 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXLSor: A Robust and Accurate Lung Segmentor on Chest X-Rays Using Criss-Cross Attention and Customized Radiorealistic Abnormalities Generation
Apr 19, 2019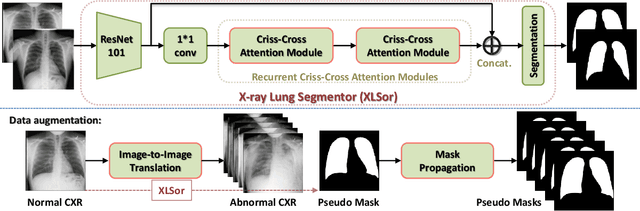
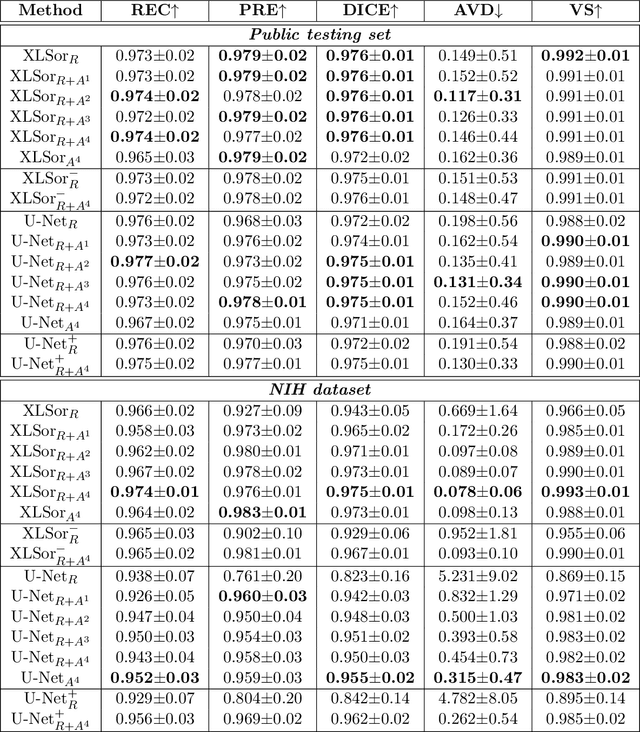
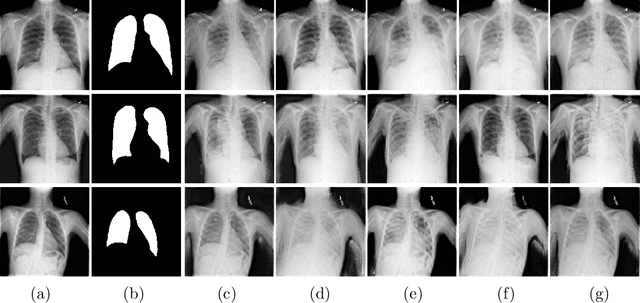
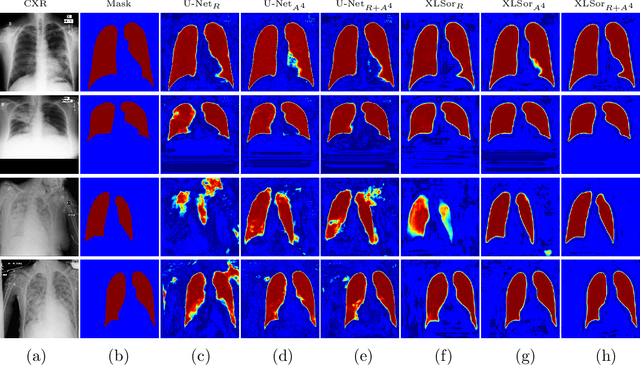
This paper proposes a novel framework for lung segmentation in chest X-rays. It consists of two key contributions, a criss-cross attention based segmentation network and radiorealistic chest X-ray image synthesis (i.e. a synthesized radiograph that appears anatomically realistic) for data augmentation. The criss-cross attention modules capture rich global contextual information in both horizontal and vertical directions for all the pixels thus facilitating accurate lung segmentation. To reduce the manual annotation burden and to train a robust lung segmentor that can be adapted to pathological lungs with hazy lung boundaries, an image-to-image translation module is employed to synthesize radiorealistic abnormal CXRs from the source of normal ones for data augmentation. The lung masks of synthetic abnormal CXRs are propagated from the segmentation results of their normal counterparts, and then serve as pseudo masks for robust segmentor training. In addition, we annotate 100 CXRs with lung masks on a more challenging NIH Chest X-ray dataset containing both posterioranterior and anteroposterior views for evaluation. Extensive experiments validate the robustness and effectiveness of the proposed framework. The code and data can be found from https://github.com/rsummers11/CADLab/tree/master/Lung_Segmentation_XLSor .
