 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Semantic and Rendering Enhancements in 3D Gaussian Modeling with Anisotropic Local Encoding
Jan 05, 2026Recent works propose extending 3DGS with semantic feature vectors for simultaneous semantic segmentation and image rendering. However, these methods often treat the semantic and rendering branches separately, relying solely on 2D supervision while ignoring the 3D Gaussian geometry. Moreover, current adaptive strategies adapt the Gaussian set depending solely on rendering gradients, which can be insufficient in subtle or textureless regions. In this work, we propose a joint enhancement framework for 3D semantic Gaussian modeling that synergizes both semantic and rendering branches. Firstly, unlike conventional point cloud shape encoding, we introduce an anisotropic 3D Gaussian Chebyshev descriptor using the Laplace-Beltrami operator to capture fine-grained 3D shape details, thereby distinguishing objects with similar appearances and reducing reliance on potentially noisy 2D guidance. In addition, without relying solely on rendering gradient, we adaptively adjust Gaussian allocation and spherical harmonics with local semantic and shape signals, enhancing rendering efficiency through selective resource allocation. Finally, we employ a cross-scene knowledge transfer module to continuously update learned shape patterns, enabling faster convergence and robust representations without relearning shape information from scratch for each new scene. Experiments on multiple datasets demonstrate improvements in segmentation accuracy and rendering quality while maintaining high rendering frame rates.
Towards Ancient Plant Seed Classification: A Benchmark Dataset and Baseline Model
Dec 20, 2025Understanding the dietary preferences of ancient societies and their evolution across periods and regions is crucial for revealing human-environment interactions. Seeds, as important archaeological artifacts, represent a fundamental subject of archaeobotanical research. However, traditional studies rely heavily on expert knowledge, which is often time-consuming and inefficient. Intelligent analysis methods have made progress in various fields of archaeology, but there remains a research gap in data and methods in archaeobotany, especially in the classification task of ancient plant seeds. To address this, we construct the first Ancient Plant Seed Image Classification (APS) dataset. It contains 8,340 images from 17 genus- or species-level seed categories excavated from 18 archaeological sites across China. In addition, we design a framework specifically for the ancient plant seed classification task (APSNet), which introduces the scale feature (size) of seeds based on learning fine-grained information to guide the network in discovering key "evidence" for sufficient classification. Specifically, we design a Size Perception and Embedding (SPE) module in the encoder part to explicitly extract size information for the purpose of complementing fine-grained information. We propose an Asynchronous Decoupled Decoding (ADD) architecture based on traditional progressive learning to decode features from both channel and spatial perspectives, enabling efficient learning of discriminative features. In both quantitative and qualitative analyses, our approach surpasses existing state-of-the-art image classification methods, achieving an accuracy of 90.5%. This demonstrates that our work provides an effective tool for large-scale, systematic archaeological research.
WaterFlow: Explicit Physics-Prior Rectified Flow for Underwater Saliency Mask Generation
Oct 14, 2025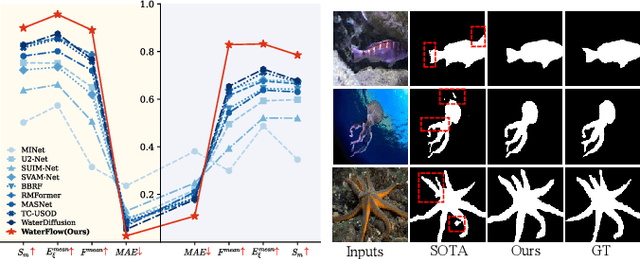
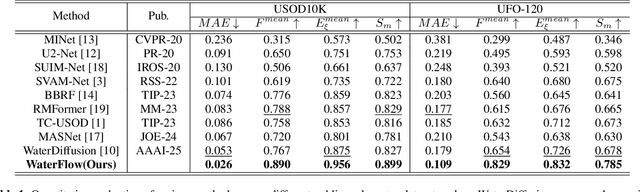
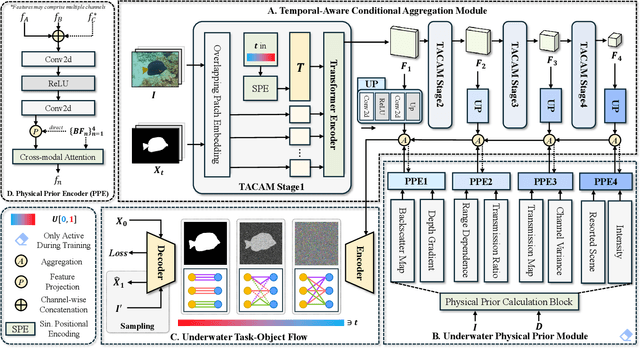

Underwater Salient Object Detection (USOD) faces significant challenges, including underwater image quality degradation and domain gaps. Existing methods tend to ignore the physical principles of underwater imaging or simply treat degradation phenomena in underwater images as interference factors that must be eliminated, failing to fully exploit the valuable information they contain. We propose WaterFlow, a rectified flow-based framework for underwater salient object detection that innovatively incorporates underwater physical imaging information as explicit priors directly into the network training process and introduces temporal dimension modeling, significantly enhancing the model's capability for salient object identification. On the USOD10K dataset, WaterFlow achieves a 0.072 gain in S_m, demonstrating the effectiveness and superiority of our method. The code will be published after the acceptance.
