 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Image Synthesis for Abdominal CT
Dec 11, 2023



As a new emerging and promising type of generative models, diffusion models have proven to outperform Generative Adversarial Networks (GANs) in multiple tasks, including image synthesis. In this work, we explore semantic image synthesis for abdominal CT using conditional diffusion models, which can be used for downstream applications such as data augmentation. We systematically evaluated the performance of three diffusion models, as well as to other state-of-the-art GAN-based approaches, and studied the different conditioning scenarios for the semantic mask. Experimental results demonstrated that diffusion models were able to synthesize abdominal CT images with better quality. Additionally, encoding the mask and the input separately is more effective than na\"ive concatenating.
RAISE -- Radiology AI Safety, an End-to-end lifecycle approach
Nov 24, 2023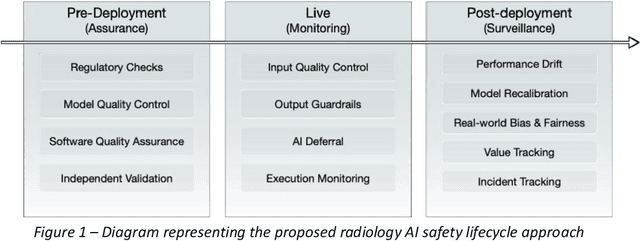
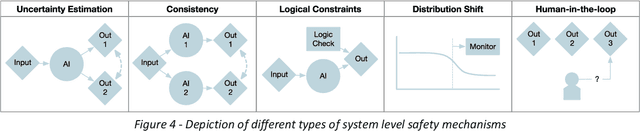
The integration of AI into radiology introduces opportunities for improved clinical care provision and efficiency but it demands a meticulous approach to mitigate potential risks as with any other new technology. Beginning with rigorous pre-deployment evaluation and validation, the focus should be on ensuring models meet the highest standards of safety, effectiveness and efficacy for their intended applications. Input and output guardrails implemented during production usage act as an additional layer of protection, identifying and addressing individual failures as they occur. Continuous post-deployment monitoring allows for tracking population-level performance (data drift), fairness, and value delivery over time. Scheduling reviews of post-deployment model performance and educating radiologists about new algorithmic-driven findings is critical for AI to be effective in clinical practice. Recognizing that no single AI solution can provide absolute assurance even when limited to its intended use, the synergistic application of quality assurance at multiple levels - regulatory, clinical, technical, and ethical - is emphasized. Collaborative efforts between stakeholders spanning healthcare systems, industry, academia, and government are imperative to address the multifaceted challenges involved. Trust in AI is an earned privilege, contingent on a broad set of goals, among them transparently demonstrating that the AI adheres to the same rigorous safety, effectiveness and efficacy standards as other established medical technologies. By doing so, developers can instil confidence among providers and patients alike, enabling the responsible scaling of AI and the realization of its potential benefits. The roadmap presented herein aims to expedite the achievement of deployable, reliable, and safe AI in radiology.
Automated Measurement of Pericoronary Adipose Tissue Attenuation and Volume in CT Angiography
Nov 22, 2023



Pericoronary adipose tissue (PCAT) is the deposition of fat in the vicinity of the coronary arteries. It is an indicator of coronary inflammation and associated with coronary artery disease. Non-invasive coronary CT angiography (CCTA) is presently used to obtain measures of the thickness, volume, and attenuation of fat deposition. However, prior works solely focus on measuring PCAT using semi-automated approaches at the right coronary artery (RCA) over the left coronary artery (LCA). In this pilot work, we developed a fully automated approach for the measurement of PCAT mean attenuation and volume in the region around both coronary arteries. First, we used a large subset of patients from the public ImageCAS dataset (n = 735) to train a 3D full resolution nnUNet to segment LCA and RCA. Then, we automatically measured PCAT in the surrounding arterial regions. We evaluated our method on a held-out test set of patients (n = 183) from the same dataset. A mean Dice score of 83% and PCAT attenuation of -73.81 $\pm$ 12.69 HU was calculated for the RCA, while a mean Dice score of 81% and PCAT attenuation of -77.51 $\pm$ 7.94 HU was computed for the LCA. To the best of our knowledge, we are the first to develop a fully automated method to measure PCAT attenuation and volume at both the RCA and LCA. Our work underscores how automated PCAT measurement holds promise as a biomarker for identification of inflammation and cardiac disease.
