 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconstructing Instruction-Following: A New Benchmark for Granular Evaluation of Large Language Model Instruction Compliance Abilities
Jan 26, 2026Reliably ensuring Large Language Models (LLMs) follow complex instructions is a critical challenge, as existing benchmarks often fail to reflect real-world use or isolate compliance from task success. We introduce MOSAIC (MOdular Synthetic Assessment of Instruction Compliance), a modular framework that uses a dynamically generated dataset with up to 20 application-oriented generation constraints to enable a granular and independent analysis of this capability. Our evaluation of five LLMs from different families based on this new benchmark demonstrates that compliance is not a monolithic capability but varies significantly with constraint type, quantity, and position. The analysis reveals model-specific weaknesses, uncovers synergistic and conflicting interactions between instructions, and identifies distinct positional biases such as primacy and recency effects. These granular insights are critical for diagnosing model failures and developing more reliable LLMs for systems that demand strict adherence to complex instructions.
Enhancing LLM Instruction Following: An Evaluation-Driven Multi-Agentic Workflow for Prompt Instructions Optimization
Jan 06, 2026Large Language Models (LLMs) often generate substantively relevant content but fail to adhere to formal constraints, leading to outputs that are conceptually correct but procedurally flawed. Traditional prompt refinement approaches focus on rephrasing the description of the primary task an LLM has to perform, neglecting the granular constraints that function as acceptance criteria for its response. We propose a novel multi-agentic workflow that decouples optimization of the primary task description from its constraints, using quantitative scores as feedback to iteratively rewrite and improve them. Our evaluation demonstrates this method produces revised prompts that yield significantly higher compliance scores from models like Llama 3.1 8B and Mixtral-8x 7B.
GRAID: Synthetic Data Generation with Geometric Constraints and Multi-Agentic Reflection for Harmful Content Detection
Aug 23, 2025



We address the problem of data scarcity in harmful text classification for guardrailing applications and introduce GRAID (Geometric and Reflective AI-Driven Data Augmentation), a novel pipeline that leverages Large Language Models (LLMs) for dataset augmentation. GRAID consists of two stages: (i) generation of geometrically controlled examples using a constrained LLM, and (ii) augmentation through a multi-agentic reflective process that promotes stylistic diversity and uncovers edge cases. This combination enables both reliable coverage of the input space and nuanced exploration of harmful content. Using two benchmark data sets, we demonstrate that augmenting a harmful text classification dataset with GRAID leads to significant improvements in downstream guardrail model performance.
Building Safe GenAI Applications: An End-to-End Overview of Red Teaming for Large Language Models
Mar 05, 2025

The rapid growth of Large Language Models (LLMs) presents significant privacy, security, and ethical concerns. While much research has proposed methods for defending LLM systems against misuse by malicious actors, researchers have recently complemented these efforts with an offensive approach that involves red teaming, i.e., proactively attacking LLMs with the purpose of identifying their vulnerabilities. This paper provides a concise and practical overview of the LLM red teaming literature, structured so as to describe a multi-component system end-to-end. To motivate red teaming we survey the initial safety needs of some high-profile LLMs, and then dive into the different components of a red teaming system as well as software packages for implementing them. We cover various attack methods, strategies for attack-success evaluation, metrics for assessing experiment outcomes, as well as a host of other considerations. Our survey will be useful for any reader who wants to rapidly obtain a grasp of the major red teaming concepts for their own use in practical applications.
Description Boosting for Zero-Shot Entity and Relation Classification
Jun 04, 2024



Zero-shot entity and relation classification models leverage available external information of unseen classes -- e.g., textual descriptions -- to annotate input text data. Thanks to the minimum data requirement, Zero-Shot Learning (ZSL) methods have high value in practice, especially in applications where labeled data is scarce. Even though recent research in ZSL has demonstrated significant results, our analysis reveals that those methods are sensitive to provided textual descriptions of entities (or relations). Even a minor modification of descriptions can lead to a change in the decision boundary between entity (or relation) classes. In this paper, we formally define the problem of identifying effective descriptions for zero shot inference. We propose a strategy for generating variations of an initial description, a heuristic for ranking them and an ensemble method capable of boosting the predictions of zero-shot models through description enhancement. Empirical results on four different entity and relation classification datasets show that our proposed method outperform existing approaches and achieve new SOTA results on these datasets under the ZSL settings. The source code of the proposed solutions and the evaluation framework are open-sourced.
