 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters
May 05, 2022
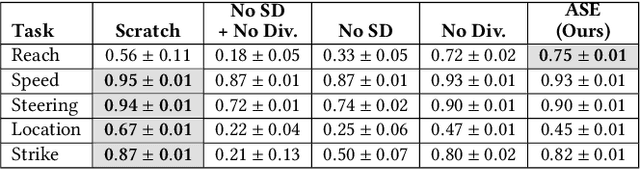
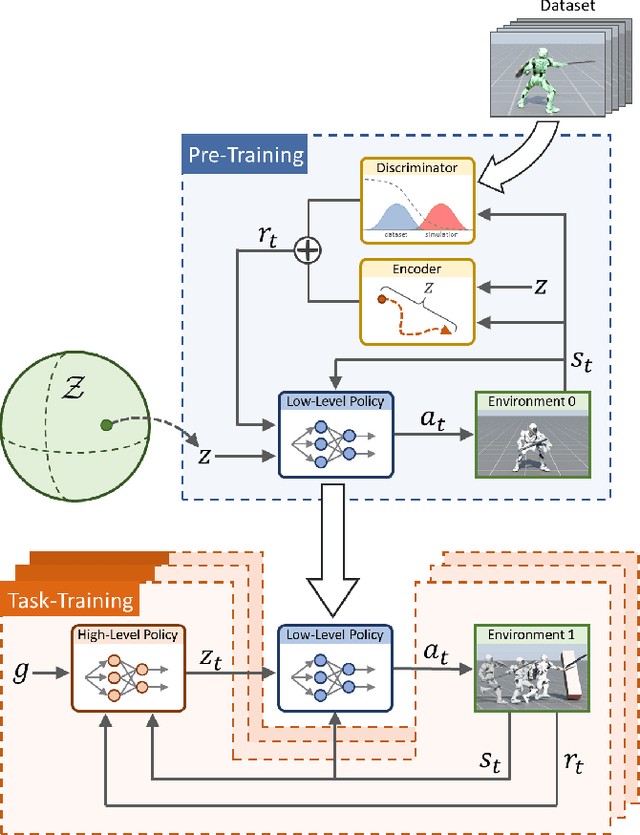
The incredible feats of athleticism demonstrated by humans are made possible in part by a vast repertoire of general-purpose motor skills, acquired through years of practice and experience. These skills not only enable humans to perform complex tasks, but also provide powerful priors for guiding their behaviors when learning new tasks. This is in stark contrast to what is common practice in physics-based character animation, where control policies are most typically trained from scratch for each task. In this work, we present a large-scale data-driven framework for learning versatile and reusable skill embeddings for physically simulated characters. Our approach combines techniques from adversarial imitation learning and unsupervised reinforcement learning to develop skill embeddings that produce life-like behaviors, while also providing an easy to control representation for use on new downstream tasks. Our models can be trained using large datasets of unstructured motion clips, without requiring any task-specific annotation or segmentation of the motion data. By leveraging a massively parallel GPU-based simulator, we are able to train skill embeddings using over a decade of simulated experiences, enabling our model to learn a rich and versatile repertoire of skills. We show that a single pre-trained model can be effectively applied to perform a diverse set of new tasks. Our system also allows users to specify tasks through simple reward functions, and the skill embedding then enables the character to automatically synthesize complex and naturalistic strategies in order to achieve the task objectives.
