 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Question-Guided Video Representation for Multi-Turn Video Question Answering
Paper and Code
Jul 31, 2019
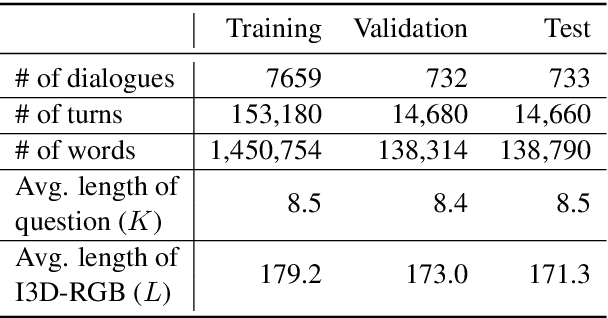
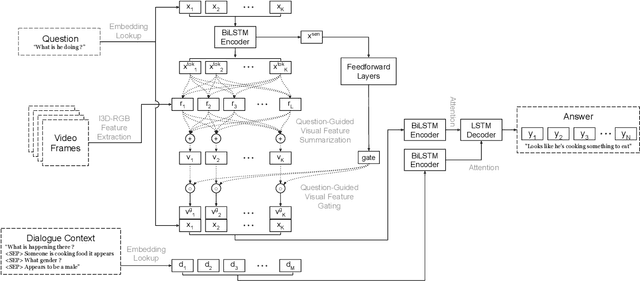
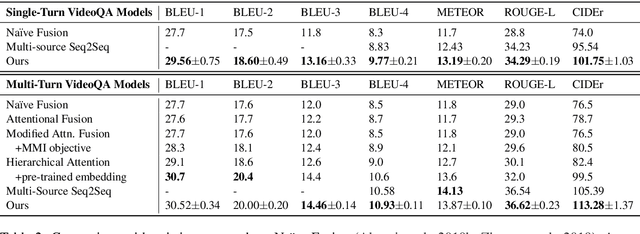
Understanding and conversing about dynamic scenes is one of the key capabilities of AI agents that navigate the environment and convey useful information to humans. Video question answering is a specific scenario of such AI-human interaction where an agent generates a natural language response to a question regarding the video of a dynamic scene. Incorporating features from multiple modalities, which often provide supplementary information, is one of the challenging aspects of video question answering. Furthermore, a question often concerns only a small segment of the video, hence encoding the entire video sequence using a recurrent neural network is not computationally efficient. Our proposed question-guided video representation module efficiently generates the token-level video summary guided by each word in the question. The learned representations are then fused with the question to generate the answer. Through empirical evaluation on the Audio Visual Scene-aware Dialog (AVSD) dataset, our proposed models in single-turn and multi-turn question answering achieve state-of-the-art performance on several automatic natural language generation evaluation metrics.