 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Labels: Empowering Human with Natural Language Explanations through a Novel Active-Learning Architecture
May 22, 2023



Data annotation is a costly task; thus, researchers have proposed low-scenario learning techniques like Active-Learning (AL) to support human annotators; Yet, existing AL works focus only on the label, but overlook the natural language explanation of a data point, despite that real-world humans (e.g., doctors) often need both the labels and the corresponding explanations at the same time. This work proposes a novel AL architecture to support and reduce human annotations of both labels and explanations in low-resource scenarios. Our AL architecture incorporates an explanation-generation model that can explicitly generate natural language explanations for the prediction model and for assisting humans' decision-making in real-world. For our AL framework, we design a data diversity-based AL data selection strategy that leverages the explanation annotations. The automated AL simulation evaluations demonstrate that our data selection strategy consistently outperforms traditional data diversity-based strategy; furthermore, human evaluation demonstrates that humans prefer our generated explanations to the SOTA explanation-generation system.
Bridging Nations: Quantifying the Role of Multilinguals in Communication on Social Media
Apr 07, 2023



Social media enables the rapid spread of many kinds of information, from memes to social movements. However, little is known about how information crosses linguistic boundaries. We apply causal inference techniques on the European Twitter network to quantify multilingual users' structural role and communication influence in cross-lingual information exchange. Overall, multilinguals play an essential role; posting in multiple languages increases betweenness centrality by 13%, and having a multilingual network neighbor increases monolinguals' odds of sharing domains and hashtags from another language 16-fold and 4-fold, respectively. We further show that multilinguals have a greater impact on diffusing information less accessible to their monolingual compatriots, such as information from far-away countries and content about regional politics, nascent social movements, and job opportunities. By highlighting information exchange across borders, this work sheds light on a crucial component of how information and ideas spread around the world.
Green Federated Learning
Mar 26, 2023



The rapid progress of AI is fueled by increasingly large and computationally intensive machine learning models and datasets. As a consequence, the amount of compute used in training state-of-the-art models is exponentially increasing (doubling every 10 months between 2015 and 2022), resulting in a large carbon footprint. Federated Learning (FL) - a collaborative machine learning technique for training a centralized model using data of decentralized entities - can also be resource-intensive and have a significant carbon footprint, particularly when deployed at scale. Unlike centralized AI that can reliably tap into renewables at strategically placed data centers, cross-device FL may leverage as many as hundreds of millions of globally distributed end-user devices with diverse energy sources. Green AI is a novel and important research area where carbon footprint is regarded as an evaluation criterion for AI, alongside accuracy, convergence speed, and other metrics. In this paper, we propose the concept of Green FL, which involves optimizing FL parameters and making design choices to minimize carbon emissions consistent with competitive performance and training time. The contributions of this work are two-fold. First, we adopt a data-driven approach to quantify the carbon emissions of FL by directly measuring real-world at-scale FL tasks running on millions of phones. Second, we present challenges, guidelines, and lessons learned from studying the trade-off between energy efficiency, performance, and time-to-train in a production FL system. Our findings offer valuable insights into how FL can reduce its carbon footprint, and they provide a foundation for future research in the area of Green AI.
When does the student surpass the teacher? Federated Semi-supervised Learning with Teacher-Student EMA
Jan 24, 2023Semi-Supervised Learning (SSL) has received extensive attention in the domain of computer vision, leading to development of promising approaches such as FixMatch. In scenarios where training data is decentralized and resides on client devices, SSL must be integrated with privacy-aware training techniques such as Federated Learning. We consider the problem of federated image classification and study the performance and privacy challenges with existing federated SSL (FSSL) approaches. Firstly, we note that even state-of-the-art FSSL algorithms can trivially compromise client privacy and other real-world constraints such as client statelessness and communication cost. Secondly, we observe that it is challenging to integrate EMA (Exponential Moving Average) updates into the federated setting, which comes at a trade-off between performance and communication cost. We propose a novel approach FedSwitch, that improves privacy as well as generalization performance through Exponential Moving Average (EMA) updates. FedSwitch utilizes a federated semi-supervised teacher-student EMA framework with two features - local teacher adaptation and adaptive switching between teacher and student for pseudo-label generation. Our proposed approach outperforms the state-of-the-art on federated image classification, can be adapted to real-world constraints, and achieves good generalization performance with minimal communication cost overhead.