M$^2$BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation
Apr 19, 2022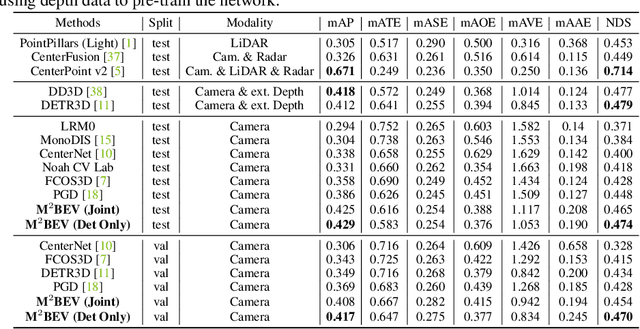
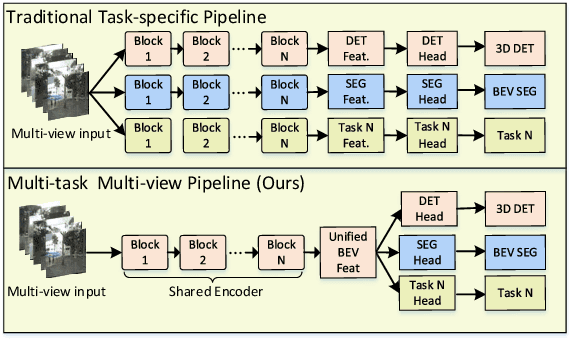
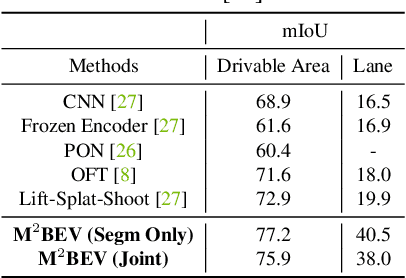
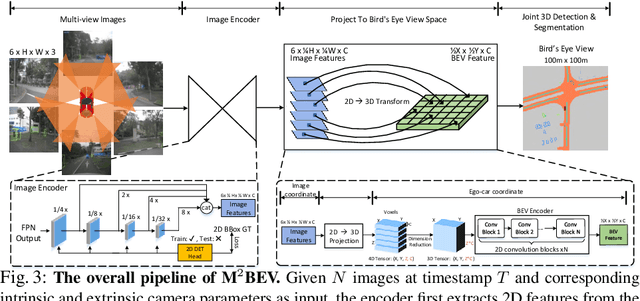
In this paper, we propose M$^2$BEV, a unified framework that jointly performs 3D object detection and map segmentation in the Birds Eye View~(BEV) space with multi-camera image inputs. Unlike the majority of previous works which separately process detection and segmentation, M$^2$BEV infers both tasks with a unified model and improves efficiency. M$^2$BEV efficiently transforms multi-view 2D image features into the 3D BEV feature in ego-car coordinates. Such BEV representation is important as it enables different tasks to share a single encoder. Our framework further contains four important designs that benefit both accuracy and efficiency: (1) An efficient BEV encoder design that reduces the spatial dimension of a voxel feature map. (2) A dynamic box assignment strategy that uses learning-to-match to assign ground-truth 3D boxes with anchors. (3) A BEV centerness re-weighting that reinforces with larger weights for more distant predictions, and (4) Large-scale 2D detection pre-training and auxiliary supervision. We show that these designs significantly benefit the ill-posed camera-based 3D perception tasks where depth information is missing. M$^2$BEV is memory efficient, allowing significantly higher resolution images as input, with faster inference speed. Experiments on nuScenes show that M$^2$BEV achieves state-of-the-art results in both 3D object detection and BEV segmentation, with the best single model achieving 42.5 mAP and 57.0 mIoU in these two tasks, respectively.
