 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Approaches to Document-level Machine Translation
Jan 26, 2021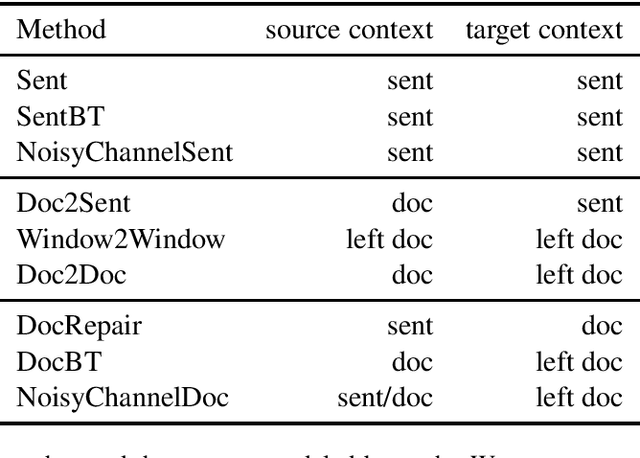
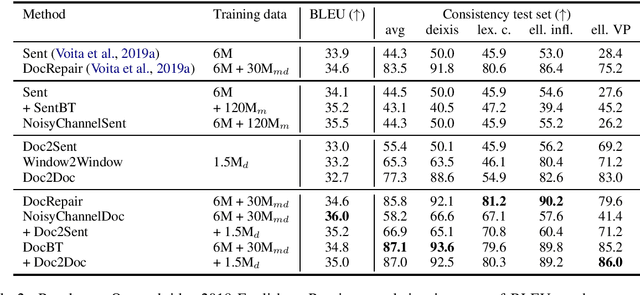
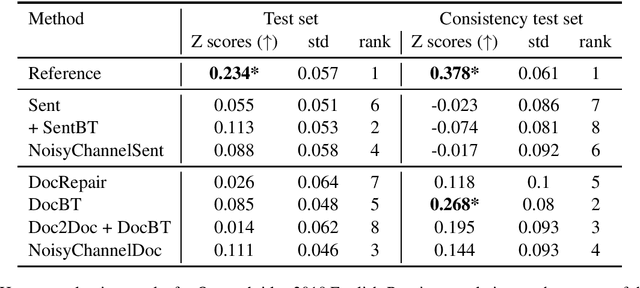
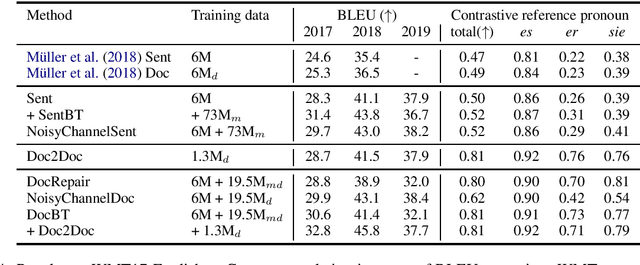
Document-level machine translation conditions on surrounding sentences to produce coherent translations. There has been much recent work in this area with the introduction of custom model architectures and decoding algorithms. This paper presents a systematic comparison of selected approaches from the literature on two benchmarks for which document-level phenomena evaluation suites exist. We find that a simple method based purely on back-translating monolingual document-level data performs as well as much more elaborate alternatives, both in terms of document-level metrics as well as human evaluation.
