 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Knowledge Representation with Meta Knowledge Distillation for Single Image Super-Resolution
Jul 18, 2022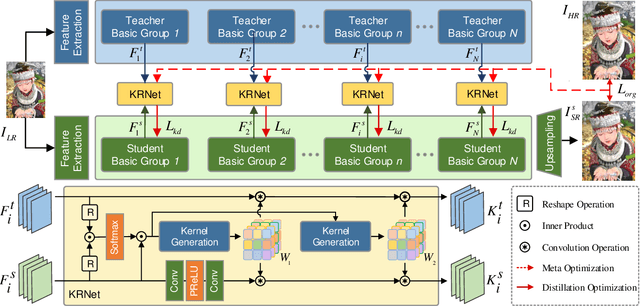
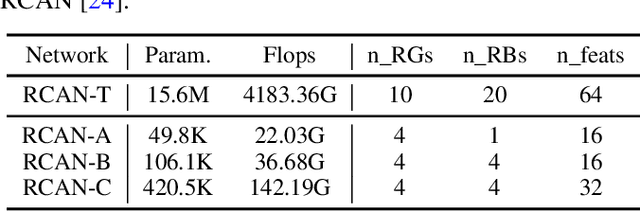
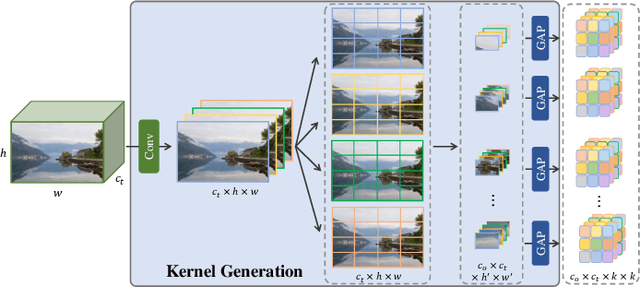
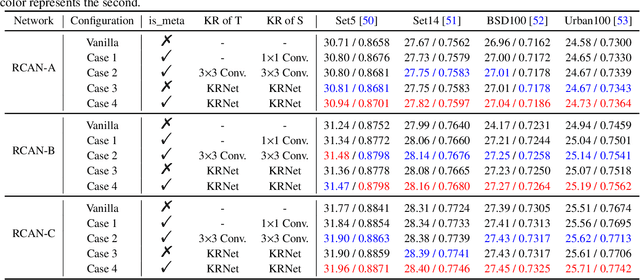
Knowledge distillation (KD), which can efficiently transfer knowledge from a cumbersome network (teacher) to a compact network (student), has demonstrated its advantages in some computer vision applications. The representation of knowledge is vital for knowledge transferring and student learning, which is generally defined in hand-crafted manners or uses the intermediate features directly. In this paper, we propose a model-agnostic meta knowledge distillation method under the teacher-student architecture for the single image super-resolution task. It provides a more flexible and accurate way to help the teachers transmit knowledge in accordance with the abilities of students via knowledge representation networks (KRNets) with learnable parameters. In order to improve the perception ability of knowledge representation to students' requirements, we propose to solve the transformation process from intermediate outputs to transferred knowledge by employing the student features and the correlation between teacher and student in the KRNets. Specifically, the texture-aware dynamic kernels are generated and then extract texture features to be improved and the corresponding teacher guidance so as to decompose the distillation problem into texture-wise supervision for further promoting the recovery quality of high-frequency details. In addition, the KRNets are optimized in a meta-learning manner to ensure the knowledge transferring and the student learning are beneficial to improving the reconstructed quality of the student. Experiments conducted on various single image super-resolution datasets demonstrate that our proposed method outperforms existing defined knowledge representation related distillation methods, and can help super-resolution algorithms achieve better reconstruction quality without introducing any inference complexity.