AUV-Net: Learning Aligned UV Maps for Texture Transfer and Synthesis
Apr 06, 2022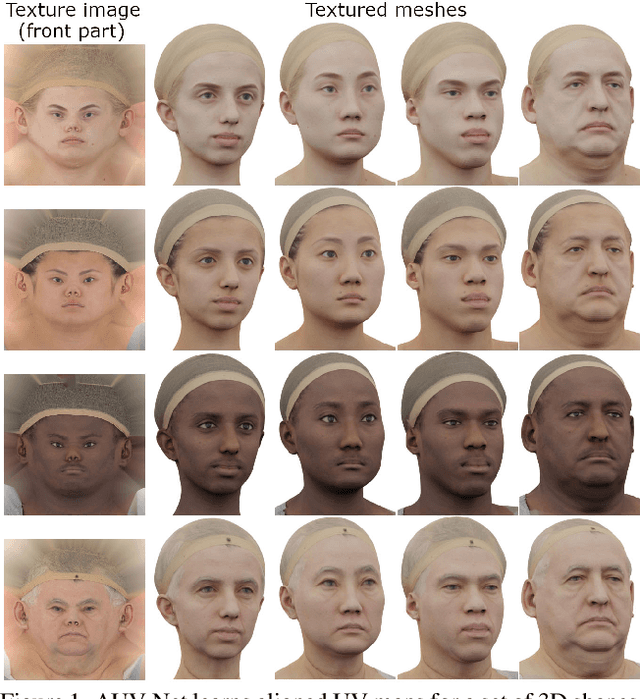


In this paper, we address the problem of texture representation for 3D shapes for the challenging and underexplored tasks of texture transfer and synthesis. Previous works either apply spherical texture maps which may lead to large distortions, or use continuous texture fields that yield smooth outputs lacking details. We argue that the traditional way of representing textures with images and linking them to a 3D mesh via UV mapping is more desirable, since synthesizing 2D images is a well-studied problem. We propose AUV-Net which learns to embed 3D surfaces into a 2D aligned UV space, by mapping the corresponding semantic parts of different 3D shapes to the same location in the UV space. As a result, textures are aligned across objects, and can thus be easily synthesized by generative models of images. Texture alignment is learned in an unsupervised manner by a simple yet effective texture alignment module, taking inspiration from traditional works on linear subspace learning. The learned UV mapping and aligned texture representations enable a variety of applications including texture transfer, texture synthesis, and textured single view 3D reconstruction. We conduct experiments on multiple datasets to demonstrate the effectiveness of our method. Project page: https://nv-tlabs.github.io/AUV-NET.
Learning Smooth Neural Functions via Lipschitz Regularization
Feb 16, 2022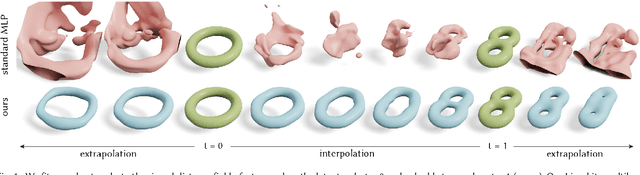

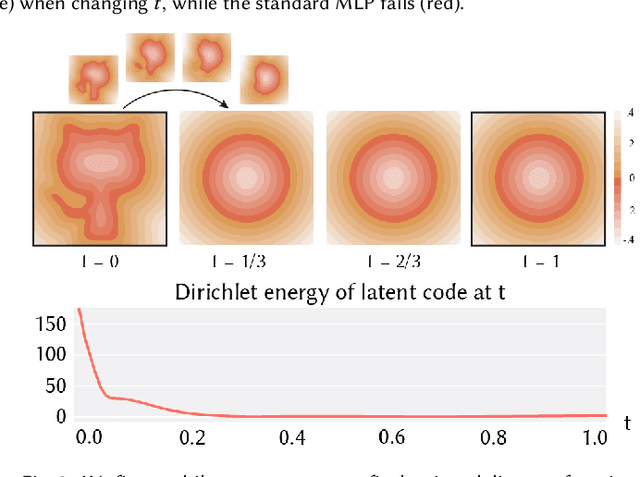

Neural implicit fields have recently emerged as a useful representation for 3D shapes. These fields are commonly represented as neural networks which map latent descriptors and 3D coordinates to implicit function values. The latent descriptor of a neural field acts as a deformation handle for the 3D shape it represents. Thus, smoothness with respect to this descriptor is paramount for performing shape-editing operations. In this work, we introduce a novel regularization designed to encourage smooth latent spaces in neural fields by penalizing the upper bound on the field's Lipschitz constant. Compared with prior Lipschitz regularized networks, ours is computationally fast, can be implemented in four lines of code, and requires minimal hyperparameter tuning for geometric applications. We demonstrate the effectiveness of our approach on shape interpolation and extrapolation as well as partial shape reconstruction from 3D point clouds, showing both qualitative and quantitative improvements over existing state-of-the-art and non-regularized baselines.
