 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe EMPATHIC Framework for Task Learning from Implicit Human Feedback
Sep 28, 2020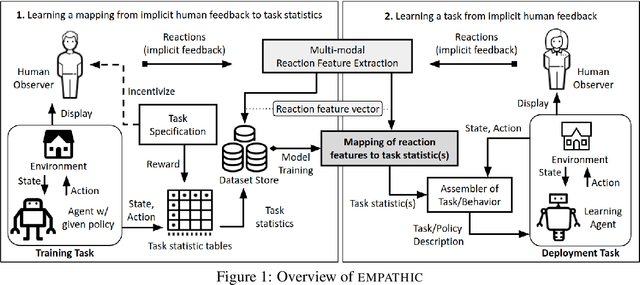



Reactions such as gestures, facial expressions, and vocalizations are an abundant, naturally occurring channel of information that humans provide during interactions. A robot or other agent could leverage an understanding of such implicit human feedback to improve its task performance at no cost to the human. This approach contrasts with common agent teaching methods based on demonstrations, critiques, or other guidance that need to be attentively and intentionally provided. In this paper, we first define the general problem of learning from implicit human feedback and then propose to address this problem through a novel data-driven framework, EMPATHIC. This two-stage method consists of (1) mapping implicit human feedback to relevant task statistics such as rewards, optimality, and advantage; and (2) using such a mapping to learn a task. We instantiate the first stage and three second-stage evaluations of the learned mapping. To do so, we collect a dataset of human facial reactions while participants observe an agent execute a sub-optimal policy for a prescribed training task. We train a deep neural network on this data and demonstrate its ability to (1) infer relative reward ranking of events in the training task from prerecorded human facial reactions; (2) improve the policy of an agent in the training task using live human facial reactions; and (3) transfer to a novel domain in which it evaluates robot manipulation trajectories.
ScrewNet: Category-Independent Articulation Model Estimation From Depth Images Using Screw Theory
Aug 24, 2020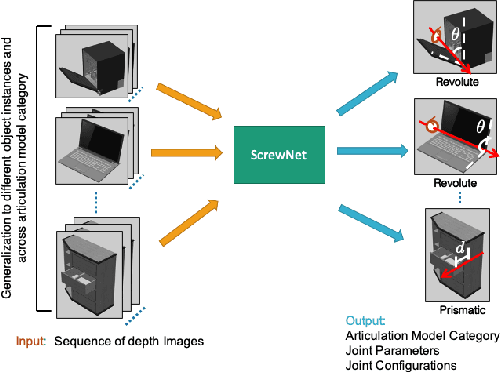
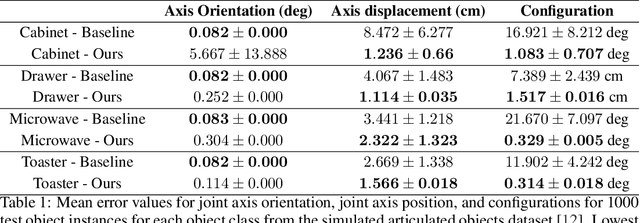
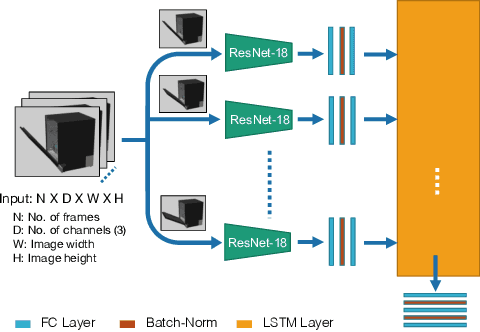
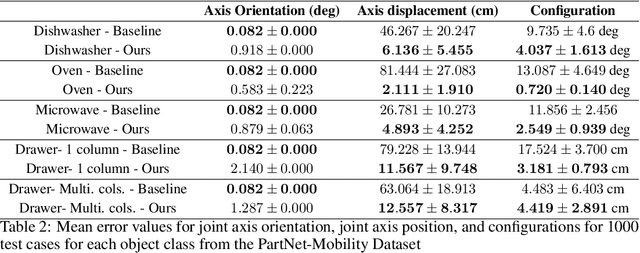
Robots in human environments will need to interact with a wide variety of articulated objects such as cabinets, drawers, and dishwashers while assisting humans in performing day-to-day tasks. Existing methods either require objects to be textured or need to know the articulation model category a priori for estimating the model parameters for an articulated object. We propose ScrewNet, a novel approach that estimates an object's articulation model directly from depth images without requiring a priori knowledge of the articulation model category. ScrewNet uses screw theory to unify the representation of different articulation types and perform category-independent articulation model estimation. We evaluate our approach on two benchmarking datasets and compare its performance with a current state-of-the-art method. Results demonstrate that ScrewNet can successfully estimate the articulation models and their parameters for novel objects across articulation model categories with better on average accuracy than the prior state-of-the-art method.
