 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the 3D Fauna of the Web
Jan 04, 2024Learning 3D models of all animals on the Earth requires massively scaling up existing solutions. With this ultimate goal in mind, we develop 3D-Fauna, an approach that learns a pan-category deformable 3D animal model for more than 100 animal species jointly. One crucial bottleneck of modeling animals is the limited availability of training data, which we overcome by simply learning from 2D Internet images. We show that prior category-specific attempts fail to generalize to rare species with limited training images. We address this challenge by introducing the Semantic Bank of Skinned Models (SBSM), which automatically discovers a small set of base animal shapes by combining geometric inductive priors with semantic knowledge implicitly captured by an off-the-shelf self-supervised feature extractor. To train such a model, we also contribute a new large-scale dataset of diverse animal species. At inference time, given a single image of any quadruped animal, our model reconstructs an articulated 3D mesh in a feed-forward fashion within seconds.
Ponymation: Learning 3D Animal Motions from Unlabeled Online Videos
Dec 21, 2023We introduce Ponymation, a new method for learning a generative model of articulated 3D animal motions from raw, unlabeled online videos. Unlike existing approaches for motion synthesis, our model does not require any pose annotations or parametric shape models for training, and is learned purely from a collection of raw video clips obtained from the Internet. We build upon a recent work, MagicPony, which learns articulated 3D animal shapes purely from single image collections, and extend it on two fronts. First, instead of training on static images, we augment the framework with a video training pipeline that incorporates temporal regularizations, achieving more accurate and temporally consistent reconstructions. Second, we learn a generative model of the underlying articulated 3D motion sequences via a spatio-temporal transformer VAE, simply using 2D reconstruction losses without relying on any explicit pose annotations. At inference time, given a single 2D image of a new animal instance, our model reconstructs an articulated, textured 3D mesh, and generates plausible 3D animations by sampling from the learned motion latent space.
Language-Informed Visual Concept Learning
Dec 06, 2023Our understanding of the visual world is centered around various concept axes, characterizing different aspects of visual entities. While different concept axes can be easily specified by language, e.g. color, the exact visual nuances along each axis often exceed the limitations of linguistic articulations, e.g. a particular style of painting. In this work, our goal is to learn a language-informed visual concept representation, by simply distilling large pre-trained vision-language models. Specifically, we train a set of concept encoders to encode the information pertinent to a set of language-informed concept axes, with an objective of reproducing the input image through a pre-trained Text-to-Image (T2I) model. To encourage better disentanglement of different concept encoders, we anchor the concept embeddings to a set of text embeddings obtained from a pre-trained Visual Question Answering (VQA) model. At inference time, the model extracts concept embeddings along various axes from new test images, which can be remixed to generate images with novel compositions of visual concepts. With a lightweight test-time finetuning procedure, it can also generalize to novel concepts unseen at training.
Stanford-ORB: A Real-World 3D Object Inverse Rendering Benchmark
Oct 25, 2023



We introduce Stanford-ORB, a new real-world 3D Object inverse Rendering Benchmark. Recent advances in inverse rendering have enabled a wide range of real-world applications in 3D content generation, moving rapidly from research and commercial use cases to consumer devices. While the results continue to improve, there is no real-world benchmark that can quantitatively assess and compare the performance of various inverse rendering methods. Existing real-world datasets typically only consist of the shape and multi-view images of objects, which are not sufficient for evaluating the quality of material recovery and object relighting. Methods capable of recovering material and lighting often resort to synthetic data for quantitative evaluation, which on the other hand does not guarantee generalization to complex real-world environments. We introduce a new dataset of real-world objects captured under a variety of natural scenes with ground-truth 3D scans, multi-view images, and environment lighting. Using this dataset, we establish the first comprehensive real-world evaluation benchmark for object inverse rendering tasks from in-the-wild scenes, and compare the performance of various existing methods.
Farm3D: Learning Articulated 3D Animals by Distilling 2D Diffusion
Apr 20, 2023We present Farm3D, a method to learn category-specific 3D reconstructors for articulated objects entirely from "free" virtual supervision from a pre-trained 2D diffusion-based image generator. Recent approaches can learn, given a collection of single-view images of an object category, a monocular network to predict the 3D shape, albedo, illumination and viewpoint of any object occurrence. We propose a framework using an image generator like Stable Diffusion to generate virtual training data for learning such a reconstruction network from scratch. Furthermore, we include the diffusion model as a score to further improve learning. The idea is to randomise some aspects of the reconstruction, such as viewpoint and illumination, generating synthetic views of the reconstructed 3D object, and have the 2D network assess the quality of the resulting image, providing feedback to the reconstructor. Different from work based on distillation which produces a single 3D asset for each textual prompt in hours, our approach produces a monocular reconstruction network that can output a controllable 3D asset from a given image, real or generated, in only seconds. Our network can be used for analysis, including monocular reconstruction, or for synthesis, generating articulated assets for real-time applications such as video games.
Seeing a Rose in Five Thousand Ways
Dec 09, 2022What is a rose, visually? A rose comprises its intrinsics, including the distribution of geometry, texture, and material specific to its object category. With knowledge of these intrinsic properties, we may render roses of different sizes and shapes, in different poses, and under different lighting conditions. In this work, we build a generative model that learns to capture such object intrinsics from a single image, such as a photo of a bouquet. Such an image includes multiple instances of an object type. These instances all share the same intrinsics, but appear different due to a combination of variance within these intrinsics and differences in extrinsic factors, such as pose and illumination. Experiments show that our model successfully learns object intrinsics (distribution of geometry, texture, and material) for a wide range of objects, each from a single Internet image. Our method achieves superior results on multiple downstream tasks, including intrinsic image decomposition, shape and image generation, view synthesis, and relighting.
