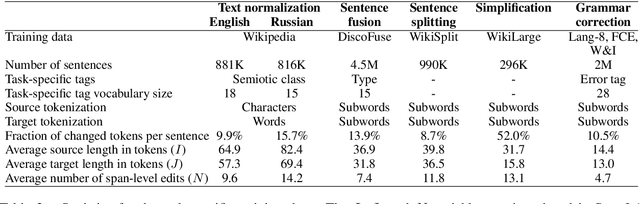
We propose Seq2Edits, an open-vocabulary approach to sequence editing for natural language processing (NLP) tasks with a high degree of overlap between input and output texts. In this approach, each sequence-to-sequence transduction is represented as a sequence of edit operations, where each operation either replaces an entire source span with target tokens or keeps it unchanged. We evaluate our method on five NLP tasks (text normalization, sentence fusion, sentence splitting & rephrasing, text simplification, and grammatical error correction) and report competitive results across the board. For grammatical error correction, our method speeds up inference by up to 5.2x compared to full sequence models because inference time depends on the number of edits rather than the number of target tokens. For text normalization, sentence fusion, and grammatical error correction, our approach improves explainability by associating each edit operation with a human-readable tag.
Data Weighted Training Strategies for Grammatical Error Correction
Sep 09, 2020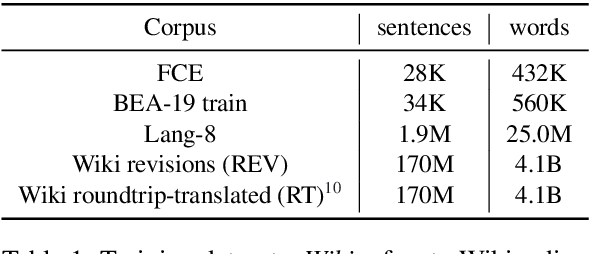
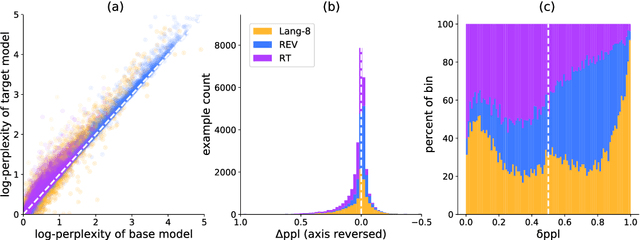
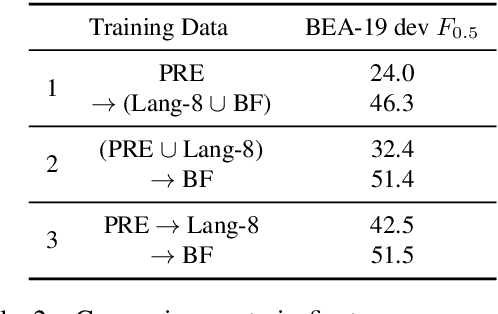
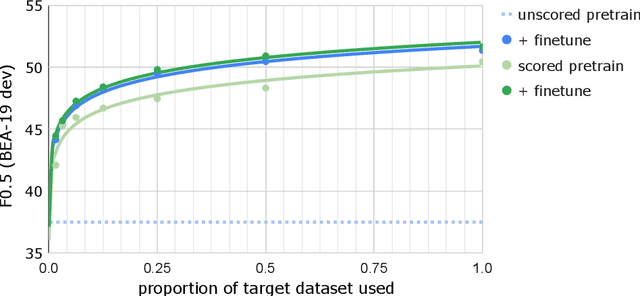
Recent progress in the task of Grammatical Error Correction (GEC) has been driven by addressing data sparsity, both through new methods for generating large and noisy pretraining data and through the publication of small and higher-quality finetuning data in the BEA-2019 shared task. Building upon recent work in Neural Machine Translation (NMT), we make use of both kinds of data by deriving example-level scores on our large pretraining data based on a smaller, higher-quality dataset. In this work, we perform an empirical study to discover how to best incorporate delta-log-perplexity, a type of example scoring, into a training schedule for GEC. In doing so, we perform experiments that shed light on the function and applicability of delta-log-perplexity. Models trained on scored data achieve state-of-the-art results on common GEC test sets.