FAIVConf: Face enhancement for AI-based Video Conference with Low Bit-rate
Jul 08, 2022
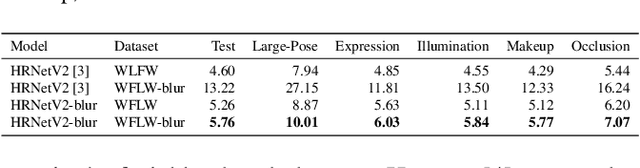
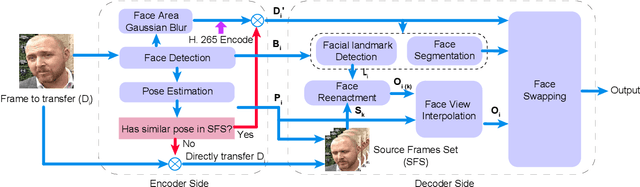
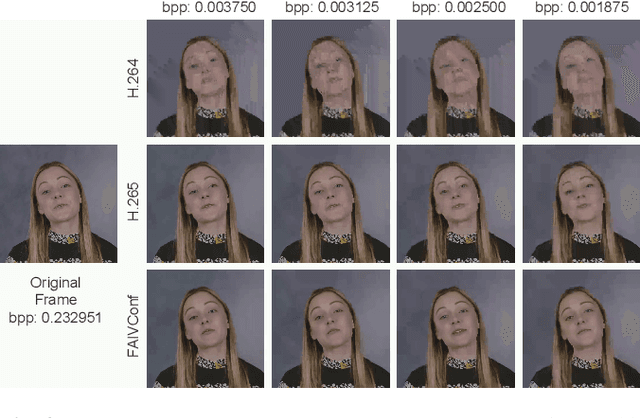
Recently, high-quality video conferencing with fewer transmission bits has become a very hot and challenging problem. We propose FAIVConf, a specially designed video compression framework for video conferencing, based on the effective neural human face generation techniques. FAIVConf brings together several designs to improve the system robustness in real video conference scenarios: face-swapping to avoid artifacts in background animation; facial blurring to decrease transmission bit-rate and maintain the quality of extracted facial landmarks; and dynamic source update for face view interpolation to accommodate a large range of head poses. Our method achieves a significant bit-rate reduction in the video conference and gives much better visual quality under the same bit-rate compared with H.264 and H.265 coding schemes.
Coarse-to-fine Deep Video Coding with Hyperprior-guided Mode Prediction
Jun 15, 2022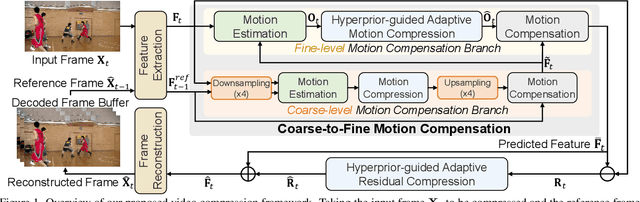
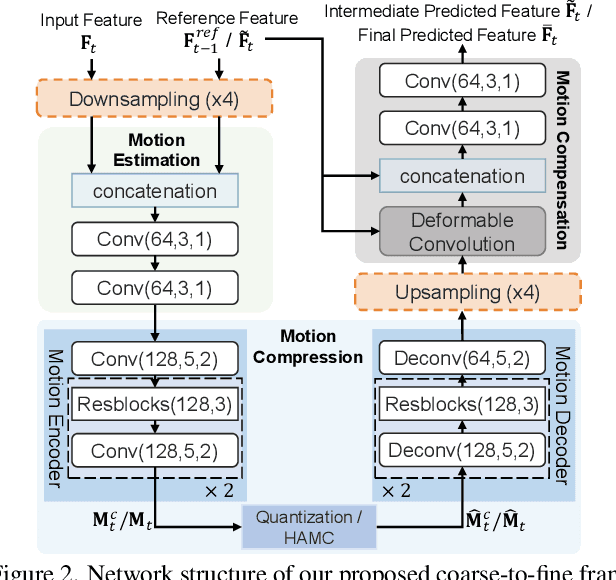
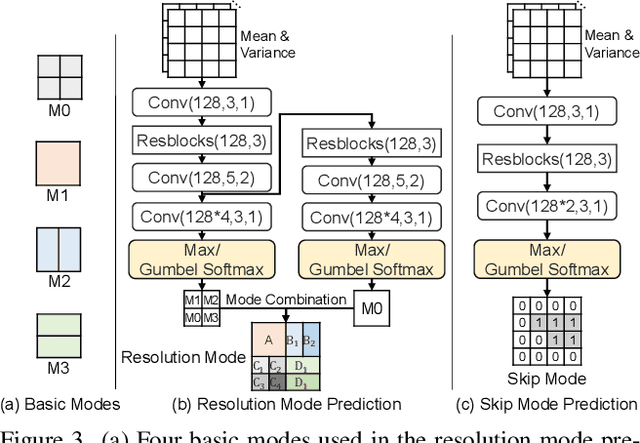
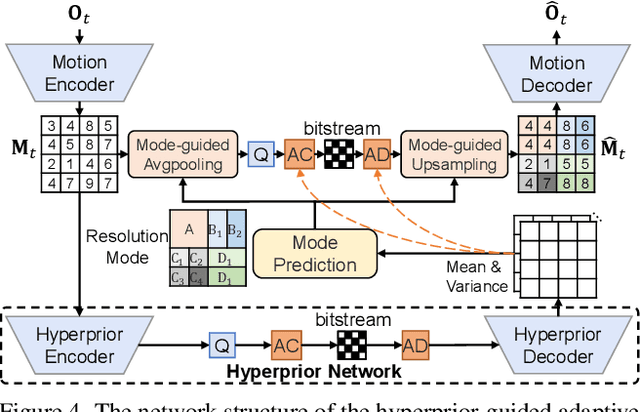
The previous deep video compression approaches only use the single scale motion compensation strategy and rarely adopt the mode prediction technique from the traditional standards like H.264/H.265 for both motion and residual compression. In this work, we first propose a coarse-to-fine (C2F) deep video compression framework for better motion compensation, in which we perform motion estimation, compression and compensation twice in a coarse to fine manner. Our C2F framework can achieve better motion compensation results without significantly increasing bit costs. Observing hyperprior information (i.e., the mean and variance values) from the hyperprior networks contains discriminant statistical information of different patches, we