Language Models not just for Pre-training: Fast Online Neural Noisy Channel Modeling
Nov 13, 2020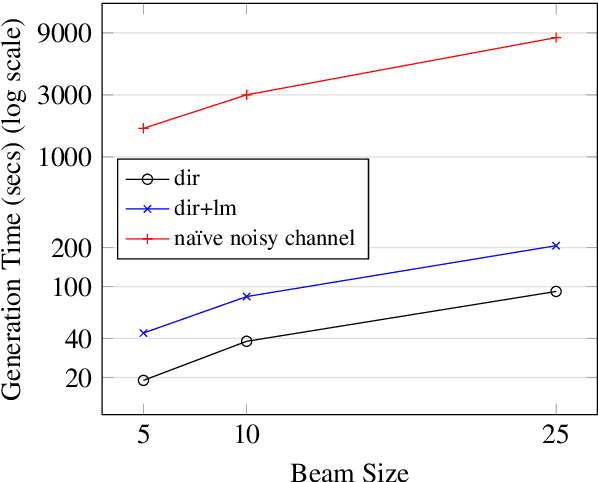
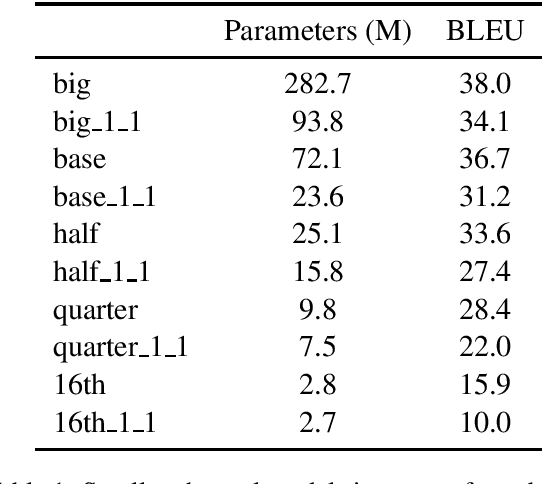
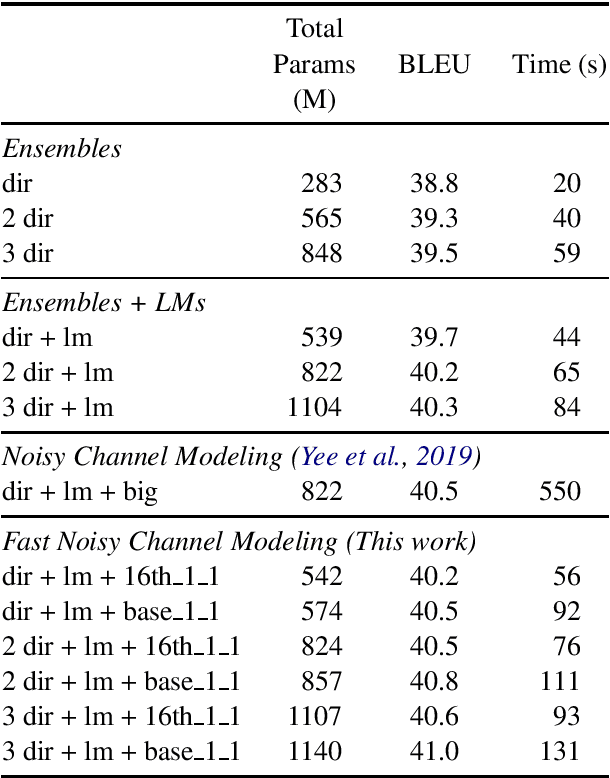
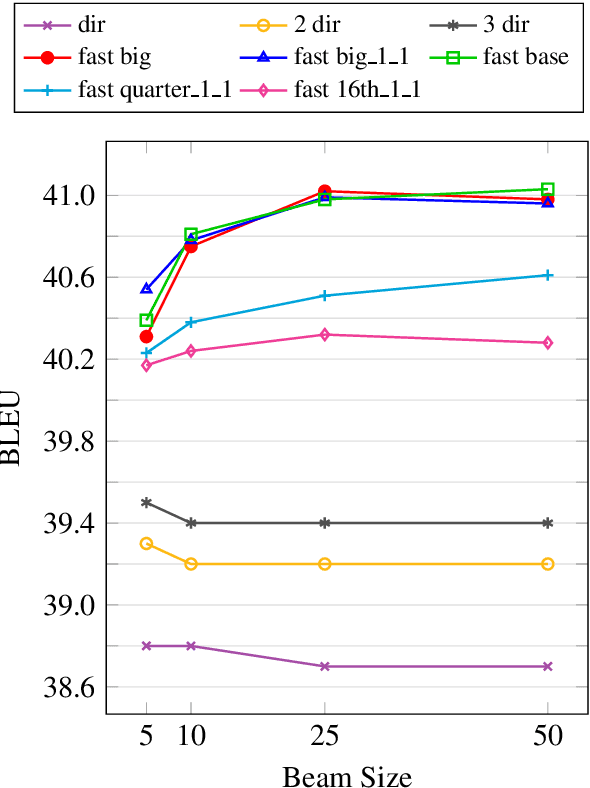
Pre-training models on vast quantities of unlabeled data has emerged as an effective approach to improving accuracy on many NLP tasks. On the other hand, traditional machine translation has a long history of leveraging unlabeled data through noisy channel modeling. The same idea has recently been shown to achieve strong improvements for neural machine translation. Unfortunately, na\"{i}ve noisy channel modeling with modern sequence to sequence models is up to an order of magnitude slower than alternatives. We address this issue by introducing efficient approximations to make inference with the noisy channel approach as fast as strong ensembles while increasing accuracy. We also show that the noisy channel approach can outperform strong pre-training results by achieving a new state of the art on WMT Romanian-English translation.
