 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSR-Net: Multi-Scale Relighting Network for One-to-One Relighting
Jul 13, 2021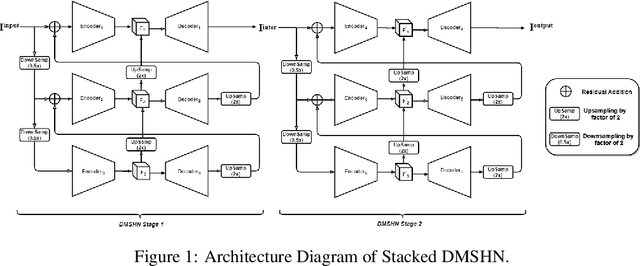


Deep image relighting allows photo enhancement by illumination-specific retouching without human effort and so it is getting much interest lately. Most of the existing popular methods available for relighting are run-time intensive and memory inefficient. Keeping these issues in mind, we propose the use of Stacked Deep Multi-Scale Hierarchical Network, which aggregates features from each image at different scales. Our solution is differentiable and robust for translating image illumination setting from input image to target image. Additionally, we have also shown that using a multi-step training approach to this problem with two different loss functions can significantly boost performance and can achieve a high quality reconstruction of a relighted image.
Fast and Accurate Quantized Camera Scene Detection on Smartphones, Mobile AI 2021 Challenge: Report
May 17, 2021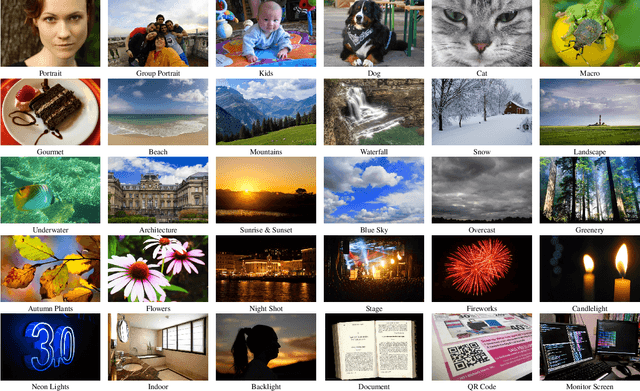
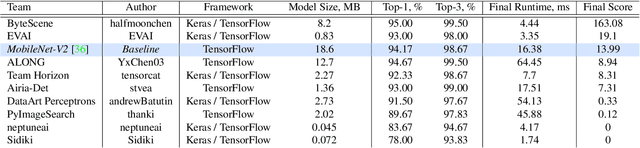

Camera scene detection is among the most popular computer vision problem on smartphones. While many custom solutions were developed for this task by phone vendors, none of the designed models were available publicly up until now. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop quantized deep learning-based camera scene classification solutions that can demonstrate a real-time performance on smartphones and IoT platforms. For this, the participants were provided with a large-scale CamSDD dataset consisting of more than 11K images belonging to the 30 most important scene categories. The runtime of all models was evaluated on the popular Apple Bionic A11 platform that can be found in many iOS devices. The proposed solutions are fully compatible with all major mobile AI accelerators and can demonstrate more than 100-200 FPS on the majority of recent smartphone platforms while achieving a top-3 accuracy of more than 98%. A detailed description of all models developed in the challenge is provided in this paper.
