 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFin-Fed-OD: Federated Outlier Detection on Financial Tabular Data
Apr 23, 2024



Anomaly detection in real-world scenarios poses challenges due to dynamic and often unknown anomaly distributions, requiring robust methods that operate under an open-world assumption. This challenge is exacerbated in practical settings, where models are employed by private organizations, precluding data sharing due to privacy and competitive concerns. Despite potential benefits, the sharing of anomaly information across organizations is restricted. This paper addresses the question of enhancing outlier detection within individual organizations without compromising data confidentiality. We propose a novel method leveraging representation learning and federated learning techniques to improve the detection of unknown anomalies. Specifically, our approach utilizes latent representations obtained from client-owned autoencoders to refine the decision boundary of inliers. Notably, only model parameters are shared between organizations, preserving data privacy. The efficacy of our proposed method is evaluated on two standard financial tabular datasets and an image dataset for anomaly detection in a distributed setting. The results demonstrate a strong improvement in the classification of unknown outliers during the inference phase for each organization's model.
A Reinforcement Learning Approach for Sequential Spatial Transformer Networks
Jun 27, 2021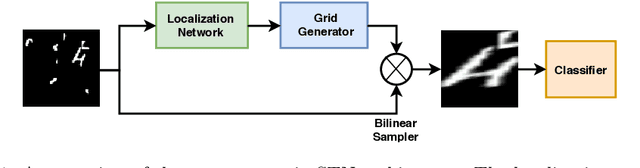

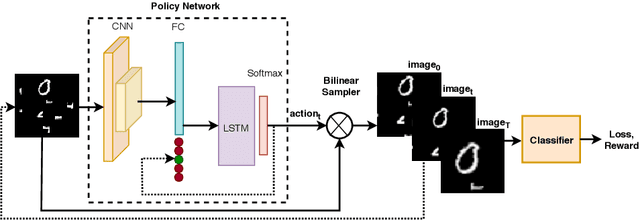

Spatial Transformer Networks (STN) can generate geometric transformations which modify input images to improve the classifier's performance. In this work, we combine the idea of STN with Reinforcement Learning (RL). To this end, we break the affine transformation down into a sequence of simple and discrete transformations. We formulate the task as a Markovian Decision Process (MDP) and use RL to solve this sequential decision-making problem. STN architectures learn the transformation parameters by minimizing the