 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human Labels to Literature: Semi-Supervised Learning of NMR Chemical Shifts at Scale
Jan 26, 2026Accurate prediction of nuclear magnetic resonance (NMR) chemical shifts is fundamental to spectral analysis and molecular structure elucidation, yet existing machine learning methods rely on limited, labor-intensive atom-assigned datasets. We propose a semi-supervised framework that learns NMR chemical shifts from millions of literature-extracted spectra without explicit atom-level assignments, integrating a small amount of labeled data with large-scale unassigned spectra. We formulate chemical shift prediction from literature spectra as a permutation-invariant set supervision problem, and show that under commonly satisfied conditions on the loss function, optimal bipartite matching reduces to a sorting-based loss, enabling stable large-scale semi-supervised training beyond traditional curated datasets. Our models achieve substantially improved accuracy and robustness over state-of-the-art methods and exhibit stronger generalization on significantly larger and more diverse molecular datasets. Moreover, by incorporating solvent information at scale, our approach captures systematic solvent effects across common NMR solvents for the first time. Overall, our results demonstrate that large-scale unlabeled spectra mined from the literature can serve as a practical and effective data source for training NMR shift models, suggesting a broader role of literature-derived, weakly structured data in data-centric AI for science.
Improving Speech Enhancement by Integrating Inter-Channel and Band Features with Dual-branch Conformer
Jul 11, 2024



Recent speech enhancement methods based on convolutional neural networks (CNNs) and transformer have been demonstrated to efficaciously capture time-frequency (T-F) information on spectrogram. However, the correlation of each channels of speech features is failed to explore. Theoretically, each channel map of speech features obtained by different convolution kernels contains information with different scales demonstrating strong correlations. To fill this gap, we propose a novel dual-branch architecture named channel-aware dual-branch conformer (CADB-Conformer), which effectively explores the long range time and frequency correlations among different channels, respectively, to extract channel relation aware time-frequency information. Ablation studies conducted on DNS-Challenge 2020 dataset demonstrate the importance of channel feature leveraging while showing the significance of channel relation aware T-F information for speech enhancement. Extensive experiments also show that the proposed model achieves superior performance than recent methods with an attractive computational costs.
PRICE: A Pretrained Model for Cross-Database Cardinality Estimation
Jun 03, 2024



Cardinality estimation (CardEst) is essential for optimizing query execution plans. Recent ML-based CardEst methods achieve high accuracy but face deployment challenges due to high preparation costs and lack of transferability across databases. In this paper, we propose PRICE, a PRetrained multI-table CardEst model, which addresses these limitations. PRICE takes low-level but transferable features w.r.t. data distributions and query information and elegantly applies self-attention models to learn meta-knowledge to compute cardinality in any database. It is generally applicable to any unseen new database to attain high estimation accuracy, while its preparation cost is as little as the basic one-dimensional histogram-based CardEst methods. Moreover, PRICE can be finetuned to further enhance its performance on any specific database. We pretrained PRICE using 30 diverse datasets, completing the process in about 5 hours with a resulting model size of only about 40MB. Evaluations show that PRICE consistently outperforms existing methods, achieving the highest estimation accuracy on several unseen databases and generating faster execution plans with lower overhead. After finetuning with a small volume of databasespecific queries, PRICE could even find plans very close to the optimal ones. Meanwhile, PRICE is generally applicable to different settings such as data updates, data scaling, and query workload shifts. We have made all of our data and codes publicly available at https://github.com/StCarmen/PRICE.
UniDM: A Unified Framework for Data Manipulation with Large Language Models
May 10, 2024



Designing effective data manipulation methods is a long standing problem in data lakes. Traditional methods, which rely on rules or machine learning models, require extensive human efforts on training data collection and tuning models. Recent methods apply Large Language Models (LLMs) to resolve multiple data manipulation tasks. They exhibit bright benefits in terms of performance but still require customized designs to fit each specific task. This is very costly and can not catch up with the requirements of big data lake platforms. In this paper, inspired by the cross-task generality of LLMs on NLP tasks, we pave the first step to design an automatic and general solution to tackle with data manipulation tasks. We propose UniDM, a unified framework which establishes a new paradigm to process data manipulation tasks using LLMs. UniDM formalizes a number of data manipulation tasks in a unified form and abstracts three main general steps to solve each task. We develop an automatic context retrieval to allow the LLMs to retrieve data from data lakes, potentially containing evidence and factual information. For each step, we design effective prompts to guide LLMs to produce high quality results. By our comprehensive evaluation on a variety of benchmarks, our UniDM exhibits great generality and state-of-the-art performance on a wide variety of data manipulation tasks.
