 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Omnidirectional Aerial Manipulation Platform for Contact-Based Inspection
May 09, 2019
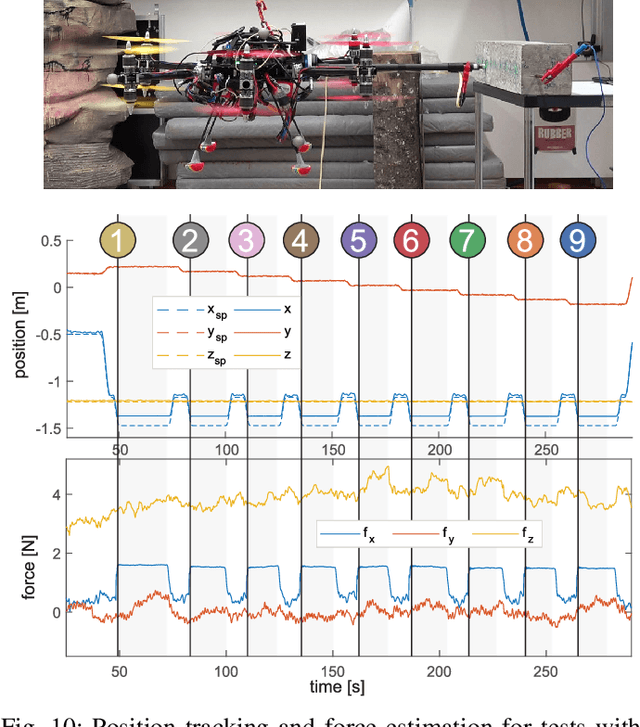
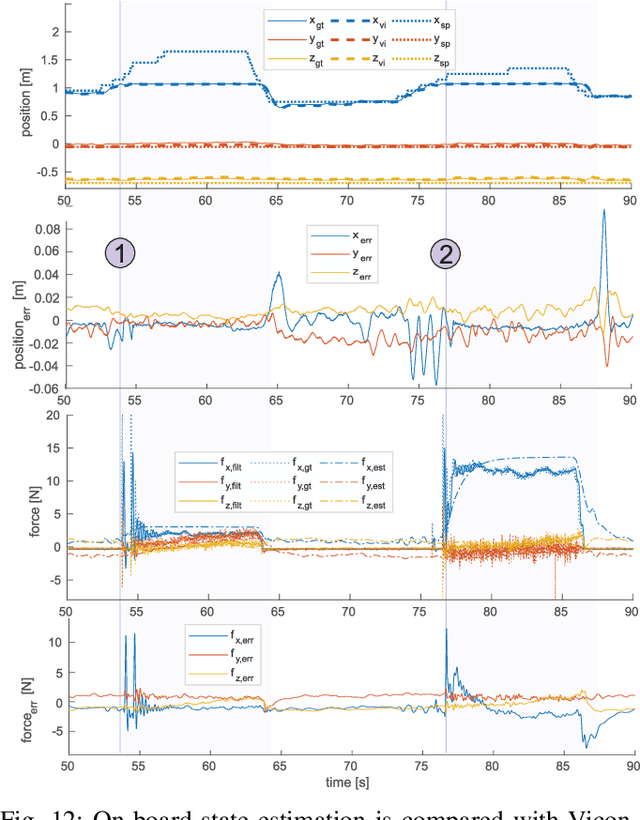
This paper presents an omnidirectional aerial manipulation platform for robust and responsive interaction with unstructured environments, toward the goal of contact-based inspection. The fully actuated tilt-rotor aerial system is equipped with a rigidly mounted end-effector, and is able to exert a 6 degree of freedom force and torque, decoupling the system's translational and rotational dynamics, and enabling precise interaction with the environment while maintaining stability. An impedance controller with selective apparent inertia is formulated to permit compliance in certain degrees of freedom while achieving precise trajectory tracking and disturbance rejection in others. Experiments demonstrate disturbance rejection, push-and-slide interaction, and on-board state estimation with depth servoing to interact with local surfaces. The system is also validated as a tool for contact-based non-destructive testing of concrete infrastructure.
