 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Data Server: A Large-Scale Search Engine for Transfer Learning Data
Jan 09, 2020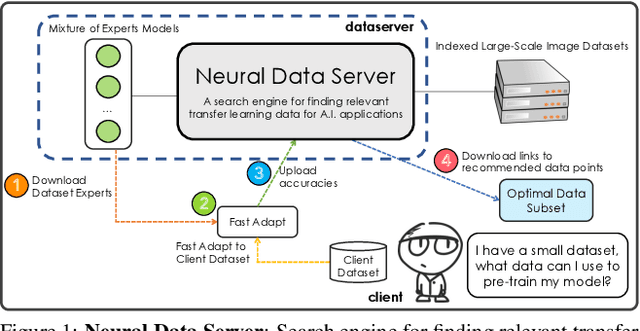
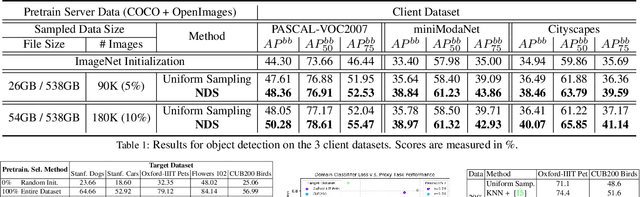

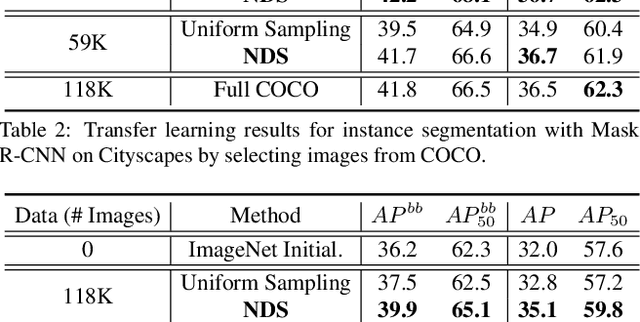
Transfer learning has proven to be a successful technique to train deep learning models in the domains where little training data is available. The dominant approach is to pretrain a model on a large generic dataset such as ImageNet and finetune its weights on the target domain. However, in the new era of an ever-increasing number of massive datasets, selecting the relevant data for pretraining is a critical issue. We introduce Neural Data Server (NDS), a large-scale search engine for finding the most useful transfer learning data to the target domain. Our NDS consists of a dataserver which indexes several large popular image datasets, and aims to recommend data to a client, an end-user with a target application with its own small labeled dataset. As in any search engine that serves information to possibly numerous users, we want the online computation performed by the dataserver to be minimal. The dataserver represents large datasets with a much more compact mixture-of experts model, and employs it to perform data search in a series of dataserver-client transactions at a low computational cost. We show the effectiveness of NDS in various transfer learning scenarios, demonstrating state-of-the-art performance on several target datasets and tasks such as image classification, object detection and instance segmentation. Our Neural Data Server is available as a web-service at http://aidemos.cs.toronto.edu/nds/, recommending data to users with the aim to improve performance of their A.I. application.