Lero: A Learning-to-Rank Query Optimizer
Feb 20, 2023A recent line of works apply machine learning techniques to assist or rebuild cost-based query optimizers in DBMS. While exhibiting superiority in some benchmarks, their deficiencies, e.g., unstable performance, high training cost, and slow model updating, stem from the inherent hardness of predicting the cost or latency of execution plans using machine learning models. In this paper, we introduce a learning-to-rank query optimizer, called Lero, which builds on top of a native query optimizer and continuously learns to improve the optimization performance. The key observation is that the relative order or rank of plans, rather than the exact cost or latency, is sufficient for query optimization. Lero employs a pairwise approach to train a classifier to compare any two plans and tell which one is better. Such a binary classification task is much easier than the regression task to predict the cost or latency, in terms of model efficiency and accuracy. Rather than building a learned optimizer from scratch, Lero is designed to leverage decades of wisdom of databases and improve the native query optimizer. With its non-intrusive design, Lero can be implemented on top of any existing DBMS with minimal integration efforts. We implement Lero and demonstrate its outstanding performance using PostgreSQL. In our experiments, Lero achieves near optimal performance on several benchmarks. It reduces the plan execution time of the native optimizer in PostgreSQL by up to 70% and other learned query optimizers by up to 37%. Meanwhile, Lero continuously learns and automatically adapts to query workloads and changes in data.
Robust Contextual Linear Bandits
Oct 26, 2022Model misspecification is a major consideration in applications of statistical methods and machine learning. However, it is often neglected in contextual bandits. This paper studies a common form of misspecification, an inter-arm heterogeneity that is not captured by context. To address this issue, we assume that the heterogeneity arises due to arm-specific random variables, which can be learned. We call this setting a robust contextual bandit. The arm-specific variables explain the unknown inter-arm heterogeneity, and we incorporate them in the robust contextual estimator of the mean reward and its uncertainty. We develop two efficient bandit algorithms for our setting: a UCB algorithm called RoLinUCB and a posterior-sampling algorithm called RoLinTS. We analyze both algorithms and bound their $n$-round Bayes regret. Our experiments show that RoLinTS is comparably statistically efficient to the classic methods when the misspecification is low, more robust when the misspecification is high, and significantly more computationally efficient than its naive implementation.
Baihe: SysML Framework for AI-driven Databases
Dec 29, 2021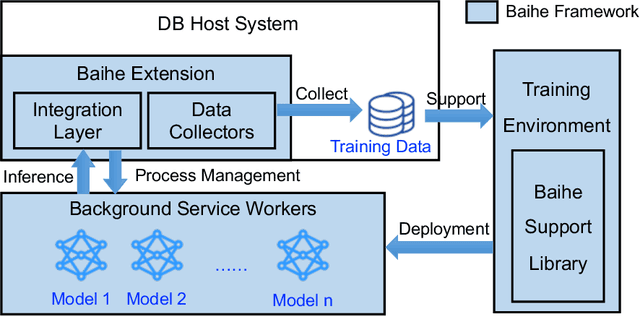
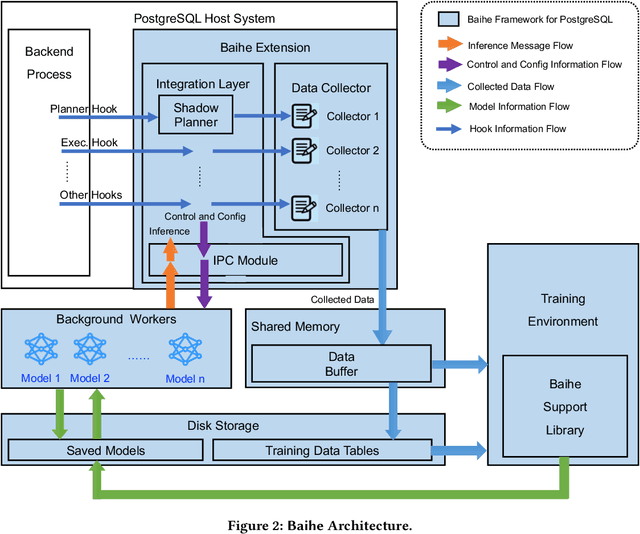
We present Baihe, a SysML Framework for AI-driven Databases. Using Baihe, an existing relational database system may be retrofitted to use learned components for query optimization or other common tasks, such as e.g. learned structure for indexing. To ensure the practicality and real world applicability of Baihe, its high level architecture is based on the following requirements: separation from the core system, minimal third party dependencies, Robustness, stability and fault tolerance, as well as stability and configurability. Based on the high level architecture, we then describe a concrete implementation of Baihe for PostgreSQL and present example use cases for learned query optimizers. To serve both practitioners, as well as researchers in the DB and AI4DB community Baihe for PostgreSQL will be released under open source license.
