 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Space Optimization: Improved Molecule Sequence Design by Latent Prompt Transformer
Feb 27, 2024



Designing molecules with desirable properties, such as drug-likeliness and high binding affinities towards protein targets, is a challenging problem. In this paper, we propose the Dual-Space Optimization (DSO) method that integrates latent space sampling and data space selection to solve this problem. DSO iteratively updates a latent space generative model and a synthetic dataset in an optimization process that gradually shifts the generative model and the synthetic data towards regions of desired property values. Our generative model takes the form of a Latent Prompt Transformer (LPT) where the latent vector serves as the prompt of a causal transformer. Our extensive experiments demonstrate effectiveness of the proposed method, which sets new performance benchmarks across single-objective, multi-objective and constrained molecule design tasks.
Single-Shot and Multi-Shot Feature Learning for Multi-Object Tracking
Nov 17, 2023Multi-Object Tracking (MOT) remains a vital component of intelligent video analysis, which aims to locate targets and maintain a consistent identity for each target throughout a video sequence. Existing works usually learn a discriminative feature representation, such as motion and appearance, to associate the detections across frames, which are easily affected by mutual occlusion and background clutter in practice. In this paper, we propose a simple yet effective two-stage feature learning paradigm to jointly learn single-shot and multi-shot features for different targets, so as to achieve robust data association in the tracking process. For the detections without being associated, we design a novel single-shot feature learning module to extract discriminative features of each detection, which can efficiently associate targets between adjacent frames. For the tracklets being lost several frames, we design a novel multi-shot feature learning module to extract discriminative features of each tracklet, which can accurately refind these lost targets after a long period. Once equipped with a simple data association logic, the resulting VisualTracker can perform robust MOT based on the single-shot and multi-shot feature representations. Extensive experimental results demonstrate that our method has achieved significant improvements on MOT17 and MOT20 datasets while reaching state-of-the-art performance on DanceTrack dataset.
FFINet: Future Feedback Interaction Network for Motion Forecasting
Nov 08, 2023Motion forecasting plays a crucial role in autonomous driving, with the aim of predicting the future reasonable motions of traffic agents. Most existing methods mainly model the historical interactions between agents and the environment, and predict multi-modal trajectories in a feedforward process, ignoring potential trajectory changes caused by future interactions between agents. In this paper, we propose a novel Future Feedback Interaction Network (FFINet) to aggregate features the current observations and potential future interactions for trajectory prediction. Firstly, we employ different spatial-temporal encoders to embed the decomposed position vectors and the current position of each scene, providing rich features for the subsequent cross-temporal aggregation. Secondly, the relative interaction and cross-temporal aggregation strategies are sequentially adopted to integrate features in the current fusion module, observation interaction module, future feedback module and global fusion module, in which the future feedback module can enable the understanding of pre-action by feeding the influence of preview information to feedforward prediction. Thirdly, the comprehensive interaction features are further fed into final predictor to generate the joint predicted trajectories of multiple agents. Extensive experimental results show that our FFINet achieves the state-of-the-art performance on Argoverse 1 and Argoverse 2 motion forecasting benchmarks.
MLF-DET: Multi-Level Fusion for Cross-Modal 3D Object Detection
Jul 18, 2023In this paper, we propose a novel and effective Multi-Level Fusion network, named as MLF-DET, for high-performance cross-modal 3D object DETection, which integrates both the feature-level fusion and decision-level fusion to fully utilize the information in the image. For the feature-level fusion, we present the Multi-scale Voxel Image fusion (MVI) module, which densely aligns multi-scale voxel features with image features. For the decision-level fusion, we propose the lightweight Feature-cued Confidence Rectification (FCR) module which further exploits image semantics to rectify the confidence of detection candidates. Besides, we design an effective data augmentation strategy termed Occlusion-aware GT Sampling (OGS) to reserve more sampled objects in the training scenes, so as to reduce overfitting. Extensive experiments on the KITTI dataset demonstrate the effectiveness of our method. Notably, on the extremely competitive KITTI car 3D object detection benchmark, our method reaches 82.89% moderate AP and achieves state-of-the-art performance without bells and whistles.