Improving Tail Performance of a Deliberation E2E ASR Model Using a Large Text Corpus
Aug 25, 2020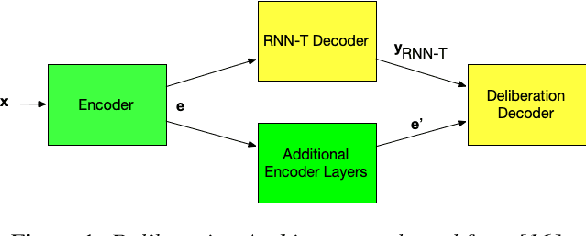
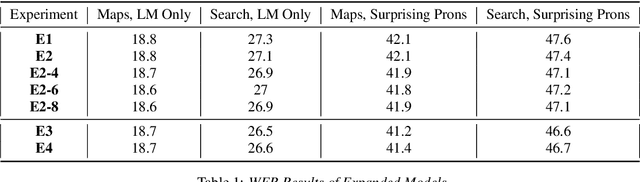
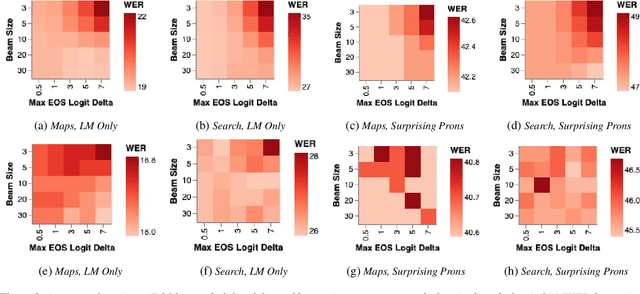
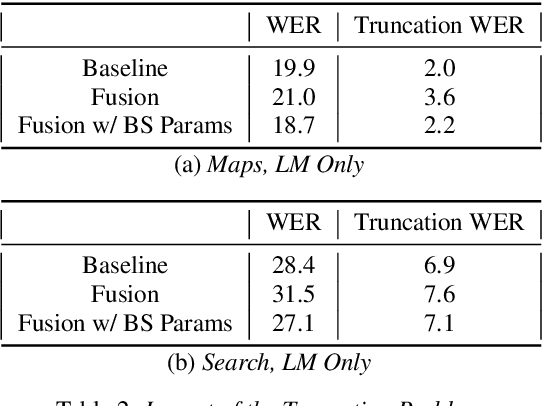
End-to-end (E2E) automatic speech recognition (ASR) systems lack the distinct language model (LM) component that characterizes traditional speech systems. While this simplifies the model architecture, it complicates the task of incorporating text-only data into training, which is important to the recognition of tail words that do not occur often in audio-text pairs. While shallow fusion has been proposed as a method for incorporating a pre-trained LM into an E2E model at inference time, it has not yet been explored for very large text corpora, and it has been shown to be very sensitive to hyperparameter settings in the beam search. In this work, we apply shallow fusion to incorporate a very large text corpus into a state-of-the-art E2EASR model. We explore the impact of model size and show that intelligent pruning of the training set can be more effective than increasing the parameter count. Additionally, we show that incorporating the LM in minimum word error rate (MWER) fine tuning makes shallow fusion far less dependent on optimal hyperparameter settings, reducing the difficulty of that tuning problem.