Beyond English-Centric Multilingual Machine Translation
Oct 21, 2020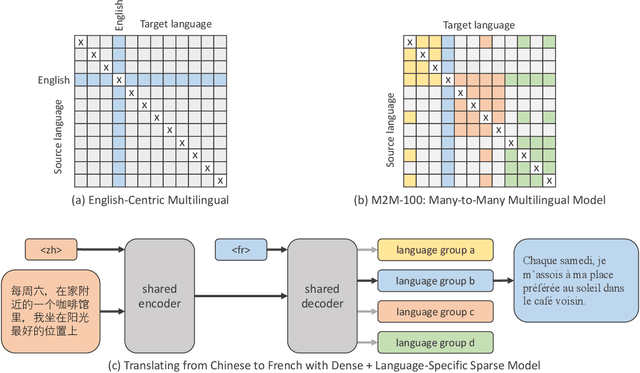

Existing work in translation demonstrated the potential of massively multilingual machine translation by training a single model able to translate between any pair of languages. However, much of this work is English-Centric by training only on data which was translated from or to English. While this is supported by large sources of training data, it does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation model that can translate directly between any pair of 100 languages. We build and open source a training dataset that covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly translating between non-English directions while performing competitively to the best single systems of WMT. We open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.
Large scale weakly and semi-supervised learning for low-resource video ASR
May 16, 2020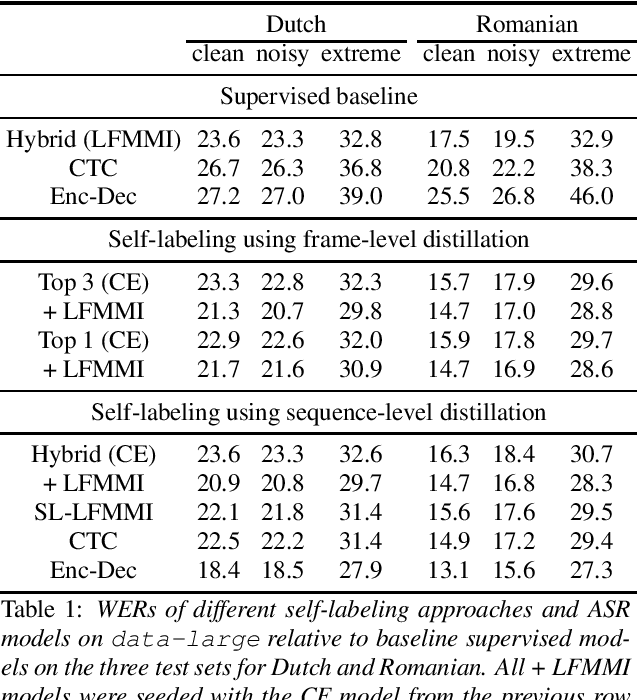
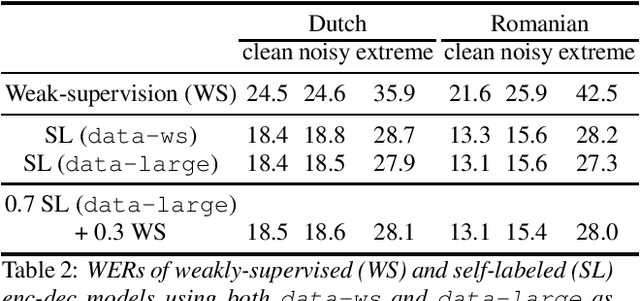
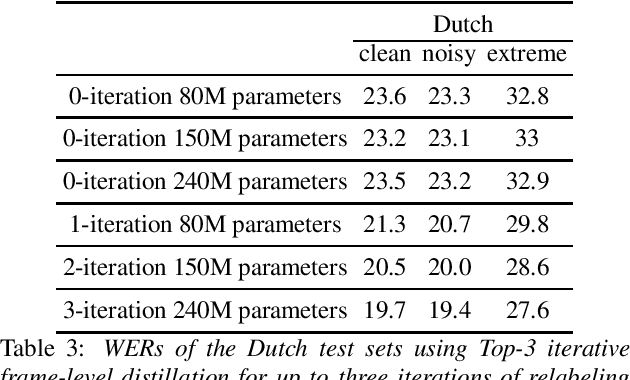