Fine-grained lesion annotation in CT images with knowledge mined from radiology reports
Mar 26, 2019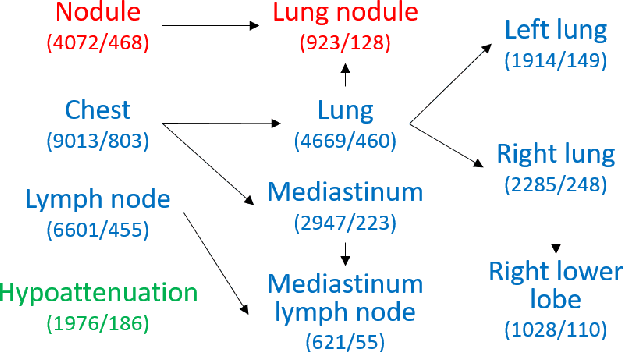
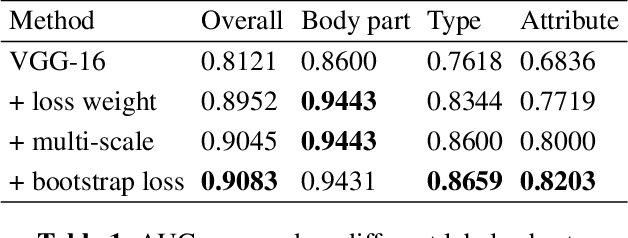

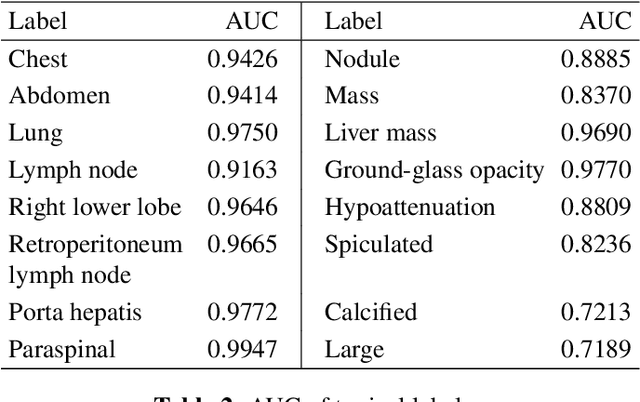
In radiologists' routine work, one major task is to read a medical image, e.g., a CT scan, find significant lesions, and write sentences in the radiology report to describe them. In this paper, we study the lesion description or annotation problem as an important step of computer-aided diagnosis (CAD). Given a lesion image, our aim is to predict multiple relevant labels, such as the lesion's body part, type, and attributes. To address this problem, we define a set of 145 labels based on RadLex to describe a large variety of lesions in the DeepLesion dataset. We directly mine training labels from the lesion's corresponding sentence in the radiology report, which requires minimal manual effort and is easily generalizable to large data and label sets. A multi-label convolutional neural network is then proposed for images with multi-scale structure and a noise-robust loss. Quantitative and qualitative experiments demonstrate the effectiveness of the framework. The average area under ROC curve on 1,872 test lesions is 0.9083.
