 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastMask: Contrastive Learning to Segment Every Thing
Mar 24, 2022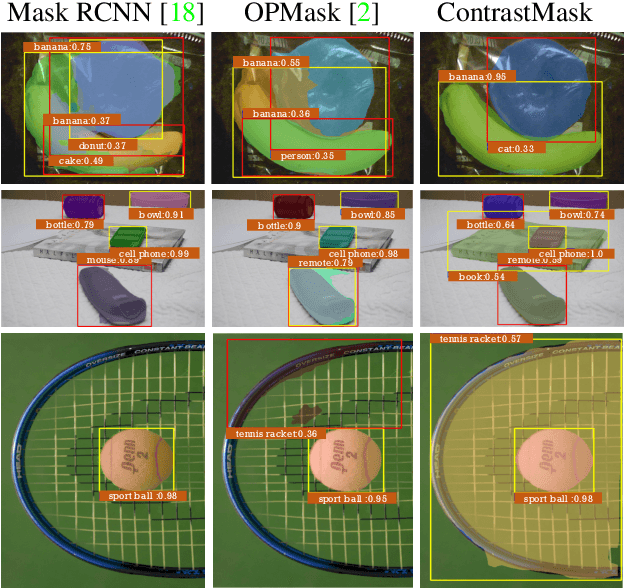
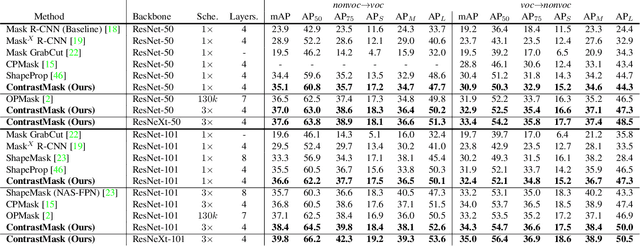
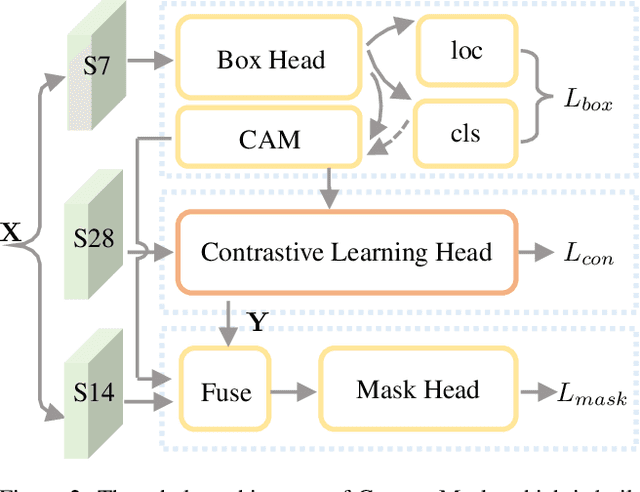
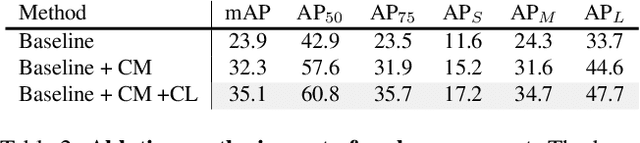
Partially-supervised instance segmentation is a task which requests segmenting objects from novel unseen categories via learning on limited seen categories with annotated masks thus eliminating demands of heavy annotation burden. The key to addressing this task is to build an effective class-agnostic mask segmentation model. Unlike previous methods that learn such models only on seen categories, in this paper, we propose a new method, named ContrastMask, which learns a mask segmentation model on both seen and unseen categories under a unified pixel-level contrastive learning framework. In this framework, annotated masks of seen categories and pseudo masks of unseen categories serve as a prior for contrastive learning, where features from the mask regions (foreground) are pulled together, and are contrasted against those from the background, and vice versa. Through this framework, feature discrimination between foreground and background is largely improved, facilitating learning of the class-agnostic mask segmentation model. Exhaustive experiments on the COCO dataset demonstrate the superiority of our method, which outperforms previous state-of-the-arts.
