 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Dataset Granularity
Dec 21, 2019
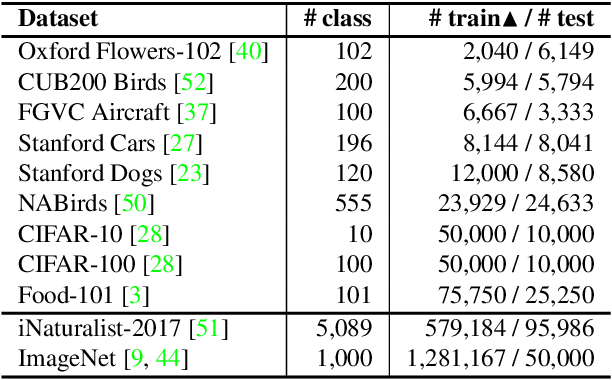
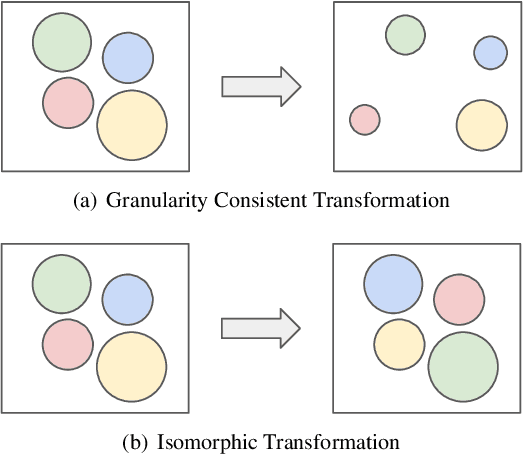
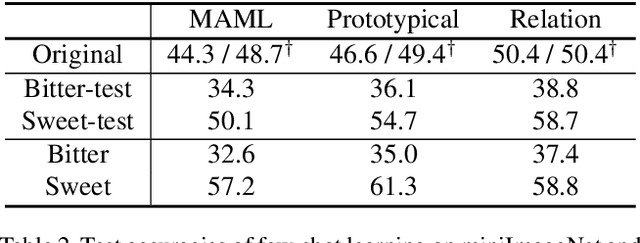
Despite the increasing visibility of fine-grained recognition in our field, "fine-grained'' has thus far lacked a precise definition. In this work, building upon clustering theory, we pursue a framework for measuring dataset granularity. We argue that dataset granularity should depend not only on the data samples and their labels, but also on the distance function we choose. We propose an axiomatic framework to capture desired properties for a dataset granularity measure and provide examples of measures that satisfy these properties. We assess each measure via experiments on datasets with hierarchical labels of varying granularity. When measuring granularity in commonly used datasets with our measure, we find that certain datasets that are widely considered fine-grained in fact contain subsets of considerable size that are substantially more coarse-grained than datasets generally regarded as coarse-grained. We also investigate the interplay between dataset granularity with a variety of factors and find that fine-grained datasets are more difficult to learn from, more difficult to transfer to, more difficult to perform few-shot learning with, and more vulnerable to adversarial attacks.