Domain Adversarial Training: A Game Perspective
Feb 10, 2022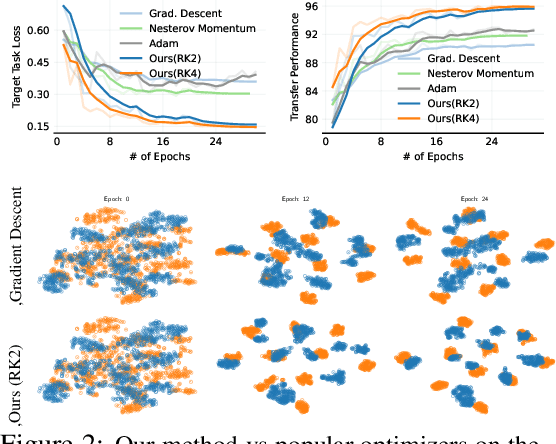
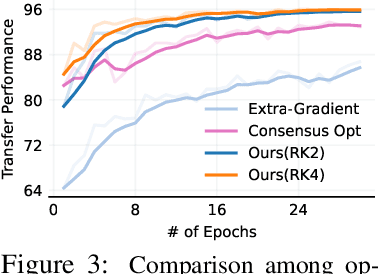

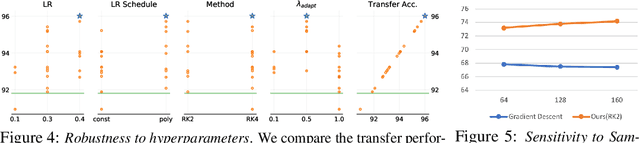
The dominant line of work in domain adaptation has focused on learning invariant representations using domain-adversarial training. In this paper, we interpret this approach from a game theoretical perspective. Defining optimal solutions in domain-adversarial training as a local Nash equilibrium, we show that gradient descent in domain-adversarial training can violate the asymptotic convergence guarantees of the optimizer, oftentimes hindering the transfer performance. Our analysis leads us to replace gradient descent with high-order ODE solvers (i.e., Runge-Kutta), for which we derive asymptotic convergence guarantees. This family of optimizers is significantly more stable and allows more aggressive learning rates, leading to high performance gains when used as a drop-in replacement over standard optimizers. Our experiments show that in conjunction with state-of-the-art domain-adversarial methods, we achieve up to 3.5% improvement with less than of half training iterations. Our optimizers are easy to implement, free of additional parameters, and can be plugged into any domain-adversarial framework.