Transformer Transducer: A Streamable Speech Recognition Model with Transformer Encoders and RNN-T Loss
Feb 14, 2020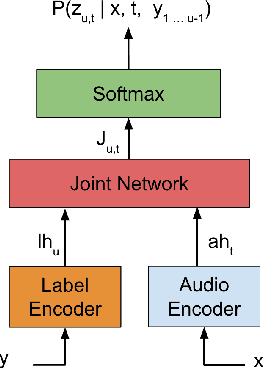

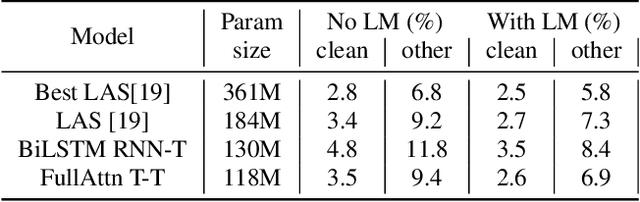
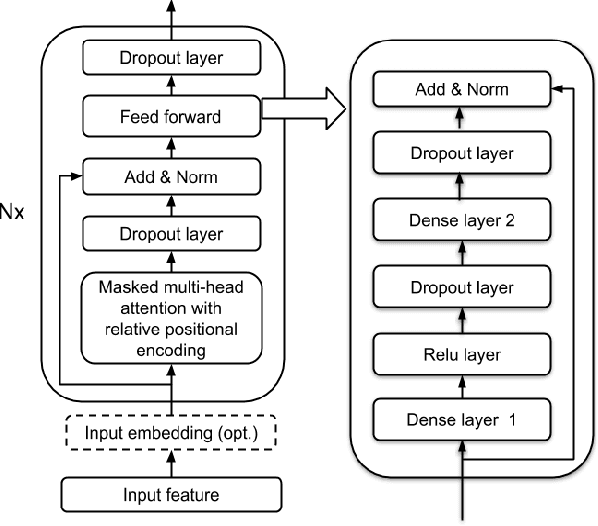
In this paper we present an end-to-end speech recognition model with Transformer encoders that can be used in a streaming speech recognition system. Transformer computation blocks based on self-attention are used to encode both audio and label sequences independently. The activations from both audio and label encoders are combined with a feed-forward layer to compute a probability distribution over the label space for every combination of acoustic frame position and label history. This is similar to the Recurrent Neural Network Transducer (RNN-T) model, which uses RNNs for information encoding instead of Transformer encoders. The model is trained with the RNN-T loss well-suited to streaming decoding. We present results on the LibriSpeech dataset showing that limiting the left context for self-attention in the Transformer layers makes decoding computationally tractable for streaming, with only a slight degradation in accuracy. We also show that the full attention version of our model beats the-state-of-the art accuracy on the LibriSpeech benchmarks. Our results also show that we can bridge the gap between full attention and limited attention versions of our model by attending to a limited number of future frames.
Corpora Generation for Grammatical Error Correction
Apr 10, 2019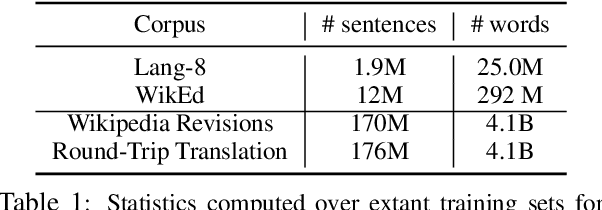
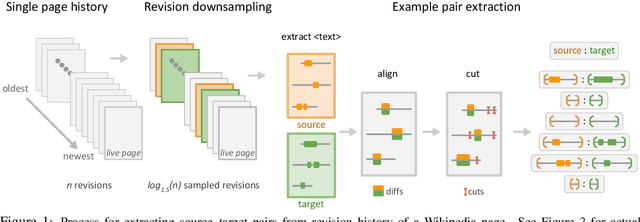
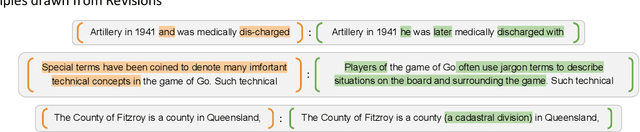

Grammatical Error Correction (GEC) has been recently modeled using the sequence-to-sequence framework. However, unlike sequence transduction problems such as machine translation, GEC suffers from the lack of plentiful parallel data. We describe two approaches for generating large parallel datasets for GEC using publicly available Wikipedia data. The first method extracts source-target pairs from Wikipedia edit histories with minimal filtration heuristics, while the second method introduces noise into Wikipedia sentences via round-trip translation through bridge languages. Both strategies yield similar sized parallel corpora containing around 4B tokens. We employ an iterative decoding strategy that is tailored to the loosely supervised nature of our constructed corpora. We demonstrate that neural GEC models trained using either type of corpora give similar performance. Fine-tuning these models on the Lang-8 corpus and ensembling allows us to surpass the state of the art on both the CoNLL-2014 benchmark and the JFLEG task. We provide systematic analysis that compares the two approaches to data generation and highlights the effectiveness of ensembling.