Abnormal Chest X-ray Identification With Generative Adversarial One-Class Classifier
Mar 05, 2019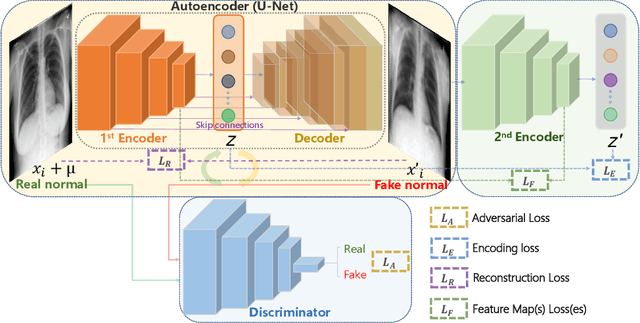
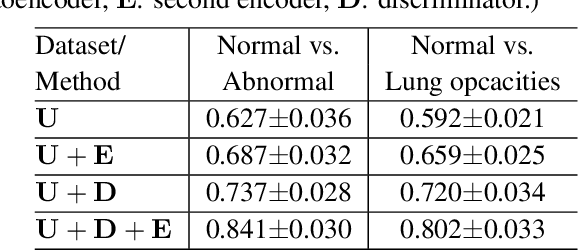
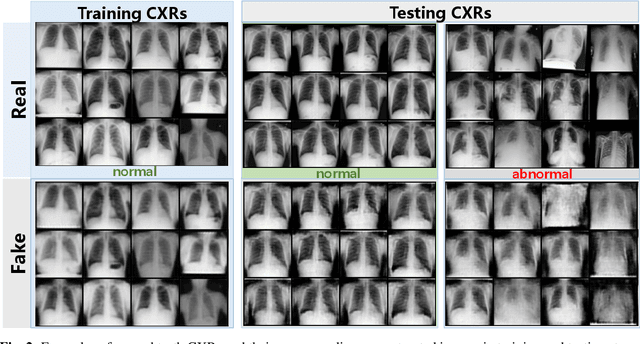
Being one of the most common diagnostic imaging tests, chest radiography requires timely reporting of potential findings in the images. In this paper, we propose an end-to-end architecture for abnormal chest X-ray identification using generative adversarial one-class learning. Unlike previous approaches, our method takes only normal chest X-ray images as input. The architecture is composed of three deep neural networks, each of which learned by competing while collaborating among them to model the underlying content structure of the normal chest X-rays. Given a chest X-ray image in the testing phase, if it is normal, the learned architecture can well model and reconstruct the content; if it is abnormal, since the content is unseen in the training phase, the model would perform poorly in its reconstruction. It thus enables distinguishing abnormal chest X-rays from normal ones. Quantitative and qualitative experiments demonstrate the effectiveness and efficiency of our approach, where an AUC of 0.841 is achieved on the challenging NIH Chest X-ray dataset in a one-class learning setting, with the potential in reducing the workload for radiologists.