Stacked Deep Multi-Scale Hierarchical Network for Fast Bokeh Effect Rendering from a Single Image
May 15, 2021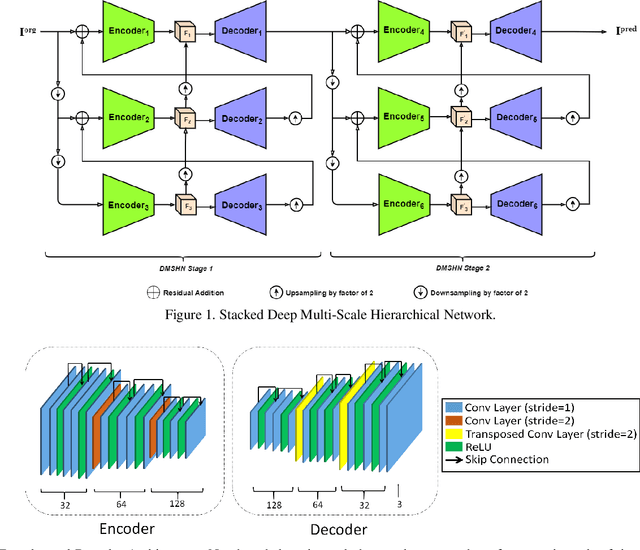
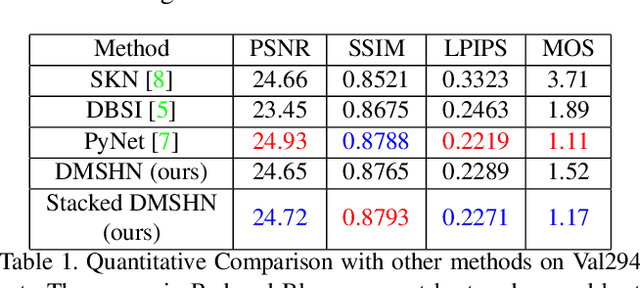

The Bokeh Effect is one of the most desirable effects in photography for rendering artistic and aesthetic photos. Usually, it requires a DSLR camera with different aperture and shutter settings and certain photography skills to generate this effect. In smartphones, computational methods and additional sensors are used to overcome the physical lens and sensor limitations to achieve such effect. Most of the existing methods utilized additional sensor's data or pretrained network for fine depth estimation of the scene and sometimes use portrait segmentation pretrained network module to segment salient objects in the image. Because of these reasons, networks have many parameters, become runtime intensive and unable to run in mid-range devices. In this paper, we used an end-to-end Deep Multi-Scale Hierarchical Network (DMSHN) model for direct Bokeh effect rendering of images captured from the monocular camera. To further improve the perceptual quality of such effect, a stacked model consisting of two DMSHN modules is also proposed. Our model does not rely on any pretrained network module for Monocular Depth Estimation or Saliency Detection, thus significantly reducing the size of model and run time. Stacked DMSHN achieves state-of-the-art results on a large scale EBB! dataset with around 6x less runtime compared to the current state-of-the-art model in processing HD quality images.
Efficient Space-time Video Super Resolution using Low-Resolution Flow and Mask Upsampling
May 03, 2021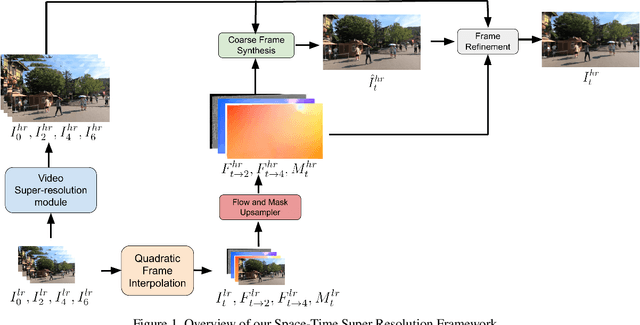
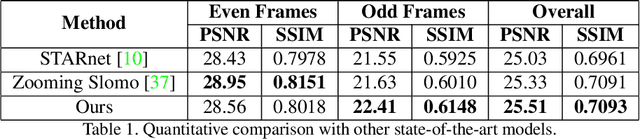

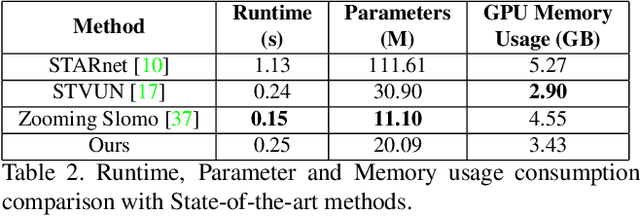
This paper explores an efficient solution for Space-time Super-Resolution, aiming to generate High-resolution Slow-motion videos from Low Resolution and Low Frame rate videos. A simplistic solution is the sequential running of Video Super Resolution and Video Frame interpolation models. However, this type of solutions are memory inefficient, have high inference time, and could not make the proper use of space-time relation property. To this extent, we first interpolate in LR space using quadratic modeling. Input LR frames are super-resolved using a state-of-the-art Video Super-Resolution method. Flowmaps and blending mask which are used to synthesize LR interpolated frame is reused in HR space using bilinear upsampling. This leads to a coarse estimate of HR intermediate frame which often contains artifacts along motion boundaries. We use a refinement network to improve the quality of HR intermediate frame via residual learning. Our model is lightweight and performs better than current state-of-the-art models in REDS STSR Validation set.