Towards long-tailed, multi-label disease classification from chest X-ray: Overview of the CXR-LT challenge
Oct 24, 2023



Many real-world image recognition problems, such as diagnostic medical imaging exams, are "long-tailed" $\unicode{x2013}$ there are a few common findings followed by many more relatively rare conditions. In chest radiography, diagnosis is both a long-tailed and multi-label problem, as patients often present with multiple findings simultaneously. While researchers have begun to study the problem of long-tailed learning in medical image recognition, few have studied the interaction of label imbalance and label co-occurrence posed by long-tailed, multi-label disease classification. To engage with the research community on this emerging topic, we conducted an open challenge, CXR-LT, on long-tailed, multi-label thorax disease classification from chest X-rays (CXRs). We publicly release a large-scale benchmark dataset of over 350,000 CXRs, each labeled with at least one of 26 clinical findings following a long-tailed distribution. We synthesize common themes of top-performing solutions, providing practical recommendations for long-tailed, multi-label medical image classification. Finally, we use these insights to propose a path forward involving vision-language foundation models for few- and zero-shot disease classification.
Expert Uncertainty and Severity Aware Chest X-Ray Classification by Multi-Relationship Graph Learning
Sep 06, 2023Patients undergoing chest X-rays (CXR) often endure multiple lung diseases. When evaluating a patient's condition, due to the complex pathologies, subtle texture changes of different lung lesions in images, and patient condition differences, radiologists may make uncertain even when they have experienced long-term clinical training and professional guidance, which makes much noise in extracting disease labels based on CXR reports. In this paper, we re-extract disease labels from CXR reports to make them more realistic by considering disease severity and uncertainty in classification. Our contributions are as follows: 1. We re-extracted the disease labels with severity and uncertainty by a rule-based approach with keywords discussed with clinical experts. 2. To further improve the explainability of chest X-ray diagnosis, we designed a multi-relationship graph learning method with an expert uncertainty-aware loss function. 3. Our multi-relationship graph learning method can also interpret the disease classification results. Our experimental results show that models considering disease severity and uncertainty outperform previous state-of-the-art methods.
How Does Pruning Impact Long-Tailed Multi-Label Medical Image Classifiers?
Aug 17, 2023Pruning has emerged as a powerful technique for compressing deep neural networks, reducing memory usage and inference time without significantly affecting overall performance. However, the nuanced ways in which pruning impacts model behavior are not well understood, particularly for long-tailed, multi-label datasets commonly found in clinical settings. This knowledge gap could have dangerous implications when deploying a pruned model for diagnosis, where unexpected model behavior could impact patient well-being. To fill this gap, we perform the first analysis of pruning's effect on neural networks trained to diagnose thorax diseases from chest X-rays (CXRs). On two large CXR datasets, we examine which diseases are most affected by pruning and characterize class "forgettability" based on disease frequency and co-occurrence behavior. Further, we identify individual CXRs where uncompressed and heavily pruned models disagree, known as pruning-identified exemplars (PIEs), and conduct a human reader study to evaluate their unifying qualities. We find that radiologists perceive PIEs as having more label noise, lower image quality, and higher diagnosis difficulty. This work represents a first step toward understanding the impact of pruning on model behavior in deep long-tailed, multi-label medical image classification. All code, model weights, and data access instructions can be found at https://github.com/VITA-Group/PruneCXR.