Fine-grained Synthesis of Unrestricted Adversarial Examples
Nov 20, 2019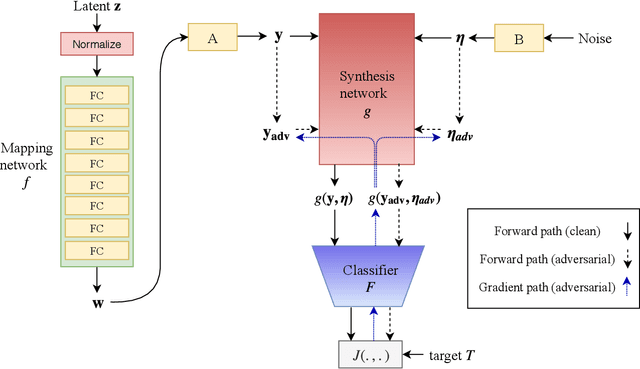
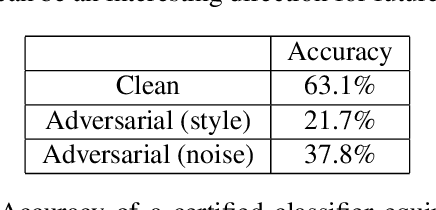

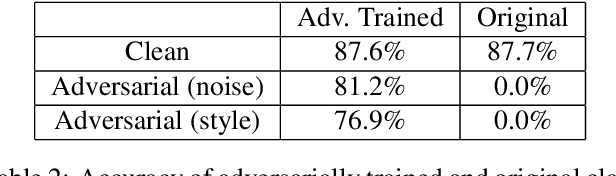
We propose a novel approach for generating unrestricted adversarial examples by manipulating fine-grained aspects of image generation. Unlike existing unrestricted attacks that typically hand-craft geometric transformations, we learn stylistic and stochastic modifications leveraging state-of-the-art generative models. This allows us to manipulate an image in a controlled, fine-grained manner without being bounded by a norm threshold. Our model can be used for both targeted and non-targeted unrestricted attacks. We demonstrate that our attacks can bypass certified defenses, yet our adversarial images look indistinguishable from natural images as verified by human evaluation. Adversarial training can be used as an effective defense without degrading performance of the model on clean images. We perform experiments on LSUN and CelebA-HQ as high resolution datasets to validate efficacy of our proposed approach.
Neural Puppet: Generative Layered Cartoon Characters
Oct 04, 2019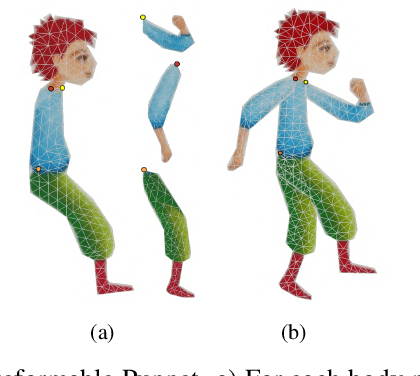
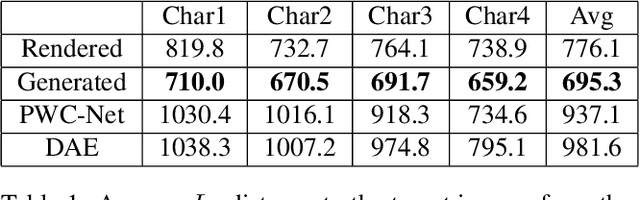
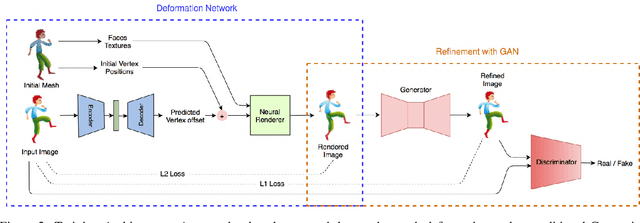
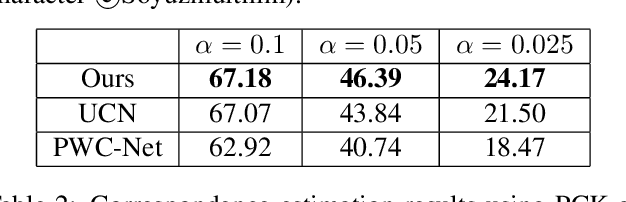
We propose a learning based method for generating new animations of a cartoon character given a few example images. Our method is designed to learn from a traditionally animated sequence, where each frame is drawn by an artist, and thus the input images lack any common structure, correspondences, or labels. We express pose changes as a deformation of a layered 2.5D template mesh, and devise a novel architecture that learns to predict mesh deformations matching the template to a target image. This enables us to extract a common low-dimensional structure from a diverse set of character poses. We combine recent advances in differentiable rendering as well as mesh-aware models to successfully align common template even if only a few character images are available during training. In addition to coarse poses, character appearance also varies due to shading, out-of-plane motions, and artistic effects. We capture these subtle changes by applying an image translation network to refine the mesh rendering, providing an end-to-end model to generate new animations of a character with high visual quality. We demonstrate that our generative model can be used to synthesize in-between frames and to create data-driven deformation. Our template fitting procedure outperforms state-of-the-art generic techniques for detecting image correspondences.
