 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Answerability of LLMs for Long-Form Question Answering
Sep 15, 2023As we embark on a new era of LLMs, it becomes increasingly crucial to understand their capabilities, limitations, and differences. Toward making further progress in this direction, we strive to build a deeper understanding of the gaps between massive LLMs (e.g., ChatGPT) and smaller yet effective open-source LLMs and their distilled counterparts. To this end, we specifically focus on long-form question answering (LFQA) because it has several practical and impactful applications (e.g., troubleshooting, customer service, etc.) yet is still understudied and challenging for LLMs. We propose a question-generation method from abstractive summaries and show that generating follow-up questions from summaries of long documents can create a challenging setting for LLMs to reason and infer from long contexts. Our experimental results confirm that: (1) our proposed method of generating questions from abstractive summaries pose a challenging setup for LLMs and shows performance gaps between LLMs like ChatGPT and open-source LLMs (Alpaca, Llama) (2) open-source LLMs exhibit decreased reliance on context for generated questions from the original document, but their generation capabilities drop significantly on generated questions from summaries -- especially for longer contexts (>1024 tokens)
XGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.
Exploring the Integration Strategies of Retriever and Large Language Models
Aug 24, 2023



The integration of retrieved passages and large language models (LLMs), such as ChatGPTs, has significantly contributed to improving open-domain question answering. However, there is still a lack of exploration regarding the optimal approach for incorporating retrieved passages into the answer generation process. This paper aims to fill this gap by investigating different methods of combining retrieved passages with LLMs to enhance answer generation. We begin by examining the limitations of a commonly-used concatenation approach. Surprisingly, this approach often results in generating "unknown" outputs, even when the correct document is among the top-k retrieved passages. To address this issue, we explore four alternative strategies for integrating the retrieved passages with the LLMs. These strategies include two single-round methods that utilize chain-of-thought reasoning and two multi-round strategies that incorporate feedback loops. Through comprehensive analyses and experiments, we provide insightful observations on how to effectively leverage retrieved passages to enhance the answer generation capability of LLMs.
Few-shot Unified Question Answering: Tuning Models or Prompts?
May 23, 2023Question-answering (QA) tasks often investigate specific question types, knowledge domains, or reasoning skills, leading to specialized models catering to specific categories of QA tasks. While recent research has explored the idea of unified QA models, such models are usually explored for high-resource scenarios and require re-training to extend their capabilities. To overcome these drawbacks, the paper explores the potential of two paradigms of tuning, model, and prompts, for unified QA under a low-resource setting. The paper provides an exhaustive analysis of their applicability using 16 QA datasets, revealing that prompt tuning can perform as well as model tuning in a few-shot setting with a good initialization. The study also shows that parameter-sharing results in superior few-shot performance, simple knowledge transfer techniques for prompt initialization can be effective, and prompt tuning achieves a significant performance boost from pre-training in a low-resource regime. The research offers insights into the advantages and limitations of prompt tuning for unified QA in a few-shot setting, contributing to the development of effective and efficient systems in low-resource scenarios.
Answering Complex Questions over Text by Hybrid Question Parsing and Execution
May 12, 2023The dominant paradigm of textual question answering systems is based on end-to-end neural networks, which excels at answering natural language questions but falls short on complex ones. This stands in contrast to the broad adaptation of semantic parsing approaches over structured data sources (e.g., relational database, knowledge graphs), that convert natural language questions to logical forms and execute them with query engines. Towards combining the strengths of neural and symbolic methods, we propose a framework of question parsing and execution on textual QA. It comprises two central pillars: (1) We parse the question of varying complexity into an intermediate representation, named H-expression, which is composed of simple questions as the primitives and symbolic operations representing the relationships among them; (2) To execute the resulting H-expressions, we design a hybrid executor, which integrates the deterministic rules to translate the symbolic operations with a drop-in neural reader network to answer each decomposed simple question. Hence, the proposed framework can be viewed as a top-down question parsing followed by a bottom-up answer backtracking. The resulting H-expressions closely guide the execution process, offering higher precision besides better interpretability while still preserving the advantages of the neural readers for resolving its primitive elements. Our extensive experiments on MuSiQue, 2WikiQA, HotpotQA, and NQ show that the proposed parsing and hybrid execution framework outperforms existing approaches in supervised, few-shot, and zero-shot settings, while also effectively exposing its underlying reasoning process.