A large annotated medical image dataset for the development and evaluation of segmentation algorithms
Feb 25, 2019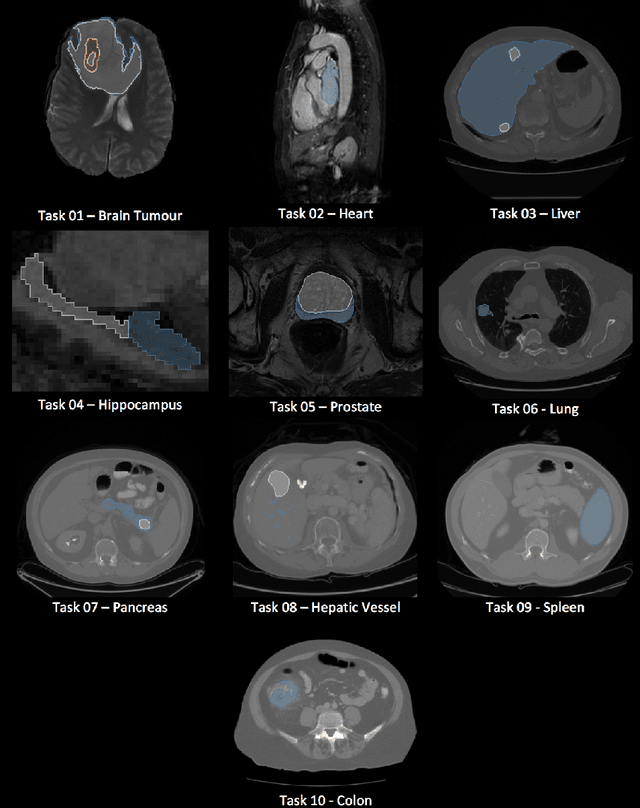

Semantic segmentation of medical images aims to associate a pixel with a label in a medical image without human initialization. The success of semantic segmentation algorithms is contingent on the availability of high-quality imaging data with corresponding labels provided by experts. We sought to create a large collection of annotated medical image datasets of various clinically relevant anatomies available under open source license to facilitate the development of semantic segmentation algorithms. Such a resource would allow: 1) objective assessment of general-purpose segmentation methods through comprehensive benchmarking and 2) open and free access to medical image data for any researcher interested in the problem domain. Through a multi-institutional effort, we generated a large, curated dataset representative of several highly variable segmentation tasks that was used in a crowd-sourced challenge - the Medical Segmentation Decathlon held during the 2018 Medical Image Computing and Computer Aided Interventions Conference in Granada, Spain. Here, we describe these ten labeled image datasets so that these data may be effectively reused by the research community.
Spatial-Temporal Convolutional LSTMs for Tumor Growth Prediction by Learning 4D Longitudinal Patient Data
Feb 23, 2019
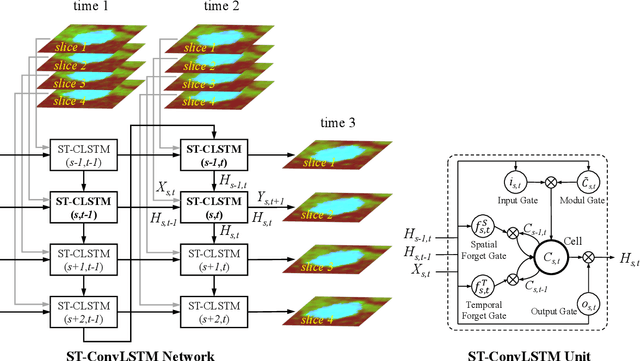
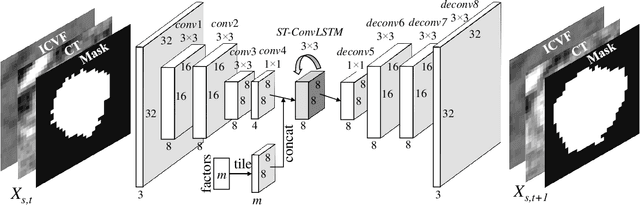

Prognostic tumor growth modeling via medical imaging observations is a challenging yet important problem in precision and predictive medicine. Traditionally, this problem is tackled through mathematical modeling and evaluated using relatively small patient datasets. Recent advances of convolutional networks (ConvNets) have demonstrated their higher accuracy than mathematical models in predicting future tumor volumes. This indicates that deep learning may have great potentials on addressing such problem. The state-of-the-art work models the cell invasion and mass-effect of tumor growth by training separate ConvNets on 2D image patches. Nevertheless such a 2D modeling approach cannot make full use of the spatial-temporal imaging context of the tumor's longitudinal 4D (3D + time) patient data. Moreover, previous methods are incapable to predict clinically-relevant tumor properties, other than the tumor volumes. In this paper, we exploit to formulate the tumor growth process through convolutional LSTMs (ConvLSTM) that extract tumor's static imaging appearances and simultaneously capture its temporal dynamic changes within a single network. We extend ConvLSTM into the spatial-temporal domain (ST-ConvLSTM) by jointly learning the inter-slice 3D contexts and the longitudinal dynamics. Our approach can incorporate other non-imaging patient information in an end-to-end trainable manner. Experiments are conducted on the largest 4D longitudinal tumor dataset of 33 patients to date. Results validate that the proposed ST-ConvLSTM model produces a Dice score of 83.2%+-5.1% and a RVD of 11.2%+-10.8%, both statistically significantly outperforming (p<0.05) other compared methods of traditional linear model, ConvLSTM, and generative adversarial network (GAN) under the metric of predicting future tumor volumes. Last, our new method enables the prediction of both cell density and CT intensity numbers.