Neural Naturalist: Generating Fine-Grained Image Comparisons
Sep 20, 2019
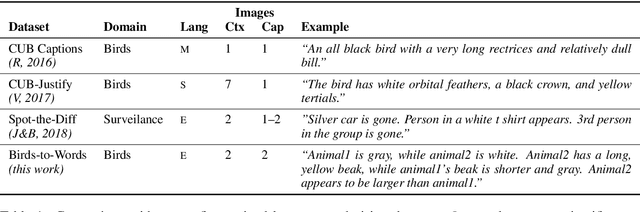
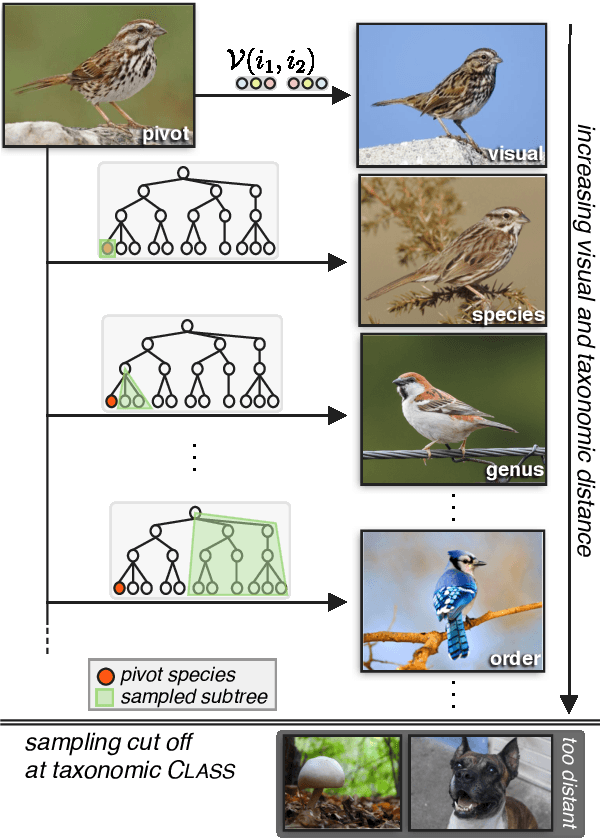
We introduce the new Birds-to-Words dataset of 41k sentences describing fine-grained differences between photographs of birds. The language collected is highly detailed, while remaining understandable to the everyday observer (e.g., "heart-shaped face," "squat body"). Paragraph-length descriptions naturally adapt to varying levels of taxonomic and visual distance---drawn from a novel stratified sampling approach---with the appropriate level of detail. We propose a new model called Neural Naturalist that uses a joint image encoding and comparative module to generate comparative language, and evaluate the results with humans who must use the descriptions to distinguish real images. Our results indicate promising potential for neural models to explain differences in visual embedding space using natural language, as well as a concrete path for machine learning to aid citizen scientists in their effort to preserve biodiversity.
