 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks
Jun 17, 2022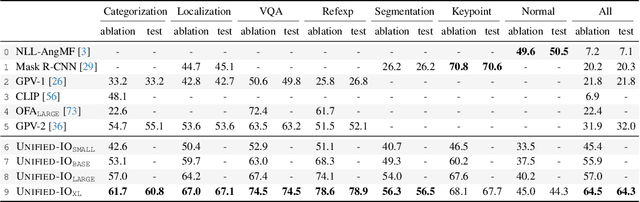
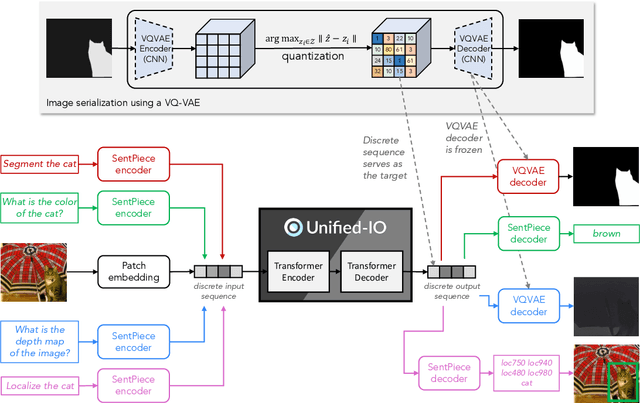
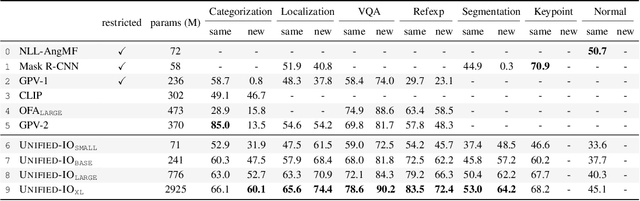
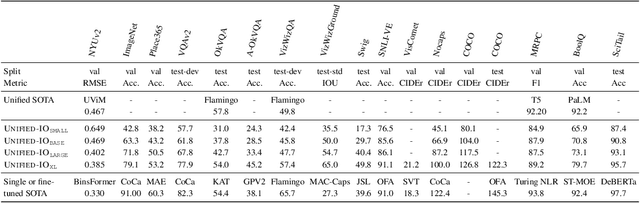
We propose Unified-IO, a model that performs a large variety of AI tasks spanning classical computer vision tasks, including pose estimation, object detection, depth estimation and image generation, vision-and-language tasks such as region captioning and referring expression comprehension, to natural language processing tasks such as question answering and paraphrasing. Developing a single unified model for such a large variety of tasks poses unique challenges due to the heterogeneous inputs and outputs pertaining to each task, including RGB images, per-pixel maps, binary masks, bounding boxes, and language. We achieve this unification by homogenizing every supported input and output into a sequence of discrete vocabulary tokens. This common representation across all tasks allows us to train a single transformer-based architecture, jointly on over 80 diverse datasets in the vision and language fields. Unified-IO is the first model capable of performing all 7 tasks on the GRIT benchmark and produces strong results across 16 diverse benchmarks like NYUv2-Depth, ImageNet, VQA2.0, OK-VQA, Swig, VizWizGround, BoolQ, and SciTail, with no task or benchmark specific fine-tuning. Demos for Unified-IO are available at https://unified-io.allenai.org.
What do navigation agents learn about their environment?