Bayesian Robust Optimization for Imitation Learning
Aug 04, 2020
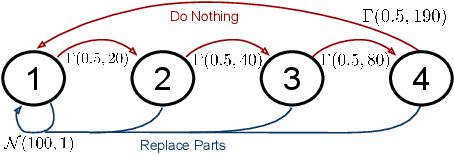
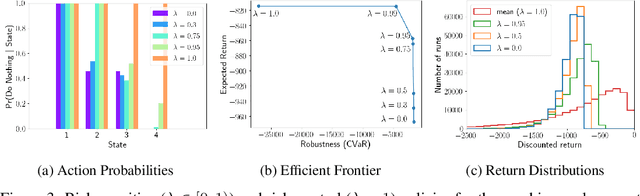
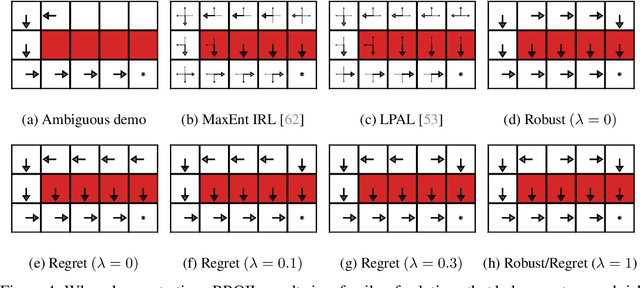
One of the main challenges in imitation learning is determining what action an agent should take when outside the state distribution of the demonstrations. Inverse reinforcement learning (IRL) can enable generalization to new states by learning a parameterized reward function, but these approaches still face uncertainty over the true reward function and corresponding optimal policy. Existing safe imitation learning approaches based on IRL deal with this uncertainty using a maxmin framework that optimizes a policy under the assumption of an adversarial reward function, whereas risk-neutral IRL approaches either optimize a policy for the mean or MAP reward function. While completely ignoring risk can lead to overly aggressive and unsafe policies, optimizing in a fully adversarial sense is also problematic as it can lead to overly conservative policies that perform poorly in practice. To provide a bridge between these two extremes, we propose Bayesian Robust Optimization for Imitation Learning (BROIL). BROIL leverages Bayesian reward function inference and a user specific risk tolerance to efficiently optimize a robust policy that balances expected return and conditional value at risk. Our empirical results show that BROIL provides a natural way to interpolate between return-maximizing and risk-minimizing behaviors and outperforms existing risk-sensitive and risk-neutral inverse reinforcement learning algorithms.
PixL2R: Guiding Reinforcement Learning Using Natural Language by Mapping Pixels to Rewards
Jul 30, 2020
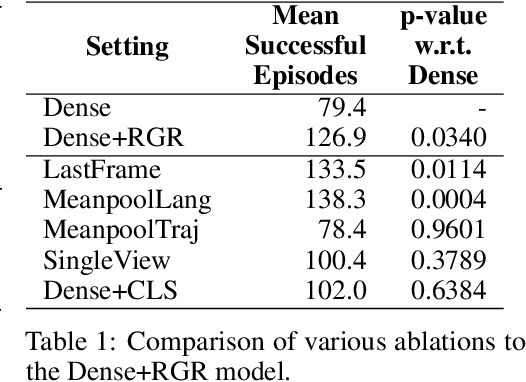
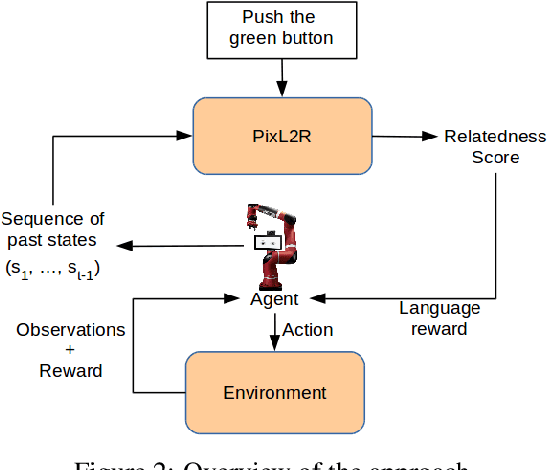
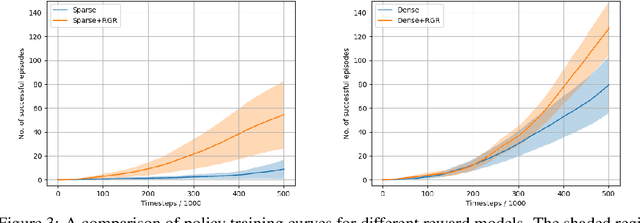