Adaptive Feature Alignment for Adversarial Training
Jun 16, 2021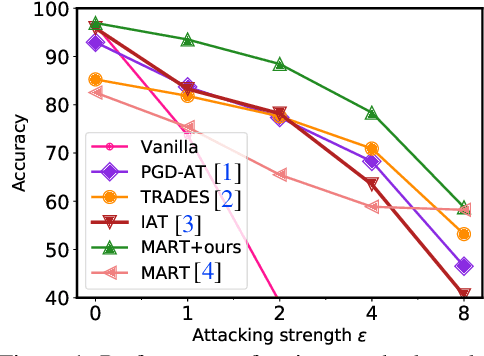
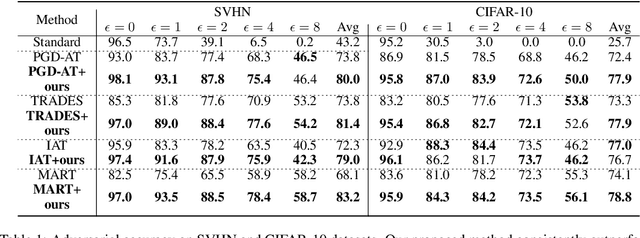
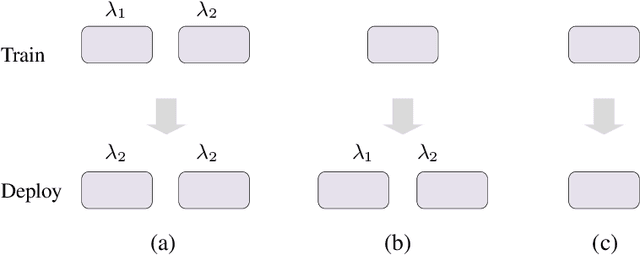
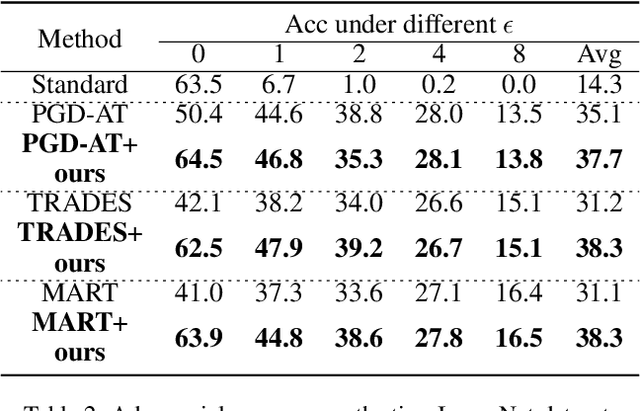
Recent studies reveal that Convolutional Neural Networks (CNNs) are typically vulnerable to adversarial attacks, which pose a threat to security-sensitive applications. Many adversarial defense methods improve robustness at the cost of accuracy, raising the contradiction between standard and adversarial accuracies. In this paper, we observe an interesting phenomenon that feature statistics change monotonically and smoothly w.r.t the rising of attacking strength. Based on this observation, we propose the adaptive feature alignment (AFA) to generate features of arbitrary attacking strengths. Our method is trained to automatically align features of arbitrary attacking strength. This is done by predicting a fusing weight in a dual-BN architecture. Unlike previous works that need to either retrain the model or manually tune a hyper-parameters for different attacking strengths, our method can deal with arbitrary attacking strengths with a single model without introducing any hyper-parameter. Importantly, our method improves the model robustness against adversarial samples without incurring much loss in standard accuracy. Experiments on CIFAR-10, SVHN, and tiny-ImageNet datasets demonstrate that our method outperforms the state-of-the-art under a wide range of attacking strengths.