Experimental Comparison of Visual-Aided Odometry Methods for Rail Vehicles
Apr 01, 2019
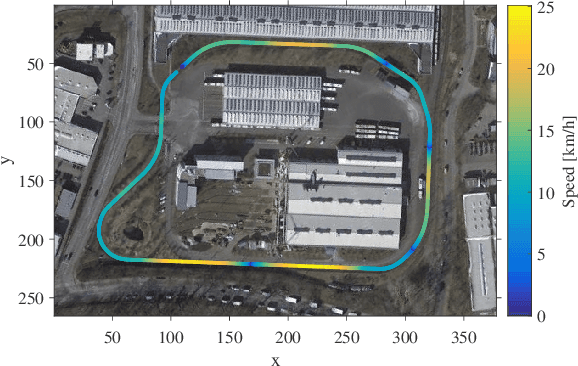
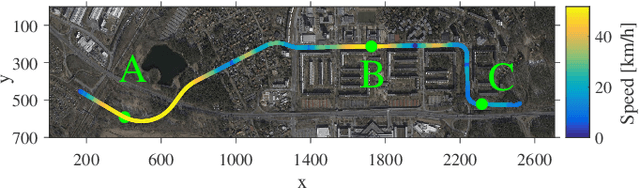
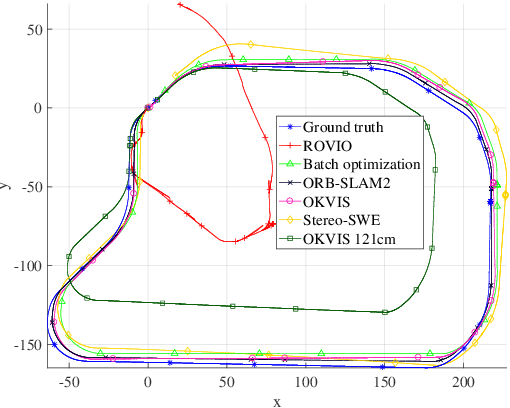
Today, rail vehicle localization is based on infrastructure-side Balises (beacons) together with on-board odometry to determine whether a rail segment is occupied. Such a coarse locking leads to a sub-optimal usage of the rail networks. New railway standards propose the use of moving blocks centered around the rail vehicles to increase the capacity of the network. However, this approach requires accurate and robust position and velocity estimation of all vehicles. In this work, we investigate the applicability, challenges and limitations of current visual and visual-inertial motion estimation frameworks for rail applications. An evaluation against RTK-GPS ground truth is performed on multiple datasets recorded in industrial, sub-urban, and forest environments. Our results show that stereo visual-inertial odometry has a great potential to provide a precise motion estimation because of its complementing sensor modalities and shows superior performance in challenging situations compared to other frameworks.
Attitude- and Cruise Control of a VTOL Tiltwing UAV
Mar 25, 2019
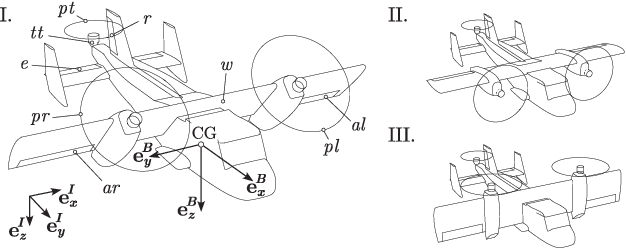
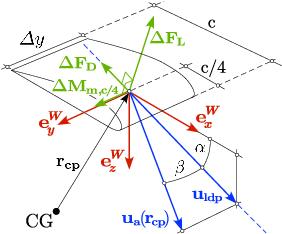
This paper presents the mathematical modeling, controller design, and flight-testing of an over-actuated Vertical Take-off and Landing (VTOL) tiltwing Unmanned Aerial Vehicle (UAV). Based on simplified aerodynamics and first-principles, a dynamical model of the UAV is developed which captures key aerodynamic effects including propeller slipstream on the wing and post-stall characteristics of the airfoils. The model-based steady-state flight envelope and the corresponding trim-actuation is analyzed and the overactuation of the UAV solved by optimizing for, e.g., power-optimal trims. The developed control system is composed of two controllers: First, a low-level attitude controller based on dynamic inversion and a daisy-chaining approach to handle allocation of redundant actuators. Secondly, a higher-level cruise controller to track a desired vertical velocity. It is based on a linearization of the system and look-up tables to determine the strong and nonlinear variation of the trims throughout the flight-envelope. We demonstrate the performance of the control-system for all flight phases (hover, transition, cruise) in extensive flight-tests.