ULDor: A Universal Lesion Detector for CT Scans with Pseudo Masks and Hard Negative Example Mining
Jan 18, 2019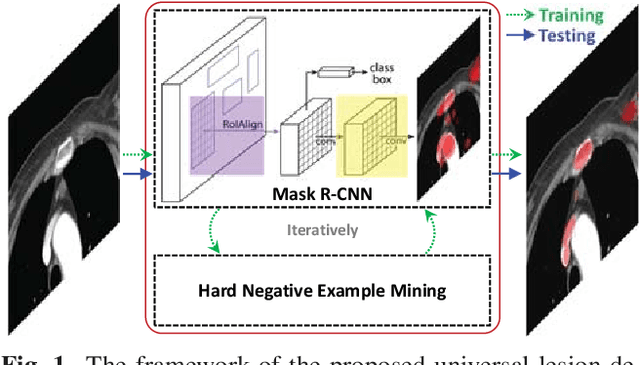
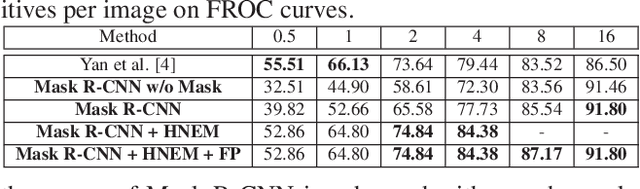
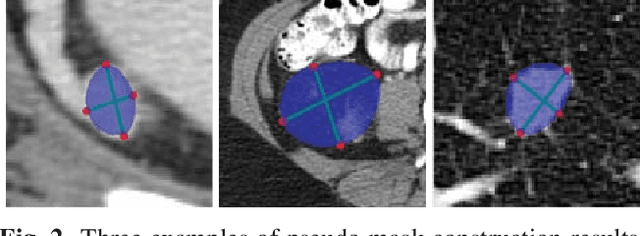
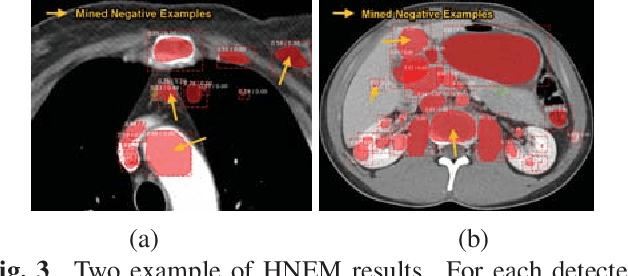
Automatic lesion detection from computed tomography (CT) scans is an important task in medical imaging analysis. It is still very challenging due to similar appearances (e.g. intensity and texture) between lesions and other tissues, making it especially difficult to develop a universal lesion detector. Instead of developing a specific-type lesion detector, this work builds a Universal Lesion Detector (ULDor) based on Mask R-CNN, which is able to detect all different kinds of lesions from whole body parts. As a state-of-the-art object detector, Mask R-CNN adds a branch for predicting segmentation masks on each Region of Interest (RoI) to improve the detection performance. However, it is almost impossible to manually annotate a large-scale dataset with pixel-level lesion masks to train the Mask R-CNN for lesion detection. To address this problem, this work constructs a pseudo mask for each lesion region that can be considered as a surrogate of the real mask, based on which the Mask R-CNN is employed for lesion detection. On the other hand, this work proposes a hard negative example mining strategy to reduce the false positives for improving the detection performance. Experimental results on the NIH DeepLesion dataset demonstrate that the ULDor is enhanced using pseudo masks and the proposed hard negative example mining strategy and achieves a sensitivity of 86.21% with five false positives per image.