The Shmoop Corpus: A Dataset of Stories with Loosely Aligned Summaries
Jan 01, 2020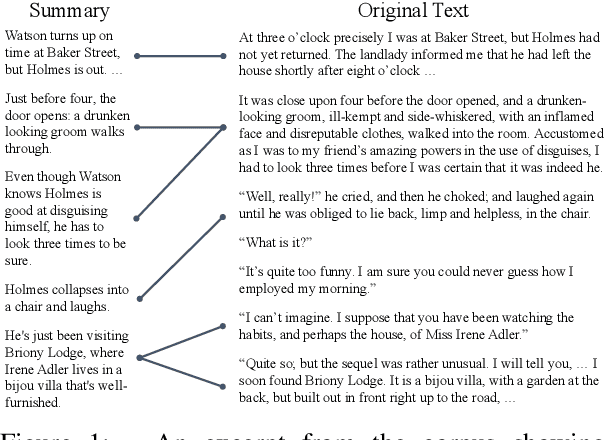
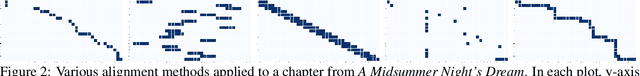

Understanding stories is a challenging reading comprehension problem for machines as it requires reading a large volume of text and following long-range dependencies. In this paper, we introduce the Shmoop Corpus: a dataset of 231 stories that are paired with detailed multi-paragraph summaries for each individual chapter (7,234 chapters), where the summary is chronologically aligned with respect to the story chapter. From the corpus, we construct a set of common NLP tasks, including Cloze-form question answering and a simplified form of abstractive summarization, as benchmarks for reading comprehension on stories. We then show that the chronological alignment provides a strong supervisory signal that learning-based methods can exploit leading to significant improvements on these tasks. We believe that the unique structure of this corpus provides an important foothold towards making machine story comprehension more approachable.
Kaolin: A PyTorch Library for Accelerating 3D Deep Learning Research
Nov 13, 2019

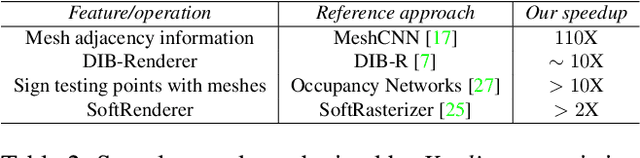

We present Kaolin, a PyTorch library aiming to accelerate 3D deep learning research. Kaolin provides efficient implementations of differentiable 3D modules for use in deep learning systems. With functionality to load and preprocess several popular 3D datasets, and native functions to manipulate meshes, pointclouds, signed distance functions, and voxel grids, Kaolin mitigates the need to write wasteful boilerplate code. Kaolin packages together several differentiable graphics modules including rendering, lighting, shading, and view warping. Kaolin also supports an array of loss functions and evaluation metrics for seamless evaluation and provides visualization functionality to render the 3D results. Importantly, we curate a comprehensive model zoo comprising many state-of-the-art 3D deep learning architectures, to serve as a starting point for future research endeavours. Kaolin is available as open-source software at https://github.com/NVIDIAGameWorks/kaolin/.
CrevNet: Conditionally Reversible Video Prediction
Oct 25, 2019

Applying resolution-preserving blocks is a common practice to maximize information preservation in video prediction, yet their high memory consumption greatly limits their application scenarios. We propose CrevNet, a Conditionally Reversible Network that uses reversible architectures to build a bijective two-way autoencoder and its complementary recurrent predictor. Our model enjoys the theoretically guaranteed property of no information loss during the feature extraction, much lower memory consumption and computational efficiency.
Neural Turtle Graphics for Modeling City Road Layouts
Oct 04, 2019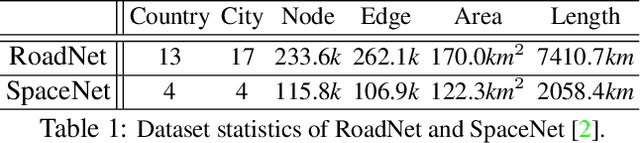
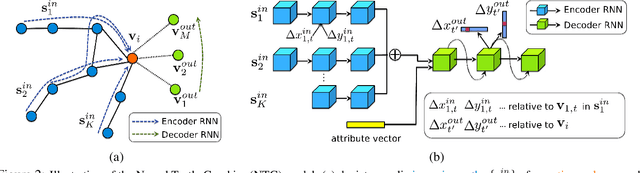
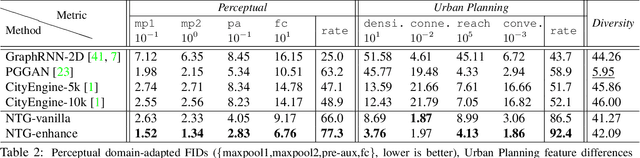

We propose Neural Turtle Graphics (NTG), a novel generative model for spatial graphs, and demonstrate its applications in modeling city road layouts. Specifically, we represent the road layout using a graph where nodes in the graph represent control points and edges in the graph represent road segments. NTG is a sequential generative model parameterized by a neural network. It iteratively generates a new node and an edge connecting to an existing node conditioned on the current graph. We train NTG on Open Street Map data and show that it outperforms existing approaches using a set of diverse performance metrics. Moreover, our method allows users to control styles of generated road layouts mimicking existing cities as well as to sketch parts of the city road layout to be synthesized. In addition to synthesis, the proposed NTG finds uses in an analytical task of aerial road parsing. Experimental results show that it achieves state-of-the-art performance on the SpaceNet dataset.