Zshot: An Open-source Framework for Zero-Shot Named Entity Recognition and Relation Extraction
Jul 25, 2023The Zero-Shot Learning (ZSL) task pertains to the identification of entities or relations in texts that were not seen during training. ZSL has emerged as a critical research area due to the scarcity of labeled data in specific domains, and its applications have grown significantly in recent years. With the advent of large pretrained language models, several novel methods have been proposed, resulting in substantial improvements in ZSL performance. There is a growing demand, both in the research community and industry, for a comprehensive ZSL framework that facilitates the development and accessibility of the latest methods and pretrained models.In this study, we propose a novel ZSL framework called Zshot that aims to address the aforementioned challenges. Our primary objective is to provide a platform that allows researchers to compare different state-of-the-art ZSL methods with standard benchmark datasets. Additionally, we have designed our framework to support the industry with readily available APIs for production under the standard SpaCy NLP pipeline. Our API is extendible and evaluable, moreover, we include numerous enhancements such as boosting the accuracy with pipeline ensembling and visualization utilities available as a SpaCy extension.
* Accepted at ACL 2023
Learning to Rank from Relevance Judgments Distributions
Feb 13, 2022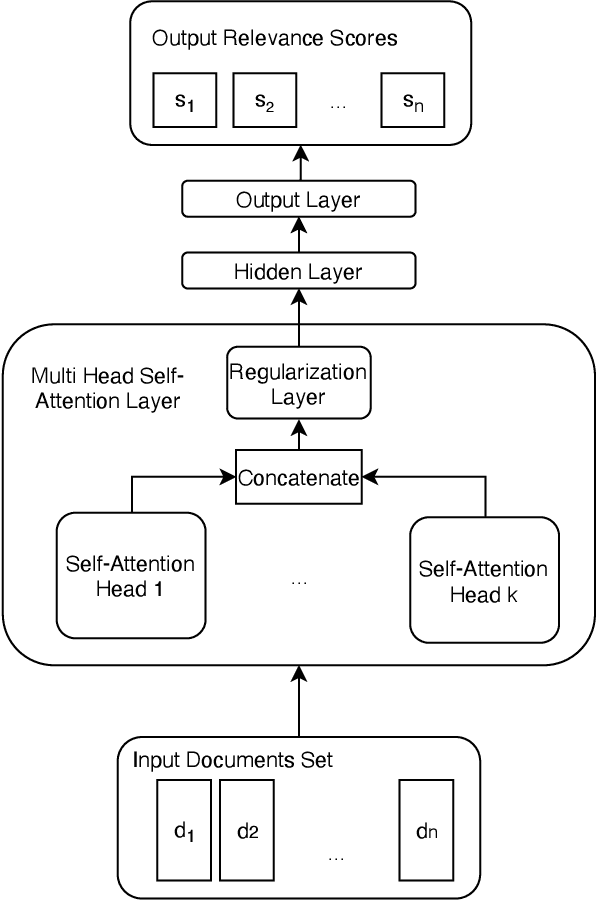
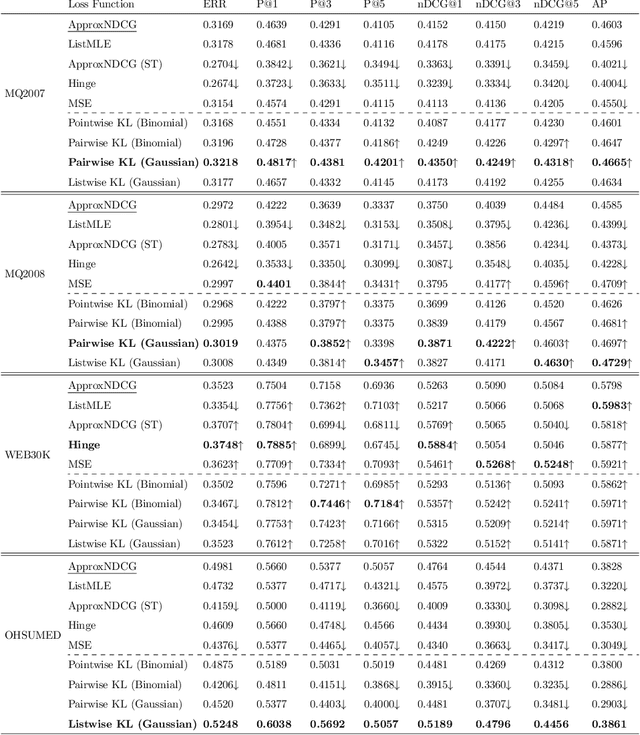
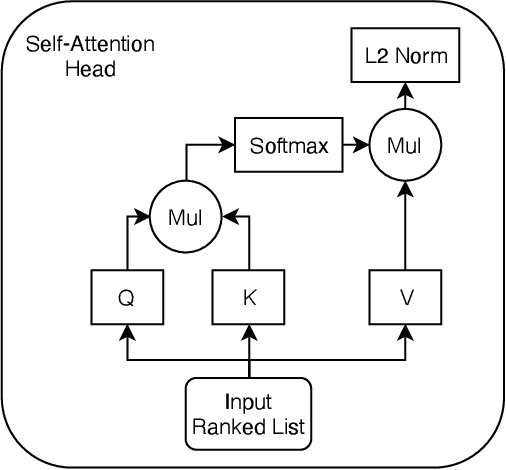
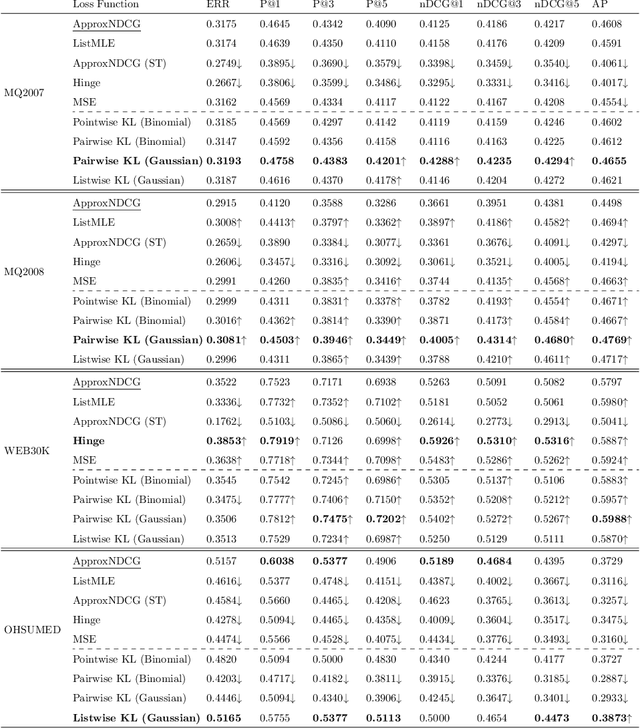
Learning to Rank (LETOR) algorithms are usually trained on annotated corpora where a single relevance label is assigned to each available document-topic pair. Within the Cranfield framework, relevance labels result from merging either multiple expertly curated or crowdsourced human assessments. In