Jun 17, 2022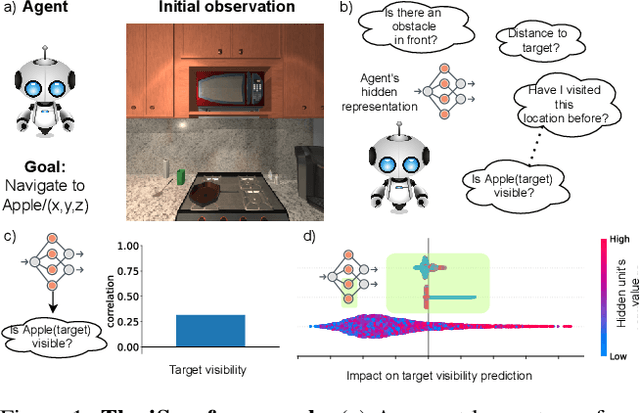
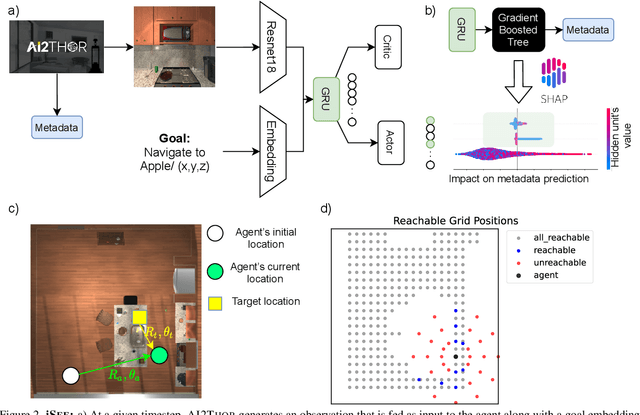
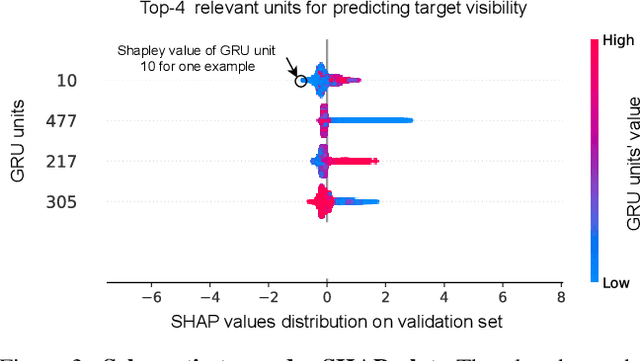
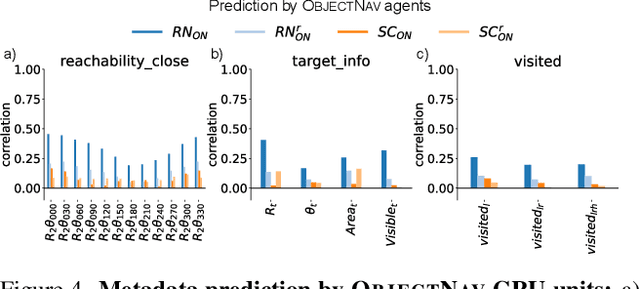
Today's state of the art visual navigation agents typically consist of large deep learning models trained end to end. Such models offer little to no interpretability about the learned skills or the actions of the agent taken in response to its environment. While past works have explored interpreting deep learning models, little attention has been devoted to interpreting embodied AI systems, which often involve reasoning about the structure of the environment, target characteristics and the outcome of one's actions. In this paper, we introduce the Interpretability System for Embodied agEnts (iSEE) for Point Goal and Object Goal navigation agents. We use iSEE to probe the dynamic representations produced by these agents for the presence of information about the agent as well as the environment. We demonstrate interesting insights about navigation agents using iSEE, including the ability to encode reachable locations (to avoid obstacles), visibility of the target, progress from the initial spawn location as well as the dramatic effect on the behaviors of agents when we mask out critical individual neurons. The code is available at: https://github.com/allenai/iSEE
ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
Jun 14, 2022

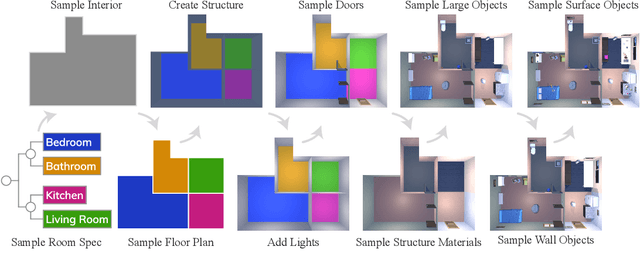
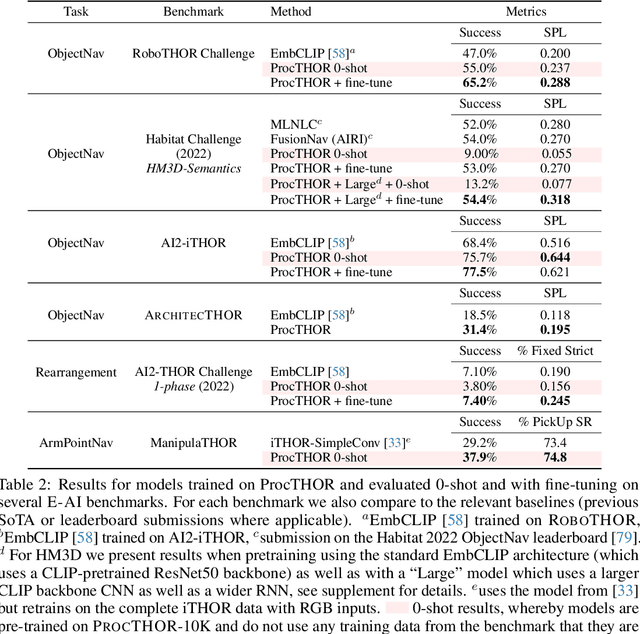
Massive datasets and high-capacity models have driven many recent advancements in computer vision and natural language understanding. This work presents a platform to enable similar success stories in Embodied AI. We propose ProcTHOR, a framework for procedural generation of Embodied AI