 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn the Eye of the Beholder: Robust Prediction with Causal User Modeling
Jun 01, 2022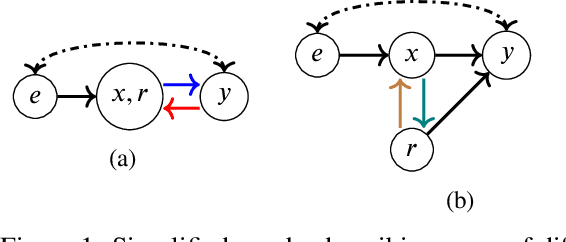

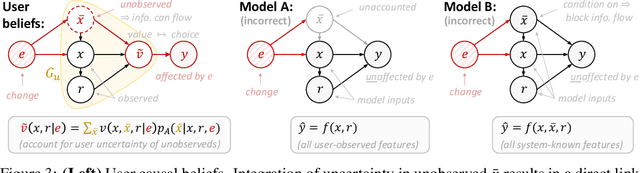
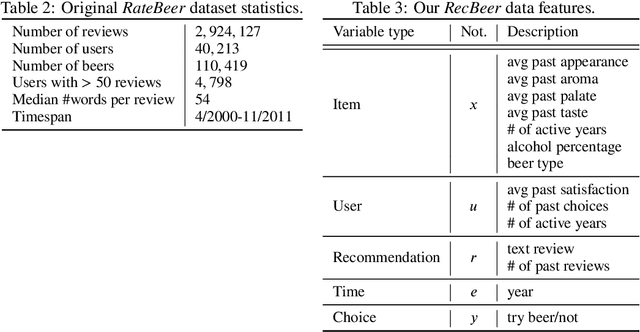
Accurately predicting the relevance of items to users is crucial to the success of many social platforms. Conventional approaches train models on logged historical data; but recommendation systems, media services, and online marketplaces all exhibit a constant influx of new content -- making relevancy a moving target, to which standard predictive models are not robust. In this paper, we propose a learning framework for relevance prediction that is robust to changes in the data distribution. Our key observation is that robustness can be obtained by accounting for how users causally perceive the environment. We model users as boundedly-rational decision makers whose causal beliefs are encoded by a causal graph, and show how minimal information regarding the graph can be used to contend with distributional changes. Experiments in multiple settings demonstrate the effectiveness of our approach.
CEBaB: Estimating the Causal Effects of Real-World Concepts on NLP Model Behavior
May 27, 2022
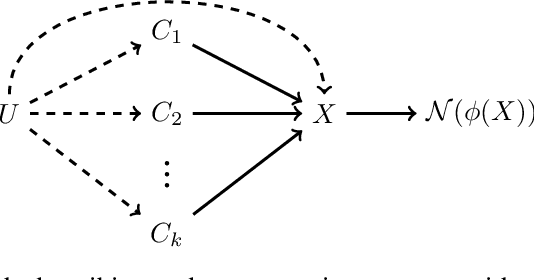

The increasing size and complexity of modern ML systems has improved their predictive capabilities but made their behavior harder to explain. Many techniques for model explanation have been developed in response, but we lack clear criteria for assessing these techniques. In this paper, we cast model explanation as the causal inference problem of estimating causal effects of real-world concepts on the output behavior of ML models given actual input data. We introduce CEBaB, a new benchmark dataset for assessing concept-based explanation methods in Natural Language Processing (NLP). CEBaB consists of short restaurant reviews with human-generated counterfactual reviews in which an aspect (food, noise, ambiance, service) of the dining experience was modified. Original and counterfactual reviews are annotated with multiply-validated sentiment ratings at the aspect-level and review-level. The rich structure of CEBaB allows us to go beyond input features to study the effects of abstract, real-world concepts on model behavior. We use CEBaB to compare the quality of a range of concept-based explanation methods covering different assumptions and conceptions of the problem, and we seek to establish natural metrics for comparative assessments of these methods.
