 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into Dark Regions for Robust Shadow Detection
Feb 21, 2024



Shadow detection is a challenging task as it requires a comprehensive understanding of shadow characteristics and global/local illumination conditions. We observe from our experiment that state-of-the-art deep methods tend to have higher error rates in differentiating shadow pixels from non-shadow pixels in dark regions (ie, regions with low-intensity values). Our key insight to this problem is that existing methods typically learn discriminative shadow features from the whole image globally, covering the full range of intensity values, and may not learn the subtle differences between shadow and non-shadow pixels in dark regions. Hence, if we can design a model to focus on a narrower range of low-intensity regions, it may be able to learn better discriminative features for shadow detection. Inspired by this insight, we propose a novel shadow detection approach that first learns global contextual cues over the entire image and then zooms into the dark regions to learn local shadow representations. To this end, we formulate an effective dark-region recommendation (DRR) module to recommend regions of low-intensity values, and a novel dark-aware shadow analysis (DASA) module to learn dark-aware shadow features from the recommended dark regions. Extensive experiments show that the proposed method outperforms the state-of-the-art methods on three popular shadow detection datasets. Code is available at https://github.com/guanhuankang/ShadowDetection2021.git.
Recasting Regional Lighting for Shadow Removal
Feb 01, 2024



Removing shadows requires an understanding of both lighting conditions and object textures in a scene. Existing methods typically learn pixel-level color mappings between shadow and non-shadow images, in which the joint modeling of lighting and object textures is implicit and inadequate. We observe that in a shadow region, the degradation degree of object textures depends on the local illumination, while simply enhancing the local illumination cannot fully recover the attenuated textures. Based on this observation, we propose to condition the restoration of attenuated textures on the corrected local lighting in the shadow region. Specifically, We first design a shadow-aware decomposition network to estimate the illumination and reflectance layers of shadow regions explicitly. We then propose a novel bilateral correction network to recast the lighting of shadow regions in the illumination layer via a novel local lighting correction module, and to restore the textures conditioned on the corrected illumination layer via a novel illumination-guided texture restoration module. We further annotate pixel-wise shadow masks for the public SRD dataset, which originally contains only image pairs. Experiments on three benchmarks show that our method outperforms existing state-of-the-art shadow removal methods.
DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior
Dec 11, 20233D generation has raised great attention in recent years. With the success of text-to-image diffusion models, the 2D-lifting technique becomes a promising route to controllable 3D generation. However, these methods tend to present inconsistent geometry, which is also known as the Janus problem. We observe that the problem is caused mainly by two aspects, i.e., viewpoint bias in 2D diffusion models and overfitting of the optimization objective. To address it, we propose a two-stage 2D-lifting framework, namely DreamControl, which optimizes coarse NeRF scenes as 3D self-prior and then generates fine-grained objects with control-based score distillation. Specifically, adaptive viewpoint sampling and boundary integrity metric are proposed to ensure the consistency of generated priors. The priors are then regarded as input conditions to maintain reasonable geometries, in which conditional LoRA and weighted score are further proposed to optimize detailed textures. DreamControl can generate high-quality 3D content in terms of both geometry consistency and texture fidelity. Moreover, our control-based optimization guidance is applicable to more downstream tasks, including user-guided generation and 3D animation. The project page is available at https://github.com/tyhuang0428/DreamControl.
TextField3D: Towards Enhancing Open-Vocabulary 3D Generation with Noisy Text Fields
Sep 29, 2023