Pruning Compact ConvNets for Efficient Inference
Jan 11, 2023Neural network pruning is frequently used to compress over-parameterized networks by large amounts, while incurring only marginal drops in generalization performance. However, the impact of pruning on networks that have been highly optimized for efficient inference has not received the same level of attention. In this paper, we analyze the effect of pruning for computer vision, and study state-of-the-art ConvNets, such as the FBNetV3 family of models. We show that model pruning approaches can be used to further optimize networks trained through NAS (Neural Architecture Search). The resulting family of pruned models can consistently obtain better performance than existing FBNetV3 models at the same level of computation, and thus provide state-of-the-art results when trading off between computational complexity and generalization performance on the ImageNet benchmark. In addition to better generalization performance, we also demonstrate that when limited computation resources are available, pruning FBNetV3 models incur only a fraction of GPU-hours involved in running a full-scale NAS.
LaSQuE: Improved Zero-Shot Classification from Explanations Through Quantifier Modeling and Curriculum Learning
Dec 18, 2022A hallmark of human intelligence is the ability to learn new concepts purely from language. Several recent approaches have explored training machine learning models via natural language supervision. However, these approaches fall short in leveraging linguistic quantifiers (such as 'always' or 'rarely') and mimicking humans in compositionally learning complex tasks. Here, we present LaSQuE, a method that can learn zero-shot classifiers from language explanations by using three new strategies - (1) modeling the