also propose two efficient hyperprior-guided mode prediction methods. Specifically, using hyperprior information as the input, we propose two mode prediction networks to respectively predict the optimal block resolutions for better motion coding and decide whether to skip residual information from each block for better residual coding without introducing additional bit cost while bringing negligible extra computation cost. Comprehensive experimental results demonstrate our proposed C2F video compression framework equipped with the new hyperprior-guided mode prediction methods achieves the state-of-the-art performance on HEVC, UVG and MCL-JCV datasets.
Neural Texture Extraction and Distribution for Controllable Person Image Synthesis
Apr 13, 2022

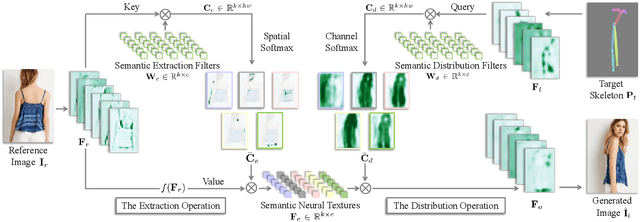
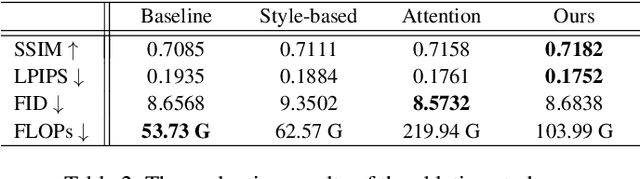
We deal with the controllable person image synthesis task which aims to re-render a human from a reference image with explicit control over body pose and appearance. Observing that person images are highly structured, we propose to generate desired images by extracting and distributing semantic entities of reference images. To achieve this goal, a neural texture extraction and distribution operation based on double attention is described. This operation first extracts semantic neural textures from reference feature maps. Then, it distributes the extracted neural textures according to the spatial distributions learned from target poses. Our model is trained to predict human images in arbitrary poses, which encourages it to extract disentangled and expressive neural textures representing the appearance of different semantic entities. The disentangled representation further enables explicit appearance control. Neural textures of different reference images can be fused to control the appearance of the interested areas. Experimental comparisons show the superiority of the proposed model. Code is available at https://github.com/RenYurui/Neural-Texture-Extraction-Distribution.