DMM-Net: Differentiable Mask-Matching Network for Video Object Segmentation
Sep 27, 2019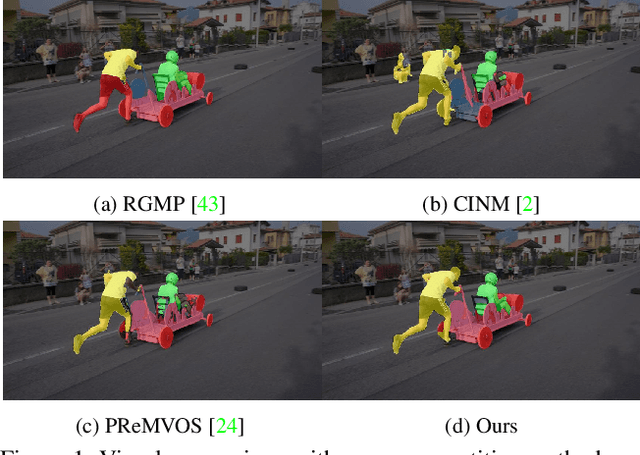
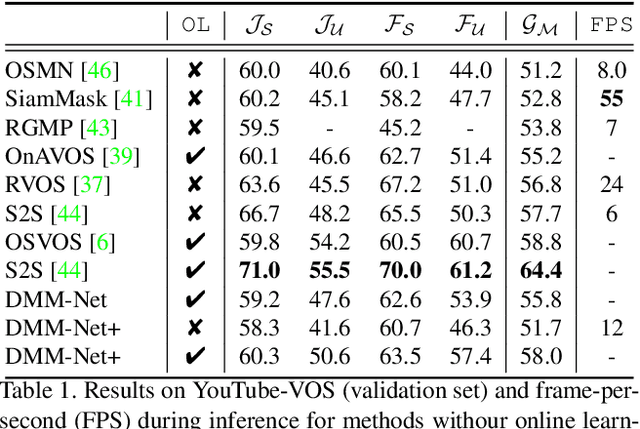
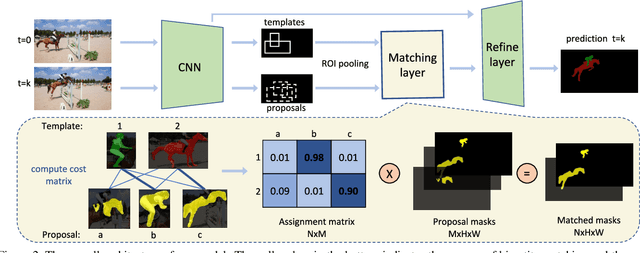
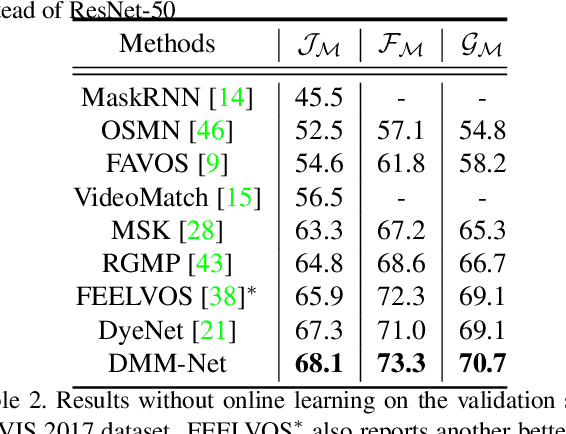
In this paper, we propose the differentiable mask-matching network (DMM-Net) for solving the video object segmentation problem where the initial object masks are provided. Relying on the Mask R-CNN backbone, we extract mask proposals per frame and formulate the matching between object templates and proposals at one time step as a linear assignment problem where the cost matrix is predicted by a CNN. We propose a differentiable matching layer by unrolling a projected gradient descent algorithm in which the projection exploits the Dykstra's algorithm. We prove that under mild conditions, the matching is guaranteed to converge to the optimum. In practice, it performs similarly to the Hungarian algorithm during inference. Meanwhile, we can back-propagate through it to learn the cost matrix. After matching, a refinement head is leveraged to improve the quality of the matched mask. Our DMM-Net achieves competitive results on the largest video object segmentation dataset YouTube-VOS. On DAVIS 2017, DMM-Net achieves the best performance without online learning on the first frames. Without any fine-tuning, DMM-Net performs comparably to state-of-the-art methods on SegTrack v2 dataset. At last, our matching layer is very simple to implement; we attach the PyTorch code ($<50$ lines) in the supplementary material. Our code is released at https://github.com/ZENGXH/DMM_Net.