SDD-FIQA: Unsupervised Face Image Quality Assessment with Similarity Distribution Distance
Mar 10, 2021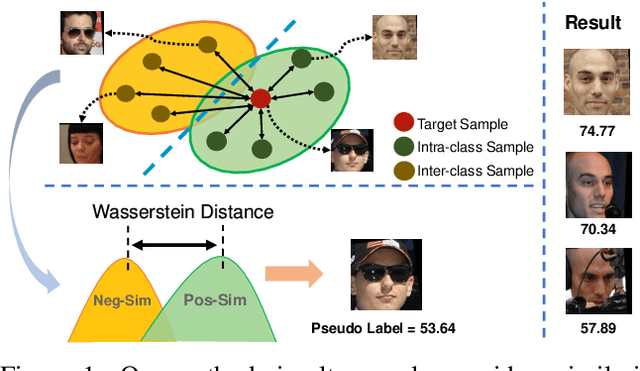
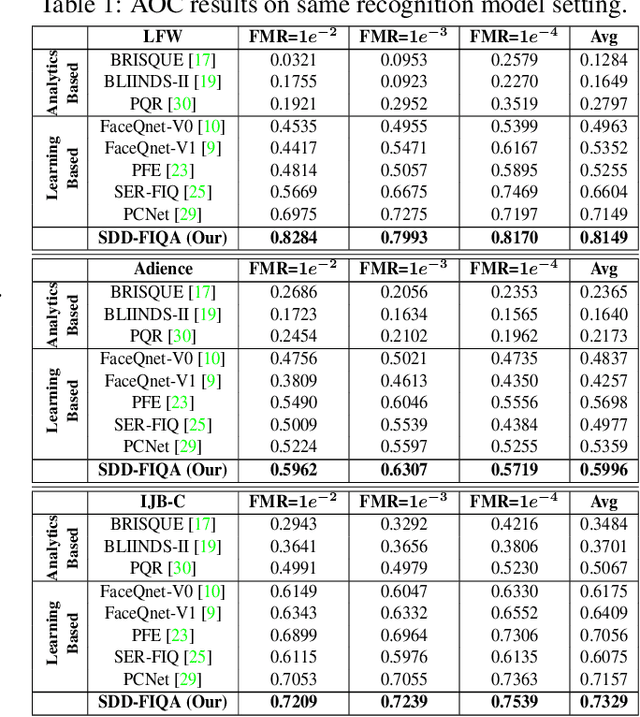
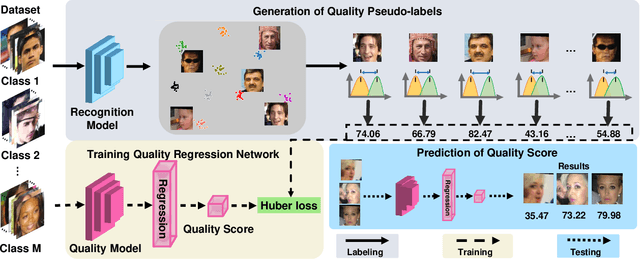
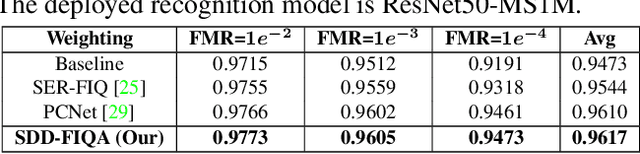
In recent years, Face Image Quality Assessment (FIQA) has become an indispensable part of the face recognition system to guarantee the stability and reliability of recognition performance in an unconstrained scenario. For this purpose, the FIQA method should consider both the intrinsic property and the recognizability of the face image. Most previous works aim to estimate the sample-wise embedding uncertainty or pair-wise similarity as the quality score, which only considers the information from partial intra-class. However, these methods ignore the valuable information from the inter-class, which is for estimating to the recognizability of face image. In this work, we argue that a high-quality face image should be similar to its intra-class samples and dissimilar to its inter-class samples. Thus, we propose a novel unsupervised FIQA method that incorporates Similarity Distribution Distance for Face Image Quality Assessment (SDD-FIQA). Our method generates quality pseudo-labels by calculating the Wasserstein Distance (WD) between the intra-class similarity distributions and inter-class similarity distributions. With these quality pseudo-labels, we are capable of training a regression network for quality prediction. Extensive experiments on benchmark datasets demonstrate that the proposed SDD-FIQA surpasses the state-of-the-arts by an impressive margin. Meanwhile, our method shows good generalization across different recognition systems.