C-DARL: Contrastive diffusion adversarial representation learning for label-free blood vessel segmentation
Jul 31, 2023Blood vessel segmentation in medical imaging is one of the essential steps for vascular disease diagnosis and interventional planning in a broad spectrum of clinical scenarios in image-based medicine and interventional medicine. Unfortunately, manual annotation of the vessel masks is challenging and resource-intensive due to subtle branches and complex structures. To overcome this issue, this paper presents a self-supervised vessel segmentation method, dubbed the contrastive diffusion adversarial representation learning (C-DARL) model. Our model is composed of a diffusion module and a generation module that learns the distribution of multi-domain blood vessel data by generating synthetic vessel images from diffusion latent. Moreover, we employ contrastive learning through a mask-based contrastive loss so that the model can learn more realistic vessel representations. To validate the efficacy, C-DARL is trained using various vessel datasets, including coronary angiograms, abdominal digital subtraction angiograms, and retinal imaging. Experimental results confirm that our model achieves performance improvement over baseline methods with noise robustness, suggesting the effectiveness of C-DARL for vessel segmentation.
Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
Jul 22, 2023



To contribute to automating the medical vision-language model, we propose a novel Chest-Xray Difference Visual Question Answering (VQA) task. Given a pair of main and reference images, this task attempts to answer several questions on both diseases and, more importantly, the differences between them. This is consistent with the radiologist's diagnosis practice that compares the current image with the reference before concluding the report. We collect a new dataset, namely MIMIC-Diff-VQA, including 700,703 QA pairs from 164,324 pairs of main and reference images. Compared to existing medical VQA datasets, our questions are tailored to the Assessment-Diagnosis-Intervention-Evaluation treatment procedure used by clinical professionals. Meanwhile, we also propose a novel expert knowledge-aware graph representation learning model to address this task. The proposed baseline model leverages expert knowledge such as anatomical structure prior, semantic, and spatial knowledge to construct a multi-relationship graph, representing the image differences between two images for the image difference VQA task. The dataset and code can be found at https://github.com/Holipori/MIMIC-Diff-VQA. We believe this work would further push forward the medical vision language model.
Improving Segmentation and Detection of Lesions in CT Scans Using Intensity Distribution Supervision
Jul 11, 2023We propose a method to incorporate the intensity information of a target lesion on CT scans in training segmentation and detection networks. We first build an intensity-based lesion probability (ILP) function from an intensity histogram of the target lesion. It is used to compute the probability of being the lesion for each voxel based on its intensity. Finally, the computed ILP map of each input CT scan is provided as additional supervision for network training, which aims to inform the network about possible lesion locations in terms of intensity values at no additional labeling cost. The method was applied to improve the segmentation of three different lesion types, namely, small bowel carcinoid tumor, kidney tumor, and lung nodule. The effectiveness of the proposed method on a detection task was also investigated. We observed improvements of 41.3% -> 47.8%, 74.2% -> 76.0%, and 26.4% -> 32.7% in segmenting small bowel carcinoid tumor, kidney tumor, and lung nodule, respectively, in terms of per case Dice scores. An improvement of 64.6% -> 75.5% was achieved in detecting kidney tumors in terms of average precision. The results of different usages of the ILP map and the effect of varied amount of training data are also presented.
Utilizing Longitudinal Chest X-Rays and Reports to Pre-Fill Radiology Reports
Jun 14, 2023Despite the reduction in turn-around times in radiology reports with the use of speech recognition software, persistent communication errors can significantly impact the interpretation of the radiology report. Pre-filling a radiology report holds promise in mitigating reporting errors, and despite efforts in the literature to generate medical reports, there exists a lack of approaches that exploit the longitudinal nature of patient visit records in the MIMIC-CXR dataset. To address this gap, we propose to use longitudinal multi-modal data, i.e., previous patient visit CXR, current visit CXR, and previous visit report, to pre-fill the 'findings' section of a current patient visit report. We first gathered the longitudinal visit information for 26,625 patients from the MIMIC-CXR dataset and created a new dataset called Longitudinal-MIMIC. With this new dataset, a transformer-based model was trained to capture the information from longitudinal patient visit records containing multi-modal data (CXR images + reports) via a cross-attention-based multi-modal fusion module and a hierarchical memory-driven decoder. In contrast to previous work that only uses current visit data as input to train a model, our work exploits the longitudinal information available to pre-fill the 'findings' section of radiology reports. Experiments show that our approach outperforms several recent approaches by >=3% on F1 score, and >=2% for BLEU-4, METEOR and ROUGE-L respectively. The dataset and code will be made publicly available.