classification error and backpropagating the gradients through a sub-differentiable sampling module. In our method, we are not bound to the differentiability of the sampling modules. Moreover, we have freedom in designing the objective rather than only minimizing the error; e.g., we can directly set the target as maximizing the accuracy. We design multiple experiments to verify the effectiveness of our method using cluttered MNIST and Fashion-MNIST datasets and show that our method outperforms STN with a proper definition of MDP components.
Hybrid Sequence to Sequence Model for Video Object Segmentation
Oct 10, 2020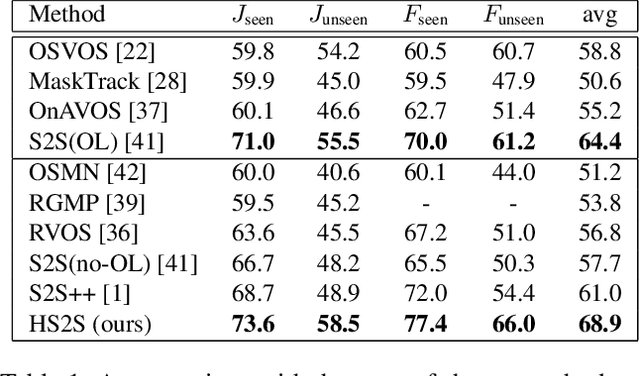
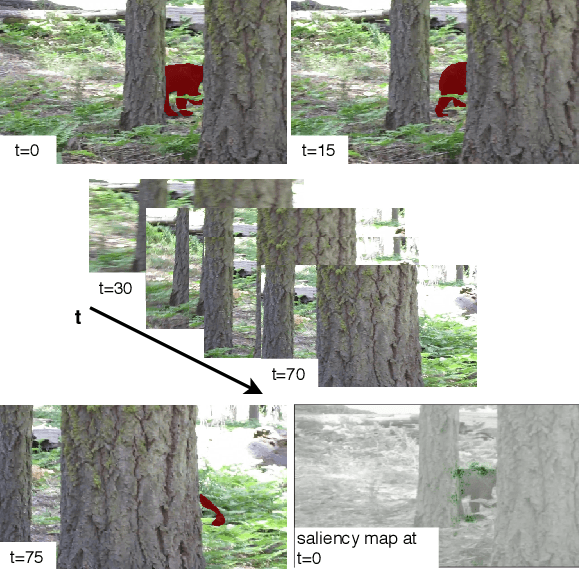

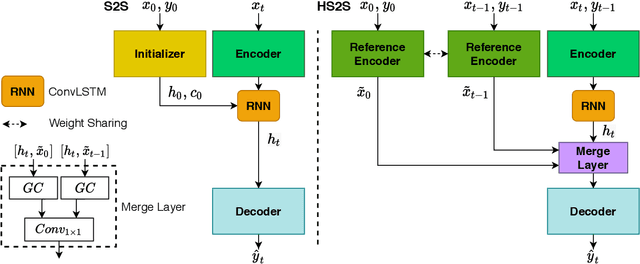
One-shot Video Object Segmentation (VOS) is the task of pixel-wise tracking an object of interest within a video sequence, where the segmentation mask of the first frame is given at inference time. In recent years, Recurrent Neural Networks (RNNs) have been widely used for VOS tasks, but they often suffer from limitations such as drift and error propagation. In this work, we study an RNN-based architecture and address some of these issues by proposing a hybrid sequence-to-sequence architecture named HS2S, utilizing a hybrid mask propagation strategy that allows incorporating the information obtained from correspondence matching. Our experiments show that augmenting the RNN with correspondence matching is a highly effective solution to reduce the drift problem. The additional information helps the model to predict more accurate masks and makes it robust against error propagation. We evaluate our HS2S model on the DAVIS2017 dataset as well as Youtube-VOS. On the latter, we achieve an improvement of 11.2pp in the overall segmentation accuracy over RNN-based state-of-the-art methods in VOS. We analyze our model's behavior in challenging cases such as occlusion and long sequences and show that our hybrid architecture significantly enhances the segmentation quality in these difficult scenarios.