Recent works learn 3D representation explicitly under text-3D guidance. However, limited text-3D data restricts the vocabulary scale and text control of generations. Generators may easily fall into a stereotype concept for certain text prompts, thus losing open-vocabulary generation ability. To tackle this issue, we introduce a conditional 3D generative model, namely TextField3D. Specifically, rather than using the text prompts as input directly, we suggest to inject dynamic noise into the latent space of given text prompts, i.e., Noisy Text Fields (NTFs). In this way, limited 3D data can be mapped to the appropriate range of textual latent space that is expanded by NTFs. To this end, an NTFGen module is proposed to model general text latent code in noisy fields. Meanwhile, an NTFBind module is proposed to align view-invariant image latent code to noisy fields, further supporting image-conditional 3D generation. To guide the conditional generation in both geometry and texture, multi-modal discrimination is constructed with a text-3D discriminator and a text-2.5D discriminator. Compared to previous methods, TextField3D includes three merits: 1) large vocabulary, 2) text consistency, and 3) low latency. Extensive experiments demonstrate that our method achieves a potential open-vocabulary 3D generation capability.
Language-based Photo Color Adjustment for Graphic Designs
Aug 06, 2023Adjusting the photo color to associate with some design elements is an essential way for a graphic design to effectively deliver its message and make it aesthetically pleasing. However, existing tools and previous works face a dilemma between the ease of use and level of expressiveness. To this end, we introduce an interactive language-based approach for photo recoloring, which provides an intuitive system that can assist both experts and novices on graphic design. Given a graphic design containing a photo that needs to be recolored, our model can predict the source colors and the target regions, and then recolor the target regions with the source colors based on the given language-based instruction. The multi-granularity of the instruction allows diverse user intentions. The proposed novel task faces several unique challenges, including: 1) color accuracy for recoloring with exactly the same color from the target design element as specified by the user; 2) multi-granularity instructions for parsing instructions correctly to generate a specific result or multiple plausible ones; and 3) locality for recoloring in semantically meaningful local regions to preserve original image semantics. To address these challenges, we propose a model called LangRecol with two main components: the language-based source color prediction module and the semantic-palette-based photo recoloring module. We also introduce an approach for generating a synthetic graphic design dataset with instructions to enable model training. We evaluate our model via extensive experiments and user studies. We also discuss several practical applications, showing the effectiveness and practicality of our approach. Code and data for this paper are at: https://zhenwwang.github.io/langrecol.
Neural Preset for Color Style Transfer
Mar 24, 2023In this paper, we present a Neural Preset technique to address the limitations of existing color style transfer methods, including visual artifacts, vast memory requirement, and slow style switching speed. Our method is based on two core designs. First, we propose Deterministic Neural Color Mapping (DNCM) to consistently operate on each pixel via an image-adaptive color mapping matrix, avoiding artifacts and supporting high-resolution inputs with a small memory footprint. Second, we develop a two-stage pipeline by dividing the task into color normalization and stylization, which allows efficient style switching by extracting color styles as presets and reusing them on normalized input images. Due to the unavailability of pairwise datasets, we describe how to train Neural Preset via a self-supervised strategy. Various advantages of Neural Preset over existing methods are demonstrated through comprehensive evaluations. Notably, Neural Preset enables stable 4K color style transfer in real-time without artifacts. Besides, we show that our trained model can naturally support multiple applications without fine-tuning, including low-light image enhancement, underwater image correction, image dehazing, and image harmonization. Project page with demos: https://zhkkke.github.io/NeuralPreset .
Structure-Informed Shadow Removal Networks
Jan 09, 2023



Shadow removal is a fundamental task in computer vision. Despite the success, existing deep learning-based shadow removal methods still produce images with shadow remnants. These shadow remnants typically exist in homogeneous regions with low intensity values, making them untraceable in the existing image-to-image mapping paradigm. We observe from our experiments that shadows mainly degrade object colors at the image structure level (in which humans perceive object outlines filled with continuous colors). Hence, in this paper, we propose to remove shadows at the image structure level. Based on this idea, we propose a novel structure-informed shadow removal network (StructNet) to leverage the image structure information to address the shadow remnant problem. Specifically, StructNet first reconstructs the structure information of the input image without shadows and then uses the restored shadow-free structure prior to guiding the image-level shadow removal. StructNet contains two main novel modules: (1) a mask-guided shadow-free extraction (MSFE) module to extract image structural features in a non-shadow to shadow directional manner, and (2) a multi-scale feature & residual aggregation (MFRA) module to leverage the shadow-free structure information to regularize feature consistency. In addition, we also propose to extend StructNet to exploit multi-level structure information (MStructNet), to further boost the shadow removal performance with minimum computational overheads. Extensive experiments on three shadow removal benchmarks demonstrate that our method outperforms existing shadow removal methods, and our StructNet can be integrated with existing methods to boost their performances further.
Efficient Mirror Detection via Multi-level Heterogeneous Learning
Nov 28, 2022



