 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPI 2023 Challenge on RGBW Fusion: Methods and Results
Apr 24, 2023



Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for an in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). With the success of the 1st MIPI Workshop@ECCV 2022, we introduce the second MIPI challenge, including four tracks focusing on novel image sensors and imaging algorithms. This paper summarizes and reviews the RGBW Joint Fusion and Denoise track on MIPI 2023. In total, 69 participants were successfully registered, and 4 teams submitted results in the final testing phase. The final results are evaluated using objective metrics, including PSNR, SSIM, LPIPS, and KLD. A detailed description of the top three models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023/.
MIPI 2023 Challenge on RGBW Remosaic: Methods and Results
Apr 20, 2023



Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for an in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). With the success of the 1st MIPI Workshop@ECCV 2022, we introduce the second MIPI challenge, including four tracks focusing on novel image sensors and imaging algorithms. This paper summarizes and reviews the RGBW Joint Remosaic and Denoise track on MIPI 2023. In total, 81 participants were successfully registered, and 4 teams submitted results in the final testing phase. The final results are evaluated using objective metrics, including PSNR, SSIM, LPIPS, and KLD. A detailed description of the top three models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2023/.
Iterative Prompt Learning for Unsupervised Backlit Image Enhancement
Mar 30, 2023We propose a novel unsupervised backlit image enhancement method, abbreviated as CLIP-LIT, by exploring the potential of Contrastive Language-Image Pre-Training (CLIP) for pixel-level image enhancement. We show that the open-world CLIP prior not only aids in distinguishing between backlit and well-lit images, but also in perceiving heterogeneous regions with different luminance, facilitating the optimization of the enhancement network. Unlike high-level and image manipulation tasks, directly applying CLIP to enhancement tasks is non-trivial, owing to the difficulty in finding accurate prompts. To solve this issue, we devise a prompt learning framework that first learns an initial prompt pair by constraining the text-image similarity between the prompt (negative/positive sample) and the corresponding image (backlit image/well-lit image) in the CLIP latent space. Then, we train the enhancement network based on the text-image similarity between the enhanced result and the initial prompt pair. To further improve the accuracy of the initial prompt pair, we iteratively fine-tune the prompt learning framework to reduce the distribution gaps between the backlit images, enhanced results, and well-lit images via rank learning, boosting the enhancement performance. Our method alternates between updating the prompt learning framework and enhancement network until visually pleasing results are achieved. Extensive experiments demonstrate that our method outperforms state-of-the-art methods in terms of visual quality and generalization ability, without requiring any paired data.
Nighttime Smartphone Reflective Flare Removal Using Optical Center Symmetry Prior
Mar 27, 2023