Understanding the Overfitting of the Episodic Meta-training
Jul 07, 2023
Despite the success of two-stage few-shot classification methods, in the episodic meta-training stage, the model suffers severe overfitting. We hypothesize that it is caused by over-discrimination, i.e., the model learns to over-rely on the superficial features that fit for base class discrimination while suppressing the novel class generalization. To penalize over-discrimination, we introduce knowledge distillation techniques to keep novel generalization knowledge from the teacher model during training. Specifically, we select the teacher model as the one with the best validation accuracy during meta-training and restrict the symmetric Kullback-Leibler (SKL) divergence between the output distribution of the linear classifier of the teacher model and that of the student model. This simple approach outperforms the standard meta-training process. We further propose the Nearest Neighbor Symmetric Kullback-Leibler (NNSKL) divergence for meta-training to push the limits of knowledge distillation techniques. NNSKL takes few-shot tasks as input and penalizes the output of the nearest neighbor classifier, which possesses an impact on the relationships between query embedding and support centers. By combining SKL and NNSKL in meta-training, the model achieves even better performance and surpasses state-of-the-art results on several benchmarks.
T-former: An Efficient Transformer for Image Inpainting
May 19, 2023



Benefiting from powerful convolutional neural networks (CNNs), learning-based image inpainting methods have made significant breakthroughs over the years. However, some nature of CNNs (e.g. local prior, spatially shared parameters) limit the performance in the face of broken images with diverse and complex forms. Recently, a class of attention-based network architectures, called transformer, has shown significant performance on natural language processing fields and high-level vision tasks. Compared with CNNs, attention operators are better at long-range modeling and have dynamic weights, but their computational complexity is quadratic in spatial resolution, and thus less suitable for applications involving higher resolution images, such as image inpainting. In this paper, we design a novel attention linearly related to the resolution according to Taylor expansion. And based on this attention, a network called $T$-former is designed for image inpainting. Experiments on several benchmark datasets demonstrate that our proposed method achieves state-of-the-art accuracy while maintaining a relatively low number of parameters and computational complexity. The code can be found at \href{https://github.com/dengyecode/T-former_image_inpainting}{github.com/dengyecode/T-former\_image\_inpainting}
VPFusion: Towards Robust Vertical Representation Learning for 3D Object Detection
Apr 06, 2023Efficient point cloud representation is a fundamental element of Lidar-based 3D object detection. Recent grid-based detectors usually divide point clouds into voxels or pillars and construct single-stream networks in Bird's Eye View. However, these point cloud encoding paradigms underestimate the point representation in the vertical direction, which cause the loss of semantic or fine-grained information, especially for vertical sensitive objects like pedestrian and cyclists. In this paper, we propose an explicit vertical multi-scale representation learning framework, VPFusion, to combine the complementary information from both voxel and pillar streams. Specifically, VPFusion first builds upon a sparse voxel-pillar-based backbone. The backbone divides point clouds into voxels and pillars, then encodes features with 3D and 2D sparse convolution simultaneously. Next, we introduce the Sparse Fusion Layer (SFL), which establishes a bidirectional pathway for sparse voxel and pillar features to enable the interaction between them. Additionally, we present the Dense Fusion Neck (DFN) to effectively combine the dense feature maps from voxel and pillar branches with multi-scale. Extensive experiments on the large-scale Waymo Open Dataset and nuScenes Dataset demonstrate that VPFusion surpasses the single-stream baselines by a large margin and achieves state-of-the-art performance with real-time inference speed.
MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking
Mar 18, 2023



The main challenge of Multi-Object Tracking~(MOT) lies in maintaining a continuous trajectory for each target. Existing methods often learn reliable motion patterns to match the same target between adjacent frames and discriminative appearance features to re-identify the lost targets after a long period. However, the reliability of motion prediction and the discriminability of appearances can be easily hurt by dense crowds and extreme occlusions in the tracking process. In this paper, we propose a simple yet effective multi-object tracker, i.e., MotionTrack, which learns robust short-term and long-term motions in a unified framework to associate trajectories from a short to long range. For dense crowds, we design a novel Interaction Module to learn interaction-aware motions from short-term trajectories, which can estimate the complex movement of each target. For extreme occlusions, we build a novel Refind Module to learn reliable long-term motions from the target's history trajectory, which can link the interrupted trajectory with its corresponding detection. Our Interaction Module and Refind Module are embedded in the well-known tracking-by-detection paradigm, which can work in tandem to maintain superior performance. Extensive experimental results on MOT17 and MOT20 datasets demonstrate the superiority of our approach in challenging scenarios, and it achieves state-of-the-art performances at various MOT metrics.
StructVPR: Distill Structural Knowledge with Weighting Samples for Visual Place Recognition
Dec 09, 2022Visual place recognition (VPR) is usually considered as a specific image retrieval problem. Limited by existing training frameworks, most deep learning-based works cannot extract sufficiently stable global features from RGB images and rely on a time-consuming re-ranking step to exploit spatial structural information for better performance. In this paper, we propose StructVPR, a novel training architecture for VPR, to enhance structural knowledge in RGB global features and thus improve feature stability in a constantly changing environment. Specifically, StructVPR uses segmentation images as a more definitive source of structural knowledge input into a CNN network and applies knowledge distillation to avoid online segmentation and inference of seg-branch in testing. Considering that not all samples contain high-quality and helpful knowledge, and some even hurt the performance of distillation, we partition samples and weigh each sample's distillation loss to enhance the expected knowledge precisely. Finally, StructVPR achieves impressive performance on several benchmarks using only global retrieval and even outperforms many two-stage approaches by a large margin. After adding additional re-ranking, ours achieves state-of-the-art performance while maintaining a low computational cost.
Learning to Refactor Action and Co-occurrence Features for Temporal Action Localization
Jun 23, 2022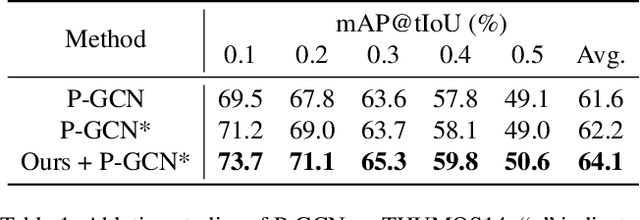
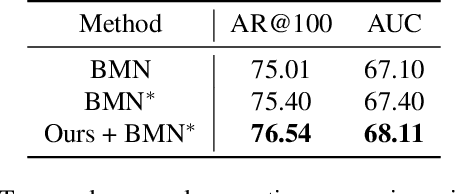
The main challenge of Temporal Action Localization is to retrieve subtle human actions from various co-occurring ingredients, e.g., context and background, in an untrimmed video. While prior approaches have achieved substantial progress through devising advanced action detectors, they still suffer from these co-occurring ingredients which often dominate the actual action content in videos. In this paper, we explore two orthogonal but complementary aspects of a video snippet, i.e., the action features and the co-occurrence features. Especially, we develop a novel auxiliary task by decoupling these two types of features within a video snippet and recombining them to generate a new feature representation with more salient action information for accurate action localization. We term our method RefactorNet, which first explicitly factorizes the action content and regularizes its co-occurrence features, and then synthesizes a new action-dominated video representation. Extensive experimental results and ablation studies on THUMOS14 and ActivityNet v1.3 demonstrate that our new representation, combined with a simple action detector, can significantly improve the action localization performance.