We present HetNet (Multi-level \textbf{Het}erogeneous \textbf{Net}work), a highly efficient mirror detection network. Current mirror detection methods focus more on performance than efficiency, limiting the real-time applications (such as drones). Their lack of efficiency is aroused by the common design of adopting homogeneous modules at different levels, which ignores the difference between different levels of features. In contrast, HetNet detects potential mirror regions initially through low-level understandings (\textit{e.g.}, intensity contrasts) and then combines with high-level understandings (contextual discontinuity for instance) to finalize the predictions. To perform accurate yet efficient mirror detection, HetNet follows an effective architecture that obtains specific information at different stages to detect mirrors. We further propose a multi-orientation intensity-based contrasted module (MIC) and a reflection semantic logical module (RSL), equipped on HetNet, to predict potential mirror regions by low-level understandings and analyze semantic logic in scenarios by high-level understandings, respectively. Compared to the state-of-the-art method, HetNet runs 664$\%$ faster and draws an average performance gain of 8.9$\%$ on MAE, 3.1$\%$ on IoU, and 2.0$\%$ on F-measure on two mirror detection benchmarks.
CLIP2Point: Transfer CLIP to Point Cloud Classification with Image-Depth Pre-training
Oct 03, 2022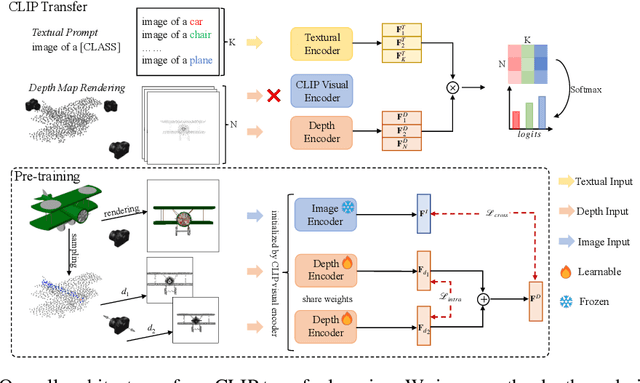