OREOS: Oriented Recognition of 3D Point Clouds in Outdoor Scenarios
Mar 19, 2019

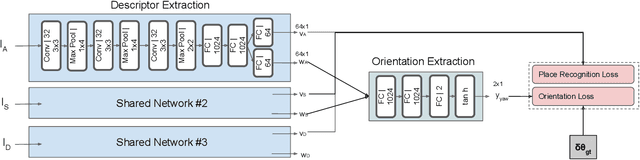
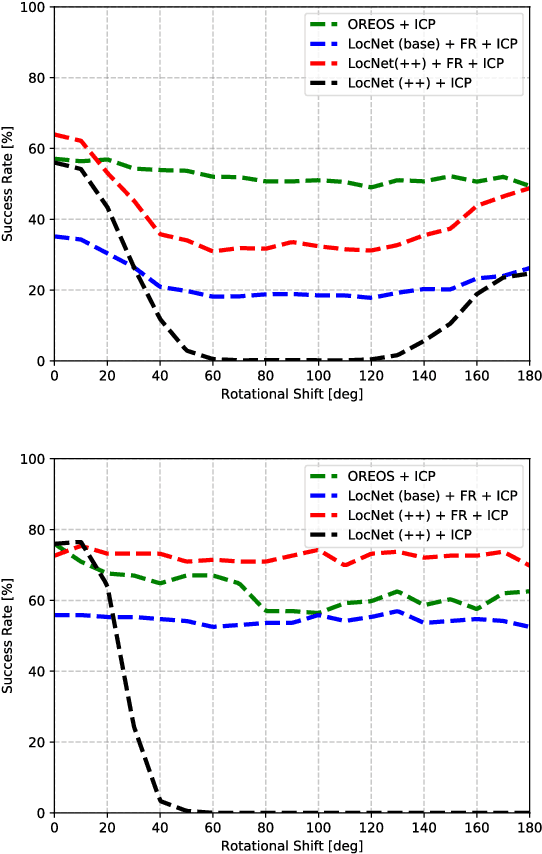
We introduce a novel method for oriented place recognition with 3D LiDAR scans. A Convolutional Neural Network is trained to extract compact descriptors from single 3D LiDAR scans. These can be used both to retrieve near-by place candidates from a map, and to estimate the yaw discrepancy needed for bootstrapping local registration methods. We employ a triplet loss function for training and use a hard-negative mining strategy to further increase the performance of our descriptor extractor. In an evaluation on the NCLT and KITTI datasets, we demonstrate that our method outperforms related state-of-the-art approaches based on both data-driven and handcrafted data representation in challenging long-term outdoor conditions.