PCRP: Unsupervised Point Cloud Object Retrieval and Pose Estimation
Feb 16, 2022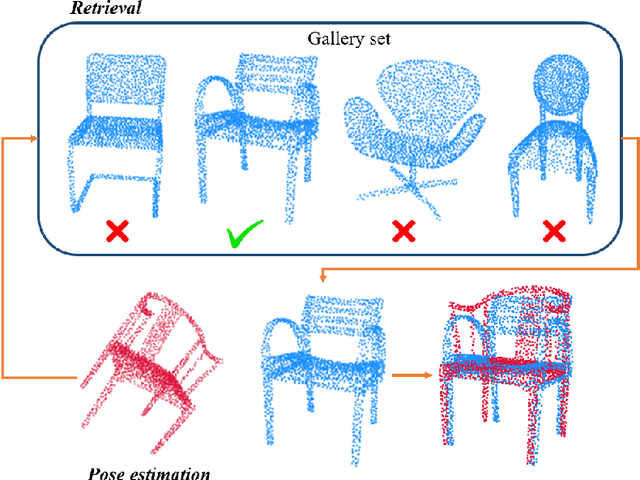
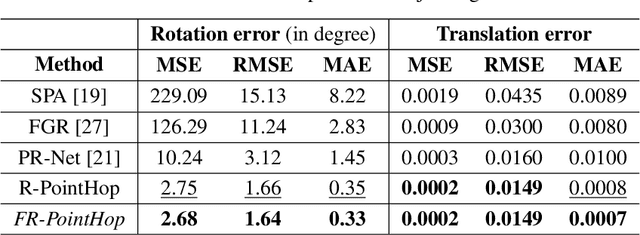
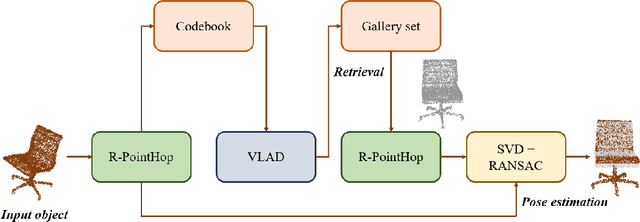
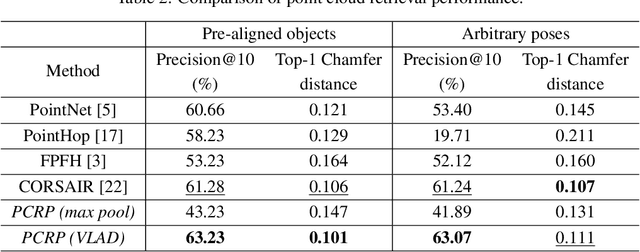
An unsupervised point cloud object retrieval and pose estimation method, called PCRP, is proposed in this work. It is assumed that there exists a gallery point cloud set that contains point cloud objects with given pose orientation information. PCRP attempts to register the unknown point cloud object with those in the gallery set so as to achieve content-based object retrieval and pose estimation jointly, where the point cloud registration task is built upon an enhanced version of the unsupervised R-PointHop method. Experiments on the ModelNet40 dataset demonstrate the superior performance of PCRP in comparison with traditional and learning based methods.