CGOF++: Controllable 3D Face Synthesis with Conditional Generative Occupancy Fields
Nov 23, 2022



Capitalizing on the recent advances in image generation models, existing controllable face image synthesis methods are able to generate high-fidelity images with some levels of controllability, e.g., controlling the shapes, expressions, textures, and poses of the generated face images. However, previous methods focus on controllable 2D image generative models, which are prone to producing inconsistent face images under large expression and pose changes. In this paper, we propose a new NeRF-based conditional 3D face synthesis framework, which enables 3D controllability over the generated face images by imposing explicit 3D conditions from 3D face priors. At its core is a conditional Generative Occupancy Field (cGOF++) that effectively enforces the shape of the generated face to conform to a given 3D Morphable Model (3DMM) mesh, built on top of EG3D [1], a recent tri-plane-based generative model. To achieve accurate control over fine-grained 3D face shapes of the synthesized images, we additionally incorporate a 3D landmark loss as well as a volume warping loss into our synthesis framework. Experiments validate the effectiveness of the proposed method, which is able to generate high-fidelity face images and shows more precise 3D controllability than state-of-the-art 2D-based controllable face synthesis methods.
MagicPony: Learning Articulated 3D Animals in the Wild
Nov 22, 2022We consider the problem of learning a function that can estimate the 3D shape, articulation, viewpoint, texture, and lighting of an articulated animal like a horse, given a single test image. We present a new method, dubbed MagicPony, that learns this function purely from in-the-wild single-view images of the object category, with minimal assumptions about the topology of deformation. At its core is an implicit-explicit representation of articulated shape and appearance, combining the strengths of neural fields and meshes. In order to help the model understand an object's shape and pose, we distil the knowledge captured by an off-the-shelf self-supervised vision transformer and fuse it into the 3D model. To overcome common local optima in viewpoint estimation, we further introduce a new viewpoint sampling scheme that comes at no added training cost. Compared to prior works, we show significant quantitative and qualitative improvements on this challenging task. The model also demonstrates excellent generalisation in reconstructing abstract drawings and artefacts, despite the fact that it is only trained on real images.
ONeRF: Unsupervised 3D Object Segmentation from Multiple Views
Nov 22, 2022We present ONeRF, a method that automatically segments and reconstructs object instances in 3D from multi-view RGB images without any additional manual annotations. The segmented 3D objects are represented using separate Neural Radiance Fields (NeRFs) which allow for various 3D scene editing and novel view rendering. At the core of our method is an unsupervised approach using the iterative Expectation-Maximization algorithm, which effectively aggregates 2D visual features and the corresponding 3D cues from multi-views for joint 3D object segmentation and reconstruction. Unlike existing approaches that can only handle simple objects, our method produces segmented full 3D NeRFs of individual objects with complex shapes, topologies and appearance. The segmented ONeRfs enable a range of 3D scene editing, such as object transformation, insertion and deletion.
Controllable 3D Face Synthesis with Conditional Generative Occupancy Fields
Jun 16, 2022
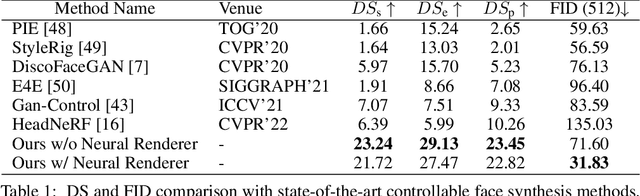
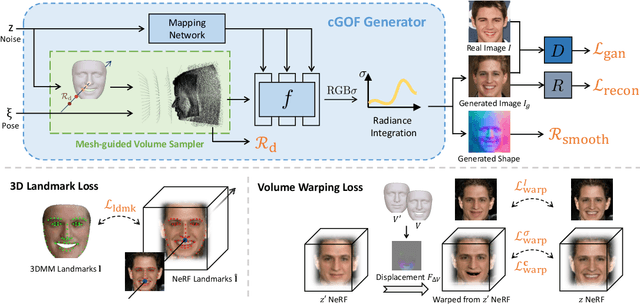
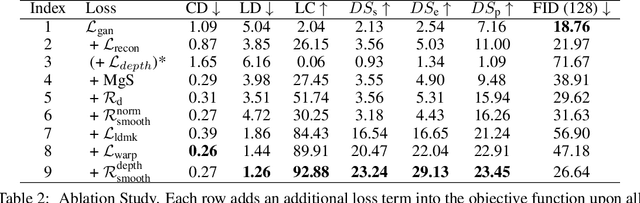
Capitalizing on the recent advances in image generation models, existing controllable face image synthesis methods are able to generate high-fidelity images with some levels of controllability, e.g., controlling the shapes, expressions, textures, and poses of the generated face images. However, these methods focus on 2D image generative models, which are prone to producing inconsistent face images under large expression and pose changes. In this paper, we propose a new NeRF-based conditional 3D face synthesis framework, which enables 3D controllability over the generated face images by imposing explicit 3D conditions from 3D face priors. At its core is a conditional Generative Occupancy Field (cGOF) that effectively enforces the shape of the generated face to commit to a given 3D Morphable Model (3DMM) mesh. To achieve accurate control over fine-grained 3D face shapes of the synthesized image, we additionally incorporate a 3D landmark loss as well as a volume warping loss into our synthesis algorithm. Experiments validate the effectiveness of the proposed method, which is able to generate high-fidelity face images and shows more precise 3D controllability than state-of-the-art 2D-based controllable face synthesis methods. Find code and demo at https://keqiangsun.github.io/projects/cgof.