Causal Scene BERT: Improving object detection by searching for challenging groups of data
Feb 08, 2022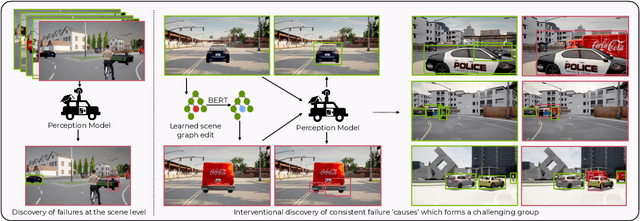
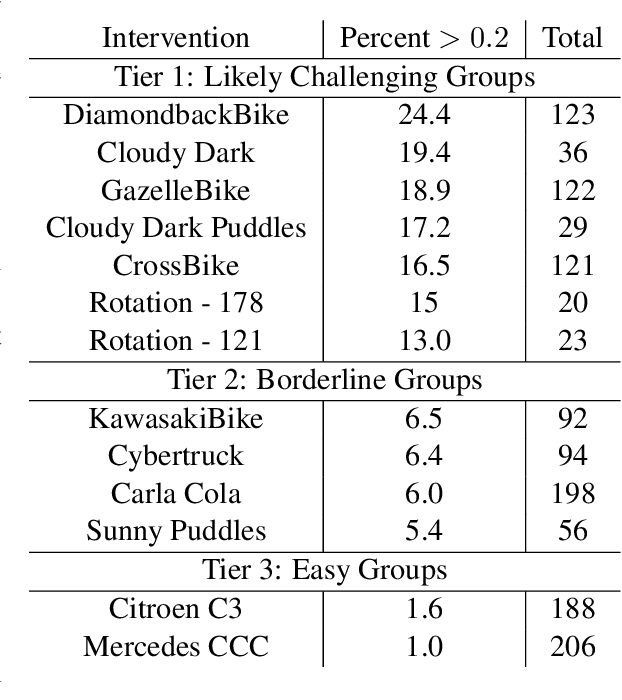
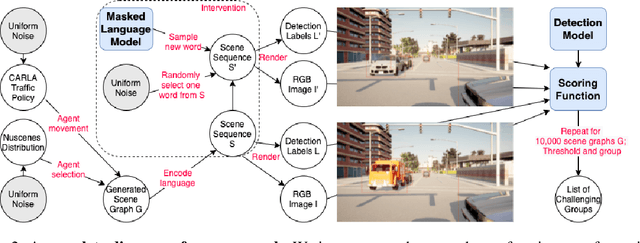
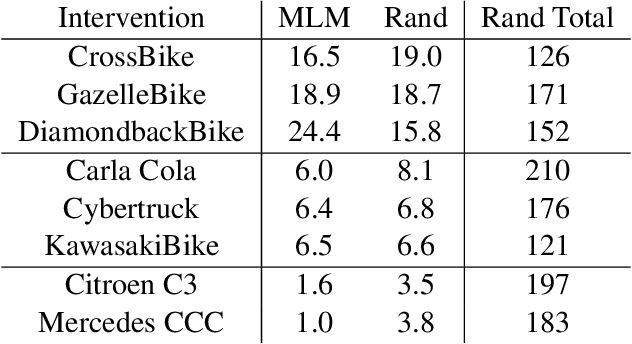
Modern computer vision applications rely on learning-based perception modules parameterized with neural networks for tasks like object detection. These modules frequently have low expected error overall but high error on atypical groups of data due to biases inherent in the training process. In building autonomous vehicles (AV), this problem is an especially important challenge because their perception modules are crucial to the overall system performance. After identifying failures in AV, a human team will comb through the associated data to group perception failures that share common causes. More data from these groups is then collected and annotated before retraining the model to fix the issue. In other words, error groups are found and addressed in hindsight. Our main contribution is a pseudo-automatic method to discover such groups in foresight by performing causal interventions on simulated scenes. To keep our interventions on the data manifold, we utilize masked language models. We verify that the prioritized groups found via intervention are challenging for the object detector and show that retraining with data collected from these groups helps inordinately compared to adding more IID data. We also plan to release software to run interventions in simulated scenes, which we hope will benefit the causality community.