A Heuristic-driven Uncertainty based Ensemble Framework for Fake News Detection in Tweets and News Articles
Apr 05, 2021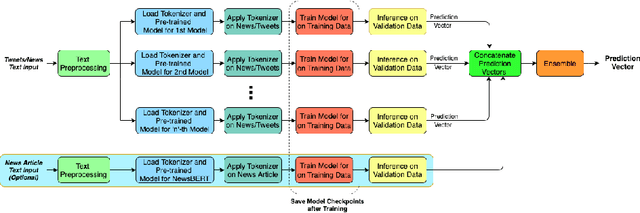

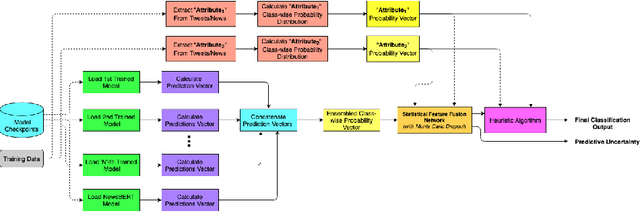
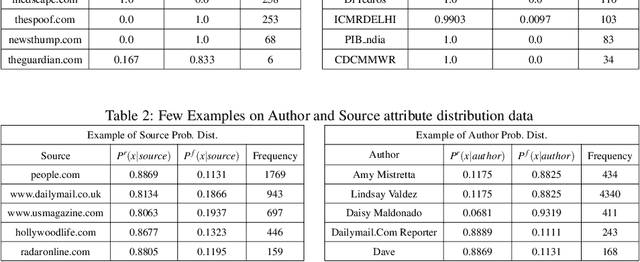
The significance of social media has increased manifold in the past few decades as it helps people from even the most remote corners of the world to stay connected. With the advent of technology, digital media has become more relevant and widely used than ever before and along with this, there has been a resurgence in the circulation of fake news and tweets that demand immediate attention. In this paper, we describe a novel Fake News Detection system that automatically identifies whether a news item is "real" or "fake", as an extension of our work in the CONSTRAINT COVID-19 Fake News Detection in English challenge. We have used an ensemble model consisting of pre-trained models followed by a statistical feature fusion network , along with a novel heuristic algorithm by incorporating various attributes present in news items or tweets like source, username handles, URL domains and authors as statistical feature. Our proposed framework have also quantified reliable predictive uncertainty along with proper class output confidence level for the classification task. We have evaluated our results on the COVID-19 Fake News dataset and FakeNewsNet dataset to show the effectiveness of the proposed algorithm on detecting fake news in short news content as well as in news articles. We obtained a best F1-score of 0.9892 on the COVID-19 dataset, and an F1-score of 0.9073 on the FakeNewsNet dataset.