Learning Discrete Structured Variational Auto-Encoder using Natural Evolution Strategies
May 03, 2022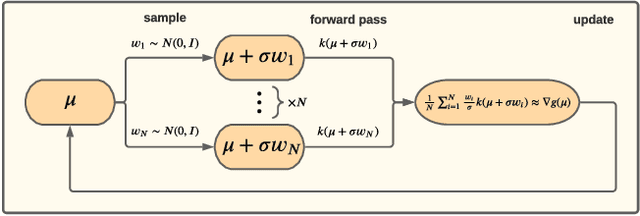
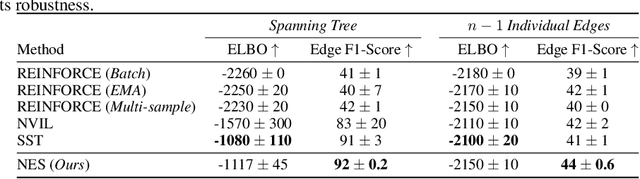

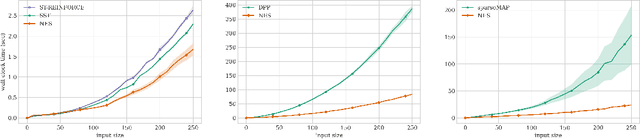
Discrete variational auto-encoders (VAEs) are able to represent semantic latent spaces in generative learning. In many real-life settings, the discrete latent space consists of high-dimensional structures, and propagating gradients through the relevant structures often requires enumerating over an exponentially large latent space. Recently, various approaches were devised to propagate approximated gradients without enumerating over the space of possible structures. In this work, we use Natural Evolution Strategies (NES), a class of gradient-free black-box optimization algorithms, to learn discrete structured VAEs. The NES algorithms are computationally appealing as they estimate gradients with forward pass evaluations only, thus they do not require to propagate gradients through their discrete structures. We demonstrate empirically that optimizing discrete structured VAEs using NES is as effective as gradient-based approximations. Lastly, we prove NES converges for non-Lipschitz functions as appear in discrete structured VAEs.
Example-based Hypernetworks for Out-of-Distribution Generalization
Apr 02, 2022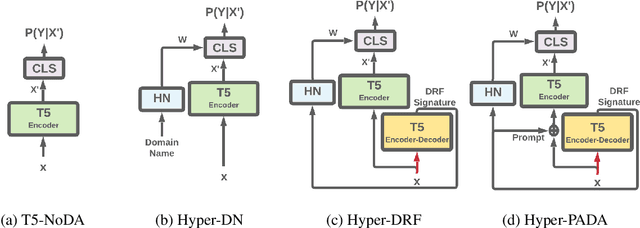

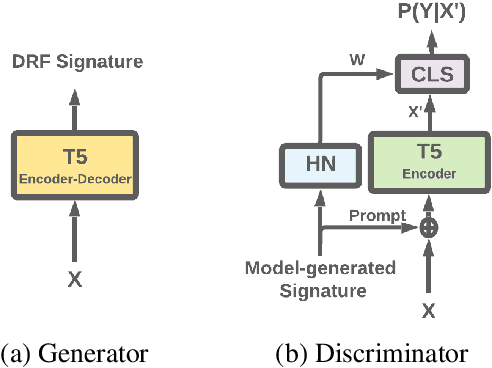

While Natural Language Processing (NLP) algorithms keep reaching unprecedented milestones, out-of-distribution generalization is still challenging. In this paper we address the problem of multi-source adaptation to unknown domains: Given labeled data from multiple source domains, we aim to generalize to data drawn from target domains that are unknown to the algorithm at training time. We present an algorithmic framework based on example-based Hypernetwork adaptation: Given an input example, a T5 encoder-decoder first generates a unique signature which embeds this example in the semantic space of the source domains, and this signature is then fed into a Hypernetwork which generates the weights of the task classifier. In an advanced version of our model, the learned signature also serves for improving the representation of the input example. In experiments with two tasks, sentiment classification and natural language inference, across 29 adaptation settings, our algorithms substantially outperform existing algorithms for this adaptation setup. To the best of our knowledge, this is the first time Hypernetworks are applied to domain adaptation or in example-based manner in NLP.
DoCoGen: Domain Counterfactual Generation for Low Resource Domain Adaptation
Mar 05, 2022
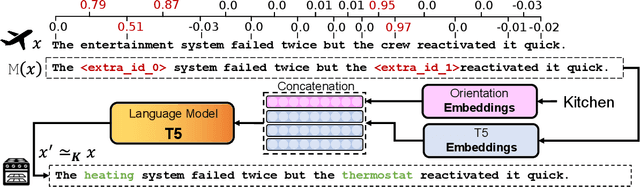
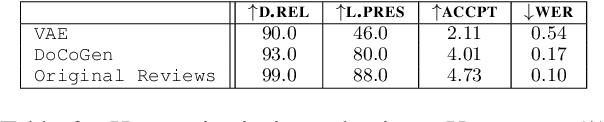
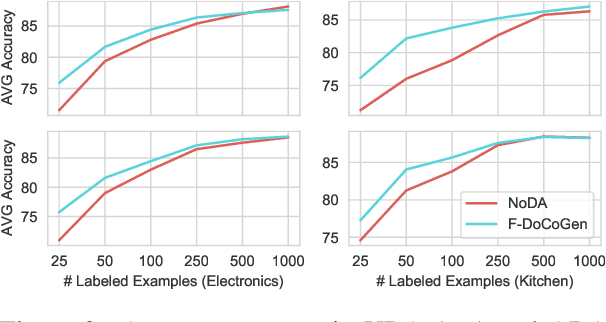
Natural language processing (NLP) algorithms have become very successful, but they still struggle when applied to out-of-distribution examples. In this paper we propose a controllable generation approach in order to deal with this domain adaptation (DA) challenge. Given an input text example, our DoCoGen algorithm generates a domain-counterfactual textual example (D-con) - that is similar to the original in all aspects, including the task label, but its domain is changed to a desired one. Importantly, DoCoGen is trained using only unlabeled examples from multiple domains - no NLP task labels or parallel pairs of textual examples and their domain-counterfactuals are required. We show that DoCoGen can generate coherent counterfactuals consisting of multiple sentences. We use the D-cons generated by DoCoGen to augment a sentiment classifier and a multi-label intent classifier in 20 and 78 DA setups, respectively, where source-domain labeled data is scarce. Our model outperforms strong baselines and improves the accuracy of a state-of-the-art unsupervised DA algorithm.
Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond
Sep 02, 2021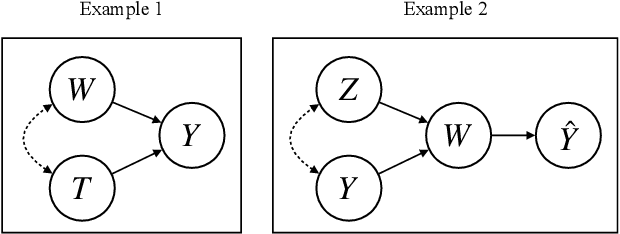
A fundamental goal of scientific research is to learn about causal relationships. However, despite its critical role in the life and social sciences, causality has not had the same importance in Natural Language Processing (NLP), which has traditionally placed more emphasis on predictive tasks. This distinction is beginning to fade, with an emerging area of interdisciplinary research at the convergence of causal inference and language processing. Still, research on causality in NLP remains scattered across domains without unified definitions, benchmark datasets and clear articulations of the remaining challenges. In this survey, we consolidate research across academic areas and situate it in the broader NLP landscape. We introduce the statistical challenge of estimating causal effects, encompassing settings where text is used as an outcome, treatment, or as a means to address confounding. In addition, we explore potential uses of causal inference to improve the performance, robustness, fairness, and interpretability of NLP models. We thus provide a unified overview of causal inference for the computational linguistics community.
DILBERT: Customized Pre-Training for Domain Adaptation withCategory Shift, with an Application to Aspect Extraction
Sep 01, 2021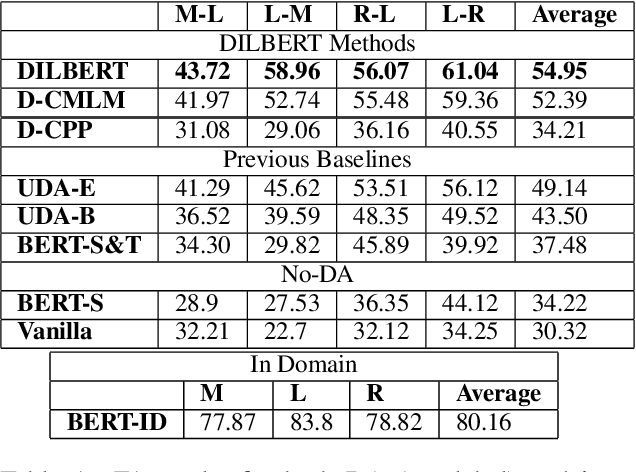
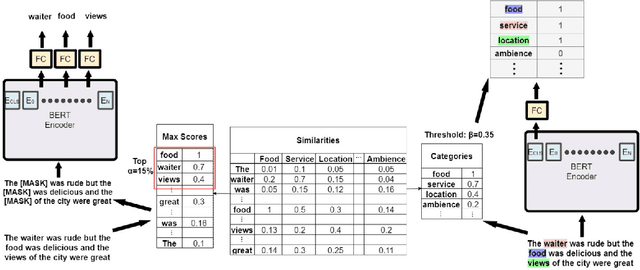
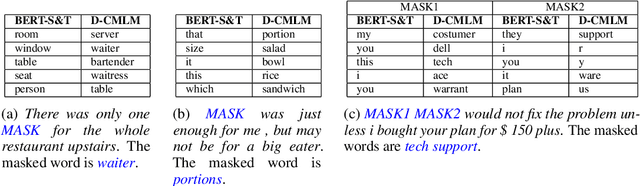
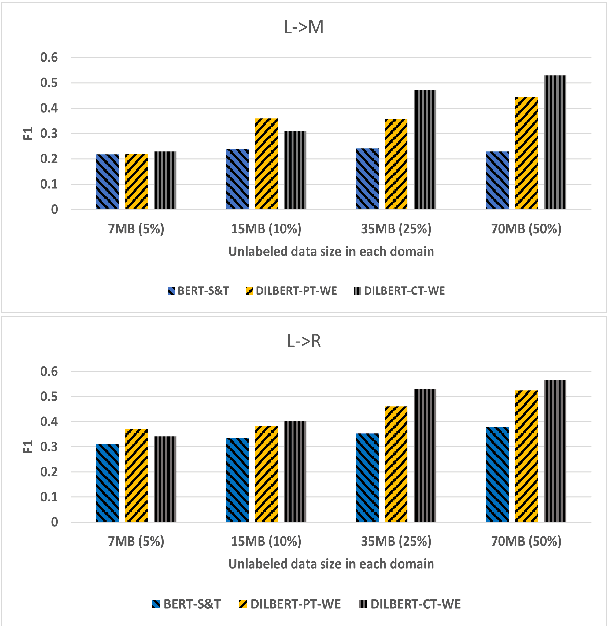
The rise of pre-trained language models has yielded substantial progress in the vast majority of Natural Language Processing (NLP) tasks. However, a generic approach towards the pre-training procedure can naturally be sub-optimal in some cases. Particularly, fine-tuning a pre-trained language model on a source domain and then applying it to a different target domain, results in a sharp performance decline of the eventual classifier for many source-target domain pairs. Moreover, in some NLP tasks, the output categories substantially differ between domains, making adaptation even more challenging. This, for example, happens in the task