AgriColMap: Aerial-Ground Collaborative 3D Mapping for Precision Farming
Mar 14, 2019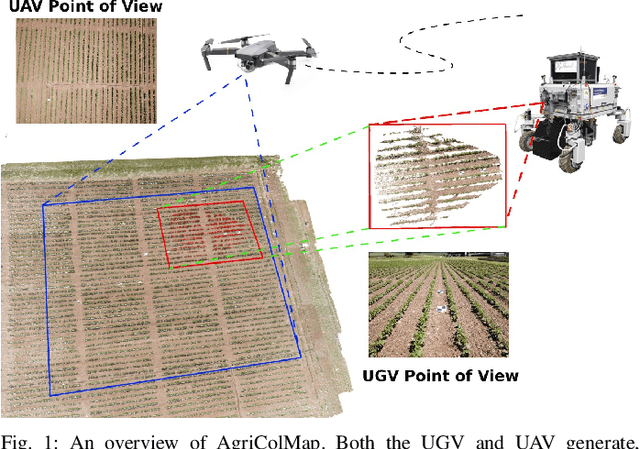

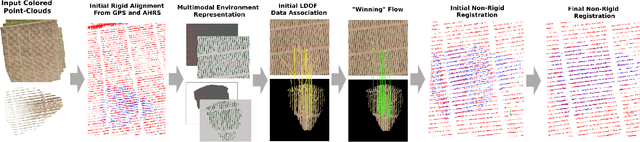
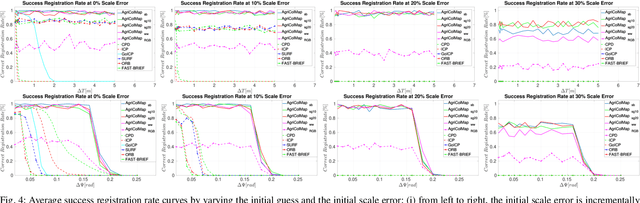
The combination of aerial survey capabilities of Unmanned Aerial Vehicles with targeted intervention abilities of agricultural Unmanned Ground Vehicles can significantly improve the effectiveness of robotic systems applied to precision agriculture. In this context, building and updating a common map of the field is an essential but challenging task. The maps built using robots of different types show differences in size, resolution and scale, the associated geolocation data may be inaccurate and biased, while the repetitiveness of both visual appearance and geometric structures found within agricultural contexts render classical map merging techniques ineffective. In this paper we propose AgriColMap, a novel map registration pipeline that leverages a grid-based multimodal environment representation which includes a vegetation index map and a Digital Surface Model. We cast the data association problem between maps built from UAVs and UGVs as a multimodal, large displacement dense optical flow estimation. The dominant, coherent flows, selected using a voting scheme, are used as point-to-point correspondences to infer a preliminary non-rigid alignment between the maps. A final refinement is then performed, by exploiting only meaningful parts of the registered maps. We evaluate our system using real world data for 3 fields with different crop species. The results show that our method outperforms several state of the art map registration and matching techniques by a large margin, and has a higher tolerance to large initial misalignments. We release an implementation of the proposed approach along with the acquired datasets with this paper.
* Published in IEEE Robotics and Automation Letters, 2019
Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery
Mar 01, 2019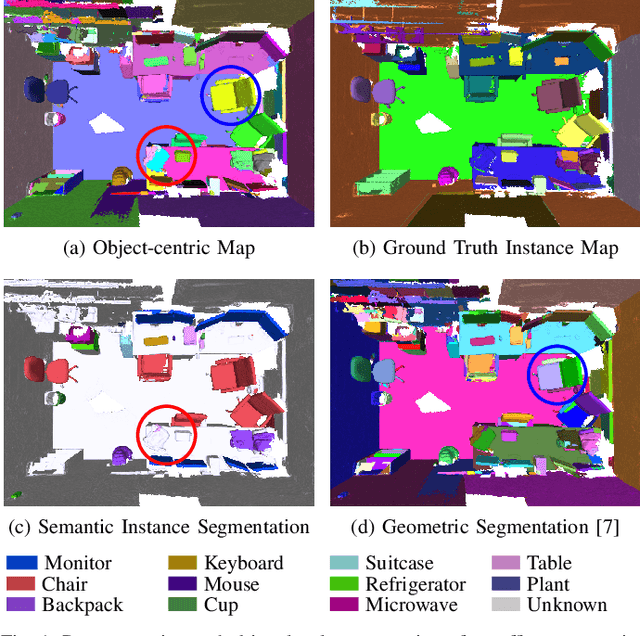
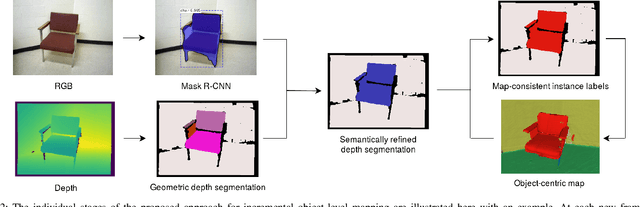