DSRN: an Efficient Deep Network for Image Relighting
Feb 18, 2021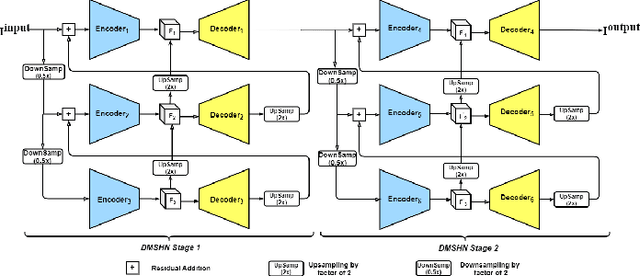
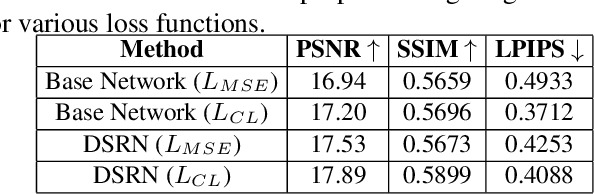
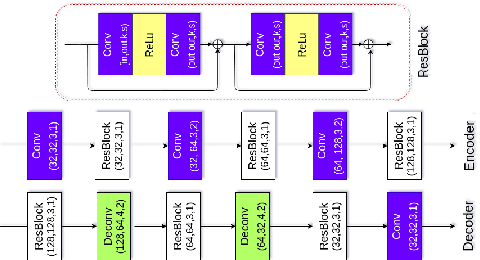
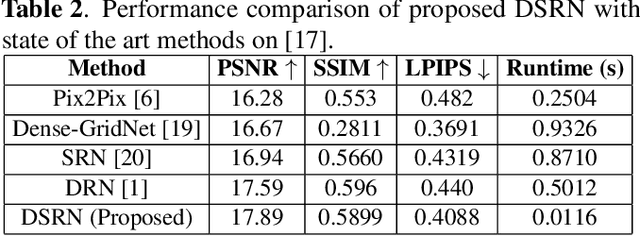
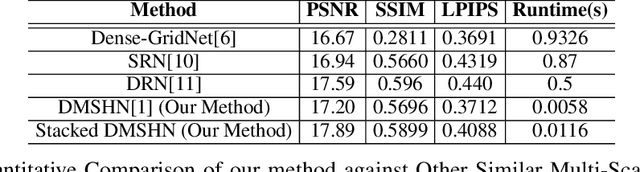
Custom and natural lighting conditions can be emulated in images of the scene during post-editing. Extraordinary capabilities of the deep learning framework can be utilized for such purpose. Deep image relighting allows automatic photo enhancement by illumination-specific retouching. Most of the state-of-the-art methods for relighting are run-time intensive and memory inefficient. In this paper, we propose an efficient, real-time framework Deep Stacked Relighting Network (DSRN) for image relighting by utilizing the aggregated features from input image at different scales. Our model is very lightweight with total size of about 42 MB and has an average inference time of about 0.0116s for image of resolution $1024 \times 1024$ which is faster as compared to other multi-scale models. Our solution is quite robust for translating image color temperature from input image to target image and also performs moderately for light gradient generation with respect to the target image. Additionally, we show that if images illuminated from opposite directions are used as input, the qualitative results improve over using a single input image.
A Heuristic-driven Ensemble Framework for COVID-19 Fake News Detection
Jan 10, 2021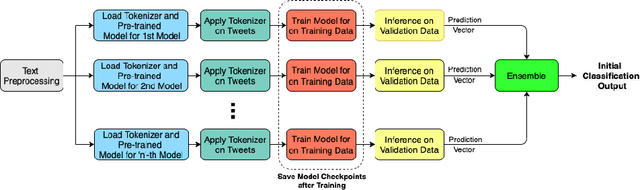
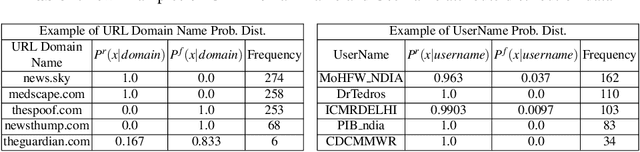
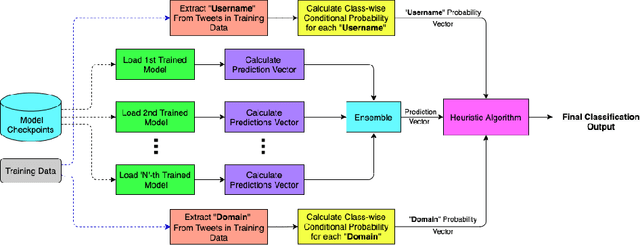
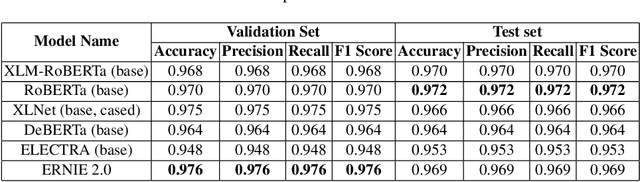