environments. ProcTHOR enables us to sample arbitrarily large datasets of diverse, interactive, customizable, and performant virtual environments to train and evaluate embodied agents across navigation, interaction, and manipulation tasks. We demonstrate the power and potential of ProcTHOR via a sample of 10,000 generated houses and a simple neural model. Models trained using only RGB images on ProcTHOR, with no explicit mapping and no human task supervision produce state-of-the-art results across 6 embodied AI benchmarks for navigation, rearrangement, and arm manipulation, including the presently running Habitat 2022, AI2-THOR Rearrangement 2022, and RoboTHOR challenges. We also demonstrate strong 0-shot results on these benchmarks, via pre-training on ProcTHOR with no fine-tuning on the downstream benchmark, often beating previous state-of-the-art systems that access the downstream training data.
A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge
Jun 03, 2022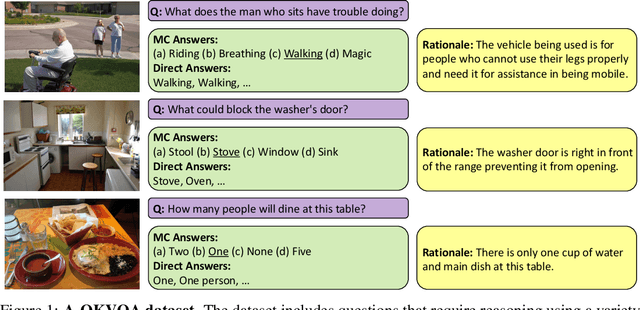

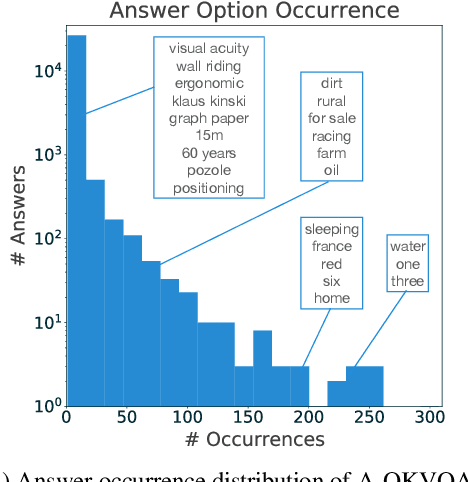
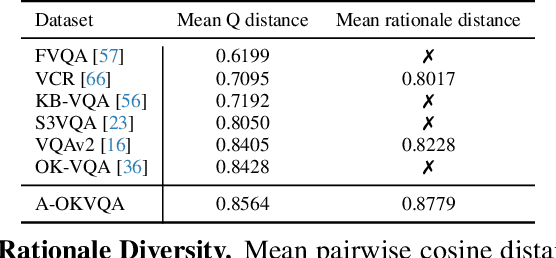
The Visual Question Answering (VQA) task aspires to provide a meaningful testbed for the development of AI models that can jointly reason over visual and natural language inputs. Despite a proliferation of VQA datasets, this goal is hindered by a set of common limitations. These include a reliance on relatively simplistic questions that are repetitive in both concepts and linguistic structure, little world knowledge needed outside of the paired image, and limited reasoning required to arrive at the correct answer. We introduce A-OKVQA, a crowdsourced dataset composed of a diverse set of about 25K questions requiring a broad base of commonsense and world knowledge to answer. In contrast