STQE: Spatial-Temporal Quality Enhancement for G-PCC Compressed Dynamic Point Clouds
Jul 23, 2025Very few studies have addressed quality enhancement for compressed dynamic point clouds. In particular, the effective exploitation of spatial-temporal correlations between point cloud frames remains largely unexplored. Addressing this gap, we propose a spatial-temporal attribute quality enhancement (STQE) network that exploits both spatial and temporal correlations to improve the visual quality of G-PCC compressed dynamic point clouds. Our contributions include a recoloring-based motion compensation module that remaps reference attribute information to the current frame geometry to achieve precise inter-frame geometric alignment, a channel-aware temporal attention module that dynamically highlights relevant regions across bidirectional reference frames, a Gaussian-guided neighborhood feature aggregation module that efficiently captures spatial dependencies between geometry and color attributes, and a joint loss function based on the Pearson correlation coefficient, designed to alleviate over-smoothing effects typical of point-wise mean squared error optimization. When applied to the latest G-PCC test model, STQE achieved improvements of 0.855 dB, 0.682 dB, and 0.828 dB in delta PSNR, with Bj{\o}ntegaard Delta rate (BD-rate) reductions of -25.2%, -31.6%, and -32.5% for the Luma, Cb, and Cr components, respectively.
Tree-Mamba: A Tree-Aware Mamba for Underwater Monocular Depth Estimation
Jul 10, 2025Underwater Monocular Depth Estimation (UMDE) is a critical task that aims to estimate high-precision depth maps from underwater degraded images caused by light absorption and scattering effects in marine environments. Recently, Mamba-based methods have achieved promising performance across various vision tasks; however, they struggle with the UMDE task because their inflexible state scanning strategies fail to model the structural features of underwater images effectively. Meanwhile, existing UMDE datasets usually contain unreliable depth labels, leading to incorrect object-depth relationships between underwater images and their corresponding depth maps. To overcome these limitations, we develop a novel tree-aware Mamba method, dubbed Tree-Mamba, for estimating accurate monocular depth maps from underwater degraded images. Specifically, we propose a tree-aware scanning strategy that adaptively constructs a minimum spanning tree based on feature similarity. The spatial topological features among the tree nodes are then flexibly aggregated through bottom-up and top-down traversals, enabling stronger multi-scale feature representation capabilities. Moreover, we construct an underwater depth estimation benchmark (called BlueDepth), which consists of 38,162 underwater image pairs with reliable depth labels. This benchmark serves as a foundational dataset for training existing deep learning-based UMDE methods to learn accurate object-depth relationships. Extensive experiments demonstrate the superiority of the proposed Tree-Mamba over several leading methods in both qualitative results and quantitative evaluations with competitive computational efficiency. Code and dataset will be available at https://wyjgr.github.io/Tree-Mamba.html.
Structural Similarity-Inspired Unfolding for Lightweight Image Super-Resolution
Jun 13, 2025Major efforts in data-driven image super-resolution (SR) primarily focus on expanding the receptive field of the model to better capture contextual information. However, these methods are typically implemented by stacking deeper networks or leveraging transformer-based attention mechanisms, which consequently increases model complexity. In contrast, model-driven methods based on the unfolding paradigm show promise in improving performance while effectively maintaining model compactness through sophisticated module design. Based on these insights, we propose a Structural Similarity-Inspired Unfolding (SSIU) method for efficient image SR. This method is designed through unfolding an SR optimization function constrained by structural similarity, aiming to combine the strengths of both data-driven and model-driven approaches. Our model operates progressively following the unfolding paradigm. Each iteration consists of multiple Mixed-Scale Gating Modules (MSGM) and an Efficient Sparse Attention Module (ESAM). The former implements comprehensive constraints on features, including a structural similarity constraint, while the latter aims to achieve sparse activation. In addition, we design a Mixture-of-Experts-based Feature Selector (MoE-FS) that fully utilizes multi-level feature information by combining features from different steps. Extensive experiments validate the efficacy and efficiency of our unfolding-inspired network. Our model outperforms current state-of-the-art models, boasting lower parameter counts and reduced memory consumption. Our code will be available at: https://github.com/eezkni/SSIU
Proto-FG3D: Prototype-based Interpretable Fine-Grained 3D Shape Classification
May 23, 2025Deep learning-based multi-view coarse-grained 3D shape classification has achieved remarkable success over the past decade, leveraging the powerful feature learning capabilities of CNN-based and ViT-based backbones. However, as a challenging research area critical for detailed shape understanding, fine-grained 3D classification remains understudied due to the limited discriminative information captured during multi-view feature aggregation, particularly for subtle inter-class variations, class imbalance, and inherent interpretability limitations of parametric model. To address these problems, we propose the first prototype-based framework named Proto-FG3D for fine-grained 3D shape classification, achieving a paradigm shift from parametric softmax to non-parametric prototype learning. Firstly, Proto-FG3D establishes joint multi-view and multi-category representation learning via Prototype Association. Secondly, prototypes are refined via Online Clustering, improving both the robustness of multi-view feature allocation and inter-subclass balance. Finally, prototype-guided supervised learning is established to enhance fine-grained discrimination via prototype-view correlation analysis and enables ad-hoc interpretability through transparent case-based reasoning. Experiments on FG3D and ModelNet40 show Proto-FG3D surpasses state-of-the-art methods in accuracy, transparent predictions, and ad-hoc interpretability with visualizations, challenging conventional fine-grained 3D recognition approaches.