A Theoretical Analysis of the Number of Shots in Few-Shot Learning
Sep 25, 2019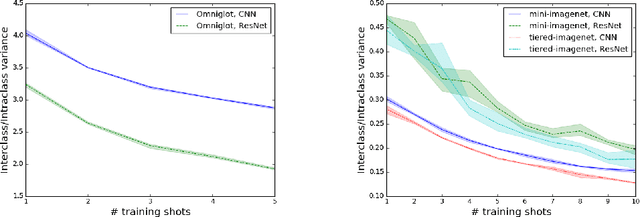
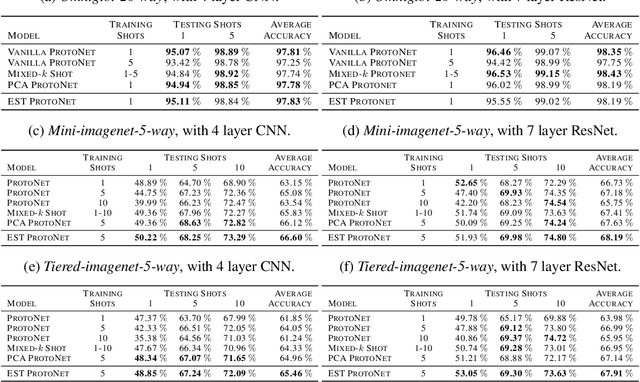
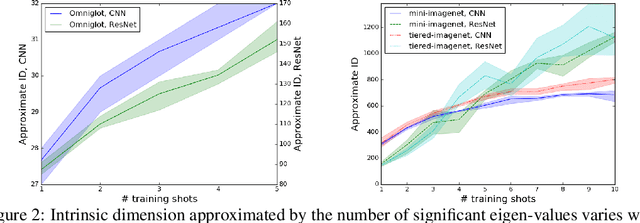
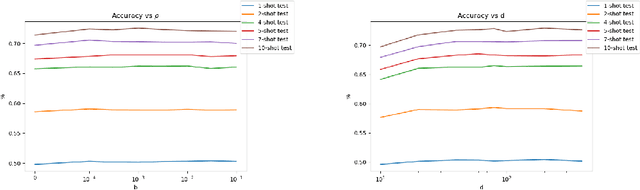
Few-shot classification is the task of predicting the category of an example from a set of few labeled examples. The number of labeled examples per category is called the number of shots (or shot number). Recent works tackle this task through meta-learning, where a meta-learner extracts information from observed tasks during meta-training to quickly adapt to new tasks during meta-testing. In this formulation, the number of shots exploited during meta-training has an impact on the recognition performance at meta-test time. Generally, the shot number used in meta-training should match the one used in meta-testing to obtain the best performance. We introduce a theoretical analysis of the impact of the shot number on Prototypical Networks, a state-of-the-art few-shot classification method. From our analysis, we propose a simple method that is robust to the choice of shot number used during meta-training, which is a crucial hyperparameter. The performance of our model trained for an arbitrary meta-training shot number shows great performance for different values of meta-testing shot numbers. We experimentally demonstrate our approach on different few-shot classification benchmarks.