Enhancing Adversarial Example Transferability with an Intermediate Level Attack
Jul 23, 2019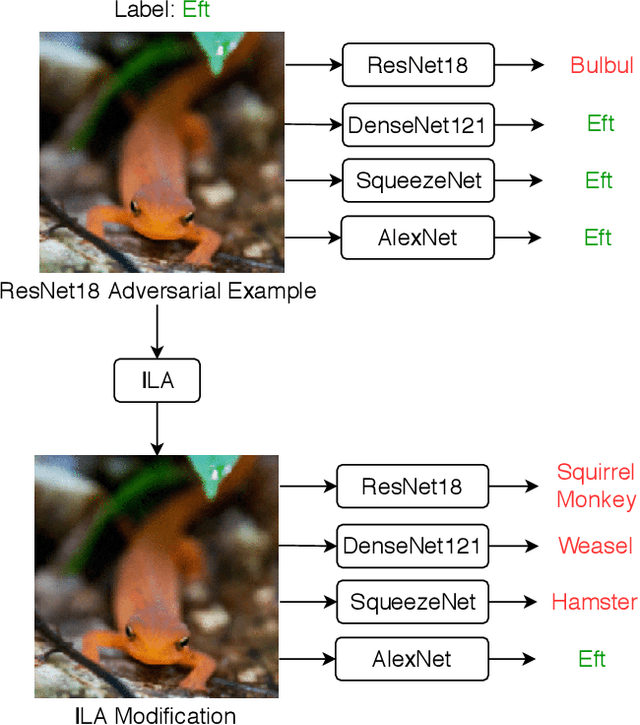
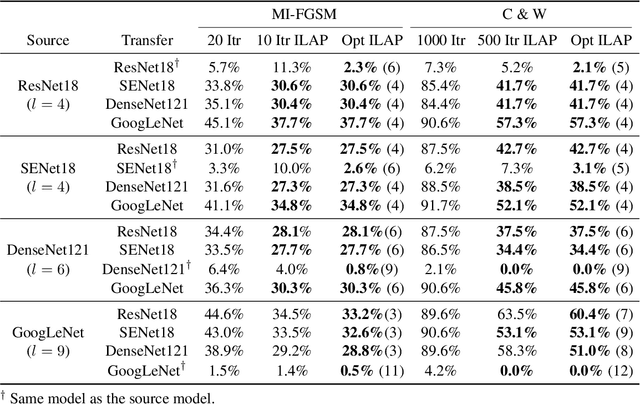

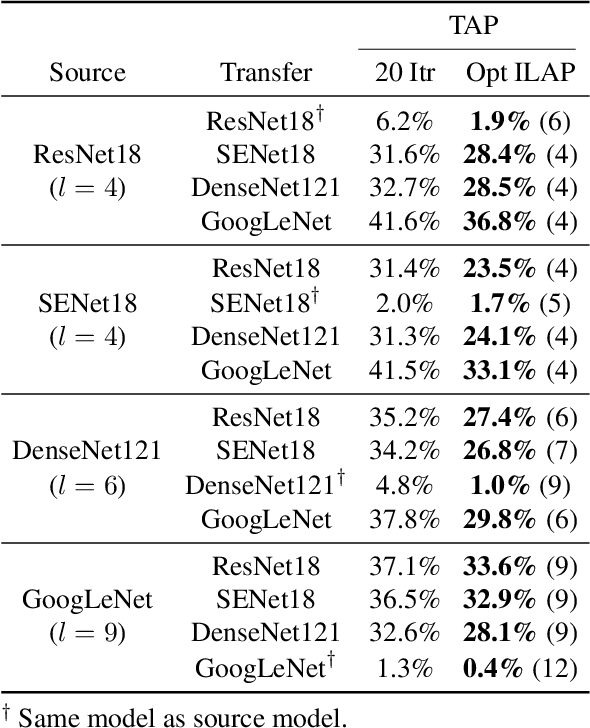
Neural networks are vulnerable to adversarial examples, malicious inputs crafted to fool trained models. Adversarial examples often exhibit black-box transfer, meaning that adversarial examples for one model can fool another model. However, adversarial examples are typically overfit to exploit the particular architecture and feature representation of a source model, resulting in sub-optimal black-box transfer attacks to other target models. We introduce the Intermediate Level Attack (ILA), which attempts to fine-tune an existing adversarial example for greater black-box transferability by increasing its perturbation on a pre-specified layer of the source model, improving upon state-of-the-art methods. We show that we can select a layer of the source model to perturb without any knowledge of the target models while achieving high transferability. Additionally, we provide some explanatory insights regarding our method and the effect of optimizing for adversarial examples in intermediate feature maps.