Many semi- and weakly-supervised approaches have been investigated for overcoming the labeling cost of building high quality speech recognition systems. On the challenging task of transcribing social media videos in low-resource conditions, we conduct a large scale systematic comparison between two self-labeling methods on one hand, and weakly-supervised pretraining using contextual metadata on the other. We investigate distillation methods at the frame level and the sequence level for hybrid, encoder-only CTC-based, and encoder-decoder speech recognition systems on Dutch and Romanian languages using 27,000 and 58,000 hours of unlabeled audio respectively. Although all approaches improved upon their respective baseline WERs by more than 8%, sequence-level distillation for encoder-decoder models provided the largest relative WER reduction of 20% compared to the strongest data-augmented supervised baseline.
Dense Passage Retrieval for Open-Domain Question Answering
May 02, 2020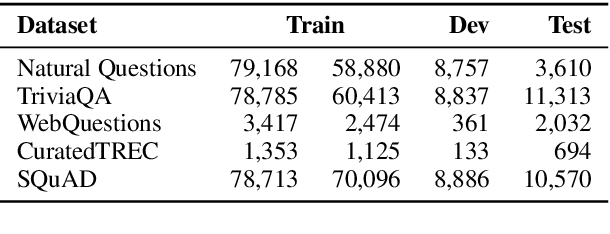
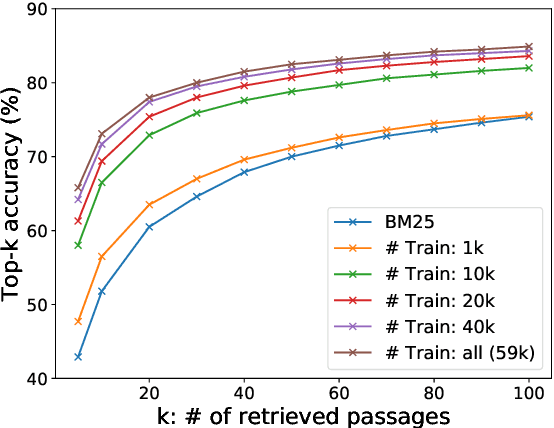
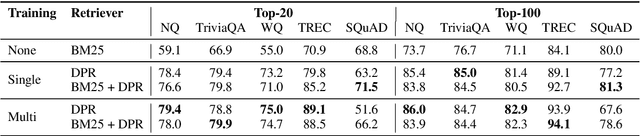
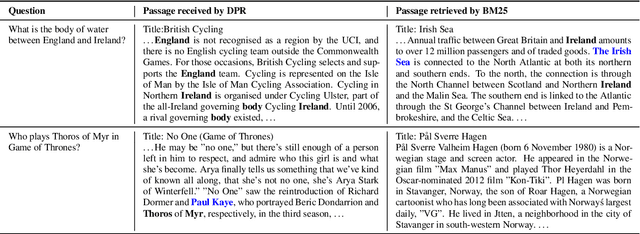
Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can be practically implemented using dense representations alone, where embeddings are learned from a small number of questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets, our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA benchmarks.