semantics of linguistic quantifiers in explanations (including exploiting ordinal strength relationships, such as 'always' > 'likely'), (2) aggregating information from multiple explanations using an attention-based mechanism, and (3) model training via curriculum learning. With these strategies, LaSQuE outperforms prior work, showing an absolute gain of up to 7% in generalizing to unseen real-world classification tasks.
A Comprehensive Review of Digital Twin -- Part 2: Roles of Uncertainty Quantification and Optimization, a Battery Digital Twin, and Perspectives
Aug 27, 2022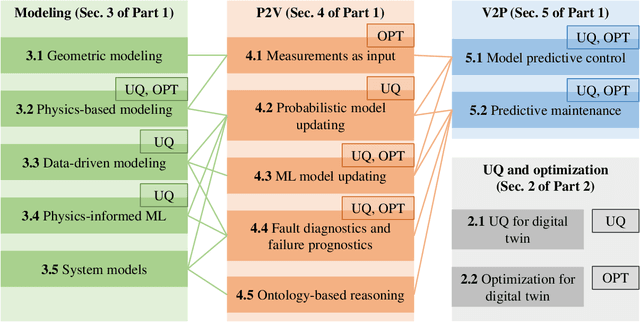
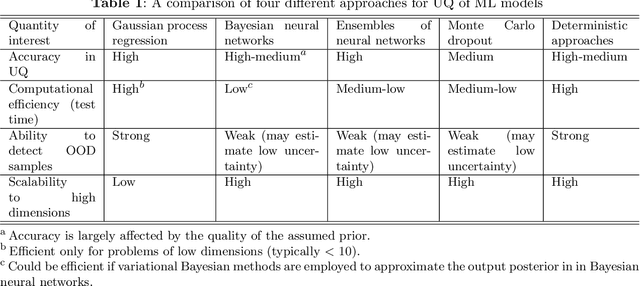
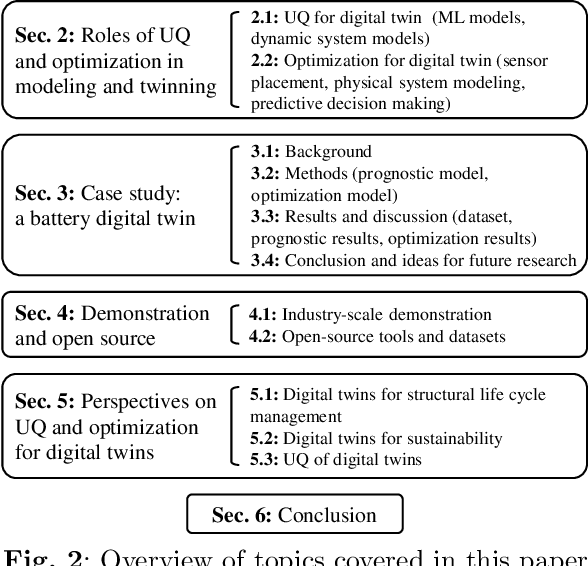
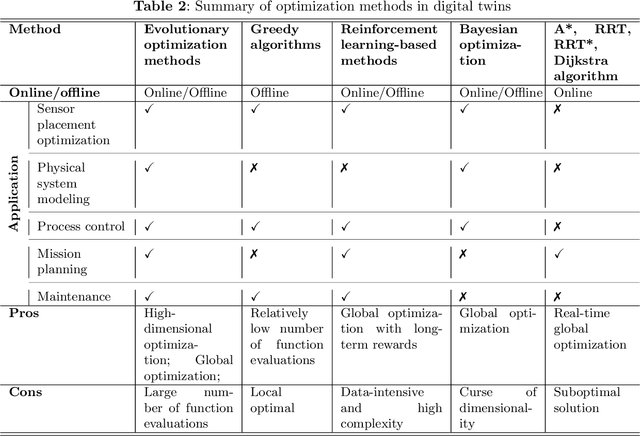
As an emerging technology in the era of Industry 4.0, digital twin is gaining unprecedented attention because of its promise to further optimize process design, quality control, health monitoring, decision and policy making, and more, by comprehensively modeling the physical world as a group of interconnected digital models. In a two-part series of papers, we examine the fundamental role of different modeling techniques, twinning enabling technologies, and uncertainty quantification and optimization methods commonly used in digital twins. This second paper presents a literature review of key enabling technologies of digital twins, with an emphasis on uncertainty quantification, optimization methods, open source datasets and tools, major findings, challenges, and future directions. Discussions focus on current methods of uncertainty quantification and optimization and how they are applied in different dimensions of a digital twin. Additionally, this paper presents a case study where a battery digital twin is constructed and tested to illustrate some of the modeling and twinning methods reviewed in this two-part review. Code and preprocessed data for generating all the results and figures presented in the case study are available on GitHub.