Glue: Adaptively Merging Single Table Cardinality to Estimate Join Query Size
Dec 07, 2021
Cardinality estimation (CardEst), a central component of the query optimizer, plays a significant role in generating high-quality query plans in DBMS. The CardEst problem has been extensively studied in the last several decades, using both traditional and ML-enhanced methods. Whereas, the hardest problem in CardEst, i.e., how to estimate the join query size on multiple tables, has not been extensively solved. Current methods either reply on independence assumptions or apply techniques with heavy burden, whose performance is still far from satisfactory. Even worse, existing CardEst methods are often designed to optimize one goal, i.e., inference speed or estimation accuracy, which can not adapt to different occasions. In this paper, we propose a very general framework, called Glue, to tackle with these challenges. Its key idea is to elegantly decouple the correlations across different tables and losslessly merge single table CardEst results to estimate the join query size. Glue supports obtaining the single table-wise CardEst results using any existing CardEst method and can process any complex join schema. Therefore, it easily adapts to different scenarios having different performance requirements, i.e., OLTP with fast estimation time or OLAP with high estimation accuracy. Meanwhile, we show that Glue can be seamlessly integrated into the plan search process and is able to support counting distinct number of values. All these properties exhibit the potential advances of deploying Glue in real-world DBMS.
Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation
Sep 15, 2021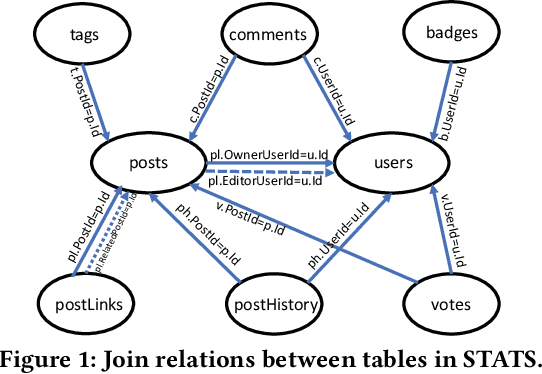
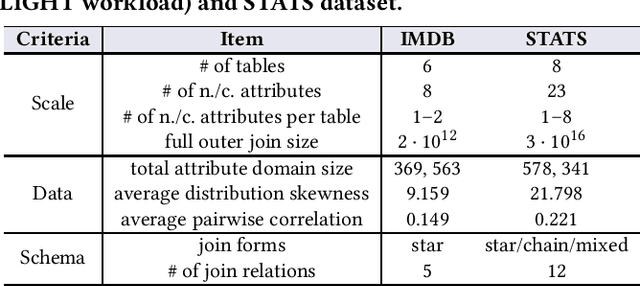
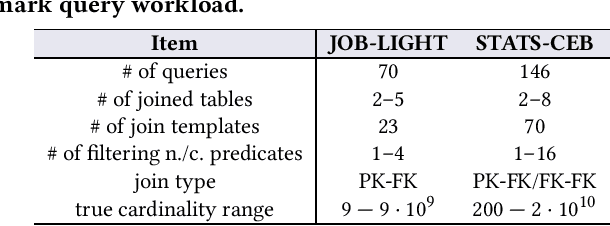
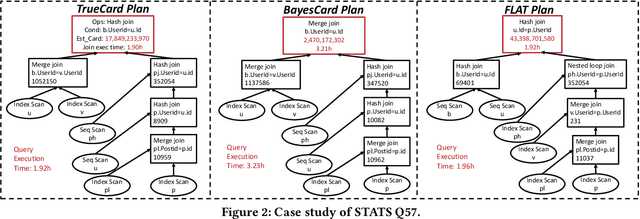
Cardinality estimation (CardEst) plays a significant role in generating high-quality query plans for a query optimizer in DBMS. In the last decade, an increasing number of advanced CardEst methods (especially ML-based) have been proposed with outstanding estimation accuracy and inference latency. However, there exists no study that systematically evaluates the quality of these methods and answer the fundamental problem: to what extent can these methods improve the performance of query