Multilingual Denoising Pre-training for Neural Machine Translation
Jan 23, 2020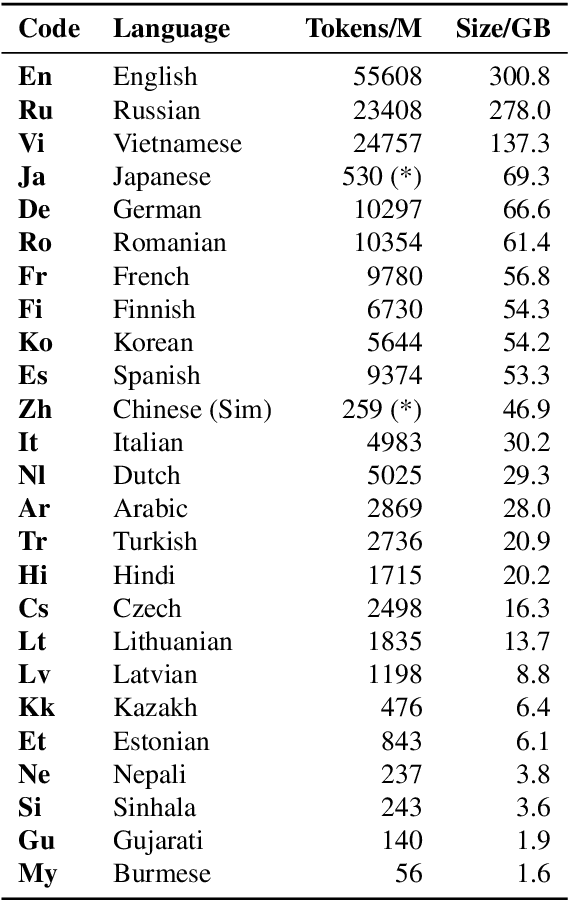
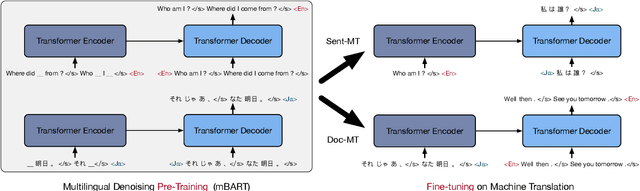
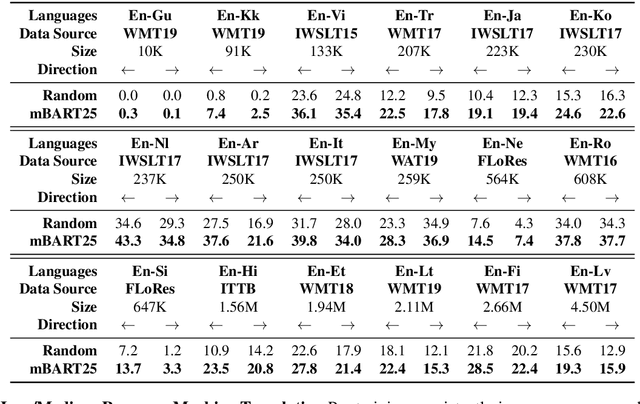
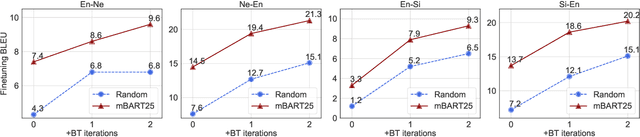
This paper demonstrates that multilingual denoising pre-training produces significant performance gains across a wide variety of machine translation (MT) tasks. We present mBART -- a sequence-to-sequence denoising auto-encoder pre-trained on large-scale monolingual corpora in many languages using the BART objective. mBART is one of the first methods for pre-training a complete sequence-to-sequence model by denoising full texts in multiple languages, while previous approaches have focused only on the encoder, decoder, or reconstructing parts of the text. Pre-training a complete model allows it to be directly fine tuned for supervised (both sentence-level and document-level) and unsupervised machine translation, with no task-specific modifications. We demonstrate that adding mBART initialization produces performance gains in all but the highest-resource settings, including up to 12 BLEU points for low resource MT and over 5 BLEU points for many document-level and unsupervised models. We also show it also enables new types of transfer to language pairs with no bi-text or that were not in the pre-training corpus, and present extensive analysis of which factors contribute the most to effective pre-training.
CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB
Nov 10, 2019
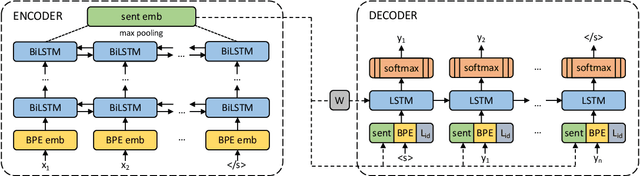
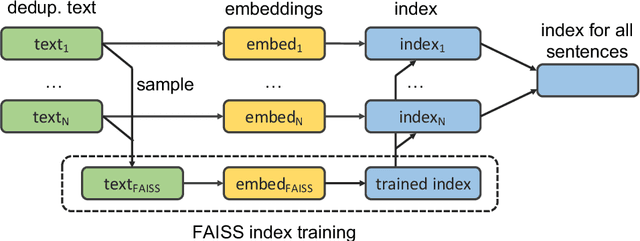
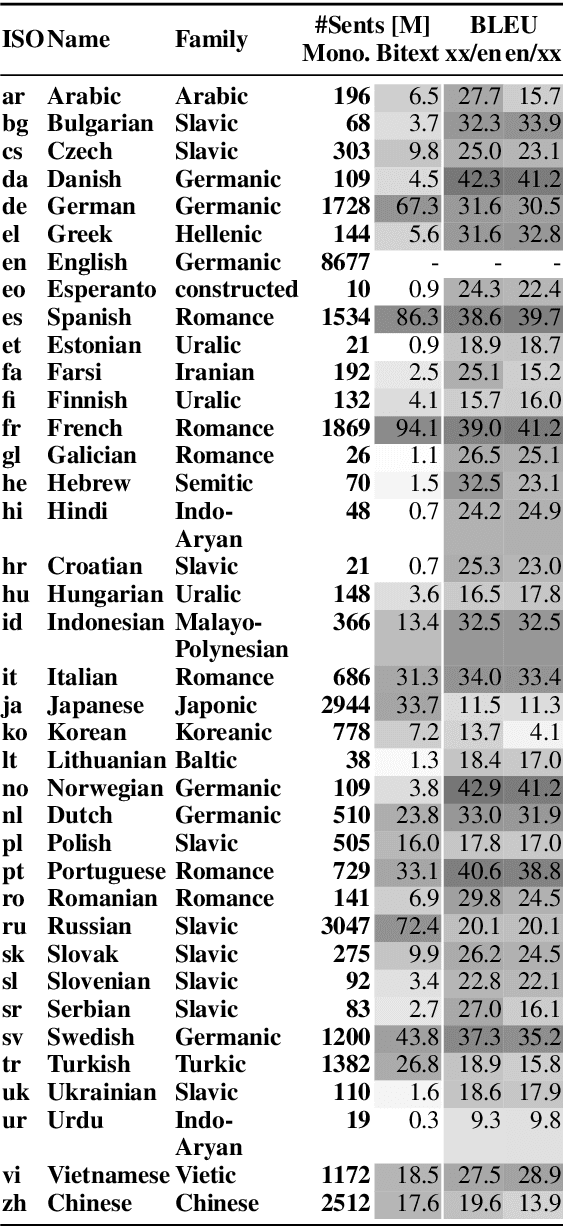
We show that margin-based bitext mining in a multilingual sentence space can be applied to monolingual corpora of billions of sentences. We are using ten snapshots of a curated common crawl corpus (Wenzek et al., 2019) totaling 32.7 billion unique sentences. Using one unified approach for 38 languages, we were able to mine 3.5 billions parallel sentences, out of which 661 million are aligned with English. 17 language pairs have more then 30 million parallel sentences, 82 more then 10 million, and most more than one million, including direct alignments between many European or Asian languages. To evaluate the quality of the mined bitexts, we train NMT systems for most of the language pairs and evaluate them on TED, WMT and WAT test sets. Using our mined bitexts only and no human translated parallel data, we achieve a new state-of-the-art for a single system on the WMT'19 test set for translation between English and German, Russian and Chinese, as well as German/French. In particular, our English/German system outperforms the best single one by close to 4 BLEU points and is almost on pair with best WMT'19 evaluation system which uses system combination and back-translation. We also achieve excellent results for distant languages pairs like Russian/Japanese, outperforming the best submission at the 2019 workshop on Asian Translation (WAT).