FoodX-251: A Dataset for Fine-grained Food Classification
Jul 14, 2019
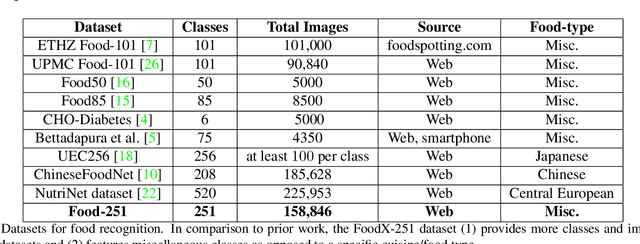

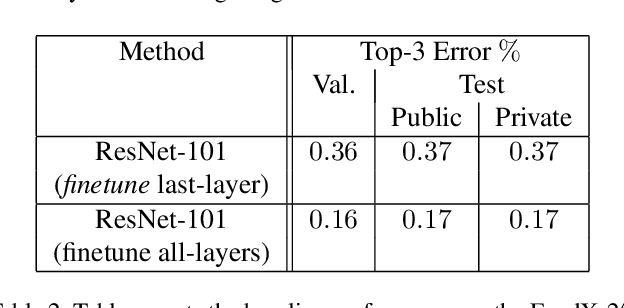
Food classification is a challenging problem due to the large number of categories, high visual similarity between different foods, as well as the lack of datasets for training state-of-the-art deep models. Solving this problem will require advances in both computer vision models as well as datasets for evaluating these models. In this paper we focus on the second aspect and introduce FoodX-251, a dataset of 251 fine-grained food categories with 158k images collected from the web. We use 118k images as a training set and provide human verified labels for 40k images that can be used for validation and testing. In this work, we outline the procedure of creating this dataset and provide relevant baselines with deep learning models. The FoodX-251 dataset has been used for organizing iFood-2019 challenge in the Fine-Grained Visual Categorization workshop (FGVC6 at CVPR 2019) and is available for download.
Positional Normalization
Jul 09, 2019
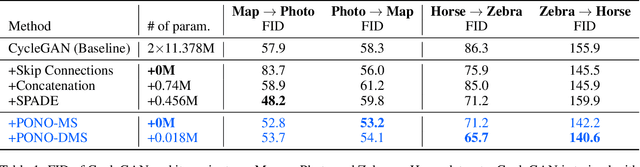


A widely deployed method for reducing the training time of deep neural networks is to normalize activations at each layer. Although various normalization schemes have been proposed, they all follow a common theme: normalize across spatial dimensions and discard the extracted statistics. In this paper, we propose a novel normalization method that noticeably departs from this convention. Our approach, which we refer to as Positional Normalization (PONO), normalizes exclusively across channels --- a naturally appealing dimension, which captures the first and second moments of features extracted at a particular image position. We argue that these moments convey structural information about the input image and the extracted features, which opens a new avenue along which a network can benefit from feature normalization: Instead of disregarding the PONO normalization constants, we propose to re-inject them into later layers to preserve or transfer structural information in generative networks.