3D Context Enhanced Region-based Convolutional Neural Network for End-to-End Lesion Detection
Jul 29, 2018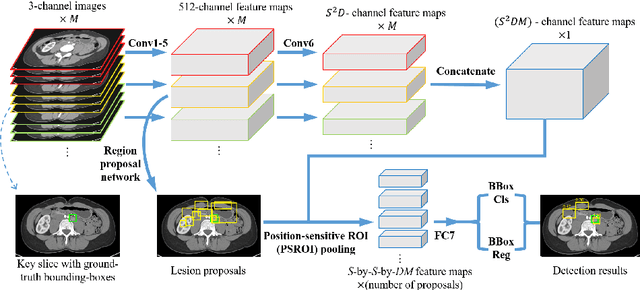

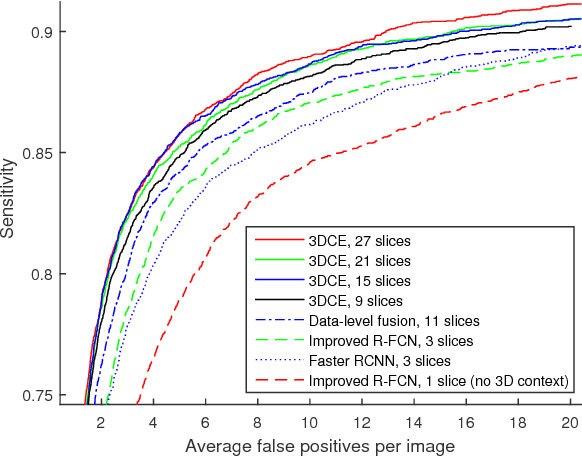
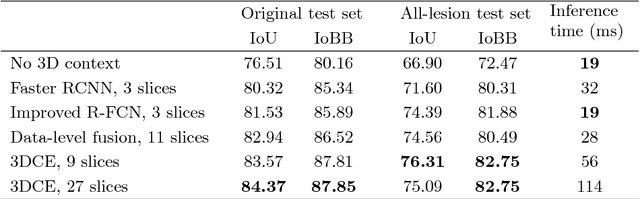
Detecting lesions from computed tomography (CT) scans is an important but difficult problem because non-lesions and true lesions can appear similar. 3D context is known to be helpful in this differentiation task. However, existing end-to-end detection frameworks of convolutional neural networks (CNNs) are mostly designed for 2D images. In this paper, we propose 3D context enhanced region-based CNN (3DCE) to incorporate 3D context information efficiently by aggregating feature maps of 2D images. 3DCE is easy to train and end-to-end in training and inference. A universal lesion detector is developed to detect all kinds of lesions in one algorithm using the DeepLesion dataset. Experimental results on this challenging task prove the effectiveness of 3DCE. We have released the code of 3DCE in https://github.com/rsummers11/CADLab/tree/master/lesion_detector_3DCE.