Towards Palmprint Verification On Smartphones
Mar 30, 2020



With the rapid development of mobile devices, smartphones have gradually become an indispensable part of people's lives. Meanwhile, biometric authentication has been corroborated to be an effective method for establishing a person's identity with high confidence. Hence, recently, biometric technologies for smartphones have also become increasingly sophisticated and popular. But it is noteworthy that the application potential of palmprints for smartphones is seriously underestimated. Studies in the past two decades have shown that palmprints have outstanding merits in uniqueness and permanence, and have high user acceptance. However, currently, studies specializing in palmprint verification for smartphones are still quite sporadic, especially when compared to face- or fingerprint-oriented ones. In this paper, aiming to fill the aforementioned research gap, we conducted a thorough study of palmprint verification on smartphones and our contributions are twofold. First, to facilitate the study of palmprint verification on smartphones, we established an annotated palmprint dataset named MPD, which was collected by multi-brand smartphones in two separate sessions with various backgrounds and illumination conditions. As the largest dataset in this field, MPD contains 16,000 palm images collected from 200 subjects. Second, we built a DCNN-based palmprint verification system named DeepMPV+ for smartphones. In DeepMPV+, two key steps, ROI extraction and ROI matching, are both formulated as learning problems and then solved naturally by modern DCNN models. The efficiency and efficacy of DeepMPV+ have been corroborated by extensive experiments. To make our results fully reproducible, the labeled dataset and the relevant source codes have been made publicly available at https://cslinzhang.github.io/MobilePalmPrint/.
A Classification Supervised Auto-Encoder Based on Predefined Evenly-Distributed Class Centroids
Feb 27, 2019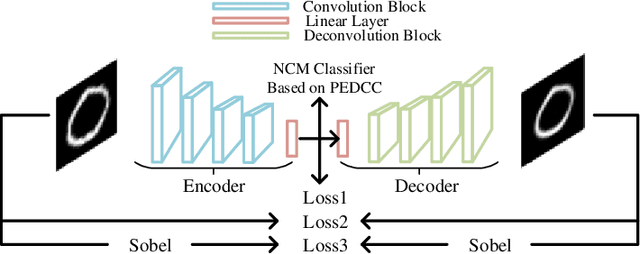
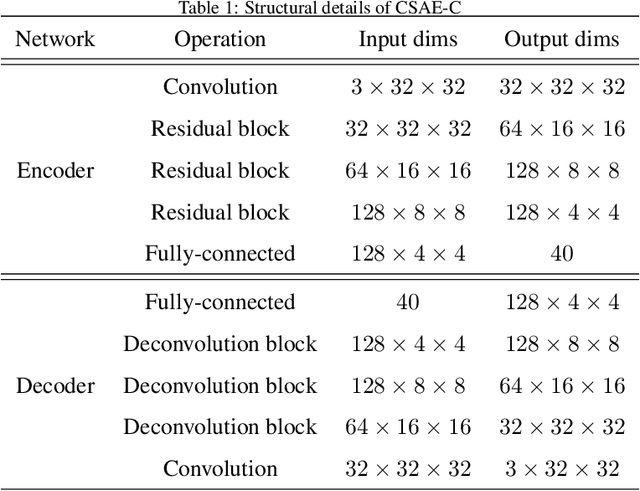
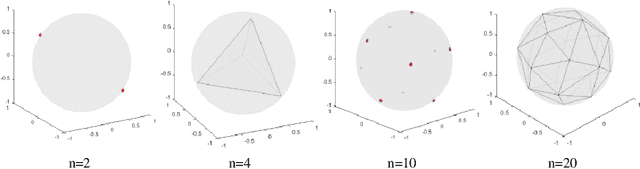
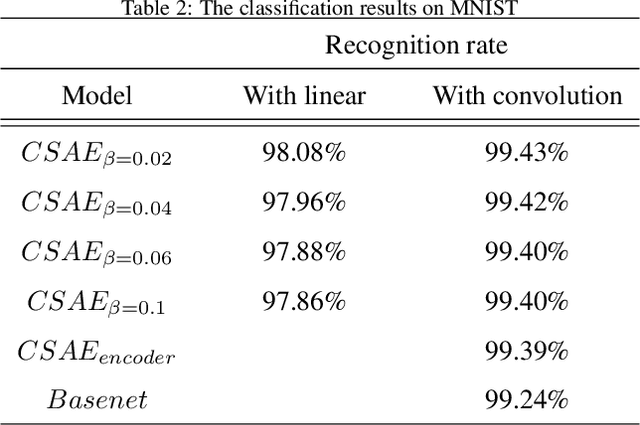
Classic Autoencoders and variational autoencoders are used to learn complex data distributions, that are built on standard function approximators, such as neural networks, which can be trained by stochastic gradient descent methods. Especially, VAE has shown promise on a lot of complex task. In this paper, a new autoencoder model - classification supervised autoencoder (CSAE) based on predefined evenly-distributed class centroids (PEDCC) is proposed. To carry out the supervised learning for autoencoder, we use PEDCC of latent variables to train the network to ensure the maximization of inter-class distance and the minimization of inner-class distance. Instead of learning mean/variance of latent variables distribution and taking reparameterization of VAE, latent variables of CSAE are directly used to classify and as input of decoder. In addition, a new loss function is proposed to combine the loss function of classification, the loss function of image codec error and the loss function for enhancing subjective quality of decoded image. Based on the basic structure of the universal autoencoder, we realized the comprehensive optimal results of encoding, decoding and classification, and good model generalization performance at the same time. Theoretical advantages are reflected in experimental results.