to the existing knowledge-based VQA datasets, the questions generally cannot be answered by simply querying a knowledge base, and instead require some form of commonsense reasoning about the scene depicted in the image. We demonstrate the potential of this new dataset through a detailed analysis of its contents and baseline performance measurements over a variety of state-of-the-art vision-language models. Project page: http://a-okvqa.allenai.org/
Continuous Scene Representations for Embodied AI
Mar 31, 2022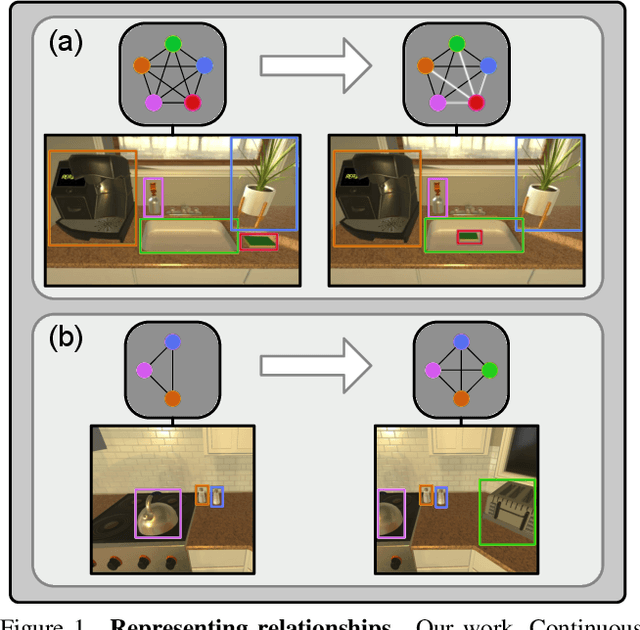
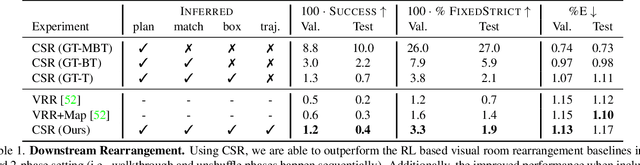
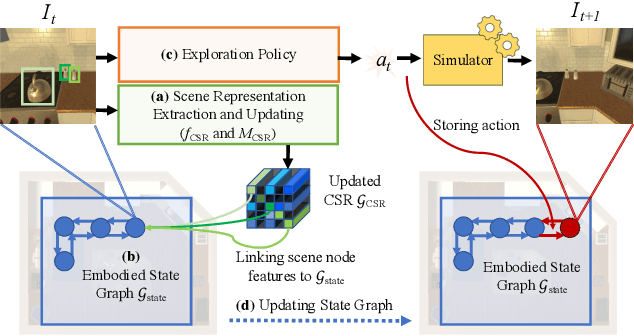
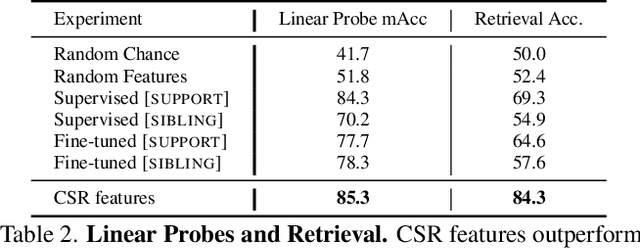
We propose Continuous Scene Representations (CSR), a scene representation constructed by an embodied agent navigating within a space, where objects and their relationships are modeled by continuous valued embeddings. Our method captures feature relationships between objects, composes them into a graph structure on-the-fly, and situates an embodied agent within the representation. Our key insight is to embed pair-wise relationships between objects in a latent space. This allows for a richer representation compared to discrete relations (e.g., [support], [next-to]) commonly used for building scene representations. CSR can track objects as the agent moves in a scene, update the representation accordingly, and detect changes in room configurations. Using CSR, we outperform state-of-the-art approaches for the challenging downstream task of visual room rearrangement, without any task specific training. Moreover, we show the learned embeddings capture salient spatial details of the scene and show applicability to real world data. A summery video and code is available at https://prior.allenai.org/projects/csr.