Attention-Guided Curriculum Learning for Weakly Supervised Classification and Localization of Thoracic Diseases on Chest Radiographs
Jul 19, 2018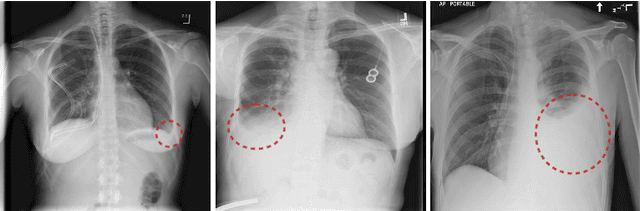
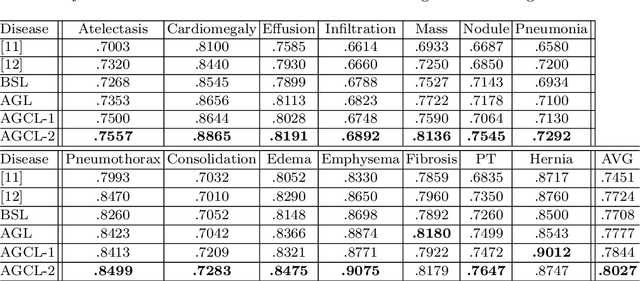
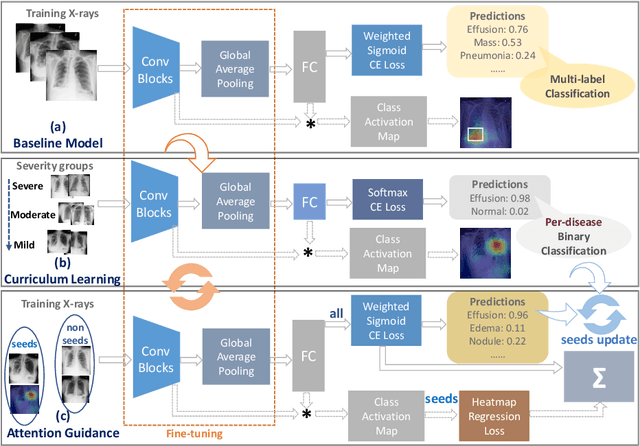
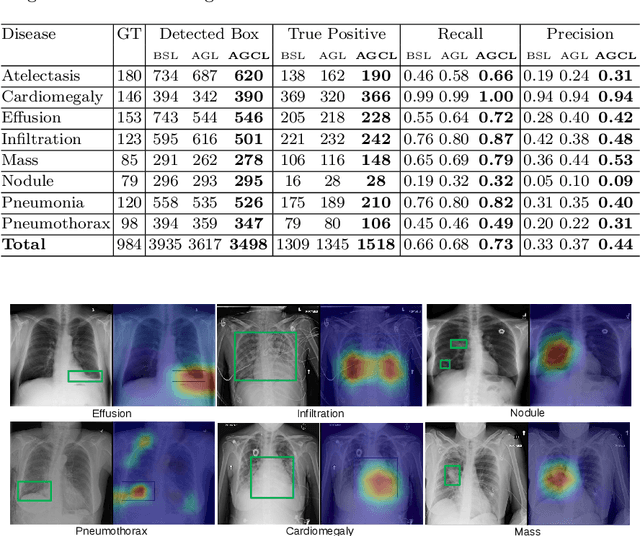
In this work, we exploit the task of joint classification and weakly supervised localization of thoracic diseases from chest radiographs, with only image-level disease labels coupled with disease severity-level (DSL) information of a subset. A convolutional neural network (CNN) based attention-guided curriculum learning (AGCL) framework is presented, which leverages the severity-level attributes mined from radiology reports. Images in order of difficulty (grouped by different severity-levels) are fed to CNN to boost the learning gradually. In addition, highly confident samples (measured by classification probabilities) and their corresponding class-conditional heatmaps (generated by the CNN) are extracted and further fed into the AGCL framework to guide the learning of more distinctive convolutional features in the next iteration. A two-path network architecture is designed to regress the heatmaps from selected seed samples in addition to the original classification task. The joint learning scheme can improve the classification and localization performance along with more seed samples for the next iteration. We demonstrate the effectiveness of this iterative refinement framework via extensive experimental evaluations on the publicly available ChestXray14 dataset. AGCL achieves over 5.7\% (averaged over 14 diseases) increase in classification AUC and 7%/11% increases in Recall/Precision for the localization task compared to the state of the art.