Reinforcement learning (RL), particularly in sparse reward settings, often requires prohibitively large numbers of interactions with the environment, thereby limiting its applicability to complex problems. To address this, several prior approaches have used natural language to guide the agent's exploration. However, these approaches typically operate on structured representations of the environment, and/or assume some structure in the natural language commands. In this work, we propose a model that directly maps pixels to rewards, given a free-form natural language description of the task, which can then be used for policy learning. Our experiments on the Meta-World robot manipulation domain show that language-based rewards significantly improves the sample efficiency of policy learning, both in sparse and dense reward settings.
Efficiently Guiding Imitation Learning Algorithms with Human Gaze
Mar 05, 2020
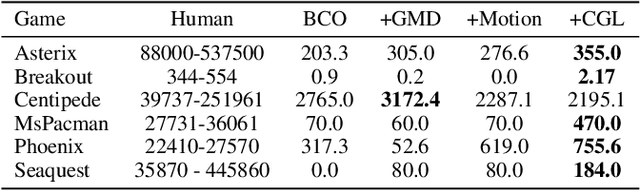
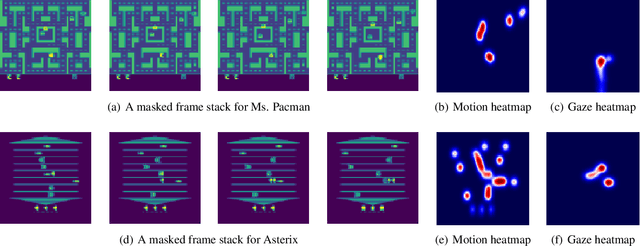
Human gaze is known to be an intention-revealing signal in human demonstrations of tasks. In this work, we use gaze cues from human demonstrators to enhance the performance of state-of-the-art inverse reinforcement learning (IRL) and behavioral cloning (BC) algorithms. We propose a novel approach for utilizing gaze data in a computationally efficient manner --- encoding the human's attention as part of an auxiliary loss function, without adding any additional learnable parameters to those models and without requiring gaze data at test time. The auxiliary loss encourages a network to have convolutional activations in regions where the human's gaze fixated. We show how to augment any existing convolutional architecture with our auxiliary gaze loss (coverage-based gaze loss or CGL) that can guide learning toward a better reward function or policy. We show that our proposed approach improves performance of both BC and IRL methods on a variety of Atari games. We also compare against two baseline methods for utilizing gaze data with imitation learning methods. Our approach outperforms a baseline method, called gaze-modulated dropout (GMD), and is comparable to another method (AGIL) which uses gaze as input to the network and thus increases the amount of learnable parameters.