optimizer in real-world settings, which is the ultimate goal of a CardEst method. In this paper, we comprehensively and systematically compare the effectiveness of CardEst methods in a real DBMS. We establish a new benchmark for CardEst, which contains a new complex real-world dataset STATS and a diverse query workload STATS-CEB. We integrate multiple most representative CardEst methods into an open-source database system PostgreSQL, and comprehensively evaluate their true effectiveness in improving query plan quality, and other important aspects affecting their applicability, ranging from inference latency, model size, and training time, to update efficiency and accuracy. We obtain a number of key findings for the CardEst methods, under different data and query settings. Furthermore, we find that the widely used estimation accuracy metric(Q-Error) cannot distinguish the importance of different sub-plan queries during query optimization and thus cannot truly reflect the query plan quality generated by CardEst methods. Therefore, we propose a new metric P-Error to evaluate the performance of CardEst methods, which overcomes the limitation of Q-Error and is able to reflect the overall end-to-end performance of CardEst methods. We have made all of the benchmark data and evaluation code publicly available at https://github.com/Nathaniel-Han/End-to-End-CardEst-Benchmark.
Random Effect Bandits
Jun 23, 2021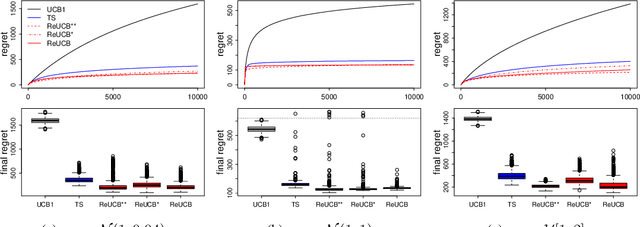
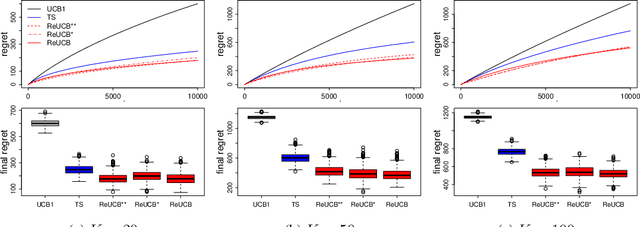
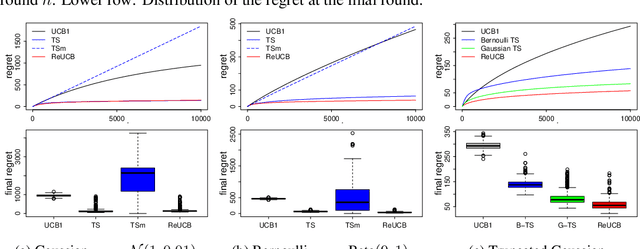
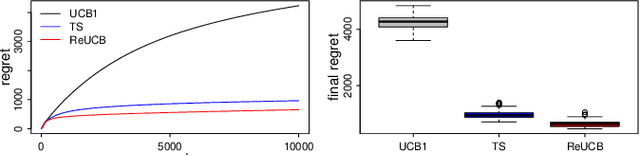
This paper studies regret minimization in multi-armed bandits, a classical online learning problem. To develop more statistically-efficient algorithms, we propose to use the assumption of a random-effect model. In this model, the mean rewards of arms are drawn independently from an unknown distribution, whose parameters we estimate. We provide an estimator of the arm means in this model and also analyze its uncertainty. Based on these results, we design a UCB algorithm, which we call ReUCB. We analyze ReUCB and prove a Bayes regret bound on its $n$-round regret, which matches an existing lower bound. Our experiments show that ReUCB can outperform Thompson sampling in various scenarios, without assuming that the prior distribution of arm means is known.