To autonomously navigate and plan interactions in real-world environments, robots require the ability to robustly perceive and map complex, unstructured surrounding scenes. Besides building an internal representation of the observed scene geometry, the key insight towards a truly functional understanding of the environment is the usage of higher-level entities during mapping, such as individual object instances. We propose an approach to incrementally build volumetric object-centric maps during online scanning with a localized RGB-D camera. First, a per-frame segmentation scheme combines an unsupervised geometric approach with instance-aware semantic object predictions. This allows us to detect and segment elements both from the set of known classes and from other, previously unseen categories. Next, a data association step tracks the predicted instances across the different frames. Finally, a map integration strategy fuses information about their 3D shape, location, and, if available, semantic class into a global volume. Evaluation on a publicly available dataset shows that the proposed approach for building instance-level semantic maps is competitive with state-of-the-art methods, while additionally able to discover objects of unseen categories. The system is further evaluated within a real-world robotic mapping setup, for which qualitative results highlight the online nature of the method.
Obstacle-aware Adaptive Informative Path Planning for UAV-based Target Search
Feb 26, 2019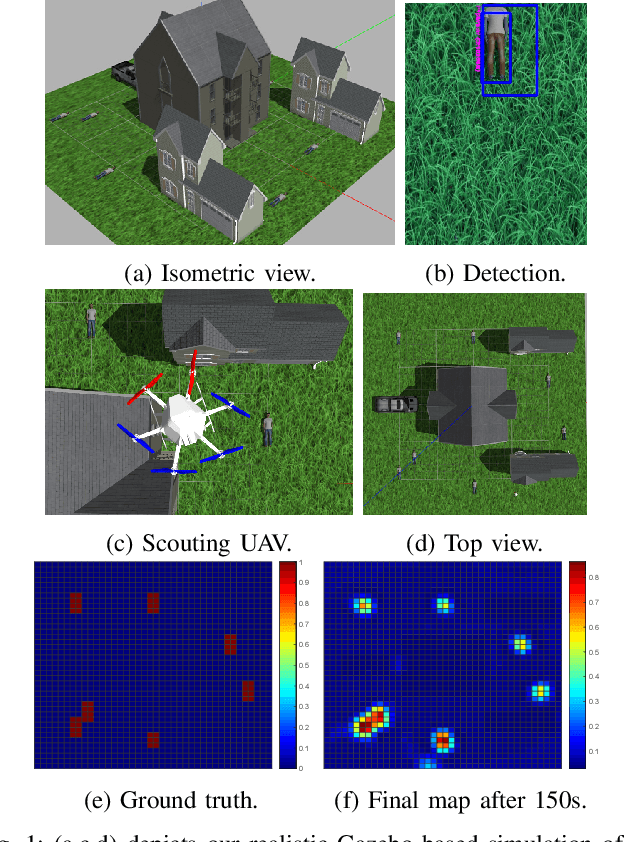

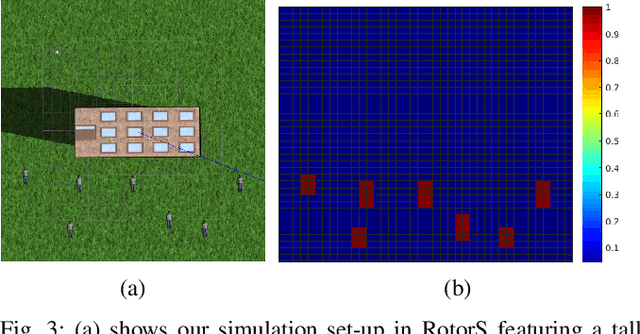
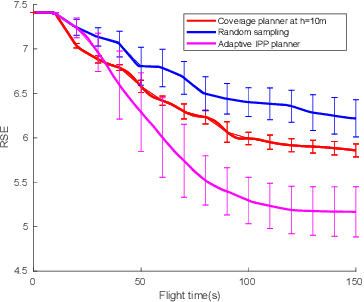
Target search with unmanned aerial vehicles (UAVs) is relevant problem to many scenarios, e.g., search and rescue (SaR). However, a key challenge is planning paths for maximal search efficiency given flight time constraints. To address this, we propose the Obstacle-aware Adaptive Informative Path Planning (OA-IPP) algorithm for target search in cluttered environments using UAVs. Our approach leverages a layered planning strategy using a Gaussian Process (GP)-based model of target occupancy to generate informative paths in continuous 3D space. Within this framework, we introduce an adaptive replanning scheme which allows us to trade off between information gain, field coverage, sensor performance, and collision avoidance for efficient target detection. Extensive simulations show that our OA-IPP method performs better than state-of-the-art planners, and we demonstrate its application in a realistic urban SaR scenario.