OctAttention: Octree-based Large-scale Contexts Model for Point Cloud Compression
Feb 12, 2022
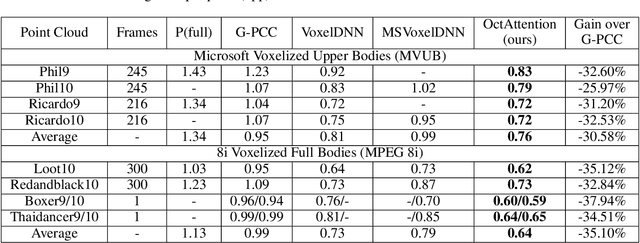
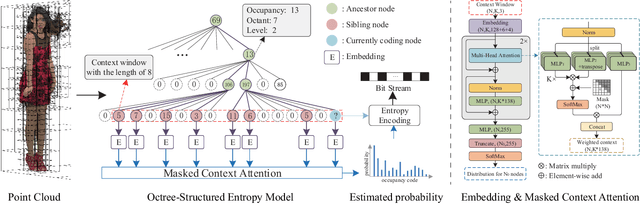
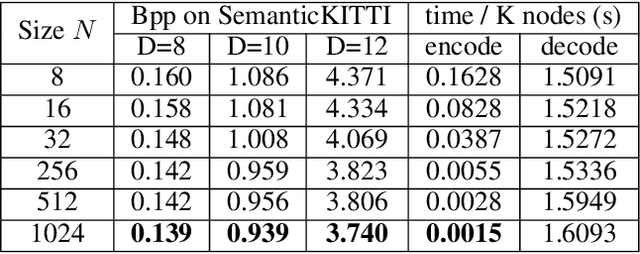
In point cloud compression, sufficient contexts are significant for modeling the point cloud distribution. However, the contexts gathered by the previous voxel-based methods decrease when handling sparse point clouds. To address this problem, we propose a multiple-contexts deep learning framework called OctAttention employing the octree structure, a memory-efficient representation for point clouds. Our approach encodes octree symbol sequences in a lossless way by gathering the information of sibling and ancestor nodes. Expressly, we first represent point clouds with octree to reduce spatial redundancy, which is robust for point clouds with different resolutions. We then design a conditional entropy model with a large receptive field that models the sibling and ancestor contexts to exploit the strong dependency among the neighboring nodes and employ an attention mechanism to emphasize the correlated nodes in the context. Furthermore, we introduce a mask operation during training and testing to make a trade-off between encoding time and performance. Compared to the previous state-of-the-art works, our approach obtains a 10%-35% BD-Rate gain on the LiDAR benchmark (e.g. SemanticKITTI) and object point cloud dataset (e.g. MPEG 8i, MVUB), and saves 95% coding time compared to the voxel-based baseline. The code is available at https://github.com/zb12138/OctAttention.
GPCO: An Unsupervised Green Point Cloud Odometry Method
Dec 08, 2021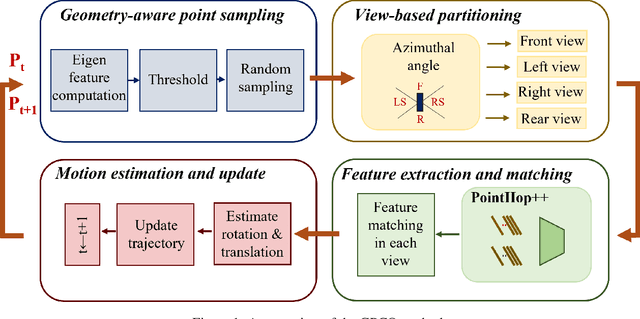
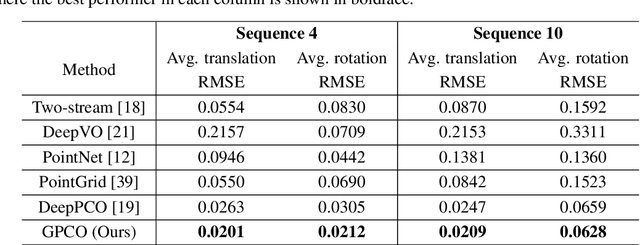
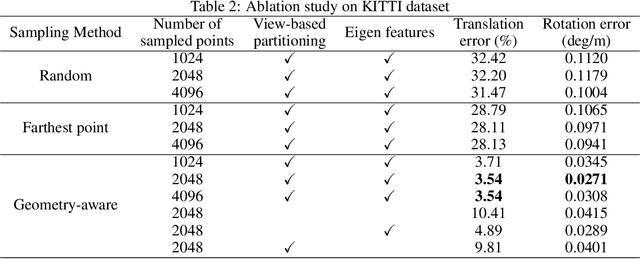
Visual odometry aims to track the incremental motion of an object using the information captured by visual sensors. In this work, we study the point cloud odometry problem, where only the point cloud scans obtained by the LiDAR (Light Detection And Ranging) are used to estimate object's motion trajectory. A lightweight point cloud odometry solution is proposed and named the green point cloud odometry (GPCO) method. GPCO is an unsupervised learning method that predicts object motion by matching features of consecutive point cloud scans. It consists of three steps. First, a geometry-aware point sampling scheme is used to select discriminant points from the large point cloud. Second, the view is partitioned into four regions surrounding the object, and the PointHop++ method is used to extract point features. Third, point correspondences are established to estimate object motion between two consecutive scans. Experiments on the KITTI dataset are conducted to demonstrate the effectiveness of the GPCO method. It is observed that GPCO outperforms benchmarking deep learning methods in accuracy while it has a significantly smaller model size and less training time.
