 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimelyFL: Heterogeneity-aware Asynchronous Federated Learning with Adaptive Partial Training
Apr 14, 2023



In cross-device Federated Learning (FL) environments, scaling synchronous FL methods is challenging as stragglers hinder the training process. Moreover, the availability of each client to join the training is highly variable over time due to system heterogeneities and intermittent connectivity. Recent asynchronous FL methods (e.g., FedBuff) have been proposed to overcome these issues by allowing slower users to continue their work on local training based on stale models and to contribute to aggregation when ready. However, we show empirically that this method can lead to a substantial drop in training accuracy as well as a slower convergence rate. The primary reason is that fast-speed devices contribute to many more rounds of aggregation while others join more intermittently or not at all, and with stale model updates. To overcome this barrier, we propose TimelyFL, a heterogeneity-aware asynchronous FL framework with adaptive partial training. During the training, TimelyFL adjusts the local training workload based on the real-time resource capabilities of each client, aiming to allow more available clients to join in the global update without staleness. We demonstrate the performance benefits of TimelyFL by conducting extensive experiments on various datasets (e.g., CIFAR-10, Google Speech, and Reddit) and models (e.g., ResNet20, VGG11, and ALBERT). In comparison with the state-of-the-art (i.e., FedBuff), our evaluations reveal that TimelyFL improves participation rate by 21.13%, harvests 1.28x - 2.89x more efficiency on convergence rate, and provides a 6.25% increment on test accuracy.
The Resource Problem of Using Linear Layer Leakage Attack in Federated Learning
Mar 27, 2023



Secure aggregation promises a heightened level of privacy in federated learning, maintaining that a server only has access to a decrypted aggregate update. Within this setting, linear layer leakage methods are the only data reconstruction attacks able to scale and achieve a high leakage rate regardless of the number of clients or batch size. This is done through increasing the size of an injected fully-connected (FC) layer. However, this results in a resource overhead which grows larger with an increasing number of clients. We show that this resource overhead is caused by an incorrect perspective in all prior work that treats an attack on an aggregate update in the same way as an individual update with a larger batch size. Instead, by attacking the update from the perspective that aggregation is combining multiple individual updates, this allows the application of sparsity to alleviate resource overhead. We show that the use of sparsity can decrease the model size overhead by over 327$\times$ and the computation time by 3.34$\times$ compared to SOTA while maintaining equivalent total leakage rate, 77% even with $1000$ clients in aggregation.
Secure Aggregation in Federated Learning is not Private: Leaking User Data at Large Scale through Model Modification
Mar 21, 2023



Security and privacy are important concerns in machine learning. End user devices often contain a wealth of data and this information is sensitive and should not be shared with servers or enterprises. As a result, federated learning was introduced to enable machine learning over large decentralized datasets while promising privacy by eliminating the need for data sharing. However, prior work has shown that shared gradients often contain private information and attackers can gain knowledge either through malicious modification of the architecture and parameters or by using optimization to approximate user data from the shared gradients. Despite this, most attacks have so far been limited in scale of number of clients, especially failing when client gradients are aggregated together using secure model aggregation. The attacks that still function are strongly limited in the number of clients attacked, amount of training samples they leak, or number of iterations they take to be trained. In this work, we introduce MANDRAKE, an attack that overcomes previous limitations to directly leak large amounts of client data even under secure aggregation across large numbers of clients. Furthermore, we break the anonymity of aggregation as the leaked data is identifiable and directly tied back to the clients they come from. We show that by sending clients customized convolutional parameters, the weight gradients of data points between clients will remain separate through aggregation. With an aggregation across many clients, prior work could only leak less than 1% of images. With the same number of non-zero parameters, and using only a single training iteration, MANDRAKE leaks 70-80% of data samples.
FedML-HE: An Efficient Homomorphic-Encryption-Based Privacy-Preserving Federated Learning System
Mar 20, 2023



Federated Learning (FL) enables machine learning model training on distributed edge devices by aggregating local model updates rather than local data. However, privacy concerns arise as the FL server's access to local model updates can potentially reveal sensitive personal information by performing attacks like gradient inversion recovery. To address these concerns, privacy-preserving methods, such as Homomorphic Encryption (HE)-based approaches, have been proposed. Despite HE's post-quantum security advantages, its applications suffer from impractical overheads. In this paper, we present FedML-HE, the first practical system for efficient HE-based secure federated aggregation that provides a user/device-friendly deployment platform. FL-HE utilizes a novel universal overhead optimization scheme, significantly reducing both computation and communication overheads during deployment while providing customizable privacy guarantees. Our optimized system demonstrates considerable overhead reduction, particularly for large models (e.g., ~10x reduction for HE-federated training of ResNet-50 and ~40x reduction for BERT), demonstrating the potential for scalable HE-based FL deployment.
FedML Parrot: A Scalable Federated Learning System via Heterogeneity-aware Scheduling on Sequential and Hierarchical Training
Mar 03, 2023