Reflective flare is a phenomenon that occurs when light reflects inside lenses, causing bright spots or a "ghosting effect" in photos, which can impact their quality. Eliminating reflective flare is highly desirable but challenging. Many existing methods rely on manually designed features to detect these bright spots, but they often fail to identify reflective flares created by various types of light and may even mistakenly remove the light sources in scenarios with multiple light sources. To address these challenges, we propose an optical center symmetry prior, which suggests that the reflective flare and light source are always symmetrical around the lens's optical center. This prior helps to locate the reflective flare's proposal region more accurately and can be applied to most smartphone cameras. Building on this prior, we create the first reflective flare removal dataset called BracketFlare, which contains diverse and realistic reflective flare patterns. We use continuous bracketing to capture the reflective flare pattern in the underexposed image and combine it with a normally exposed image to synthesize a pair of flare-corrupted and flare-free images. With the dataset, neural networks can be trained to remove the reflective flares effectively. Extensive experiments demonstrate the effectiveness of our method on both synthetic and real-world datasets.
Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement
Feb 23, 2023Ultra-High-Definition (UHD) photo has gradually become the standard configuration in advanced imaging devices. The new standard unveils many issues in existing approaches for low-light image enhancement (LLIE), especially in dealing with the intricate issue of joint luminance enhancement and noise removal while remaining efficient. Unlike existing methods that address the problem in the spatial domain, we propose a new solution, UHDFour, that embeds Fourier transform into a cascaded network. Our approach is motivated by a few unique characteristics in the Fourier domain: 1) most luminance information concentrates on amplitudes while noise is closely related to phases, and 2) a high-resolution image and its low-resolution version share similar amplitude patterns.Through embedding Fourier into our network, the amplitude and phase of a low-light image are separately processed to avoid amplifying noise when enhancing luminance. Besides, UHDFour is scalable to UHD images by implementing amplitude and phase enhancement under the low-resolution regime and then adjusting the high-resolution scale with few computations. We also contribute the first real UHD LLIE dataset, \textbf{UHD-LL}, that contains 2,150 low-noise/normal-clear 4K image pairs with diverse darkness and noise levels captured in different scenarios. With this dataset, we systematically analyze the performance of existing LLIE methods for processing UHD images and demonstrate the advantage of our solution. We believe our new framework, coupled with the dataset, would push the frontier of LLIE towards UHD. The code and dataset are available at https://li-chongyi.github.io/UHDFour.
* Porject page: https://li-chongyi.github.io/UHDFour
Deep Dynamic Scene Deblurring from Optical Flow
Jan 18, 2023