Safe Imitation Learning via Fast Bayesian Reward Inference from Preferences
Feb 21, 2020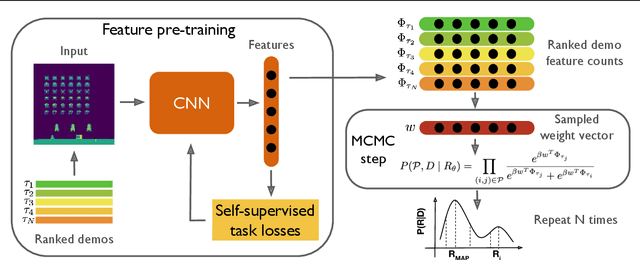

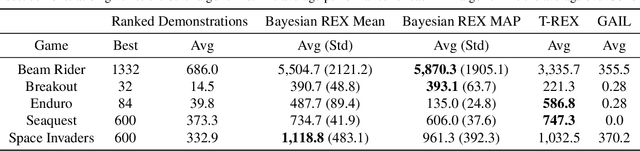
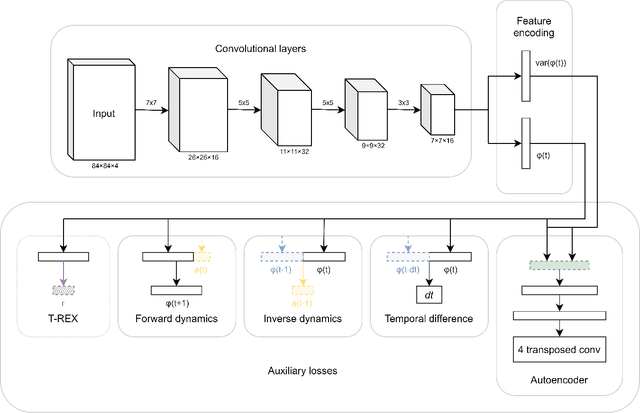
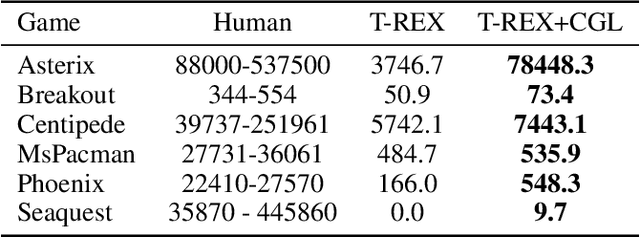
Bayesian reward learning from demonstrations enables rigorous safety and uncertainty analysis when performing imitation learning. However, Bayesian reward learning methods are typically computationally intractable for complex control problems. We propose a highly efficient Bayesian reward learning algorithm that scales to high-dimensional imitation learning problems by first pre-training a low-dimensional feature encoding via self-supervised tasks and then leveraging preferences over demonstrations to perform fast Bayesian inference. We evaluate our proposed approach on the task of learning to play Atari games from demonstrations, without access to the game score. For Atari games our approach enables us to generate 100,000 samples from the posterior over reward functions in only 5 minutes using a personal laptop. Furthermore, our proposed approach achieves comparable or better imitation learning performance than state-of-the-art methods that only find a point estimate of the reward function. Finally, we show that our approach enables efficient high-confidence policy performance bounds. We show that these high-confidence performance bounds can be used to rank the performance and risk of a variety of evaluation policies, despite not having samples of the reward function. We also show evidence that high-confidence performance bounds can be used to detect reward hacking in complex imitation learning problems.
Local Nonparametric Meta-Learning
Feb 09, 2020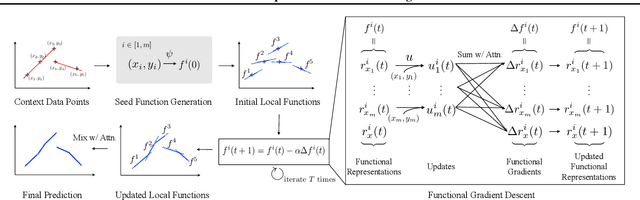
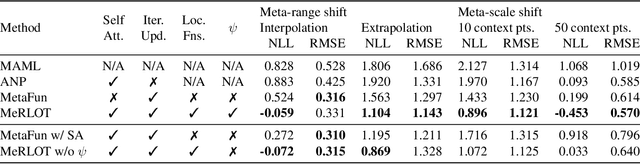
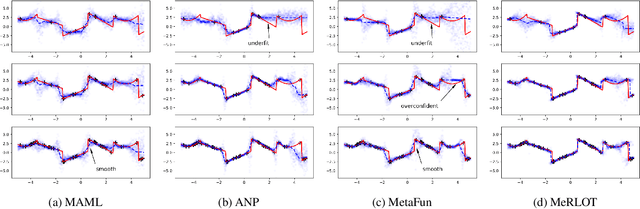
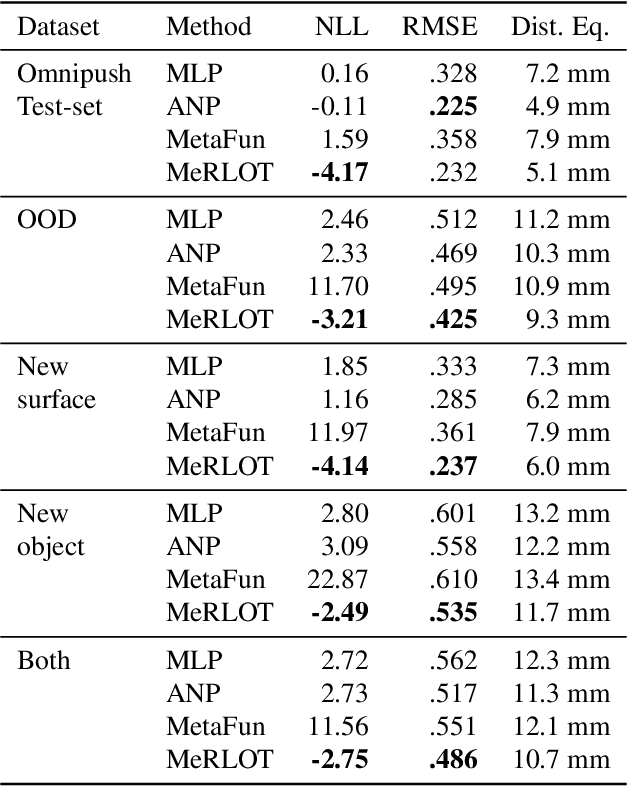
A central goal of meta-learning is to find a learning rule that enables fast adaptation across a set of tasks, by learning the appropriate inductive bias for that set. Most meta-learning algorithms try to find a \textit{global} learning rule that encodes this inductive bias. However, a global learning rule represented by a fixed-size representation is prone to meta-underfitting or -overfitting since the right representational power for a task set is difficult to choose a priori. Even when chosen correctly, we show that global, fixed-size representations often fail when confronted with certain types of out-of-distribution tasks, even when the same