Revisiting Sequence-to-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Apr 25, 2020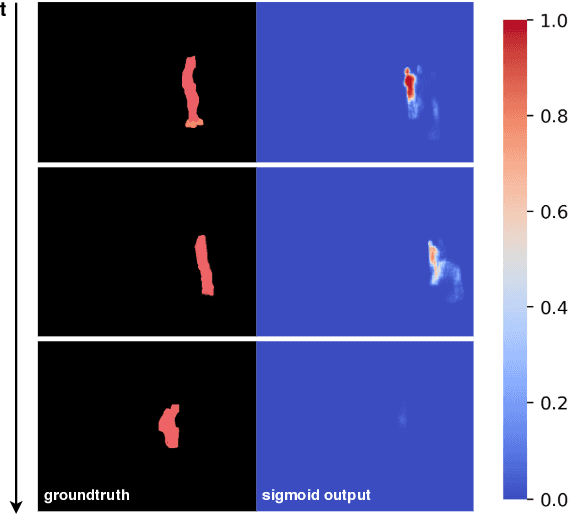
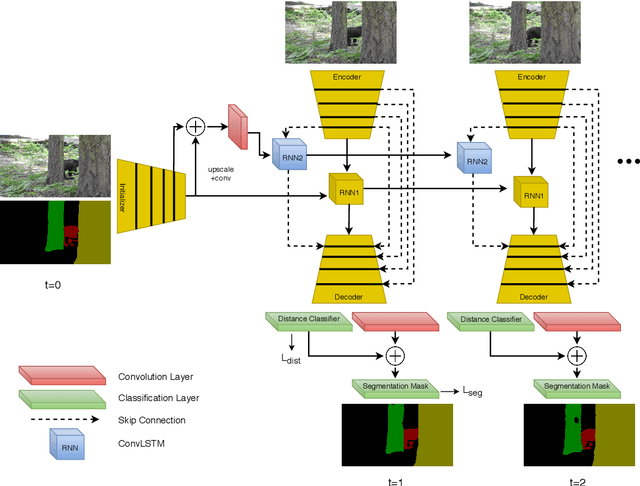
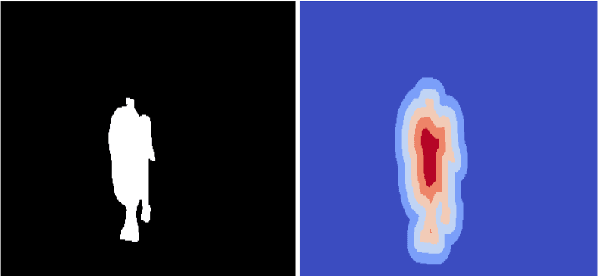

Video Object Segmentation (VOS) is an active research area of the visual domain. One of its fundamental sub-tasks is semi-supervised / one-shot learning: given only the segmentation mask for the first frame, the task is to provide pixel-accurate masks for the object over the rest of the sequence. Despite much progress in the last years, we noticed that many of the existing approaches lose objects in longer sequences, especially when the object is small or briefly occluded. In this work, we build upon a sequence-to-sequence approach that employs an encoder-decoder architecture together with a memory module for exploiting the sequential data. We further improve this approach by proposing a model that manipulates multi-scale spatio-temporal information using memory-equipped skip connections. Furthermore, we incorporate an auxiliary task based on distance classification which greatly enhances the quality of edges in segmentation masks. We compare our approach to the state of the art and show considerable improvement in the contour accuracy metric and the overall segmentation accuracy.
P $\approx$ NP, at least in Visual Question Answering
Mar 27, 2020
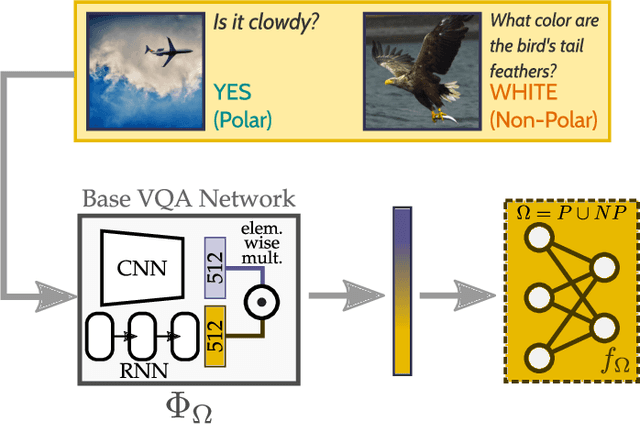
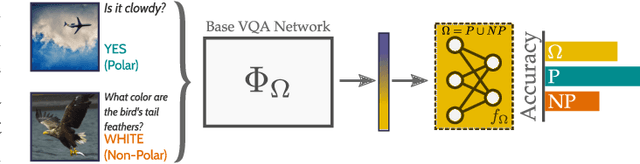
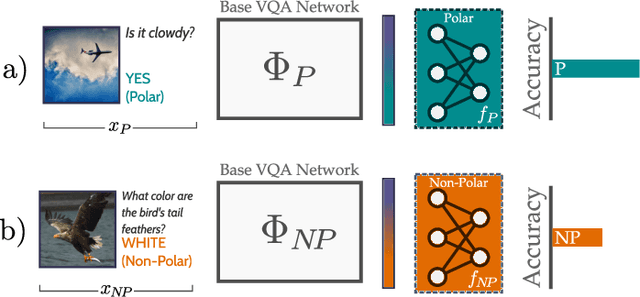
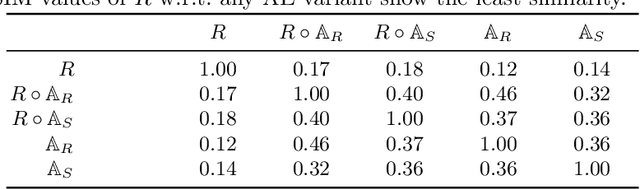
In recent years, progress in the Visual Question Answering (VQA) field has largely been driven by public challenges and large datasets. One of the most widely-used of these is the VQA 2.0 dataset, consisting of polar ("yes/no") and non-polar questions. Looking at the question distribution over all answers, we find that the answers "yes" and "no" account for 38 % of the questions, while the remaining 62% are spread over the more than 3000 remaining answers. While several sources of biases have already been investigated in the field, the effects of such an over-representation of polar vs. non-polar questions