Object Manipulation via Visual Target Localization
Mar 15, 2022
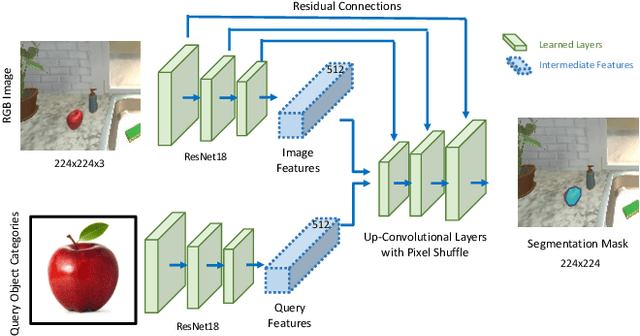
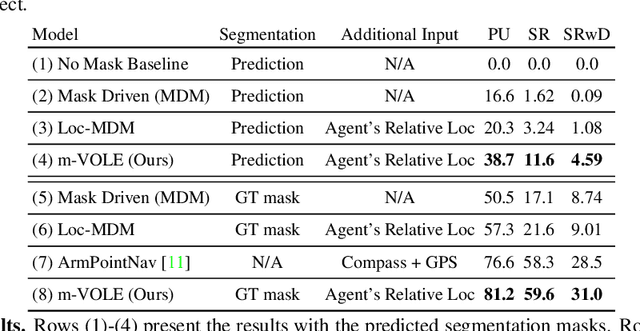
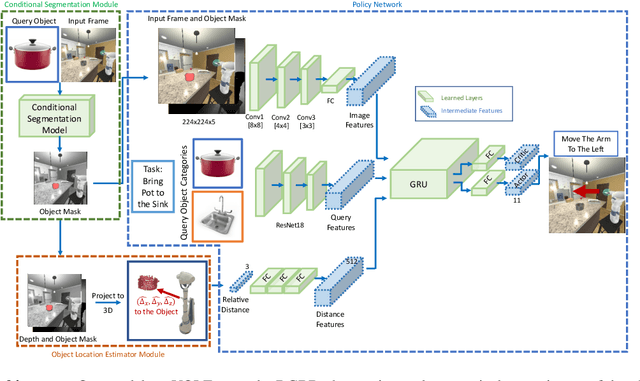
Object manipulation is a critical skill required for Embodied AI agents interacting with the world around them. Training agents to manipulate objects, poses many challenges. These include occlusion of the target object by the agent's arm, noisy object detection and localization, and the target frequently going out of view as the agent moves around in the scene. We propose Manipulation via Visual Object Location Estimation (m-VOLE), an approach that explores the environment in search for target objects, computes their 3D coordinates once they are located, and then continues to estimate their 3D locations even when the objects are not visible, thus robustly aiding the task of manipulating these objects throughout the episode. Our evaluations show a massive 3x improvement in success rate over a model that has access to the same sensory suite but is trained without the object location estimator, and our analysis shows that our agent is robust to noise in depth perception and agent localization. Importantly, our proposed approach relaxes several assumptions about idealized localization and perception that are commonly employed by recent works in embodied AI -- an important step towards training agents for object manipulation in the real world.
ASC me to Do Anything: Multi-task Training for Embodied AI
Feb 14, 2022



Embodied AI has seen steady progress across a diverse set of independent tasks. While these varied tasks have different end goals, the basic skills required to complete them successfully overlap significantly. In this paper, our goal is to leverage these shared skills to learn to perform multiple tasks jointly. We propose Atomic Skill Completion (ASC), an approach for multi-task training for Embodied AI, where a set of atomic skills shared across multiple tasks are composed together to perform the tasks. The key to the success of this approach is a pre-training scheme that decouples learning of the skills from the high-level tasks making joint training effective. We use ASC to train agents within the AI2-THOR environment to perform four interactive tasks jointly and find it to be remarkably effective. In a multi-task setting, ASC improves success rates by a factor of 2x on Seen scenes and 4x on Unseen scenes compared to no pre-training. Importantly, ASC enables us to train a multi-task agent that has a 52% higher Success Rate than training 4 independent single task agents. Finally, our hierarchical agents are more interpretable than traditional black-box architectures.