Federated Learning with Heterogeneous Architectures using Graph HyperNetworks
Jan 20, 2022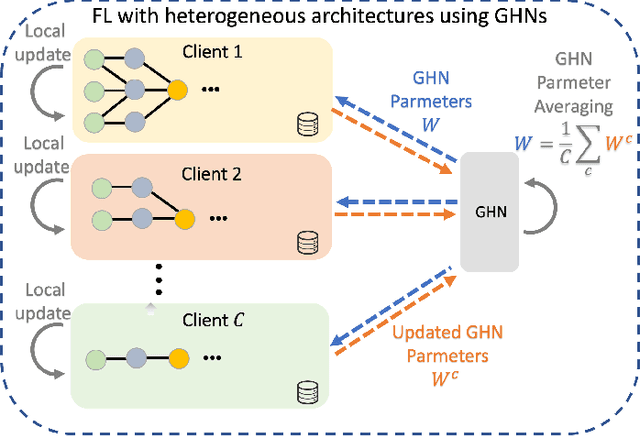
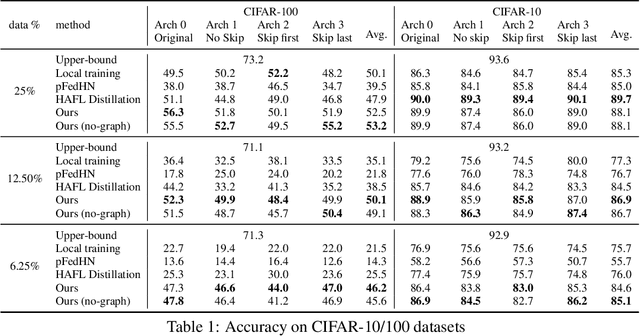
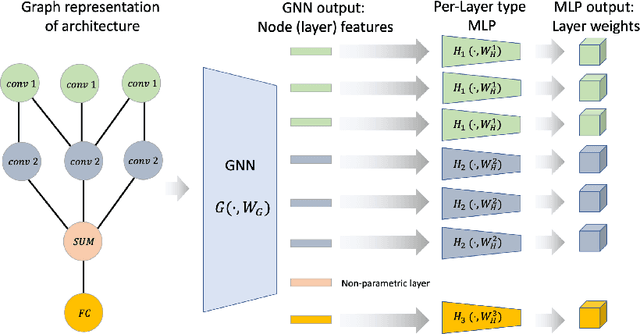
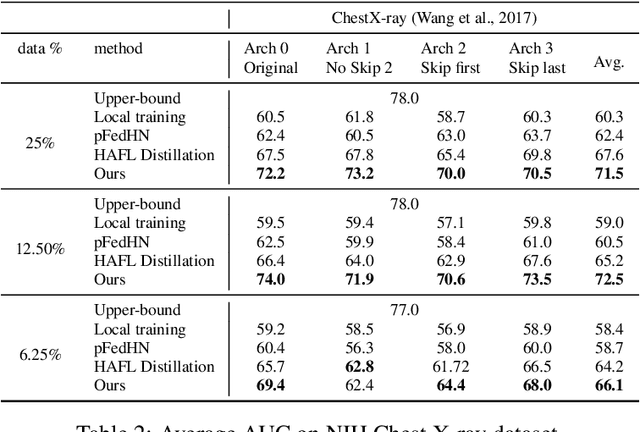
Standard Federated Learning (FL) techniques are limited to clients with identical network architectures. This restricts potential use-cases like cross-platform training or inter-organizational collaboration when both data privacy and architectural proprietary are required. We propose a new FL framework that accommodates heterogeneous client architecture by adopting a graph hypernetwork for parameter sharing. A property of the graph hyper network is that it can adapt to various computational graphs, thereby allowing meaningful parameter sharing across models. Unlike existing solutions, our framework does not limit the clients to share the same architecture type, makes no use of external data and does not require clients to disclose their model architecture. Compared with distillation-based and non-graph hypernetwork baselines, our method performs notably better on standard benchmarks. We additionally show encouraging generalization performance to unseen architectures.