Online Meta Adaptation for Variable-Rate Learned Image Compression
Nov 16, 2021
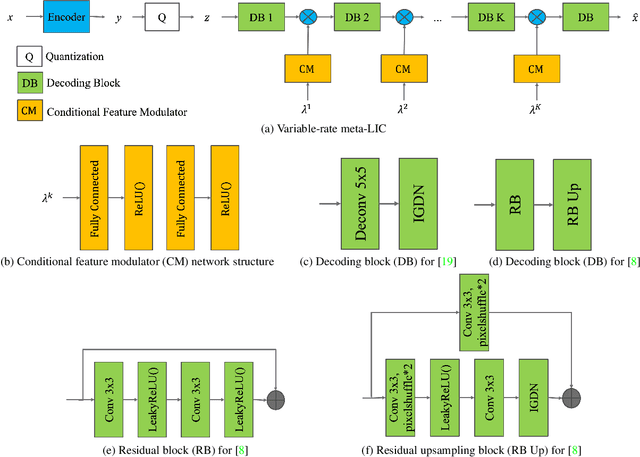
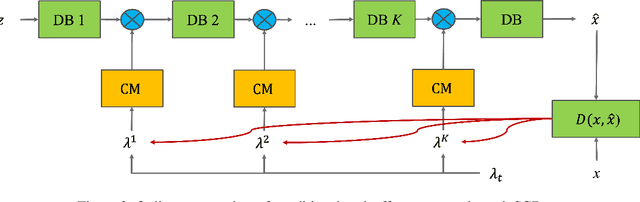
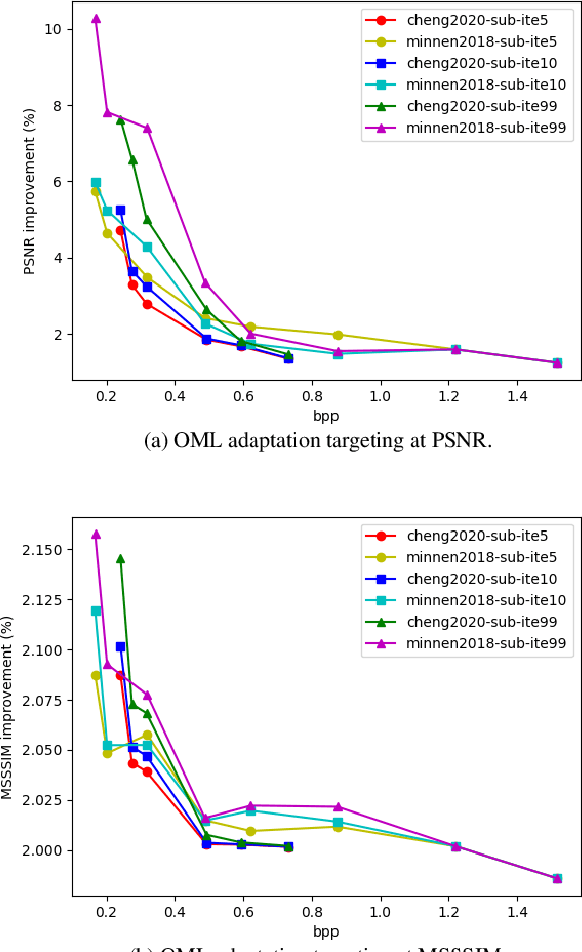
This work addresses two major issues of end-to-end learned image compression (LIC) based on deep neural networks: variable-rate learning where separate networks are required to generate compressed images with varying qualities, and the train-test mismatch between differentiable approximate quantization and true hard quantization. We introduce an online meta-learning (OML) setting for LIC, which combines ideas from meta learning and online learning in the conditional variational auto-encoder (CVAE) framework. By treating the conditional variables as meta parameters and treating the generated conditional features as meta priors, the desired reconstruction can be controlled by the meta parameters to accommodate compression with variable qualities. The online learning framework is used to update the meta parameters so that the conditional reconstruction is adaptively tuned for the current image. Through the OML mechanism, the meta parameters can be effectively updated through SGD. The conditional reconstruction is directly based on the quantized latent representation in the decoder network, and therefore helps to bridge the gap between the training estimation and true quantized latent distribution. Experiments demonstrate that our OML approach can be flexibly applied to different state-of-the-art LIC methods to achieve additional performance improvements with little computation and transmission overhead.
GSIP: Green Semantic Segmentation of Large-Scale Indoor Point Clouds
Sep 24, 2021



An efficient solution to semantic segmentation of large-scale indoor scene point clouds is proposed in this work. It is named GSIP (Green Segmentation of Indoor Point clouds) and its performance is evaluated on a representative large-scale benchmark -- the Stanford 3D Indoor Segmentation (S3DIS) dataset. GSIP has two novel components: 