The significance of social media has increased manifold in the past few decades as it helps people from even the most remote corners of the world stay connected. With the COVID-19 pandemic raging, social media has become more relevant and widely used than ever before, and along with this, there has been a resurgence in the circulation of fake news and tweets that demand immediate attention. In this paper, we describe our Fake News Detection system that automatically identifies whether a tweet related to COVID-19 is "real" or "fake", as a part of CONSTRAINT COVID19 Fake News Detection in English challenge. We have used an ensemble model consisting of pre-trained models that has helped us achieve a joint 8th position on the leader board. We have achieved an F1-score of 0.9831 against a top score of 0.9869. Post completion of the competition, we have been able to drastically improve our system by incorporating a novel heuristic algorithm based on username handles and link domains in tweets fetching an F1-score of 0.9883 and achieving state-of-the art results on the given dataset.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020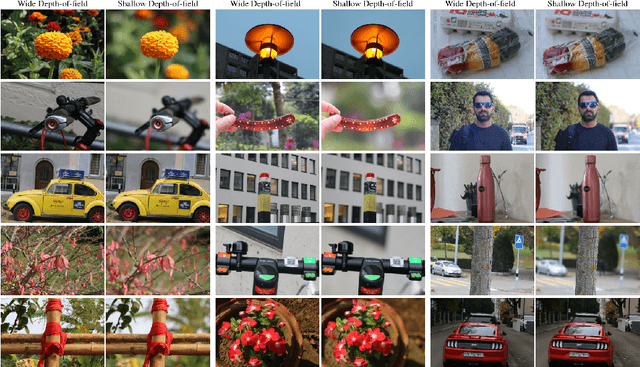


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
Depth-aware Blending of Smoothed Images for Bokeh Effect Generation
May 28, 2020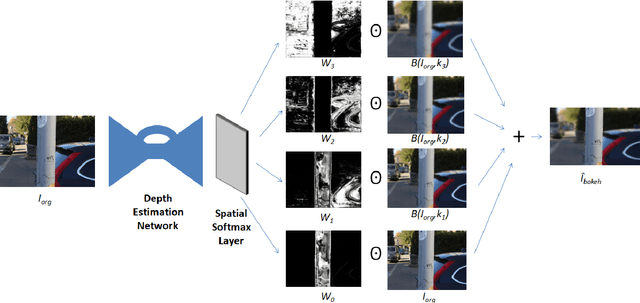
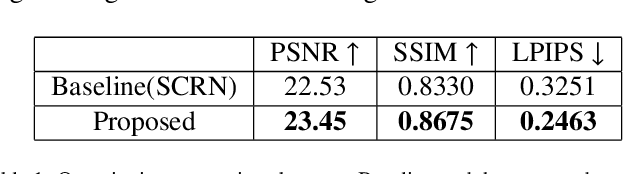
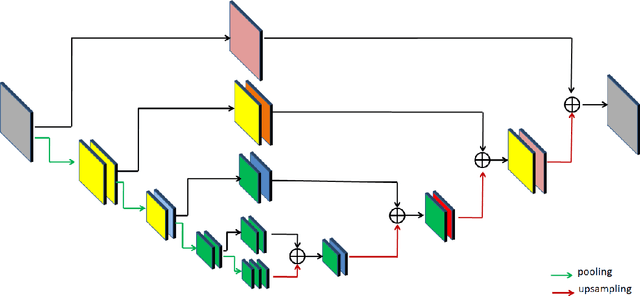
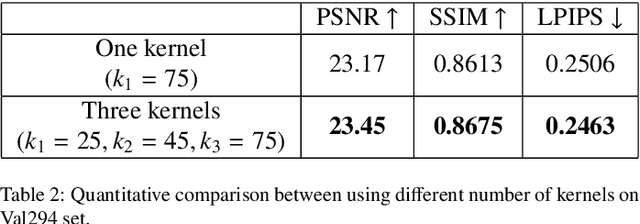
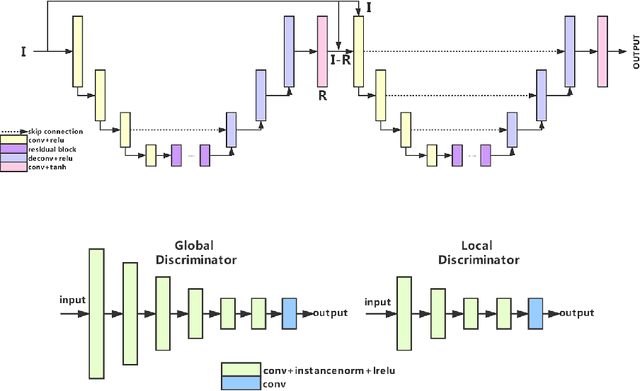
Bokeh effect is used in photography to capture images where the closer objects look sharp and every-thing else stays out-of-focus. Bokeh photos are generally captured using Single Lens Reflex cameras using shallow depth-of-field. Most of the modern smartphones can take bokeh images by leveraging dual rear cameras or a good auto-focus hardware. However, for smartphones with single-rear camera without a good auto-focus hardware, we have to rely on software to generate bokeh images. This kind of system is also useful to