Informative Path Planning and Mapping for Active Sensing Under Localization Uncertainty
Feb 25, 2019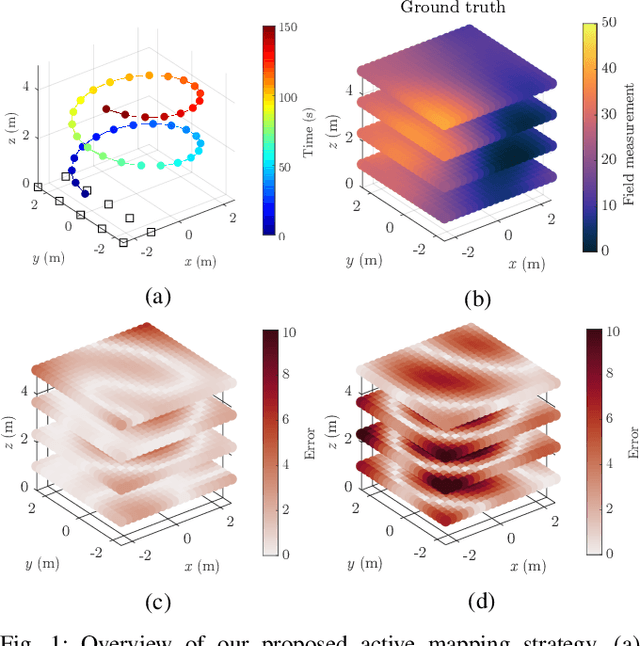
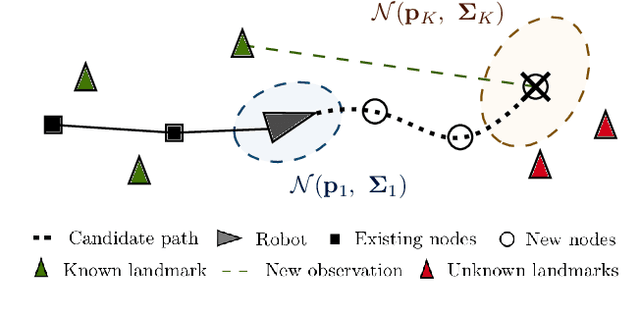
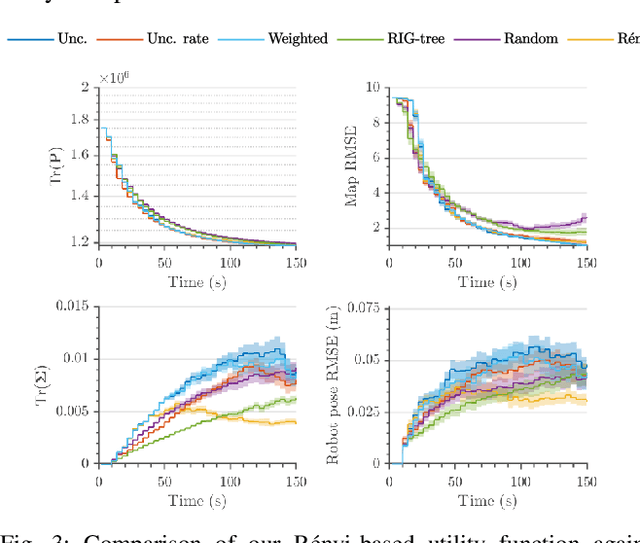
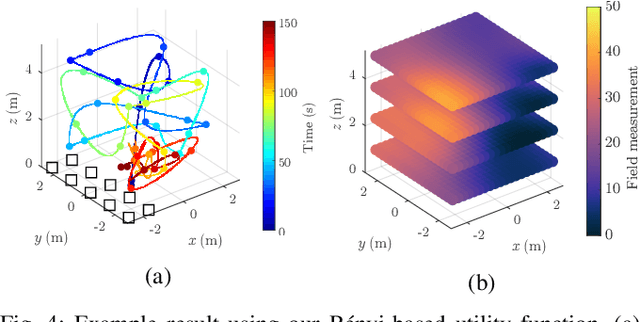
Robotic platforms are emerging as a timely and cost-efficient tool for exploration and monitoring. However, an open challenge is planning missions for robust, efficient data acquisition in complex environments. To address this issue, we introduce an informative planning framework for active sensing scenarios that accounts for the robot pose uncertainty. Our strategy exploits a Gaussian Process model to capture a target environmental field given the uncertainty on its inputs. This allows us to maintain robust maps, which are used for planning information-rich trajectories in continuous space. A key aspect of our method is a new utility function that couples the localization and field mapping objectives, enabling us to trade-off exploration against exploitation in a principled way. Extensive simulations show that our approach outperforms existing strategies, with reductions of up to 45.1% and 6.3% in mean pose uncertainty and map error. We demonstrate a proof of concept in an indoor temperature mapping scenario.