Interactron: Embodied Adaptive Object Detection
Feb 01, 2022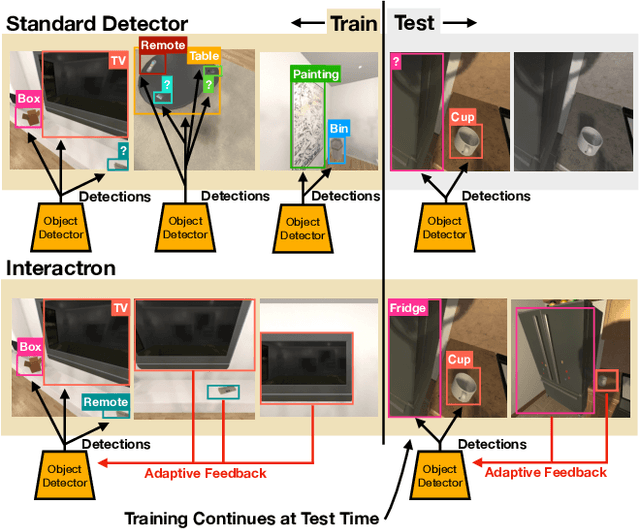

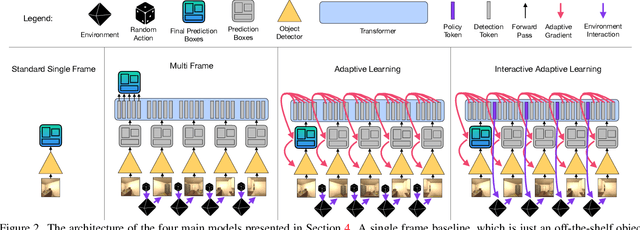
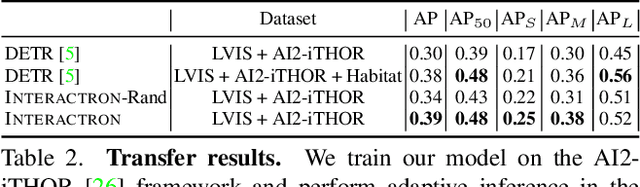
Over the years various methods have been proposed for the problem of object detection. Recently, we have witnessed great strides in this domain owing to the emergence of powerful deep neural networks. However, there are typically two main assumptions common among these approaches. First, the model is trained on a fixed training set and is evaluated on a pre-recorded test set. Second, the model is kept frozen after the training phase, so no further updates are performed after the training is finished. These two assumptions limit the applicability of these methods to real-world settings. In this paper, we propose Interactron, a method for adaptive object detection in an interactive setting, where the goal is to perform object detection in images observed by an embodied agent navigating in different environments. Our idea is to continue training during inference and adapt the model at test time without any explicit supervision via interacting with the environment. Our adaptive object detection model provides a 11.8 point improvement in AP (and 19.1 points in AP50) over DETR, a recent, high-performance object detector. Moreover, we show that our object detection model adapts to environments with completely different appearance characteristics, and its performance is on par with a model trained with full supervision for those environments.