A Comprehensive Review of Digital Twin -- Part 1: Modeling and Twinning Enabling Technologies
Aug 26, 2022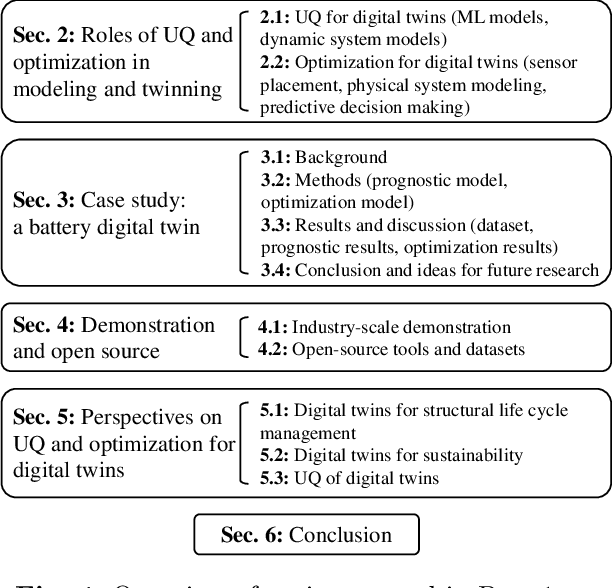
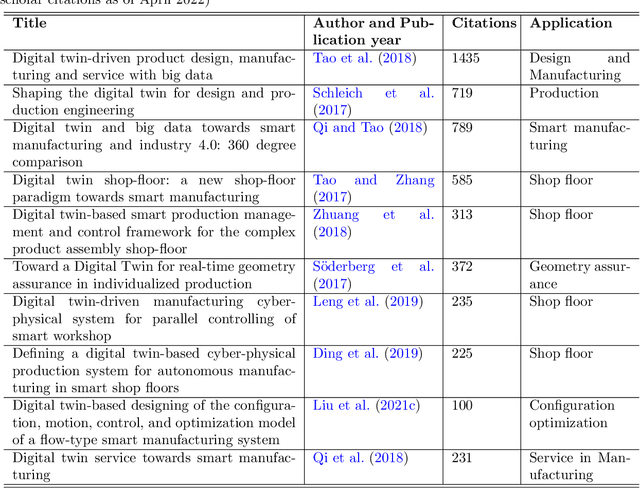
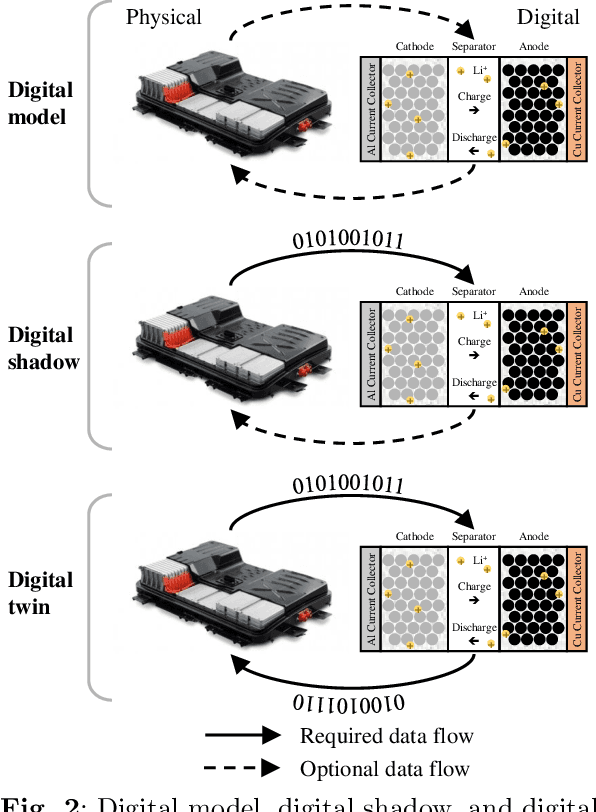
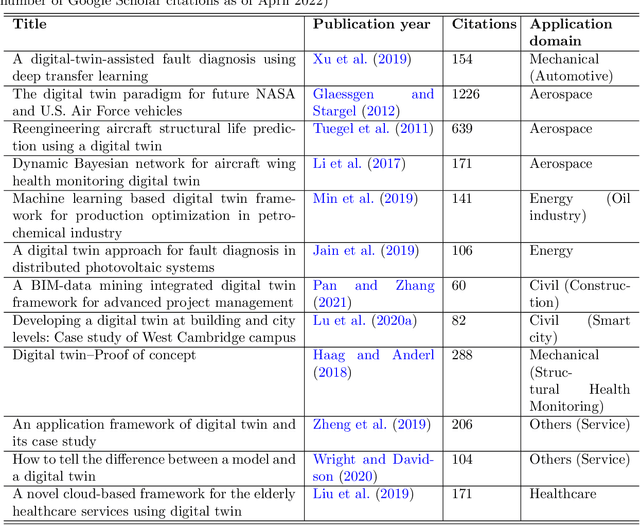
As an emerging technology in the era of Industry 4.0, digital twin is gaining unprecedented attention because of its promise to further optimize process design, quality control, health monitoring, decision and policy making, and more, by comprehensively modeling the physical world as a group of interconnected digital models. In a two-part series of papers, we examine the fundamental role of different modeling techniques, twinning enabling technologies, and uncertainty quantification and optimization methods commonly used in digital twins. This first paper presents a thorough literature review of digital twin trends across many disciplines currently pursuing this area of research. Then, digital twin modeling and twinning enabling technologies are further analyzed by classifying them into two main categories: physical-to-virtual, and virtual-to-physical, based on the direction in which data flows. Finally, this paper provides perspectives on the trajectory of digital twin technology over the next decade, and introduces a few emerging areas of research which will likely be of great use in future digital twin research. In part two of this review, the role of uncertainty quantification and optimization are discussed, a battery digital twin is demonstrated, and more perspectives on the future of digital twin are shared.