Deblurring can not only provide visually more pleasant pictures and make photography more convenient, but also can improve the performance of objection detection as well as tracking. However, removing dynamic scene blur from images is a non-trivial task as it is difficult to model the non-uniform blur mathematically. Several methods first use single or multiple images to estimate optical flow (which is treated as an approximation of blur kernels) and then adopt non-blind deblurring algorithms to reconstruct the sharp images. However, these methods cannot be trained in an end-to-end manner and are usually computationally expensive. In this paper, we explore optical flow to remove dynamic scene blur by using the multi-scale spatially variant recurrent neural network (RNN). We utilize FlowNets to estimate optical flow from two consecutive images in different scales. The estimated optical flow provides the RNN weights in different scales so that the weights can better help RNNs to remove blur in the feature spaces. Finally, we develop a convolutional neural network (CNN) to restore the sharp images from the deblurred features. Both quantitative and qualitative evaluations on the benchmark datasets demonstrate that the proposed method performs favorably against state-of-the-art algorithms in terms of accuracy, speed, and model size.
Learning Dual Memory Dictionaries for Blind Face Restoration
Oct 15, 2022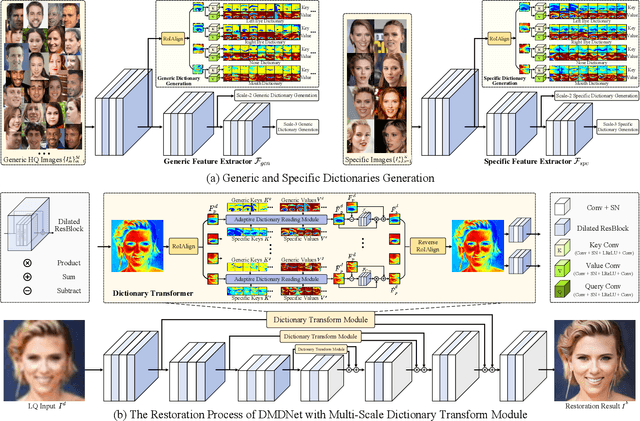
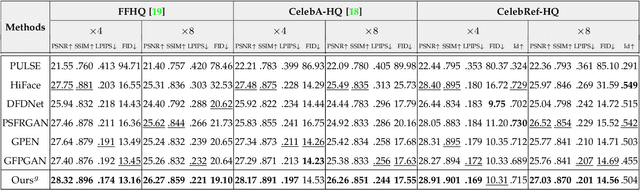
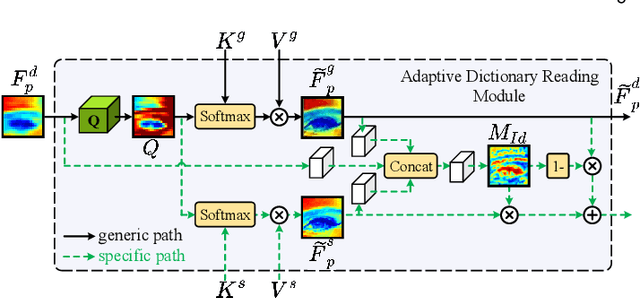
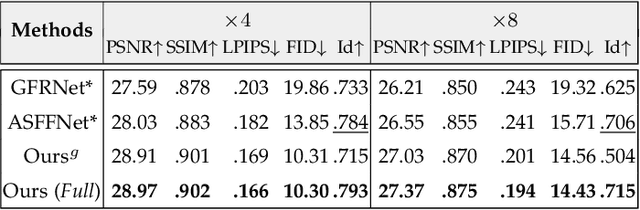
To improve the performance of blind face restoration, recent works mainly treat the two aspects, i.e., generic and specific restoration, separately. In particular, generic restoration attempts to restore the results through general facial structure prior, while on the one hand, cannot generalize to real-world degraded observations due to the limited capability of direct CNNs' mappings in learning blind restoration, and on the other hand, fails to exploit the identity-specific details. On the contrary, specific restoration aims to incorporate the identity features from the reference of the same identity, in which the requirement of proper reference severely limits the application scenarios. Generally, it is a challenging and intractable task to improve the photo-realistic performance of blind restoration and adaptively handle the generic and specific restoration scenarios with a single unified model. Instead of implicitly learning the mapping from a low-quality image to its high-quality counterpart, this paper suggests a DMDNet by explicitly memorizing the generic and specific features through dual dictionaries. First, the generic dictionary learns the general facial priors from high-quality images of any identity, while the specific dictionary stores the identity-belonging features for each person individually. Second, to handle the degraded input with or without specific reference, dictionary transform module is suggested to read the relevant details from the dual dictionaries which are subsequently fused into the input features. Finally, multi-scale dictionaries are leveraged to benefit the coarse-to-fine restoration. Moreover, a new high-quality dataset, termed CelebRef-HQ, is constructed to promote the exploration of specific face restoration in the high-resolution space.
Flare7K: A Phenomenological Nighttime Flare Removal Dataset
Oct 12, 2022
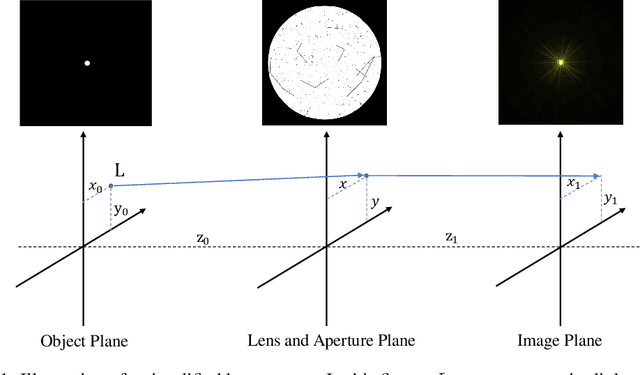