UWSAM: Segment Anything Model Guided Underwater Instance Segmentation and A Large-scale Benchmark Dataset
May 21, 2025With recent breakthroughs in large-scale modeling, the Segment Anything Model (SAM) has demonstrated significant potential in a variety of visual applications. However, due to the lack of underwater domain expertise, SAM and its variants face performance limitations in end-to-end underwater instance segmentation tasks, while their higher computational requirements further hinder their application in underwater scenarios. To address this challenge, we propose a large-scale underwater instance segmentation dataset, UIIS10K, which includes 10,048 images with pixel-level annotations for 10 categories. Then, we introduce UWSAM, an efficient model designed for automatic and accurate segmentation of underwater instances. UWSAM efficiently distills knowledge from the SAM ViT-Huge image encoder into the smaller ViT-Small image encoder via the Mask GAT-based Underwater Knowledge Distillation (MG-UKD) method for effective visual representation learning. Furthermore, we design an End-to-end Underwater Prompt Generator (EUPG) for UWSAM, which automatically generates underwater prompts instead of explicitly providing foreground points or boxes as prompts, thus enabling the network to locate underwater instances accurately for efficient segmentation. Comprehensive experimental results show that our model is effective, achieving significant performance improvements over state-of-the-art methods on multiple underwater instance datasets. Datasets and codes are available at https://github.com/LiamLian0727/UIIS10K.
SEFE: Superficial and Essential Forgetting Eliminator for Multimodal Continual Instruction Tuning
May 05, 2025Multimodal Continual Instruction Tuning (MCIT) aims to enable Multimodal Large Language Models (MLLMs) to incrementally learn new tasks without catastrophic forgetting. In this paper, we explore forgetting in this context, categorizing it into superficial forgetting and essential forgetting. Superficial forgetting refers to cases where the model's knowledge may not be genuinely lost, but its responses to previous tasks deviate from expected formats due to the influence of subsequent tasks' answer styles, making the results unusable. By contrast, essential forgetting refers to situations where the model provides correctly formatted but factually inaccurate answers, indicating a true loss of knowledge. Assessing essential forgetting necessitates addressing superficial forgetting first, as severe superficial forgetting can obscure the model's knowledge state. Hence, we first introduce the Answer Style Diversification (ASD) paradigm, which defines a standardized process for transforming data styles across different tasks, unifying their training sets into similarly diversified styles to prevent superficial forgetting caused by style shifts. Building on this, we propose RegLoRA to mitigate essential forgetting. RegLoRA stabilizes key parameters where prior knowledge is primarily stored by applying regularization, enabling the model to retain existing competencies. Experimental results demonstrate that our overall method, SEFE, achieves state-of-the-art performance.
CompGS++: Compressed Gaussian Splatting for Static and Dynamic Scene Representation
Apr 17, 2025



Gaussian splatting demonstrates proficiency for 3D scene modeling but suffers from substantial data volume due to inherent primitive redundancy. To enable future photorealistic 3D immersive visual communication applications, significant compression is essential for transmission over the existing Internet infrastructure. Hence, we propose Compressed Gaussian Splatting (CompGS++), a novel framework that leverages compact Gaussian primitives to achieve accurate 3D modeling with substantial size reduction for both static and dynamic scenes. Our design is based on the principle of eliminating redundancy both between and within primitives. Specifically, we develop a comprehensive prediction paradigm to address inter-primitive redundancy through spatial and temporal primitive prediction modules. The spatial primitive prediction module establishes predictive relationships for scene primitives and enables most primitives to be encoded as compact residuals, substantially reducing the spatial redundancy. We further devise a temporal primitive prediction module to handle dynamic scenes, which exploits primitive correlations across timestamps to effectively reduce temporal redundancy. Moreover, we devise a rate-constrained optimization module that jointly minimizes reconstruction error and rate consumption. This module effectively eliminates parameter redundancy within primitives and enhances the overall compactness of scene representations. Comprehensive evaluations across multiple benchmark datasets demonstrate that CompGS++ significantly outperforms existing methods, achieving superior compression performance while preserving accurate scene modeling. Our implementation will be made publicly available on GitHub to facilitate further research.