inductive bias is appropriate. To address these problems, we propose a novel nonparametric meta-learning algorithm that utilizes a meta-trained local learning rule, building on recent ideas in attention-based and functional gradient-based meta-learning. In several meta-regression problems, we show improved meta-generalization results using our local, nonparametric approach and achieve state-of-the-art results in the robotics benchmark, Omnipush.
Deep Bayesian Reward Learning from Preferences
Dec 10, 2019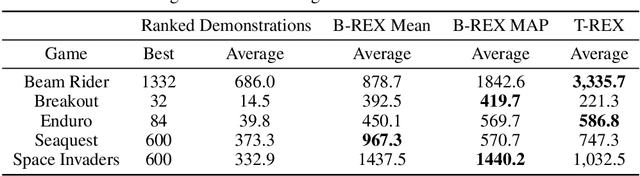
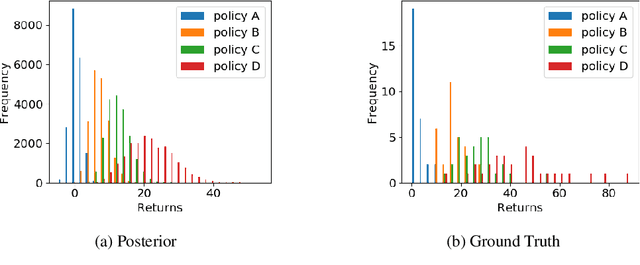
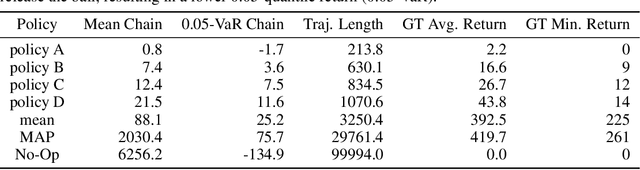
Bayesian inverse reinforcement learning (IRL) methods are ideal for safe imitation learning, as they allow a learning agent to reason about reward uncertainty and the safety of a learned policy. However, Bayesian IRL is computationally intractable for high-dimensional problems because each sample from the posterior requires solving an entire Markov Decision Process (MDP). While there exist non-Bayesian deep IRL methods, these methods typically infer point estimates of reward functions, precluding rigorous safety and uncertainty analysis. We propose Bayesian Reward Extrapolation (B-REX), a highly efficient, preference-based Bayesian reward learning algorithm that scales to high-dimensional, visual control tasks. Our approach uses successor feature representations and preferences over demonstrations to efficiently generate samples from the posterior distribution over the demonstrator's reward function without requiring an MDP solver. Using samples from the posterior, we demonstrate how to calculate high-confidence bounds on policy performance in the imitation learning setting, in which the ground-truth reward function is unknown. We evaluate our proposed approach on the task of learning to play Atari games via imitation learning from pixel inputs, with no access to the game score. We demonstrate that B-REX learns imitation policies that are competitive with a state-of-the-art deep imitation learning method that only learns a point estimate of the reward function. Furthermore, we demonstrate that samples from the posterior generated via B-REX can be used to compute high-confidence performance bounds for a variety of evaluation policies. We show that high-confidence performance bounds are useful for accurately ranking different evaluation policies when the reward function is unknown. We also demonstrate that high-confidence performance bounds may be useful for detecting reward hacking.