Simple but Effective: CLIP Embeddings for Embodied AI
Nov 18, 2021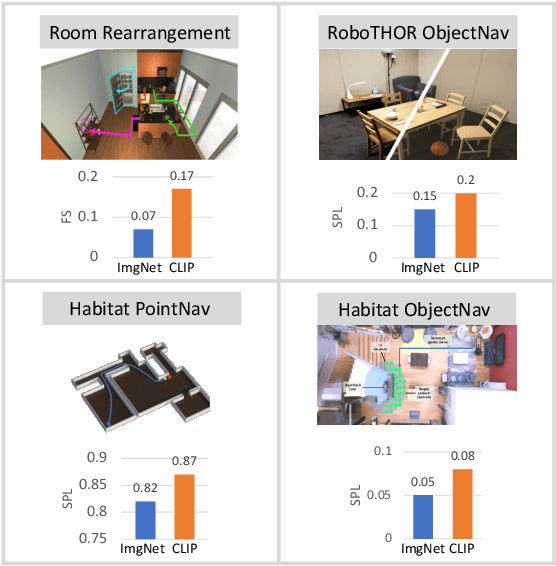
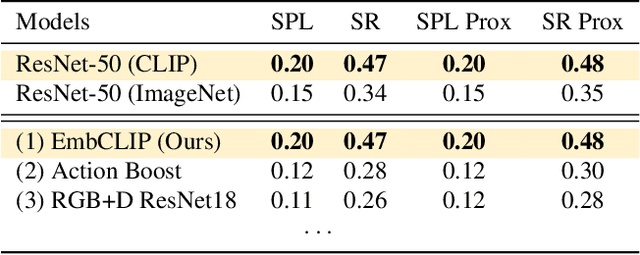
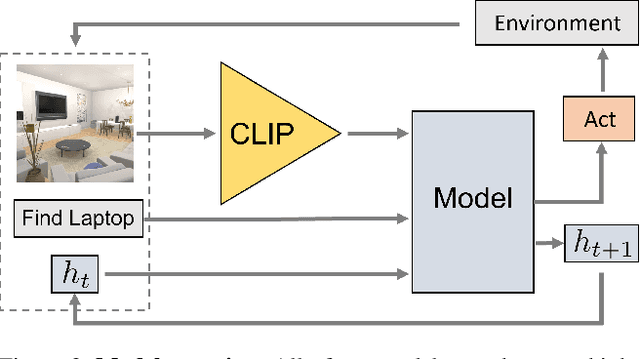
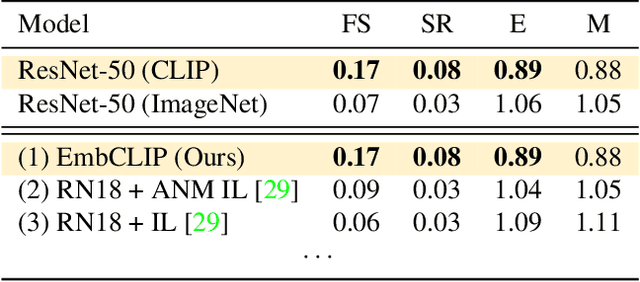
Contrastive language image pretraining (CLIP) encoders have been shown to be beneficial for a range of visual tasks from classification and detection to captioning and image manipulation. We investigate the effectiveness of CLIP visual backbones for embodied AI tasks. We build incredibly simple baselines, named EmbCLIP, with no task specific architectures, inductive biases (such as the use of semantic maps), auxiliary tasks during training, or depth maps -- yet we find that our improved baselines perform very well across a range of tasks and simulators. EmbCLIP tops the RoboTHOR ObjectNav leaderboard by a huge margin of 20 pts (Success Rate). It tops the iTHOR 1-Phase Rearrangement leaderboard, beating the next best submission, which employs Active Neural Mapping, and more than doubling the % Fixed Strict metric (0.08 to 0.17). It also beats the winners of the 2021 Habitat ObjectNav Challenge, which employ auxiliary tasks, depth maps, and human demonstrations, and those of the 2019 Habitat PointNav Challenge. We evaluate the ability of CLIP's visual representations at capturing semantic information about input observations -- primitives that are useful for navigation-heavy embodied tasks -- and find that CLIP's representations encode these primitives more effectively than ImageNet-pretrained backbones. Finally, we extend one of our baselines, producing an agent capable of zero-shot object navigation that can navigate to objects that were not used as targets during training.
CORA: Benchmarks, Baselines, and Metrics as a Platform for Continual Reinforcement Learning Agents
Oct 19, 2021Progress in continual reinforcement learning has been limited due to several barriers to entry: missing code, high compute requirements, and a lack of suitable benchmarks. In this work, we present CORA, a platform for Continual Reinforcement Learning Agents that provides benchmarks, baselines, and metrics in a single code package. The benchmarks we provide are designed to evaluate different aspects of the continual RL challenge, such as catastrophic forgetting, plasticity, ability to generalize, and sample-efficient learning. Three of the benchmarks utilize video game environments (Atari, Procgen, NetHack). The fourth benchmark, CHORES, consists of four different task sequences in a visually realistic home simulator, drawn from a diverse set of task and scene parameters. To compare continual RL methods on these benchmarks, we prepare three metrics in CORA: continual evaluation, forgetting, and zero-shot forward transfer. Finally, CORA includes a set of performant, open-source baselines of existing algorithms for researchers to use and expand on. We release CORA and hope that the continual RL community can benefit from our contributions, to accelerate the development of new continual RL algorithms.