1) a room-style data pre-processing method that selects a proper subset of points for further processing, and 2) a new feature extractor which is extended from PointHop. For the former, sampled points of each room form an input unit. For the latter, the weaknesses of PointHop's feature extraction when extending it to large-scale point clouds are identified and fixed with a simpler processing pipeline. As compared with PointNet, which is a pioneering deep-learning-based solution, GSIP is green since it has significantly lower computational complexity and a much smaller model size. Furthermore, experiments show that GSIP outperforms PointNet in segmentation performance for the S3DIS dataset.
PIRenderer: Controllable Portrait Image Generation via Semantic Neural Rendering
Sep 17, 2021
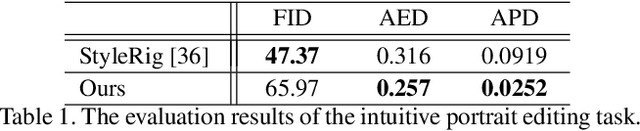
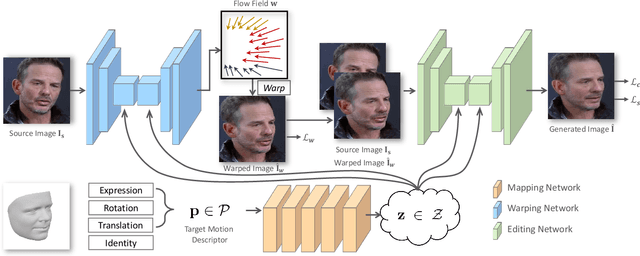

Generating portrait images by controlling the motions of existing faces is an important task of great consequence to social media industries. For easy use and intuitive control, semantically meaningful and fully disentangled parameters should be used as modifications. However, many existing techniques do not provide such fine-grained controls or use indirect editing methods i.e. mimic motions of other individuals. In this paper, a Portrait Image Neural Renderer (PIRenderer) is proposed to control the face motions with the parameters of three-dimensional morphable face models (3DMMs). The proposed model can generate photo-realistic portrait images with accurate movements according to intuitive modifications. Experiments on both direct and indirect editing tasks demonstrate the superiority of this model. Meanwhile, we further extend this model to tackle the audio-driven facial reenactment task by extracting sequential motions from audio inputs. We show that our model can generate coherent videos with convincing movements from only a single reference image and a driving audio stream. Our source code is available at https://github.com/RenYurui/PIRender.