Artificial lights commonly leave strong lens flare artifacts on images captured at night. Nighttime flare not only affects the visual quality but also degrades the performance of vision algorithms. Existing flare removal methods mainly focus on removing daytime flares and fail in nighttime. Nighttime flare removal is challenging because of the unique luminance and spectrum of artificial lights and the diverse patterns and image degradation of the flares captured at night. The scarcity of nighttime flare removal datasets limits the research on this crucial task. In this paper, we introduce, Flare7K, the first nighttime flare removal dataset, which is generated based on the observation and statistics of real-world nighttime lens flares. It offers 5,000 scattering and 2,000 reflective flare images, consisting of 25 types of scattering flares and 10 types of reflective flares. The 7,000 flare patterns can be randomly added to flare-free images, forming the flare-corrupted and flare-free image pairs. With the paired data, we can train deep models to restore flare-corrupted images taken in the real world effectively. Apart from abundant flare patterns, we also provide rich annotations, including the labeling of light source, glare with shimmer, reflective flare, and streak, which are commonly absent from existing datasets. Hence, our dataset can facilitate new work in nighttime flare removal and more fine-grained analysis of flare patterns. Extensive experiments show that our dataset adds diversity to existing flare datasets and pushes the frontier of nighttime flare removal.
MIPI 2022 Challenge on RGBW Sensor Fusion: Dataset and Report
Sep 27, 2022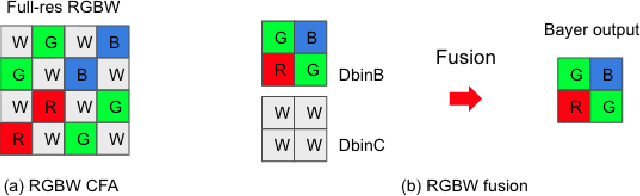
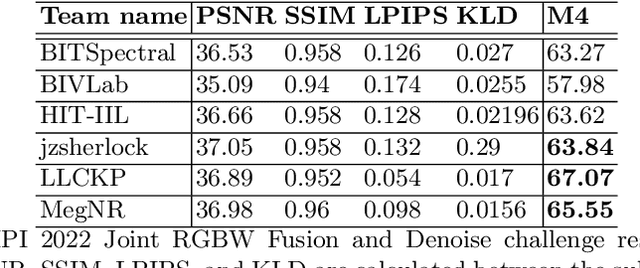


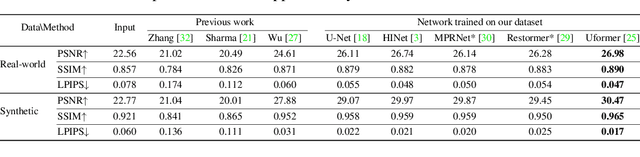
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge, including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGBW Joint Fusion and Denoise, one of the five tracks, working on the fusion of binning-mode RGBW to Bayer, is introduced. The participants were provided with a new dataset including 70 (training) and 15 (validation) scenes of high-quality RGBW and Bayer pairs. In addition, for each scene, RGBW of different noise levels was provided at 24dB and 42dB. All the data were captured using an RGBW sensor in both outdoor and indoor conditions. The final results are evaluated using objective metrics, including PSNR, SSIM}, LPIPS, and KLD. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
MIPI 2022 Challenge on RGBW Sensor Re-mosaic: Dataset and Report
Sep 15, 2022


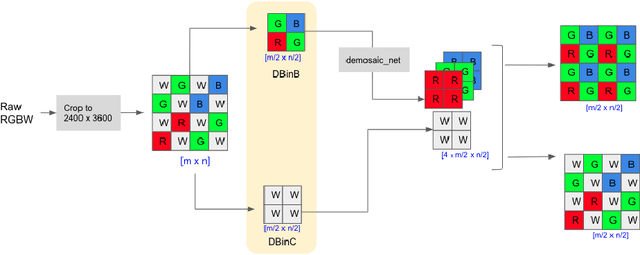
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge including five tracks focusing on novel image sensors and imaging algorithms. In this paper, RGBW Joint Remosaic and Denoise, one of the five tracks, working on the interpolation of RGBW CFA to Bayer at full resolution, is introduced. The participants were provided with a new dataset including 70 (training) and 15 (validation) scenes of high-quality RGBW and Bayer pairs. In addition, for each scene, RGBW of different noise levels was provided at 0dB, 24dB, and 42dB. All the data were captured using an RGBW sensor in both outdoor and indoor conditions. The final results are evaluated using objective metrics including PSNR, SSIM, LPIPS, and KLD. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.