 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqGRL: Suppressing Low-Frequency Bias and Mining High-Frequency Knowledge for Cross-Domain Few-Shot Learning
Nov 10, 2025Cross-domain few-shot learning (CD-FSL) aims to recognize novel classes with only a few labeled examples under significant domain shifts. While recent approaches leverage a limited amount of labeled target-domain data to improve performance, the severe imbalance between abundant source data and scarce target data remains a critical challenge for effective representation learning. We present the first frequency-space perspective to analyze this issue and identify two key challenges: (1) models are easily biased toward source-specific knowledge encoded in the low-frequency components of source data, and (2) the sparsity of target data hinders the learning of high-frequency, domain-generalizable features. To address these challenges, we propose \textbf{FreqGRL}, a novel CD-FSL framework that mitigates the impact of data imbalance in the frequency space. Specifically, we introduce a Low-Frequency Replacement (LFR) module that substitutes the low-frequency components of source tasks with those from the target domain to create new source tasks that better align with target characteristics, thus reducing source-specific biases and promoting generalizable representation learning. We further design a High-Frequency Enhancement (HFE) module that filters out low-frequency components and performs learning directly on high-frequency features in the frequency space to improve cross-domain generalization. Additionally, a Global Frequency Filter (GFF) is incorporated to suppress noisy or irrelevant frequencies and emphasize informative ones, mitigating overfitting risks under limited target supervision. Extensive experiments on five standard CD-FSL benchmarks demonstrate that our frequency-guided framework achieves state-of-the-art performance.
Semantic-aware Representation Learning for Homography Estimation
Jul 18, 2024



Homography estimation is the task of determining the transformation from an image pair. Our approach focuses on employing detector-free feature matching methods to address this issue. Previous work has underscored the importance of incorporating semantic information, however there still lacks an efficient way to utilize semantic information. Previous methods suffer from treating the semantics as a pre-processing, causing the utilization of semantics overly coarse-grained and lack adaptability when dealing with different tasks. In our work, we seek another way to use the semantic information, that is semantic-aware feature representation learning framework.Based on this, we propose SRMatcher, a new detector-free feature matching method, which encourages the network to learn integrated semantic feature representation.Specifically, to capture precise and rich semantics, we leverage the capabilities of recently popularized vision foundation models (VFMs) trained on extensive datasets. Then, a cross-images Semantic-aware Fusion Block (SFB) is proposed to integrate its fine-grained semantic features into the feature representation space. In this way, by reducing errors stemming from semantic inconsistencies in matching pairs, our proposed SRMatcher is able to deliver more accurate and realistic outcomes. Extensive experiments show that SRMatcher surpasses solid baselines and attains SOTA results on multiple real-world datasets. Compared to the previous SOTA approach GeoFormer, SRMatcher increases the area under the cumulative curve (AUC) by about 11\% on HPatches. Additionally, the SRMatcher could serve as a plug-and-play framework for other matching methods like LoFTR, yielding substantial precision improvement.
Understanding the Overfitting of the Episodic Meta-training
Jul 07, 2023
Despite the success of two-stage few-shot classification methods, in the episodic meta-training stage, the model suffers severe overfitting. We hypothesize that it is caused by over-discrimination, i.e., the model learns to over-rely on the superficial features that fit for base class discrimination while suppressing the novel class generalization. To penalize over-discrimination, we introduce knowledge distillation techniques to keep novel generalization knowledge from the teacher model during training. Specifically, we select the teacher model as the one with the best validation accuracy during meta-training and restrict the symmetric Kullback-Leibler (SKL) divergence between the output distribution of the linear classifier of the teacher model and that of the student model. This simple approach outperforms the standard meta-training process. We further propose the Nearest Neighbor Symmetric Kullback-Leibler (NNSKL) divergence for meta-training to push the limits of knowledge distillation techniques. NNSKL takes few-shot tasks as input and penalizes the output of the nearest neighbor classifier, which possesses an impact on the relationships between query embedding and support centers. By combining SKL and NNSKL in meta-training, the model achieves even better performance and surpasses state-of-the-art results on several benchmarks.