remain unclear. In this paper, we measure the potential confounding factors when polar and non-polar samples are used jointly to train a baseline VQA classifier, and compare it to an upper bound where the over-representation of polar questions is excluded from the training. Further, we perform cross-over experiments to analyze how well the feature spaces align. Contrary to expectations, we find no evidence of counterproductive effects in the joint training of unbalanced classes. In fact, by exploring the intermediate feature space of visual-text embeddings, we find that the feature space of polar questions already encodes sufficient structure to answer many non-polar questions. Our results indicate that the polar (P) and the non-polar (NP) feature spaces are strongly aligned, hence the expression P $\approx$ NP
Adversarial Defense based on Structure-to-Signal Autoencoders
Mar 21, 2018

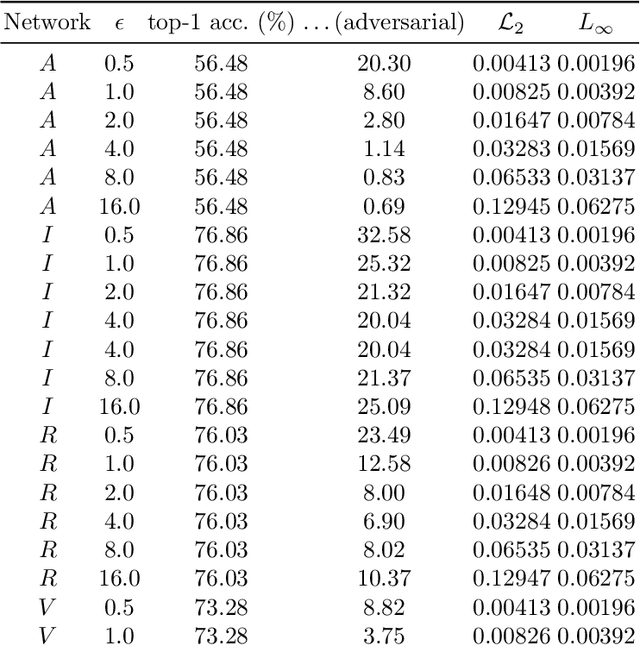
Adversarial attack methods have demonstrated the fragility of deep neural networks. Their imperceptible perturbations are frequently able fool classifiers into potentially dangerous misclassifications. We propose a novel way to interpret adversarial perturbations in terms of the effective input signal that classifiers actually use. Based on this, we apply specially trained autoencoders, referred to as S2SNets, as defense mechanism. They follow a two-stage training scheme: first unsupervised, followed by a fine-tuning of the decoder, using gradients from an existing classifier. S2SNets induce a shift in the distribution of gradients propagated through them, stripping them from class-dependent signal. We analyze their robustness against several white-box and gray-box scenarios on the large ImageNet dataset. Our approach reaches comparable resilience in white-box attack scenarios as other state-of-the-art defenses in gray-box scenarios. We further analyze the relationships of AlexNet, VGG 16, ResNet 50 and Inception v3 in adversarial space, and found that VGG 16 is the easiest to fool, while perturbations from ResNet 50 are the most transferable.