VIZARD: Reliable Visual Localization for Autonomous Vehicles in Urban Outdoor Environments
Feb 12, 2019
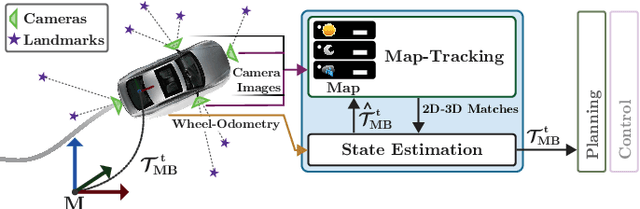
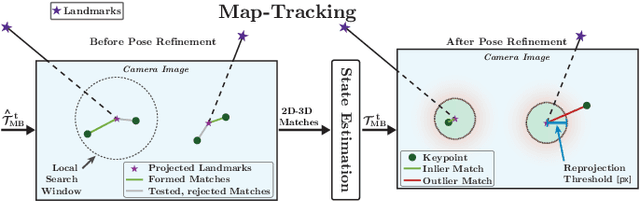
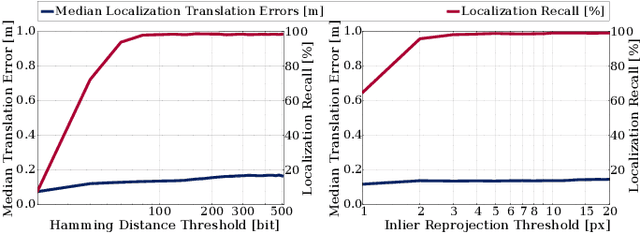
Changes in appearance is one of the main sources of failure in visual localization systems in outdoor environments. To address this challenge, we present VIZARD, a visual localization system for urban outdoor environments. By combining a local localization algorithm with the use of multi-session maps, a high localization recall can be achieved across vastly different appearance conditions. The fusion of the visual localization constraints with wheel-odometry in a state estimation framework further guarantees smooth and accurate pose estimates. In an extensive experimental evaluation on several hundreds of driving kilometers in challenging urban outdoor environments, we analyze the recall and accuracy of our localization system, investigate its key parameters and boundary conditions, and compare different types of feature descriptors. Our results show that VIZARD is able to achieve nearly 100% recall with a localization accuracy below 0.5m under varying outdoor appearance conditions, including at night-time.