Federated Learning (FL) enables collaborations among clients for train machine learning models while protecting their data privacy. Existing FL simulation platforms that are designed from the perspectives of traditional distributed training, suffer from laborious code migration between simulation and production, low efficiency, low GPU utility, low scalability with high hardware requirements and difficulty of simulating stateful clients. In this work, we firstly demystify the challenges and bottlenecks of simulating FL, and design a new FL system named as FedML \texttt{Parrot}. It improves the training efficiency, remarkably relaxes the requirements on the hardware, and supports efficient large-scale FL experiments with stateful clients by: (1) sequential training clients on devices; (2) decomposing original aggregation into local and global aggregation on devices and server respectively; (3) scheduling tasks to mitigate straggler problems and enhance computing utility; (4) distributed client state manager to support various FL algorithms. Besides, built upon our generic APIs and communication interfaces, users can seamlessly transform the simulation into the real-world deployment without modifying codes. We evaluate \texttt{Parrot} through extensive experiments for training diverse models on various FL datasets to demonstrate that \texttt{Parrot} can achieve simulating over 1000 clients (stateful or stateless) with flexible GPU devices setting ($4 \sim 32$) and high GPU utility, 1.2 $\sim$ 4 times faster than FedScale, and 10 $\sim$ 100 times memory saving than FedML. And we verify that \texttt{Parrot} works well with homogeneous and heterogeneous devices in three different clusters. Two FL algorithms with stateful clients and four algorithms with stateless clients are simulated to verify the wide adaptability of \texttt{Parrot} to different algorithms.
Proof-of-Contribution-Based Design for Collaborative Machine Learning on Blockchain
Feb 27, 2023



We consider a project (model) owner that would like to train a model by utilizing the local private data and compute power of interested data owners, i.e., trainers. Our goal is to design a data marketplace for such decentralized collaborative/federated learning applications that simultaneously provides i) proof-of-contribution based reward allocation so that the trainers are compensated based on their contributions to the trained model; ii) privacy-preserving decentralized model training by avoiding any data movement from data owners; iii) robustness against malicious parties (e.g., trainers aiming to poison the model); iv) verifiability in the sense that the integrity, i.e., correctness, of all computations in the data market protocol including contribution assessment and outlier detection are verifiable through zero-knowledge proofs; and v) efficient and universal design. We propose a blockchain-based marketplace design to achieve all five objectives mentioned above. In our design, we utilize a distributed storage infrastructure and an aggregator aside from the project owner and the trainers. The aggregator is a processing node that performs certain computations, including assessing trainer contributions, removing outliers, and updating hyper-parameters. We execute the proposed data market through a blockchain smart contract. The deployed smart contract ensures that the project owner cannot evade payment, and honest trainers are rewarded based on their contributions at the end of training. Finally, we implement the building blocks of the proposed data market and demonstrate their applicability in practical scenarios through extensive experiments.
Federated Analytics: A survey
Feb 02, 2023



Federated analytics (FA) is a privacy-preserving framework for computing data analytics over multiple remote parties (e.g., mobile devices) or silo-ed institutional entities (e.g., hospitals, banks) without sharing the data among parties. Motivated by the practical use cases of federated analytics, we follow a systematic discussion on federated analytics in this article. In particular, we discuss the unique characteristics of federated analytics and how it differs from federated learning. We also explore a wide range of FA queries and discuss various existing solutions and potential use case applications for different FA queries.
* To appear in APSIPA Transactions on Signal and Information Processing, Volume 12, Issue 1
SMILE: Scaling Mixture-of-Experts with Efficient Bi-level Routing
Dec 10, 2022



The mixture of Expert (MoE) parallelism is a recent advancement that scales up the model size with constant computational cost. MoE selects different sets of parameters (i.e., experts) for each incoming token, resulting in a sparsely-activated model. Despite several successful applications of MoE, its training efficiency degrades significantly as the number of experts increases. The routing stage in MoE relies on the efficiency of the All2All communication collective, which suffers from network congestion and has poor scalability. To mitigate these issues, we introduce SMILE, which exploits heterogeneous network bandwidth and splits a single-step routing into bi-level routing. Our experimental results show that the proposed method obtains a 2.5x speedup over Switch Transformer in terms of pretraining throughput on the Colossal Clean Crawled Corpus without losing any convergence speed.
FedAudio: A Federated Learning Benchmark for Audio Tasks
Nov 18, 2022