T-former: An Efficient Transformer for Image Inpainting
May 19, 2023



Benefiting from powerful convolutional neural networks (CNNs), learning-based image inpainting methods have made significant breakthroughs over the years. However, some nature of CNNs (e.g. local prior, spatially shared parameters) limit the performance in the face of broken images with diverse and complex forms. Recently, a class of attention-based network architectures, called transformer, has shown significant performance on natural language processing fields and high-level vision tasks. Compared with CNNs, attention operators are better at long-range modeling and have dynamic weights, but their computational complexity is quadratic in spatial resolution, and thus less suitable for applications involving higher resolution images, such as image inpainting. In this paper, we design a novel attention linearly related to the resolution according to Taylor expansion. And based on this attention, a network called $T$-former is designed for image inpainting. Experiments on several benchmark datasets demonstrate that our proposed method achieves state-of-the-art accuracy while maintaining a relatively low number of parameters and computational complexity. The code can be found at \href{https://github.com/dengyecode/T-former_image_inpainting}{github.com/dengyecode/T-former\_image\_inpainting}
Auxiliary Loss Adaptation for Image Inpainting
Nov 22, 2021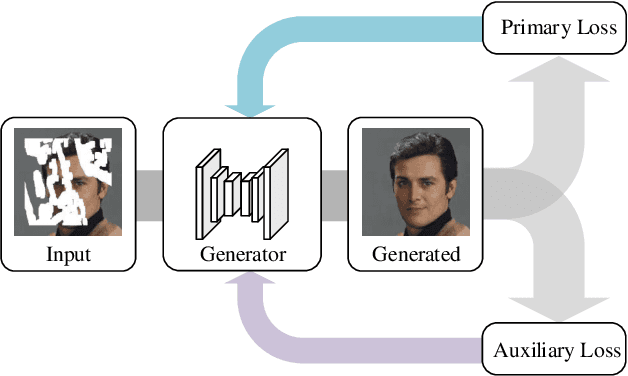
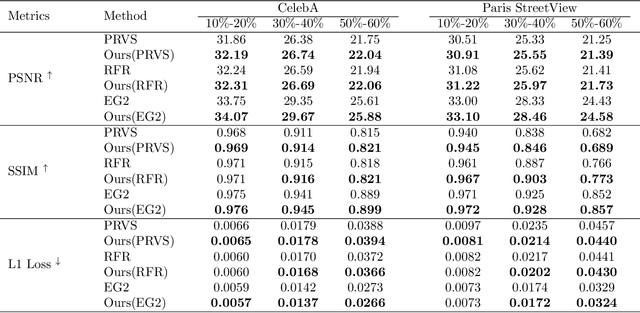
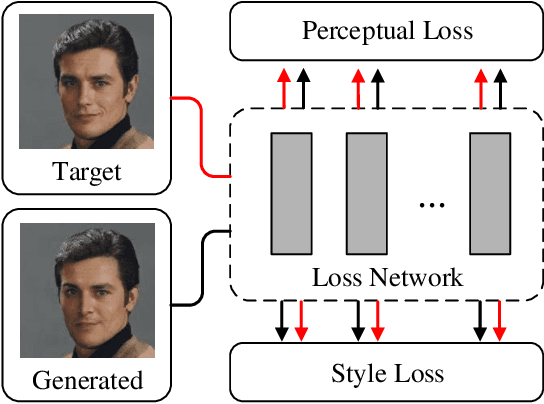
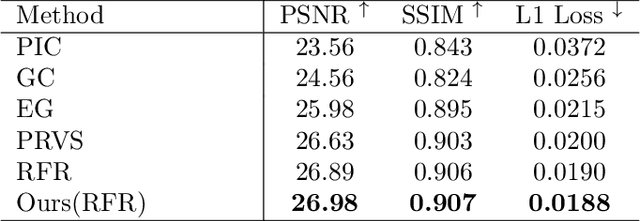
Auxiliary losses commonly used in image inpainting lead to better reconstruction performance by incorporating prior knowledge of missing regions. However, it usually requires a lot of effort to fully exploit the potential of auxiliary losses, or otherwise, improperly weighted auxiliary losses would distract the model from the inpainting task, and the effectiveness of an auxiliary loss might vary during the training process. Hence the design of auxiliary losses takes strong domain expertise. To mitigate the problem, in this work, we introduce the Auxiliary Loss Adaptation for Image Inpainting (ALA) algorithm to dynamically adjust the parameters of the auxiliary loss. Our method is based on the principle that the best auxiliary loss is the one that helps increase the performance of the main loss most through several steps of gradient descent. We then examined two commonly used auxiliary losses in inpainting and used ALA to adapt their parameters. Experimental results show that ALA induces more competitive inpainting results than fixed auxiliary losses. In particular, simply combining auxiliary loss with ALA, existing inpainting methods can achieve increased performances without explicitly incorporating delicate network design or structure knowledge prior.