Comparing Task Simplifications to Learn Closed-Loop Object Picking Using Deep Reinforcement Learning
Jan 31, 2019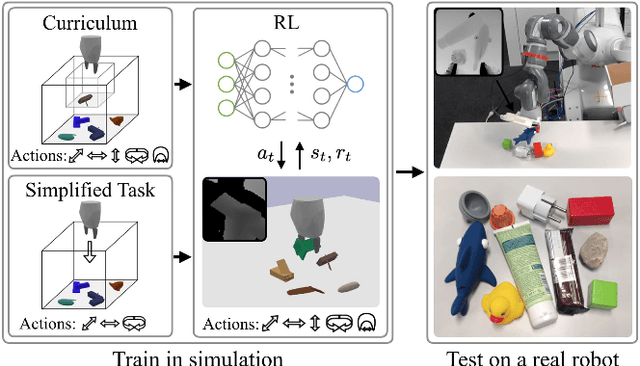
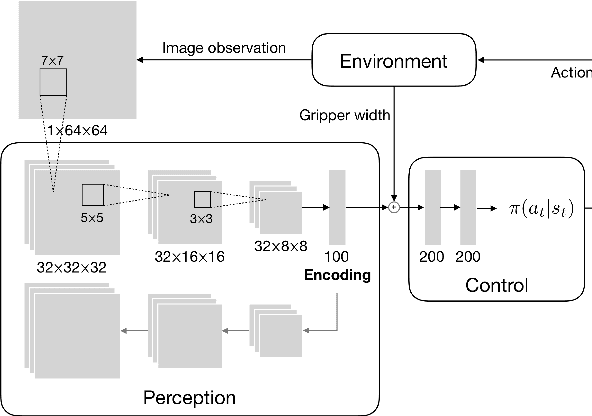

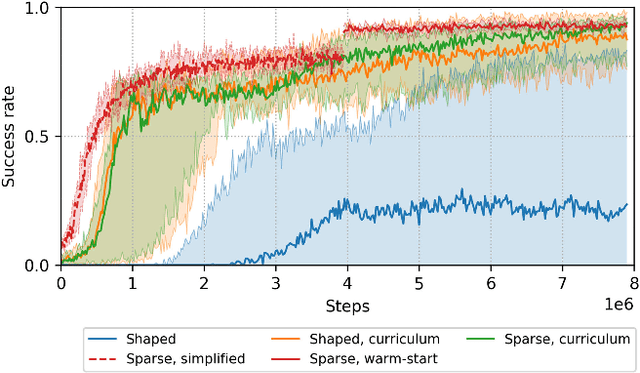
Enabling autonomous robots to interact in unstructured environments with dynamic objects requires manipulation capabilities that can deal with clutter, changes, and objects' variability. This paper presents a comparison of different reinforcement learning-based approaches for object picking with a robotic manipulator. We learn closed-loop policies mapping depth camera inputs to motion commands and compare different approaches to keep the problem tractable, including reward shaping, curriculum learning and using a policy pre-trained on a task with a reduced action set to warm-start the full problem. For efficient and more flexible data collection, we train in simulation and transfer the policies to a real robot. We show that using curriculum learning, policies learned with a sparse reward formulation can be trained at similar rates as with a shaped reward. These policies result in success rates comparable to the policy initialized on the simplified task. We could successfully transfer these policies to the real robot with only minor modifications of the depth image filtering. We found that using a heuristic to warm-start the training was useful to enforce desired behavior, while the policies trained from scratch using a curriculum learned better to cope with unseen scenarios where objects are removed.