Training ASR models by Generation of Contextual Information
Oct 27, 2019
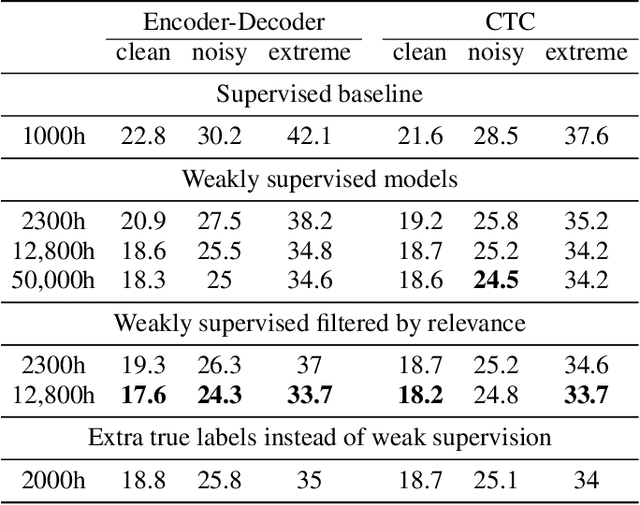
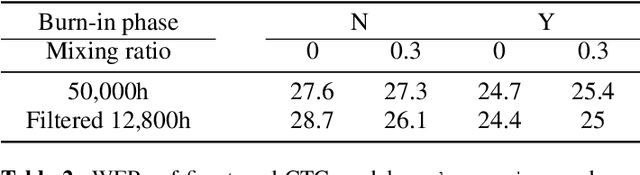

Supervised ASR models have reached unprecedented levels of accuracy, thanks in part to ever-increasing amounts of labelled training data. However, in many applications and locales, only moderate amounts of data are available, which has led to a surge in semi- and weakly-supervised learning research. In this paper, we conduct a large-scale study evaluating the effectiveness of weakly-supervised learning for speech recognition by using loosely related contextual information as a surrogate for ground-truth labels. For weakly supervised training, we use 50k hours of public English social media videos along with their respective titles and post text to train an encoder-decoder transformer model. Our best encoder-decoder models achieve an average of 20.8% WER reduction over a 1000 hours supervised baseline, and an average of 13.4% WER reduction when using only the weakly supervised encoder for CTC fine-tuning. Our results show that our setup for weak supervision improved both the encoder acoustic representations as well as the decoder language generation abilities.
On The Evaluation of Machine Translation Systems Trained With Back-Translation
Aug 14, 2019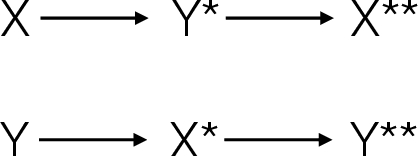
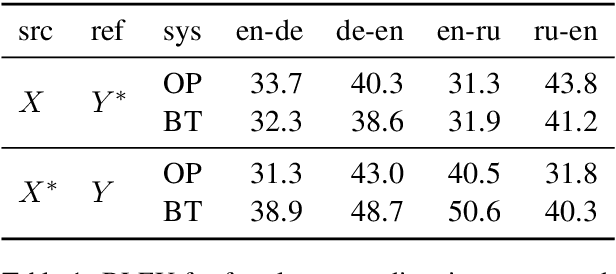
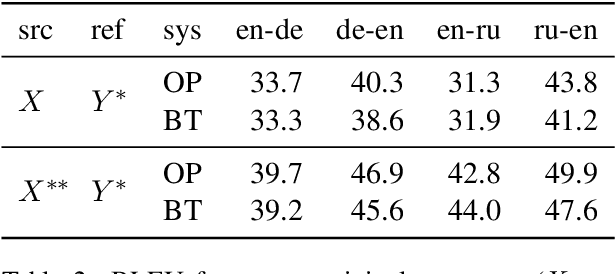
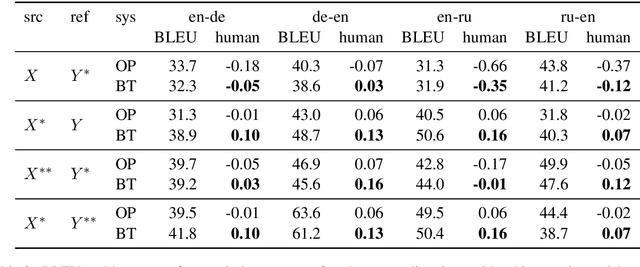
Back-translation is a widely used data augmentation technique which leverages target monolingual data. However, its effectiveness has been challenged since automatic metrics such as BLEU only show significant improvements for test examples where the source itself is a translation, or