BigDatasetGAN: Synthesizing ImageNet with Pixel-wise Annotations
Jan 12, 2022

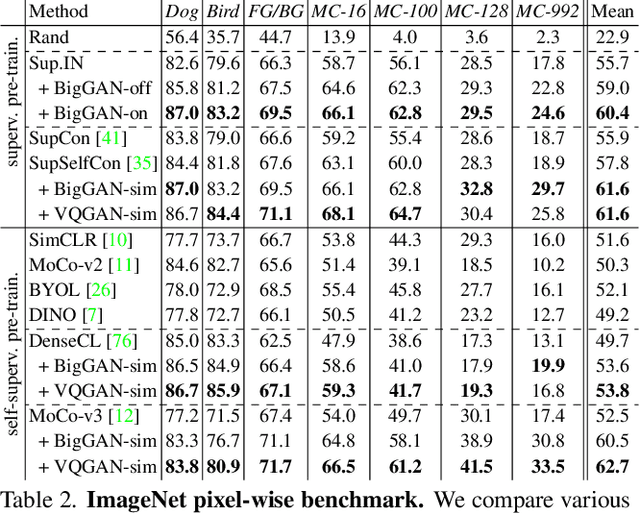
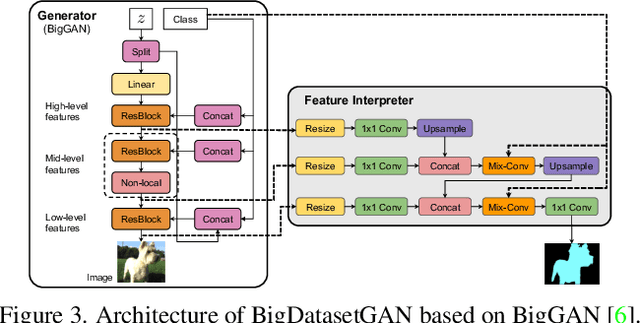
Annotating images with pixel-wise labels is a time-consuming and costly process. Recently, DatasetGAN showcased a promising alternative - to synthesize a large labeled dataset via a generative adversarial network (GAN) by exploiting a small set of manually labeled, GAN-generated images. Here, we scale DatasetGAN to ImageNet scale of class diversity. We take image samples from the class-conditional generative model BigGAN trained on ImageNet, and manually annotate 5 images per class, for all 1k classes. By training an effective feature segmentation architecture on top of BigGAN, we turn BigGAN into a labeled dataset generator. We further show that VQGAN can similarly serve as a dataset generator, leveraging the already annotated data. We create a new ImageNet benchmark by labeling an additional set of 8k real images and evaluate segmentation performance in a variety of settings. Through an extensive ablation study we show big gains in leveraging a large generated dataset to train different supervised and self-supervised backbone models on pixel-wise tasks. Furthermore, we demonstrate that using our synthesized datasets for pre-training leads to improvements over standard ImageNet pre-training on several downstream datasets, such as PASCAL-VOC, MS-COCO, Cityscapes and chest X-ray, as well as tasks (detection, segmentation). Our benchmark will be made public and maintain a leaderboard for this challenging task. Project Page: https://nv-tlabs.github.io/big-datasetgan/
Generating Useful Accident-Prone Driving Scenarios via a Learned Traffic Prior
Dec 09, 2021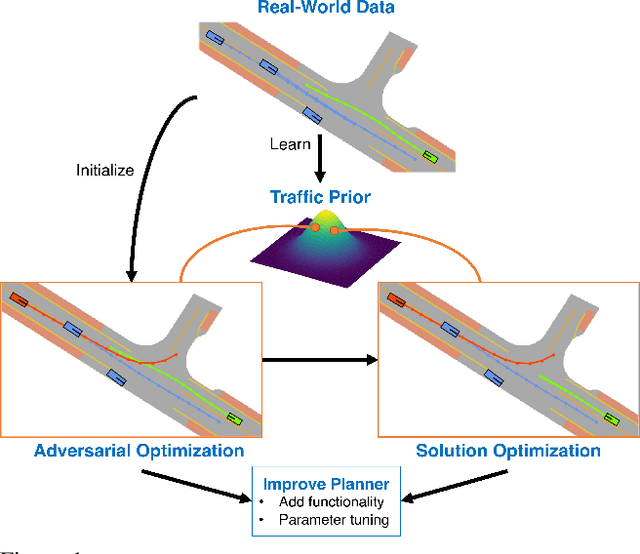

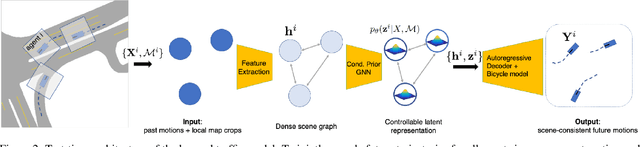

Evaluating and improving planning for autonomous vehicles requires scalable generation of long-tail traffic scenarios. To be useful, these scenarios must be realistic and challenging, but not impossible to drive through safely. In this work, we introduce STRIVE, a method to automatically generate challenging scenarios that cause a given planner to produce undesirable behavior, like collisions. To maintain scenario plausibility, the key idea is to leverage a learned model of traffic motion in the form of a graph-based conditional VAE. Scenario generation is formulated as an optimization in the latent space of this traffic model, effected by perturbing an initial real-world scene to produce trajectories that collide with a given planner. A subsequent optimization is used to find a "solution" to the scenario, ensuring it is useful to improve the given planner. Further analysis clusters generated scenarios based on collision type. We attack two planners and show that STRIVE successfully generates realistic, challenging scenarios in both cases. We additionally "close the loop" and use these scenarios to optimize hyperparameters of a rule-based planner.