Reconciling Security and Communication Efficiency in Federated Learning
Jul 26, 2022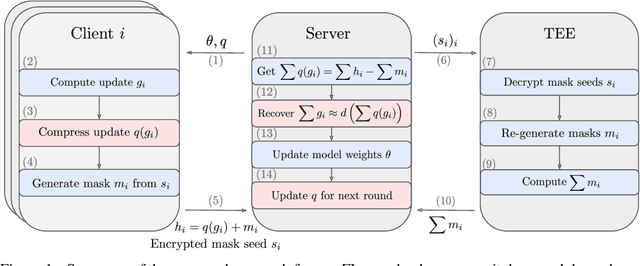

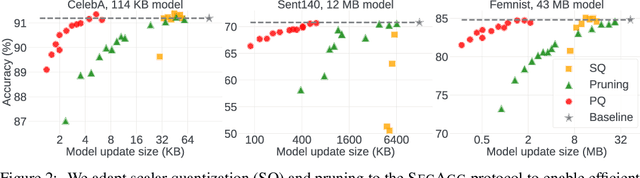
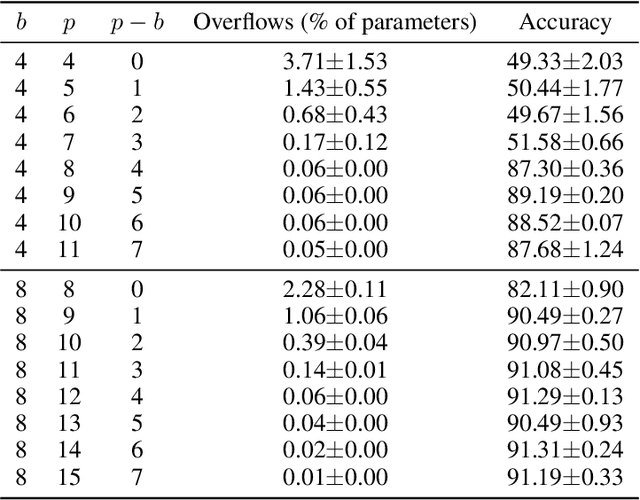
Cross-device Federated Learning is an increasingly popular machine learning setting to train a model by leveraging a large population of client devices with high privacy and security guarantees. However, communication efficiency remains a major bottleneck when scaling federated learning to production environments, particularly due to bandwidth constraints during uplink communication. In this paper, we formalize and address the problem of compressing client-to-server model updates under the Secure Aggregation primitive, a core component of Federated Learning pipelines that allows the server to aggregate the client updates without accessing them individually. In particular, we adapt standard scalar quantization and pruning methods to Secure Aggregation and propose Secure Indexing, a variant of Secure Aggregation that supports quantization for extreme compression. We establish state-of-the-art results on LEAF benchmarks in a secure Federated Learning setup with up to 40$\times$ compression in uplink communication with no meaningful loss in utility compared to uncompressed baselines.
Pulse Shape Simulation and Discrimination using Machine-Learning Techniques
Jun 30, 2022

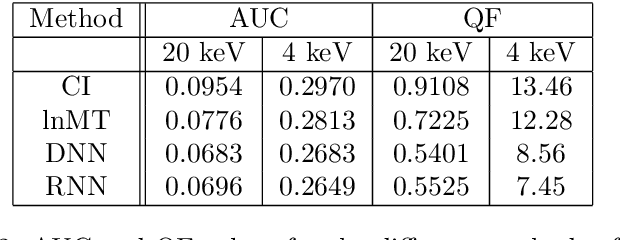
An essential metric for the quality of a particle-identification experiment is its statistical power to discriminate between signal and background. Pulse shape discrimination (PSD) is a basic method for this purpose in many nuclear, high-energy, and rare-event search experiments where scintillator detectors are used. Conventional techniques exploit the difference between decay-times of the pulse from signal and background events or pulse signals caused by different types of radiation quanta to achieve good discrimination. However, such techniques are efficient only when the total light-emission is sufficient to get a proper pulse profile. This is only possible when there is significant recoil energy due to the incident particle in the detector. But, rare-event search experiments like neutrino or dark-matter direct search experiments don't always satisfy these conditions. Hence, it becomes imperative to have a method that can deliver very efficient discrimination in these scenarios. Neural network-based machine-learning algorithms have been used for classification problems in many areas of physics, especially in high-energy experiments, and have given better results compared to conventional techniques. We present the results of our investigations of two network-based methods viz. Dense Neural Network and Recurrent Neural Network, for pulse shape discrimination and compare the same with conventional methods.