CT Image Enhancement Using Stacked Generative Adversarial Networks and Transfer Learning for Lesion Segmentation Improvement
Jul 18, 2018
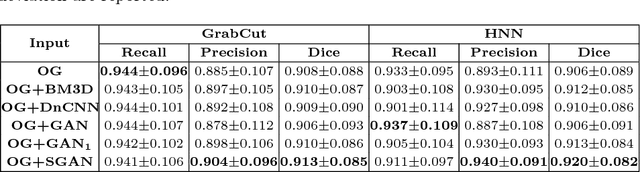


Automated lesion segmentation from computed tomography (CT) is an important and challenging task in medical image analysis. While many advancements have been made, there is room for continued improvements. One hurdle is that CT images can exhibit high noise and low contrast, particularly in lower dosages. To address this, we focus on a preprocessing method for CT images that uses stacked generative adversarial networks (SGAN) approach. The first GAN reduces the noise in the CT image and the second GAN generates a higher resolution image with enhanced boundaries and high contrast. To make up for the absence of high quality CT images, we detail how to synthesize a large number of low- and high-quality natural images and use transfer learning with progressively larger amounts of CT images. We apply both the classic GrabCut method and the modern holistically nested network (HNN) to lesion segmentation, testing whether SGAN can yield improved lesion segmentation. Experimental results on the DeepLesion dataset demonstrate that the SGAN enhancements alone can push GrabCut performance over HNN trained on original images. We also demonstrate that HNN + SGAN performs best compared against four other enhancement methods, including when using only a single GAN.
Accurate Weakly-Supervised Deep Lesion Segmentation using Large-Scale Clinical Annotations: Slice-Propagated 3D Mask Generation from 2D RECIST
Jul 02, 2018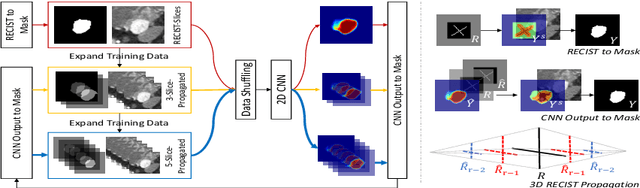
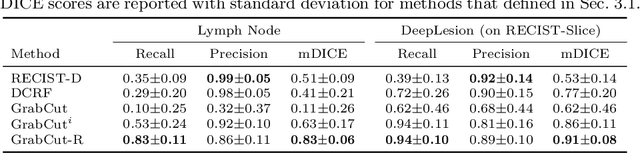
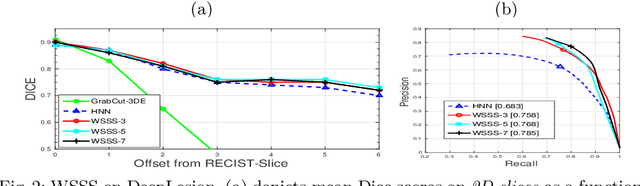
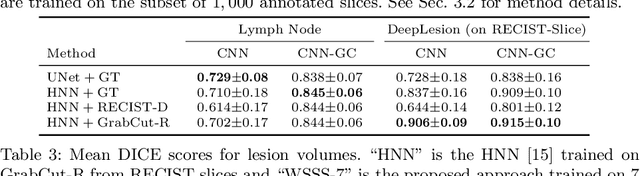
Volumetric lesion segmentation from computed tomography (CT) images is a powerful means to precisely assess multiple time-point lesion/tumor changes. However, because manual 3D segmentation is prohibitively time consuming, current practices rely on an imprecise surrogate called response evaluation criteria in solid tumors (RECIST). Despite their coarseness, RECIST markers are commonly found in current hospital picture and archiving systems (PACS), meaning they can provide a potentially powerful, yet extraordinarily challenging, source of weak supervision for full 3D segmentation. Toward this end, we introduce a convolutional neural network (CNN) based weakly supervised slice-propagated segmentation (WSSS) method to 1) generate the initial lesion segmentation on the axial RECIST-slice; 2) learn the data distribution on RECIST-slices; 3) extrapolate to segment the whole lesion slice by slice to finally obtain a volumetric segmentation. To validate the proposed method, we first test its performance on a fully annotated lymph node dataset, where WSSS performs comparably to its fully supervised counterparts. We then test on a comprehensive lesion dataset with 32,735 RECIST marks, where we report a mean Dice score of 92% on RECIST-marked slices and 76% on the entire 3D volumes.