HENet:A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage
Mar 15, 2018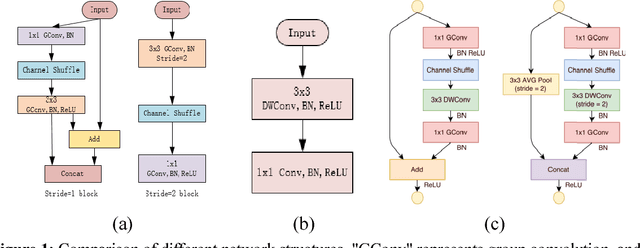
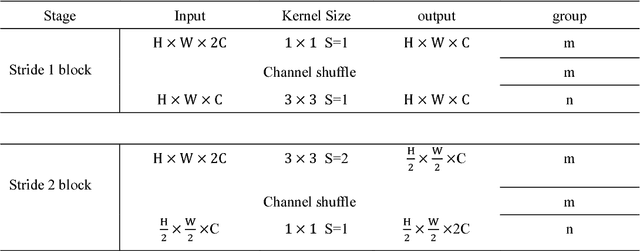
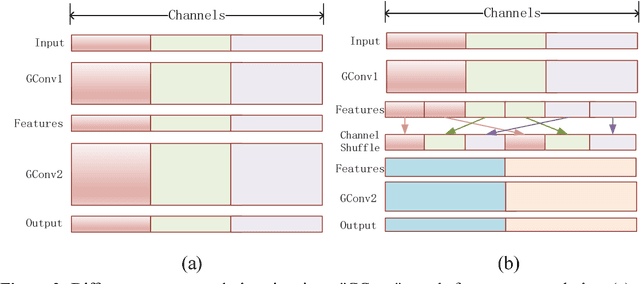
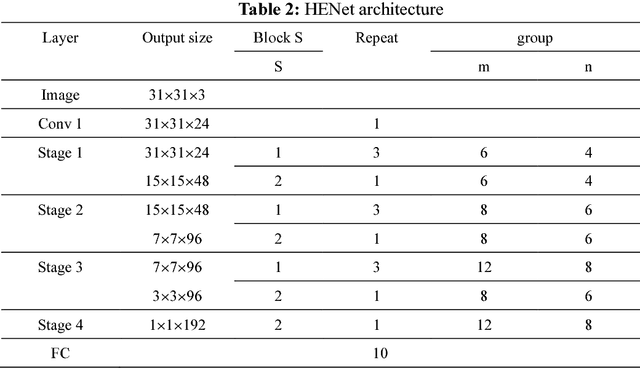
In order to enhance the real-time performance of convolutional neural networks(CNNs), more and more researchers are focusing on improving the efficiency of CNN. Based on the analysis of some CNN architectures, such as ResNet, DenseNet, ShuffleNet and so on, we combined their advantages and proposed a very efficient model called Highly Efficient Networks(HENet). The new architecture uses an unusual way to combine group convolution and channel shuffle which was mentioned in ShuffleNet. Inspired by ResNet and DenseNet, we also proposed a new way to use element-wise addition and concatenation connection with each block. In order to make greater use of feature maps, pooling operations are removed from HENet. The experiments show that our model's efficiency is more than 1 times higher than ShuffleNet on many open source datasets, such as CIFAR-10/100 and SVHN.