Neural Language Modeling with Visual Features
Mar 07, 2019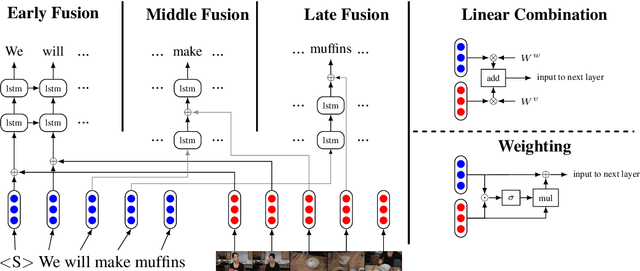
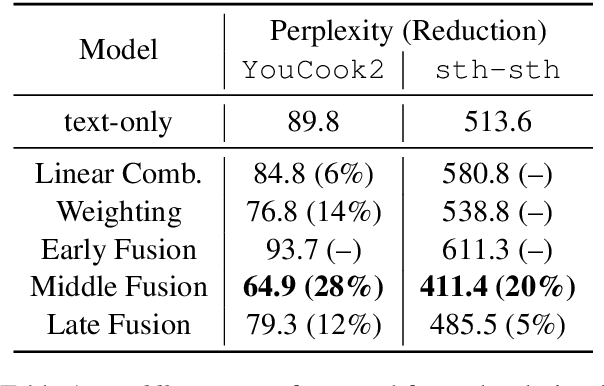
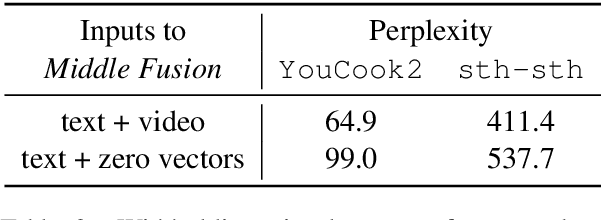
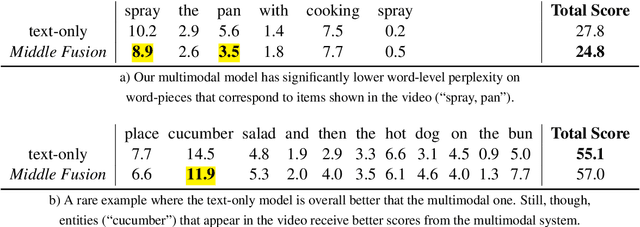
Multimodal language models attempt to incorporate non-linguistic features for the language modeling task. In this work, we extend a standard recurrent neural network (RNN) language model with features derived from videos. We train our models on data that is two orders-of-magnitude bigger than datasets used in prior work. We perform a thorough exploration of model architectures for combining visual and text features. Our experiments on two corpora (YouCookII and 20bn-something-something-v2) show that the best performing architecture consists of middle fusion of visual and text features, yielding over 25% relative improvement in perplexity. We report analysis that provides insights into why our multimodal language model improves upon a standard RNN language model.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Weakly Supervised Grammatical Error Correction using Iterative Decoding
Oct 31, 2018
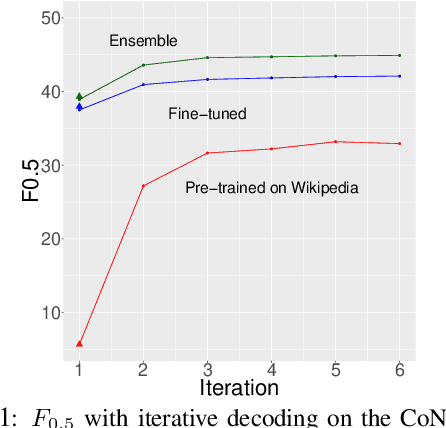
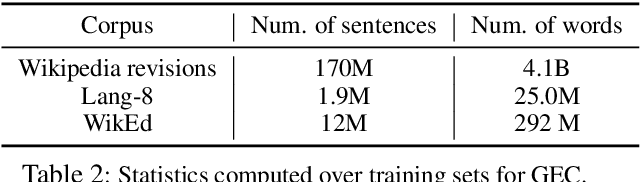

We describe an approach to Grammatical Error Correction (GEC) that is effective at making use of models trained on large amounts of weakly supervised bitext. We train the Transformer sequence-to-sequence model on 4B tokens of Wikipedia revisions and employ an iterative decoding strategy that is tailored to the loosely-supervised nature of the Wikipedia training corpus. Finetuning on the Lang-8 corpus and ensembling yields an F0.5 of 58.3 on the CoNLL'14 benchmark and a GLEU of 62.4 on JFLEG. The combination of weakly supervised training and iterative decoding obtains an F0.5 of 48.2 on CoNLL'14 even without using any labeled GEC data.