Frame Averaging for Equivariant Shape Space Learning
Dec 03, 2021
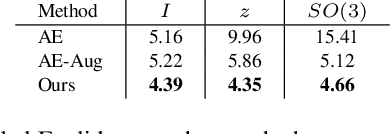

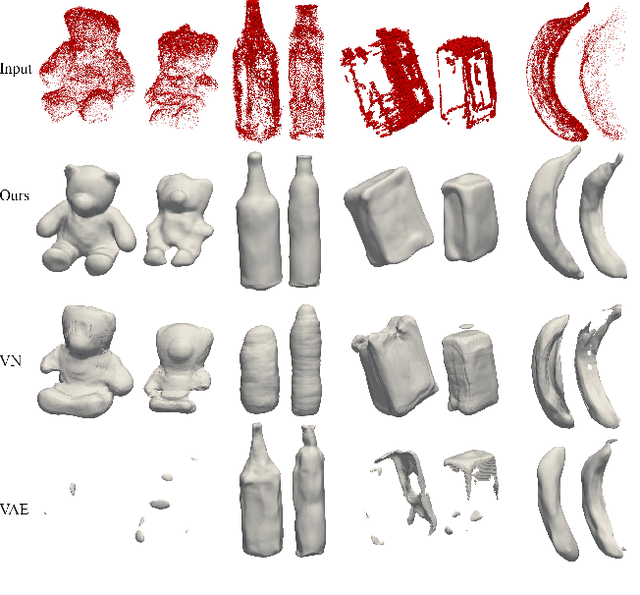
The task of shape space learning involves mapping a train set of shapes to and from a latent representation space with good generalization properties. Often, real-world collections of shapes have symmetries, which can be defined as transformations that do not change the essence of the shape. A natural way to incorporate symmetries in shape space learning is to ask that the mapping to the shape space (encoder) and mapping from the shape space (decoder) are equivariant to the relevant symmetries. In this paper, we present a framework for incorporating equivariance in encoders and decoders by introducing two contributions: (i) adapting the recent Frame Averaging (FA) framework for building generic, efficient, and maximally expressive Equivariant autoencoders; and (ii) constructing autoencoders equivariant to piecewise Euclidean motions applied to different parts of the shape. To the best of our knowledge, this is the first fully piecewise Euclidean equivariant autoencoder construction. Training our framework is simple: it uses standard reconstruction losses and does not require the introduction of new losses. Our architectures are built of standard (backbone) architectures with the appropriate frame averaging to make them equivariant. Testing our framework on both rigid shapes dataset using implicit neural representations, and articulated shape datasets using mesh-based neural networks show state-of-the-art generalization to unseen test shapes, improving relevant baselines by a large margin. In particular, our method demonstrates significant improvement in generalizing to unseen articulated poses.