Video Face Clustering with Unknown Number of Clusters
Aug 20, 2019
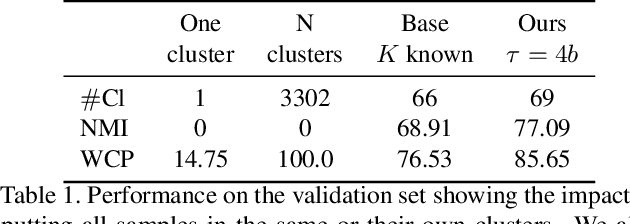
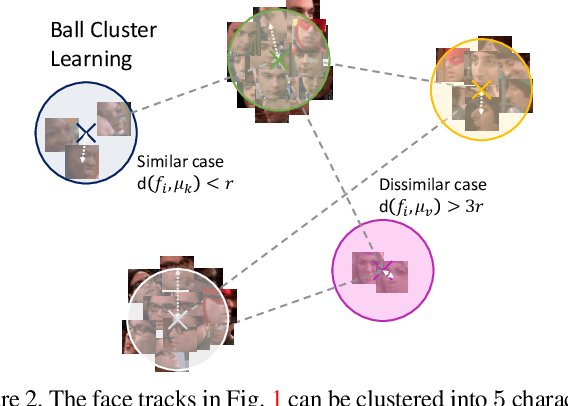
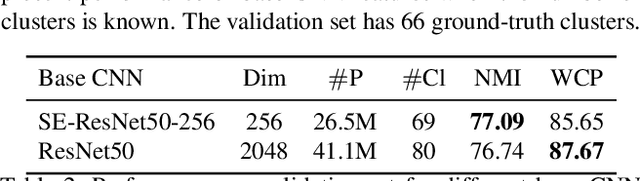
Understanding videos such as TV series and movies requires analyzing who the characters are and what they are doing. We address the challenging problem of clustering face tracks based on their identity. Different from previous work in this area, we choose to operate in a realistic and difficult setting where: (i) the number of characters is not known a priori; and (ii) face tracks belonging to minor or background characters are not discarded. To this end, we propose Ball Cluster Learning (BCL), a supervised approach to carve the embedding space into balls of equal size, one for each cluster. The learned ball radius is easily translated to a stopping criterion for iterative merging algorithms. This gives BCL the ability to estimate the number of clusters as well as their assignment, achieving promising results on commonly used datasets. We also present a thorough discussion of how existing metric learning literature can be adapted for this task.
Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer
Aug 03, 2019

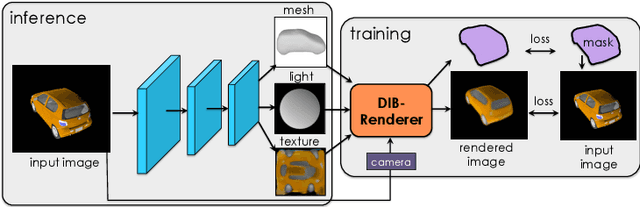

Many machine learning models operate on images, but ignore the fact that images are 2D projections formed by 3D geometry interacting with light, in a process called rendering. Enabling ML models to understand image formation might be key for generalization. However, due to an essential rasterization step involving discrete assignment operations, rendering pipelines are non-differentiable and thus largely inaccessible to gradient-based ML techniques. In this paper, we present DIB-R, a differentiable rendering framework which allows gradients to be analytically computed for all pixels in an image. Key to our approach is to view foreground rasterization as a weighted interpolation of local properties and background rasterization as an distance-based aggregation of global geometry. Our approach allows for accurate optimization over vertex positions, colors, normals, light directions and texture coordinates through a variety of lighting models. We showcase our approach in two ML applications: single-image 3D object prediction, and 3D textured object generation, both trained using exclusively using 2D supervision. Our project website is: https://nv-tlabs.github.io/DIB-R/
Gated-SCNN: Gated Shape CNNs for Semantic Segmentation
Jul 12, 2019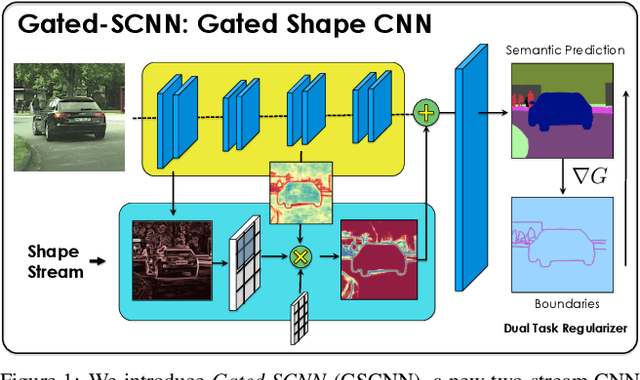
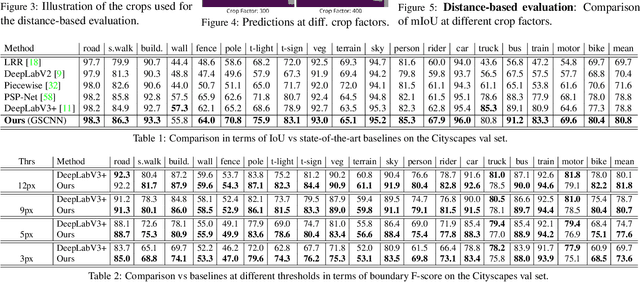
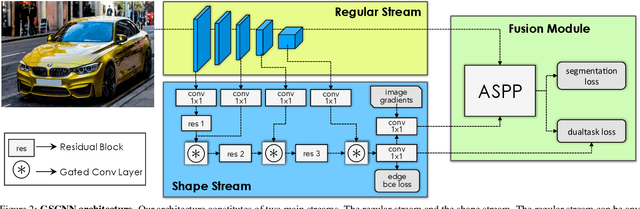

Current state-of-the-art methods for image segmentation form a dense image representation where the color, shape and texture information are all processed together inside a deep CNN. This however may not be ideal as they contain very different type of information relevant for recognition. Here, we propose a new two-stream CNN architecture for semantic segmentation that explicitly wires shape information as a separate processing branch, i.e. shape stream, that processes information in parallel to the classical stream. Key to this architecture is a new type of gates that connect the intermediate layers of the two streams. Specifically, we use the higher-level activations in the classical stream to gate the lower-level activations in the shape stream, effectively removing noise and helping the shape stream to only focus on processing the relevant boundary-related information. This enables us to use a very shallow architecture for the shape stream that operates on the image-level resolution. Our experiments show that this leads to a highly effective architecture that produces sharper predictions around object boundaries and significantly boosts performance on thinner and smaller objects. Our method achieves state-of-the-art performance on the Cityscapes benchmark, in terms of both mask (mIoU) and boundary (F-score) quality, improving by 2% and 4% over strong baselines.