 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Semantic and Rendering Enhancements in 3D Gaussian Modeling with Anisotropic Local Encoding
Jan 05, 2026Recent works propose extending 3DGS with semantic feature vectors for simultaneous semantic segmentation and image rendering. However, these methods often treat the semantic and rendering branches separately, relying solely on 2D supervision while ignoring the 3D Gaussian geometry. Moreover, current adaptive strategies adapt the Gaussian set depending solely on rendering gradients, which can be insufficient in subtle or textureless regions. In this work, we propose a joint enhancement framework for 3D semantic Gaussian modeling that synergizes both semantic and rendering branches. Firstly, unlike conventional point cloud shape encoding, we introduce an anisotropic 3D Gaussian Chebyshev descriptor using the Laplace-Beltrami operator to capture fine-grained 3D shape details, thereby distinguishing objects with similar appearances and reducing reliance on potentially noisy 2D guidance. In addition, without relying solely on rendering gradient, we adaptively adjust Gaussian allocation and spherical harmonics with local semantic and shape signals, enhancing rendering efficiency through selective resource allocation. Finally, we employ a cross-scene knowledge transfer module to continuously update learned shape patterns, enabling faster convergence and robust representations without relearning shape information from scratch for each new scene. Experiments on multiple datasets demonstrate improvements in segmentation accuracy and rendering quality while maintaining high rendering frame rates.
Exploiting Local and Global Structure for Point Cloud Semantic Segmentation with Contextual Point Representations
Nov 13, 2019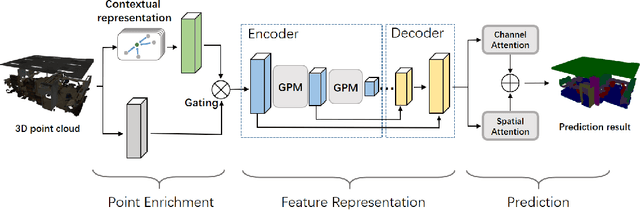
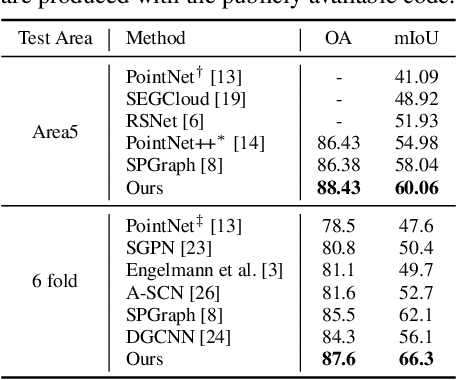
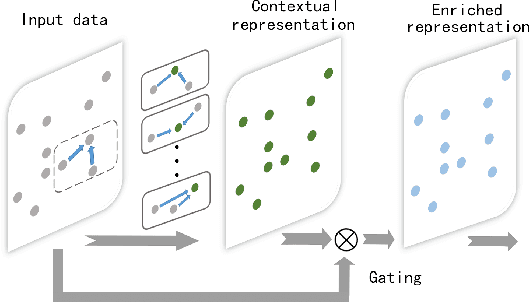
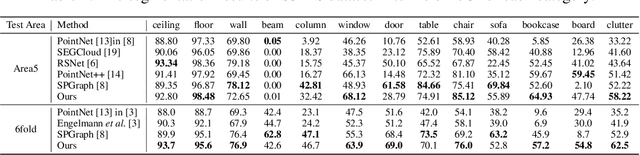
In this paper, we propose one novel model for point cloud semantic segmentation, which exploits both the local and global structures within the point cloud based on the contextual point representations. Specifically, we enrich each point representation by performing one novel gated fusion on the point itself and its contextual points. Afterwards, based on the enriched representation, we propose one novel graph pointnet module, relying on the graph attention block to dynamically compose and update each point representation within the local point cloud structure. Finally, we resort to the spatial-wise and channel-wise attention strategies to exploit the point cloud global structure and thereby yield the resulting semantic label for each point. Extensive results on the public point cloud databases, namely the S3DIS and ScanNet datasets, demonstrate the effectiveness of our proposed model, outperforming the state-of-the-art approaches. Our code for this paper is available at https://github.com/fly519/ELGS.