Efficiently Aligned Cross-Lingual Transfer Learning for Conversational Tasks using Prompt-Tuning
Apr 03, 2023



Cross-lingual transfer of language models trained on high-resource languages like English has been widely studied for many NLP tasks, but focus on conversational tasks has been rather limited. This is partly due to the high cost of obtaining non-English conversational data, which results in limited coverage. In this work, we introduce XSGD, a parallel and large-scale multilingual conversation dataset that we created by translating the English-only Schema-Guided Dialogue (SGD) dataset (Rastogi et al., 2020) into 105 other languages. XSGD contains approximately 330k utterances per language. To facilitate aligned cross-lingual representations, we develop an efficient prompt-tuning-based method for learning alignment prompts. We also investigate two different classifiers: NLI-based and vanilla classifiers, and test cross-lingual capability enabled by the aligned prompts. We evaluate our model's cross-lingual generalization capabilities on two conversation tasks: slot-filling and intent classification. Our results demonstrate the strong and efficient modeling ability of NLI-based classifiers and the large cross-lingual transfer improvements achieved by our aligned prompts, particularly in few-shot settings.
Unsupervised Dense Retrieval Deserves Better Positive Pairs: Scalable Augmentation with Query Extraction and Generation
Dec 17, 2022Dense retrievers have made significant strides in obtaining state-of-the-art results on text retrieval and open-domain question answering (ODQA). Yet most of these achievements were made possible with the help of large annotated datasets, unsupervised learning for dense retrieval models remains an open problem. In this work, we explore two categories of methods for creating pseudo query-document pairs, named query extraction (QExt) and transferred query generation (TQGen), to augment the retriever training in an annotation-free and scalable manner. Specifically, QExt extracts pseudo queries by document structures or selecting salient random spans, and TQGen utilizes generation models trained for other NLP tasks (e.g., summarization) to produce pseudo queries. Extensive experiments show that dense retrievers trained with individual augmentation methods can perform comparably well with multiple strong baselines, and combining them leads to further improvements, achieving state-of-the-art performance of unsupervised dense retrieval on both BEIR and ODQA datasets.
Uni-Parser: Unified Semantic Parser for Question Answering on Knowledge Base and Database
Nov 09, 2022Parsing natural language questions into executable logical forms is a useful and interpretable way to perform question answering on structured data such as knowledge bases (KB) or databases (DB). However, existing approaches on semantic parsing cannot adapt to both modalities, as they suffer from the exponential growth of the logical form candidates and can hardly generalize to unseen data. In this work, we propose Uni-Parser, a unified semantic parser for question answering (QA) on both KB and DB. We introduce the primitive (relation and entity in KB, and table name, column name and cell value in DB) as an essential element in our framework. The number of primitives grows linearly with the number of retrieved relations in KB and DB, preventing us from dealing with exponential logic form candidates. We leverage the generator to predict final logical forms by altering and composing topranked primitives with different operations (e.g. select, where, count). With sufficiently pruned search space by a contrastive primitive ranker, the generator is empowered to capture the composition of primitives enhancing its generalization ability. We achieve competitive results on multiple KB and DB QA benchmarks more efficiently, especially in the compositional and zero-shot settings.
Improving the Faithfulness of Abstractive Summarization via Entity Coverage Control
Jul 05, 2022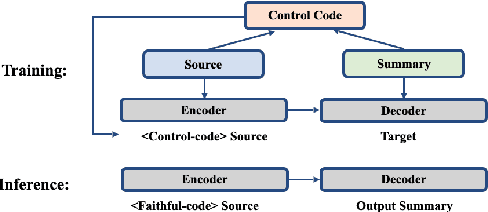
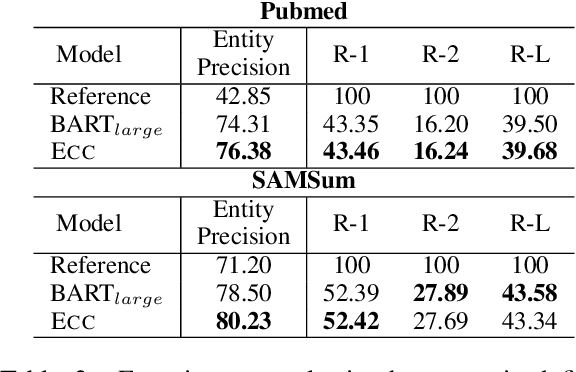
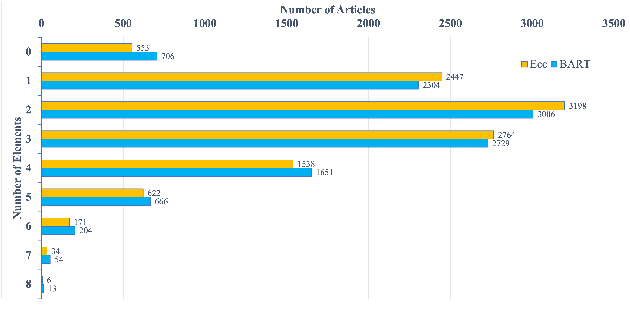
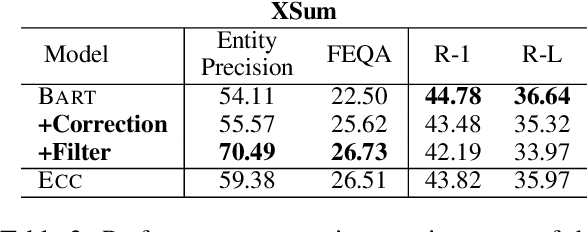
Abstractive summarization systems leveraging pre-training language models have achieved superior results on benchmark datasets. However, such models have been shown to be more prone to hallucinate facts that are unfaithful to the input context. In this paper, we propose a method to remedy entity-level extrinsic hallucinations with Entity Coverage Control (ECC). We first compute entity coverage precision and prepend the corresponding control code for each training example, which implicitly guides the model to recognize faithfulness contents in the training phase. We further extend our method via intermediate fine-tuning on large but noisy data extracted from Wikipedia to unlock zero-shot summarization. We show that the proposed method leads to more faithful and salient abstractive summarization in supervised fine-tuning and zero-shot settings according to our experimental results on three benchmark datasets XSum, Pubmed, and SAMSum of very different domains and styles.