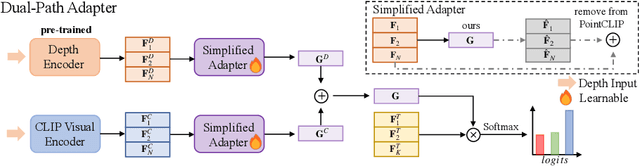

Pre-training across 3D vision and language remains under development because of limited training data. Recent works attempt to transfer vision-language pre-training models to 3D vision. PointCLIP converts point cloud data to multi-view depth maps, adopting CLIP for shape classification. However, its performance is restricted by the domain gap between rendered depth maps and images, as well as the diversity of depth distributions. To address this issue, we propose CLIP2Point, an image-depth pre-training method by contrastive learning to transfer CLIP to the 3D domain, and adapt it to point cloud classification. We introduce a new depth rendering setting that forms a better visual effect, and then render 52,460 pairs of images and depth maps from ShapeNet for pre-training. The pre-training scheme of CLIP2Point combines cross-modality learning to enforce the depth features for capturing expressive visual and textual features and intra-modality learning to enhance the invariance of depth aggregation. Additionally, we propose a novel Dual-Path Adapter (DPA) module, i.e., a dual-path structure with simplified adapters for few-shot learning. The dual-path structure allows the joint use of CLIP and CLIP2Point, and the simplified adapter can well fit few-shot tasks without post-search. Experimental results show that CLIP2Point is effective in transferring CLIP knowledge to 3D vision. Our CLIP2Point outperforms PointCLIP and other self-supervised 3D networks, achieving state-of-the-art results on zero-shot and few-shot classification.
Large-Field Contextual Feature Learning for Glass Detection
Sep 10, 2022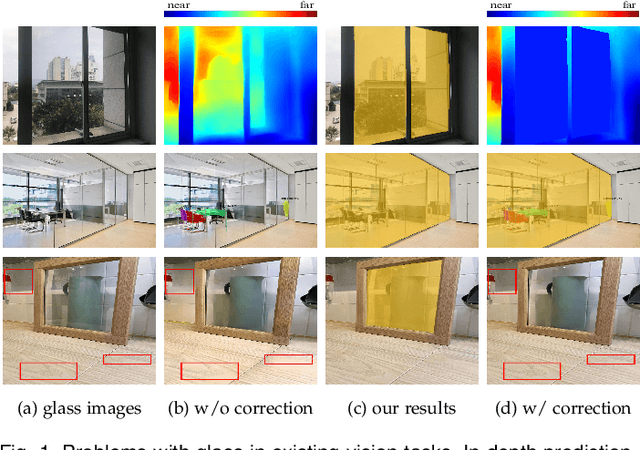
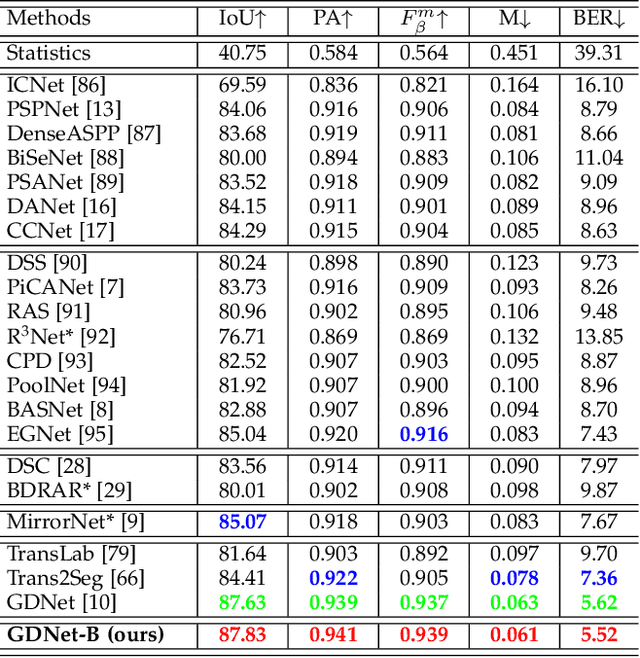

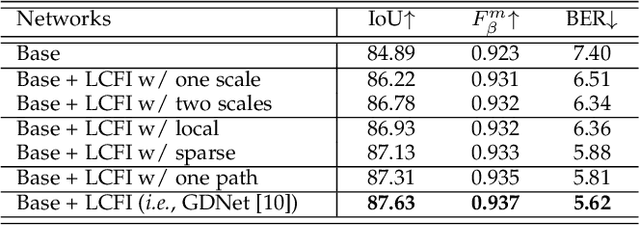
Glass is very common in our daily life. Existing computer vision systems neglect it and thus may have severe consequences, e.g., a robot may crash into a glass wall. However, sensing the presence of glass is not straightforward. The key challenge is that arbitrary objects/scenes can appear behind the glass. In this paper, we propose an important problem of detecting glass surfaces from a single RGB image. To address this problem, we construct the first large-scale glass detection dataset (GDD) and propose a novel glass detection network, called GDNet-B, which explores abundant contextual cues in a large field-of-view via a novel large-field contextual feature integration (LCFI) module and integrates both high-level and low-level boundary features with a boundary feature enhancement (BFE) module. Extensive experiments demonstrate that our GDNet-B achieves satisfying glass detection results on the images within and beyond the GDD testing set. We further validate the effectiveness and generalization capability of our proposed GDNet-B by applying it to other vision tasks, including mirror segmentation and salient object detection. Finally, we show the potential applications of glass detection and discuss possible future research directions.