 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Modern NLP Systems Reliably Annotate Chest Radiography Exams? A Pre-Purchase Evaluation and Comparative Study of Solutions from AWS, Google, Azure, John Snow Labs, and Open-Source Models on an Independent Pediatric Dataset
May 29, 2025General-purpose clinical natural language processing (NLP) tools are increasingly used for the automatic labeling of clinical reports. However, independent evaluations for specific tasks, such as pediatric chest radiograph (CXR) report labeling, are limited. This study compares four commercial clinical NLP systems - Amazon Comprehend Medical (AWS), Google Healthcare NLP (GC), Azure Clinical NLP (AZ), and SparkNLP (SP) - for entity extraction and assertion detection in pediatric CXR reports. Additionally, CheXpert and CheXbert, two dedicated chest radiograph report labelers, were evaluated on the same task using CheXpert-defined labels. We analyzed 95,008 pediatric CXR reports from a large academic pediatric hospital. Entities and assertion statuses (positive, negative, uncertain) from the findings and impression sections were extracted by the NLP systems, with impression section entities mapped to 12 disease categories and a No Findings category. CheXpert and CheXbert extracted the same 13 categories. Outputs were compared using Fleiss Kappa and accuracy against a consensus pseudo-ground truth. Significant differences were found in the number of extracted entities and assertion distributions across NLP systems. SP extracted 49,688 unique entities, GC 16,477, AZ 31,543, and AWS 27,216. Assertion accuracy across models averaged around 62%, with SP highest (76%) and AWS lowest (50%). CheXpert and CheXbert achieved 56% accuracy. Considerable variability in performance highlights the need for careful validation and review before deploying NLP tools for clinical report labeling.
RAISE -- Radiology AI Safety, an End-to-end lifecycle approach
Nov 24, 2023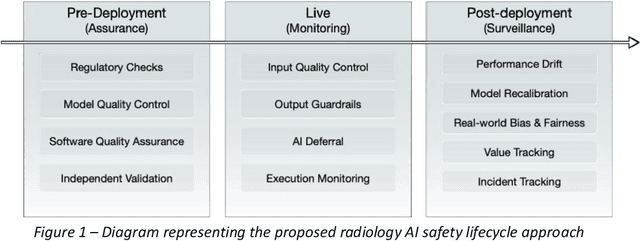
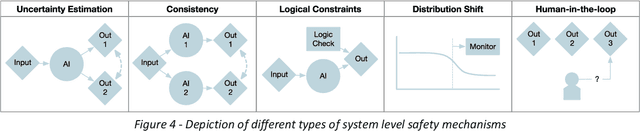
The integration of AI into radiology introduces opportunities for improved clinical care provision and efficiency but it demands a meticulous approach to mitigate potential risks as with any other new technology. Beginning with rigorous pre-deployment evaluation and validation, the focus should be on ensuring models meet the highest standards of safety, effectiveness and efficacy for their intended applications. Input and output guardrails implemented during production usage act as an additional layer of protection, identifying and addressing individual failures as they occur. Continuous post-deployment monitoring allows for tracking population-level performance (data drift), fairness, and value delivery over time. Scheduling reviews of post-deployment model performance and educating radiologists about new algorithmic-driven findings is critical for AI to be effective in clinical practice. Recognizing that no single AI solution can provide absolute assurance even when limited to its intended use, the synergistic application of quality assurance at multiple levels - regulatory, clinical, technical, and ethical - is emphasized. Collaborative efforts between stakeholders spanning healthcare systems, industry, academia, and government are imperative to address the multifaceted challenges involved. Trust in AI is an earned privilege, contingent on a broad set of goals, among them transparently demonstrating that the AI adheres to the same rigorous safety, effectiveness and efficacy standards as other established medical technologies. By doing so, developers can instil confidence among providers and patients alike, enabling the responsible scaling of AI and the realization of its potential benefits. The roadmap presented herein aims to expedite the achievement of deployable, reliable, and safe AI in radiology.