Federated learning (FL) has gained substantial attention in recent years due to the data privacy concerns related to the pervasiveness of consumer devices that continuously collect data from users. While a number of FL benchmarks have been developed to facilitate FL research, none of them include audio data and audio-related tasks. In this paper, we fill this critical gap by introducing a new FL benchmark for audio tasks which we refer to as FedAudio. FedAudio includes four representative and commonly used audio datasets from three important audio tasks that are well aligned with FL use cases. In particular, a unique contribution of FedAudio is the introduction of data noises and label errors to the datasets to emulate challenges when deploying FL systems in real-world settings. FedAudio also includes the benchmark results of the datasets and a PyTorch library with the objective of facilitating researchers to fairly compare their algorithms. We hope FedAudio could act as a catalyst to inspire new FL research for audio tasks and thus benefit the acoustic and speech research community. The datasets and benchmark results can be accessed at https://github.com/zhang-tuo-pdf/FedAudio.
FLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings
Oct 10, 2022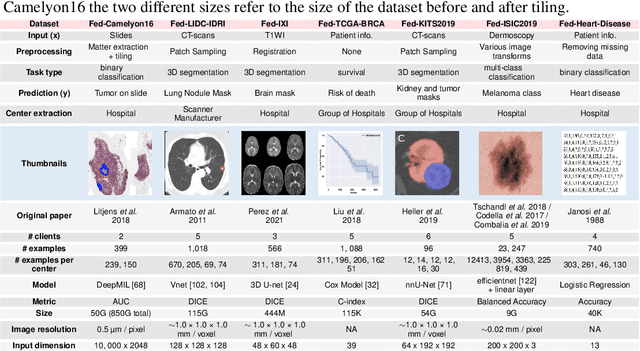
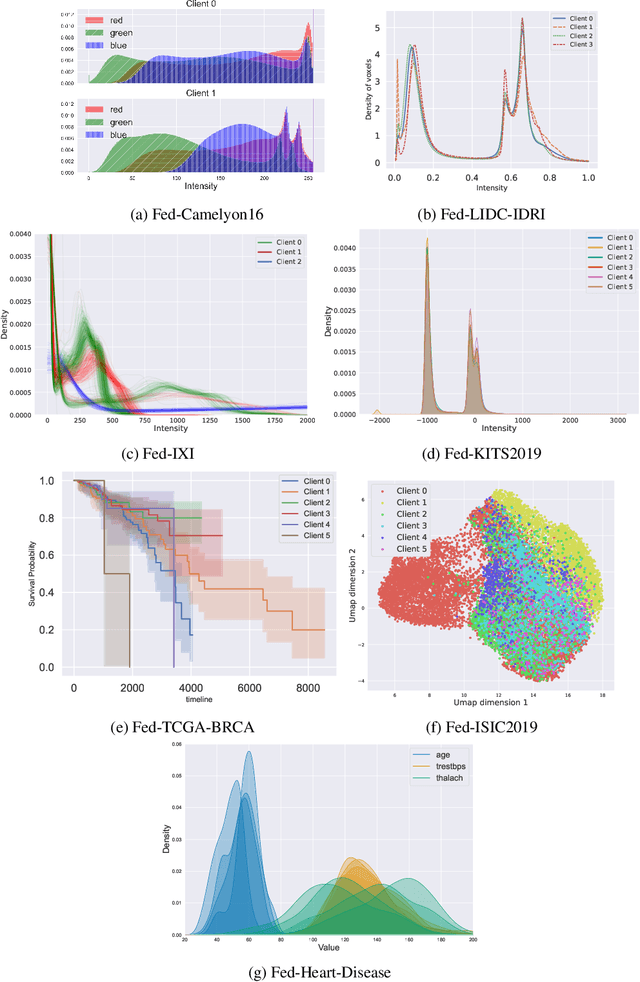
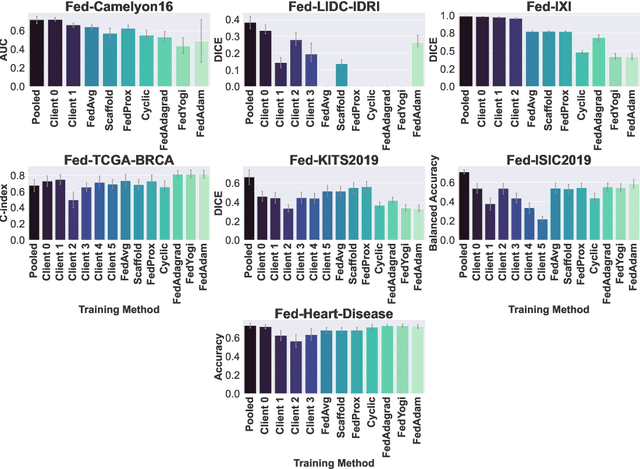

Federated Learning (FL) is a novel approach enabling several clients holding sensitive data to collaboratively train machine learning models, without centralizing data. The cross-silo FL setting corresponds to the case of few ($2$--$50$) reliable clients, each holding medium to large datasets, and is typically found in applications such as healthcare, finance, or industry. While previous works have proposed representative datasets for cross-device FL, few realistic healthcare cross-silo FL datasets exist, thereby slowing algorithmic research in this critical application. In this work, we propose a novel cross-silo dataset suite focused on healthcare, FLamby (Federated Learning AMple Benchmark of Your cross-silo strategies), to bridge the gap between theory and practice of cross-silo FL. FLamby encompasses 7 healthcare datasets with natural splits, covering multiple tasks, modalities, and data volumes, each accompanied with baseline training code. As an illustration, we additionally benchmark standard FL algorithms on all datasets. Our flexible and modular suite allows researchers to easily download datasets, reproduce results and re-use the different components for their research. FLamby is available at~\url{www.github.com/owkin/flamby}.