Modeling Multi-hop Question Answering as Single Sequence Prediction
May 18, 2022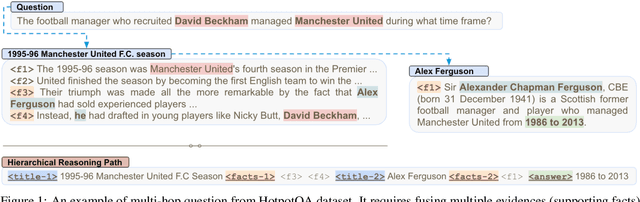
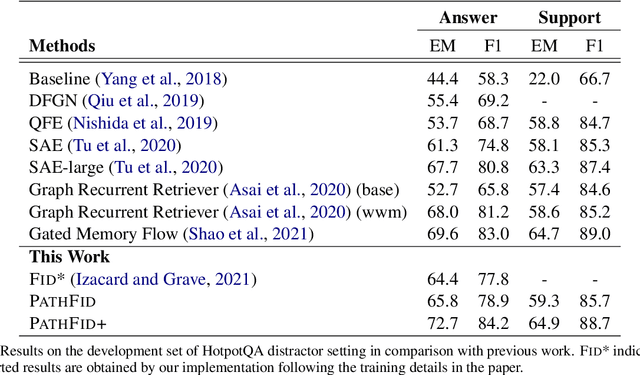
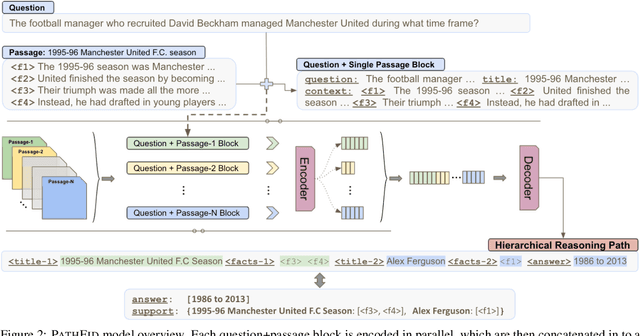
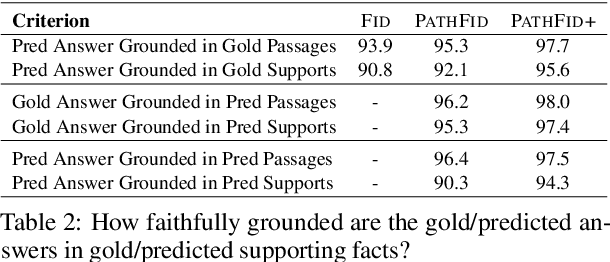
Fusion-in-decoder (Fid) (Izacard and Grave, 2020) is a generative question answering (QA) model that leverages passage retrieval with a pre-trained transformer and pushed the state of the art on single-hop QA. However, the complexity of multi-hop QA hinders the effectiveness of the generative QA approach. In this work, we propose a simple generative approach (PathFid) that extends the task beyond just answer generation by explicitly modeling the reasoning process to resolve the answer for multi-hop questions. By linearizing the hierarchical reasoning path of supporting passages, their key sentences, and finally the factoid answer, we cast the problem as a single sequence prediction task. To facilitate complex reasoning with multiple clues, we further extend the unified flat representation of multiple input documents by encoding cross-passage interactions. Our extensive experiments demonstrate that PathFid leads to strong performance gains on two multi-hop QA datasets: HotpotQA and IIRC. Besides the performance gains, PathFid is more interpretable, which in turn yields answers that are more faithfully grounded to the supporting passages and facts compared to the baseline Fid model.