Learning Hybrid Object Kinematics for Efficient Hierarchical Planning Under Uncertainty
Jul 21, 2019

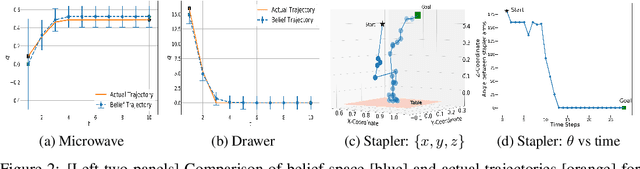
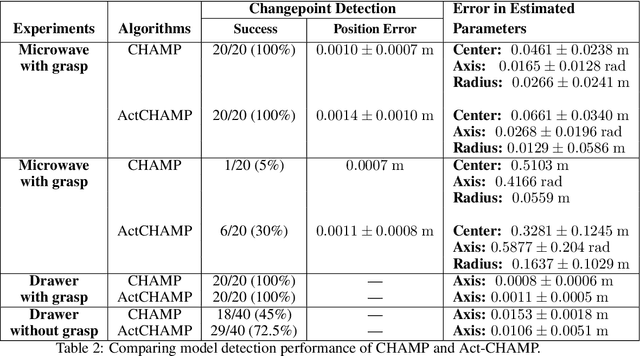
Sudden changes in the dynamics of robotic tasks, such as contact with an object or the latching of a door, are often viewed as inconvenient discontinuities that make manipulation difficult. However, when these transitions are well-understood, they can be leveraged to reduce uncertainty or aid manipulation---for example, wiggling a screw to determine if it is fully inserted or not. Current model-free reinforcement learning approaches require large amounts of data to learn to leverage such dynamics, scale poorly as problem complexity grows, and do not transfer well to significantly different problems. By contrast, hierarchical planning-based methods scale well via plan decomposition and work well on a wide variety of problems, but often rely on precise hand-specified models and task decompositions. To combine the advantages of these opposing paradigms, we propose a new method, Act-CHAMP, which (1) learns hybrid kinematics models of objects from unsegmented data, (2) leverages actions, in addition to states, to outperform a state-of-the-art observation-only inference method, and (3) does so in a manner that is compatible with efficient, hierarchical POMDP planning. Beyond simply coping with challenging dynamics, we show that our end-to-end system leverages the learned kinematics to reduce uncertainty, plan efficiently, and use objects in novel ways not encountered during training.
Understanding Teacher Gaze Patterns for Robot Learning
Jul 16, 2019
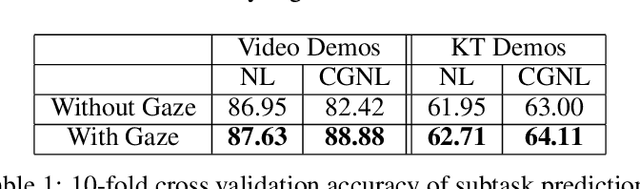

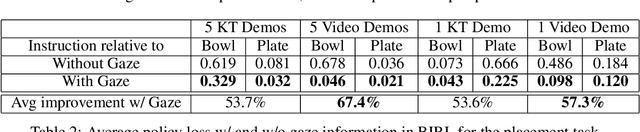
Human gaze is known to be a strong indicator of underlying human intentions and goals during manipulation tasks. This work studies gaze patterns of human teachers demonstrating tasks to robots and proposes ways in which such patterns can be used to enhance robot learning. Using both kinesthetic teaching and video demonstrations, we identify novel intention-revealing gaze behaviors during teaching. These prove to be informative in a variety of problems ranging from reference frame inference to segmentation of multi-step tasks. Based on our findings, we propose two proof-of-concept algorithms which show that gaze data can enhance subtask classification for a multi-step task up to 6% and reward inference and policy learning for a single-step task up to 67%. Our findings provide a foundation for a model of natural human gaze in robot learning from demonstration settings and present open problems for utilizing human gaze to enhance robot learning.