translationese. This is believed to be due to translationese inputs better matching the back-translated training data. In this work, we show that this conjecture is not empirically supported and that back-translation improves translation quality of both naturally occurring text as well as translationese according to professional human translators. We provide empirical evidence to support the view that back-translation is preferred by humans because it produces more fluent outputs. BLEU cannot capture human preferences because references are translationese when source sentences are natural text. We recommend complementing BLEU with a language model score to measure fluency.
Facebook FAIR's WMT19 News Translation Task Submission
Jul 15, 2019
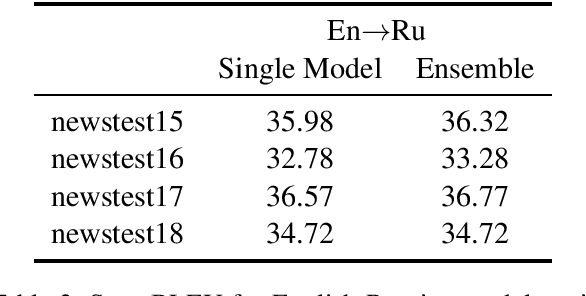
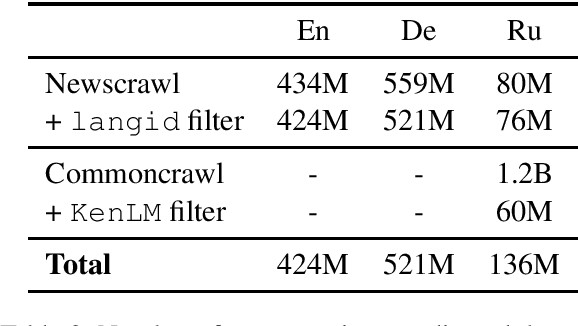
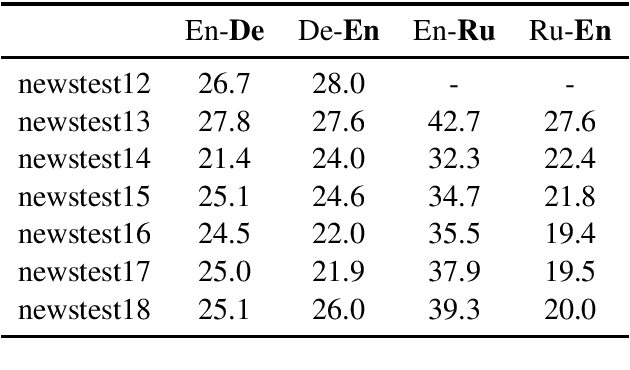
This paper describes Facebook FAIR's submission to the WMT19 shared news translation task. We participate in two language pairs and four language directions, English <-> German and English <-> Russian. Following our submission from last year, our baseline systems are large BPE-based transformer models trained with the Fairseq sequence modeling toolkit which rely on sampled back-translations. This year we experiment with different bitext data filtering schemes, as well as with adding filtered back-translated data. We also ensemble and fine-tune our models on domain-specific data, then decode using noisy channel model reranking. Our submissions are ranked first in all four directions of the human evaluation campaign. On En->De, our system significantly outperforms other systems as well as human translations. This system improves upon our WMT'18 submission by 4.5 BLEU points.