PointFlow: 3D Point Cloud Generation with Continuous Normalizing Flows
Jul 01, 2019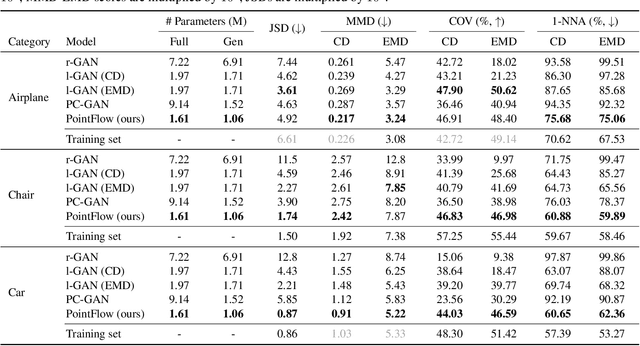
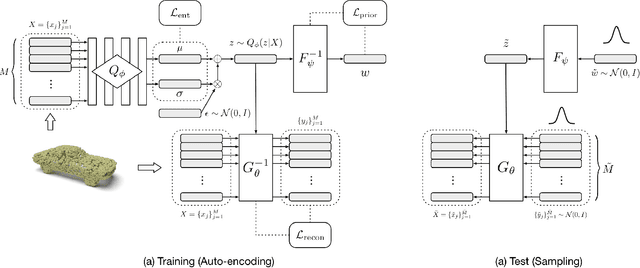
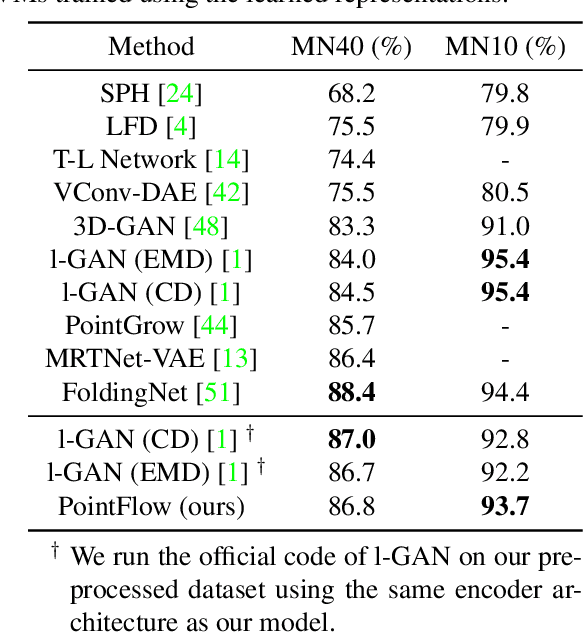
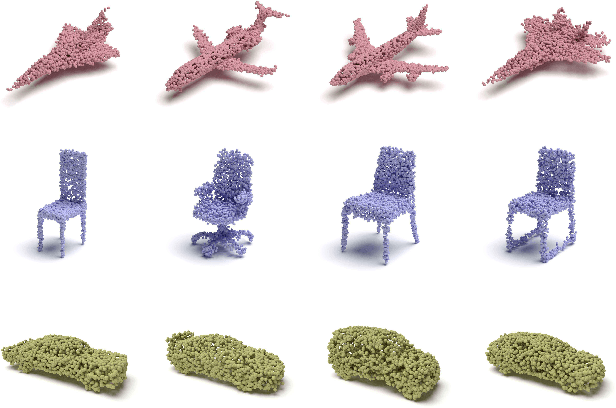
As 3D point clouds become the representation of choice for multiple vision and graphics applications, the ability to synthesize or reconstruct high-resolution, high-fidelity point clouds becomes crucial. Despite the recent success of deep learning models in discriminative tasks of point clouds, generating point clouds remains challenging. This paper proposes a principled probabilistic framework to generate 3D point clouds by modeling them as a distribution of distributions. Specifically, we learn a two-level hierarchy of distributions where the first level is the distribution of shapes and the second level is the distribution of points given a shape. This formulation allows us to both sample shapes and sample an arbitrary number of points from a shape. Our generative model, named PointFlow, learns each level of the distribution with a continuous normalizing flow. The invertibility of normalizing flows enables the computation of the likelihood during training and allows us to train our model in the variational inference framework. Empirically, we demonstrate that PointFlow achieves state-of-the-art performance in point cloud generation. We additionally show that our model can faithfully reconstruct point clouds and learn useful representations in an unsupervised manner. The code will be available at https://github.com/stevenygd/PointFlow.