generate bokeh effect in already captured images. In this paper, an end-to-end deep learning framework is proposed to generate high-quality bokeh effect from images. The original image and different versions of smoothed images are blended to generate Bokeh effect with the help of a monocular depth estimation network. The proposed approach is compared against a saliency detection based baseline and a number of approaches proposed in AIM 2019 Challenge on Bokeh Effect Synthesis. Extensive experiments are shown in order to understand different parts of the proposed algorithm. The network is lightweight and can process an HD image in 0.03 seconds. This approach ranked second in AIM 2019 Bokeh effect challenge-Perceptual Track.
Fast Deep Multi-patch Hierarchical Network for Nonhomogeneous Image Dehazing
May 12, 2020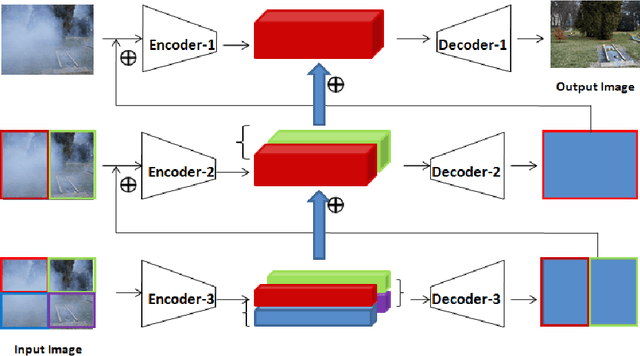
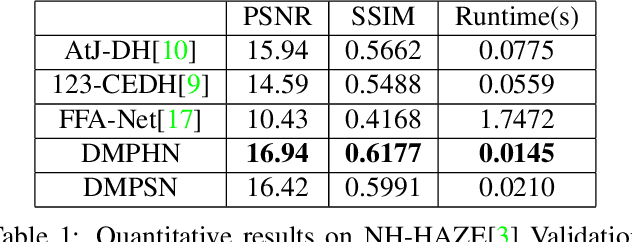
Recently, CNN based end-to-end deep learning methods achieve superiority in Image Dehazing but they tend to fail drastically in Non-homogeneous dehazing. Apart from that, existing popular Multi-scale approaches are runtime intensive and memory inefficient. In this context, we proposed a fast Deep Multi-patch Hierarchical Network to restore Non-homogeneous hazed images by aggregating features from multiple image patches from different spatial sections of the hazed image with fewer number of network parameters. Our proposed method is quite robust for different environments with various density of the haze or fog in the scene and very lightweight as the total size of the model is around 21.7 MB. It also provides faster runtime compared to current multi-scale methods with an average runtime of 0.0145s to process 1200x1600 HD quality image. Finally, we show the superiority of this network on Dense Haze Removal to other state-of-the-art models.