this paper, we explore how to train LETOR models with relevance judgments distributions (either real or synthetically generated) assigned to document-topic pairs instead of single-valued relevance labels. We propose five new probabilistic loss functions to deal with the higher expressive power provided by relevance judgments distributions and show how they can be applied both to neural and GBM architectures. Moreover, we show how training a LETOR model on a sampled version of the relevance judgments from certain probability distributions can improve its performance when relying either on traditional or probabilistic loss functions. Finally, we validate our hypothesis on real-world crowdsourced relevance judgments distributions. Overall, we observe that relying on relevance judgments distributions to train different LETOR models can boost their performance and even outperform strong baselines such as LambdaMART on several test collections.
Neural Feature Selection for Learning to Rank
Feb 22, 2021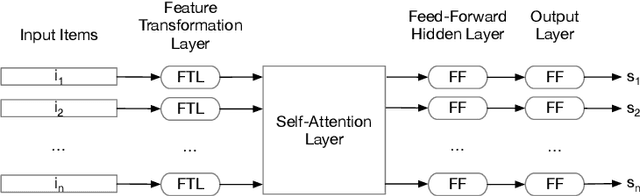
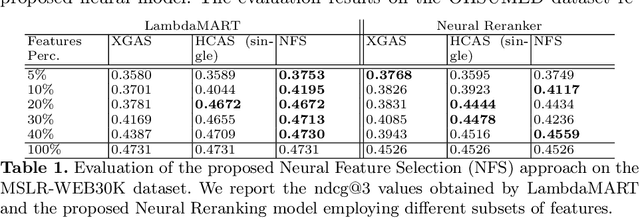
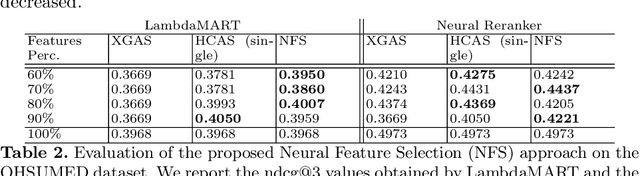
LEarning TO Rank (LETOR) is a research area in the field of Information Retrieval (IR) where machine learning models are employed to rank a set of items. In the past few years, neural LETOR approaches have become a competitive alternative to traditional ones like LambdaMART. However, neural architectures performance grew proportionally to their complexity and size. This can be an obstacle for their adoption in large-scale search systems where a model size impacts latency and update time. For this reason, we propose an architecture-agnostic approach based on a neural LETOR model to reduce the size of its input by up to 60% without affecting the system performance. This approach also allows to reduce a LETOR model complexity and, therefore, its training and inference time up to 50%.