The Herbarium Challenge 2019 Dataset
Jun 15, 2019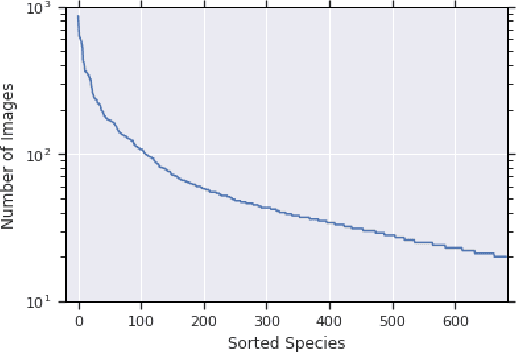



Herbarium sheets are invaluable for botanical research, and considerable time and effort is spent by experts to label and identify specimens on them. In view of recent advances in computer vision and deep learning, developing an automated approach to help experts identify specimens could significantly accelerate research in this area. Whereas most existing botanical datasets comprise photos of specimens in the wild, herbarium sheets exhibit dried specimens, which poses new challenges. We present a challenge dataset of herbarium sheet images labeled by experts, with the intent of facilitating the development of automated identification techniques for this challenging scenario.
The iMaterialist Fashion Attribute Dataset
Jun 14, 2019
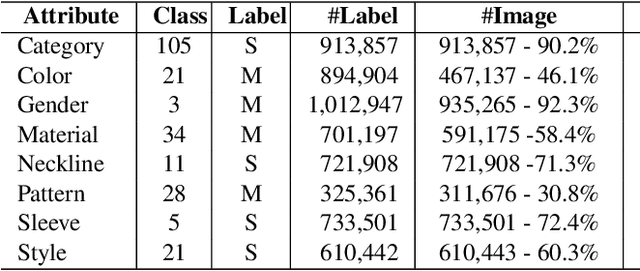
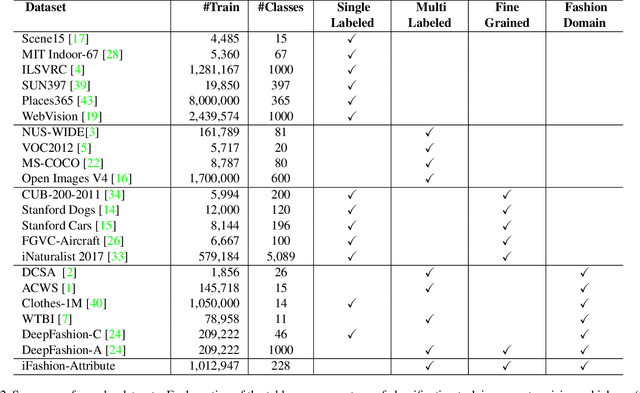
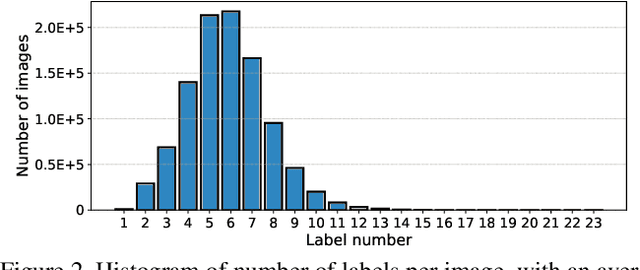
Large-scale image databases such as ImageNet have significantly advanced image classification and other visual recognition tasks. However much of these datasets are constructed only for single-label and coarse object-level classification. For real-world applications, multiple labels and fine-grained categories are often needed, yet very few such datasets exist publicly, especially those of large-scale and high quality. In this work, we contribute to the community a new dataset called iMaterialist Fashion Attribute (iFashion-Attribute) to address this problem in the fashion domain. The dataset is constructed from over one million fashion images with a label space that includes 8 groups of 228 fine-grained attributes in total. Each image is annotated by experts with multiple, high-quality fashion attributes. The result is the first known million-scale multi-label and fine-grained image dataset. We conduct extensive experiments and provide baseline results with modern deep Convolutional Neural Networks (CNNs). Additionally, we demonstrate models pre-trained on iFashion-Attribute achieve superior transfer learning performance on fashion related tasks compared with pre-training from ImageNet or other fashion datasets. Data is available at: https://github.com/visipedia/imat_fashion_comp