of aspect extraction, where the aspects of interest of reviews of, e.g., restaurants or electronic devices may be very different. This paper presents a new fine-tuning scheme for BERT, which aims to address the above challenges. We name this scheme DILBERT: Domain Invariant Learning with BERT, and customize it for aspect extraction in the unsupervised domain adaptation setting. DILBERT harnesses the categorical information of both the source and the target domains to guide the pre-training process towards a more domain and category invariant representation, thus closing the gap between the domains. We show that DILBERT yields substantial improvements over state-of-the-art baselines while using a fraction of the unlabeled data, particularly in more challenging domain adaptation setups.
Towards Zero-shot Language Modeling
Aug 06, 2021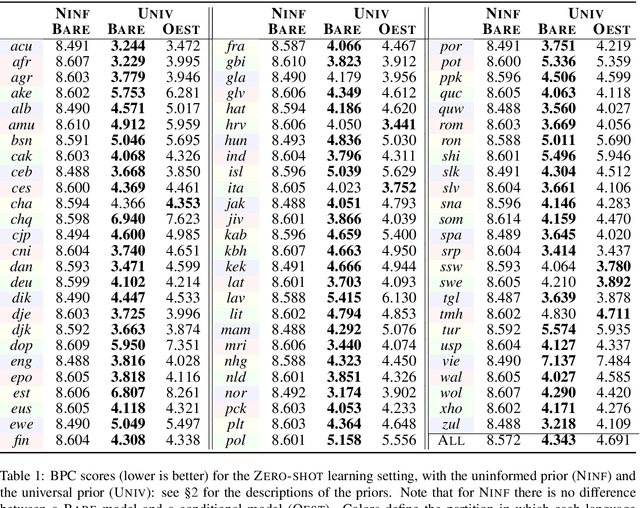
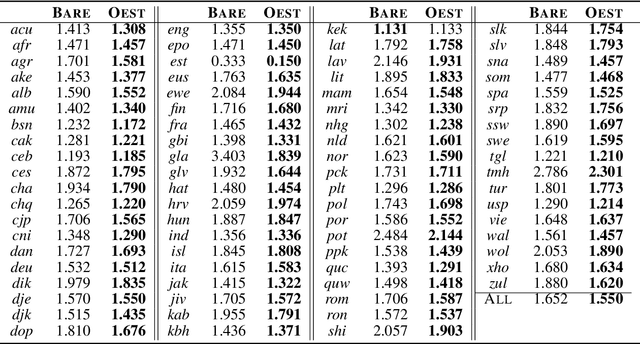
Can we construct a neural model that is inductively biased towards learning human languages? Motivated by this question, we aim at constructing an informative prior over neural weights, in order to adapt quickly to held-out languages in the task of character-level language modeling. We infer this distribution from a sample of typologically diverse training languages via Laplace approximation. The use of such a prior outperforms baseline models with an uninformative prior (so-called "fine-tuning") in both zero-shot and few-shot settings. This shows that the prior is imbued with universal phonological knowledge. Moreover, we harness additional language-specific side information as distant supervision for held-out languages. Specifically, we condition language models on features from typological databases, by concatenating them to hidden states or generating weights with hyper-networks. These features appear beneficial in the few-shot setting, but not in the zero-shot setting. Since the paucity of digital texts affects the majority of the world's languages, we hope that these findings will help broaden the scope of applications for language technology.
Are VQA Systems RAD? Measuring Robustness to Augmented Data with Focused Interventions
Jun 08, 2021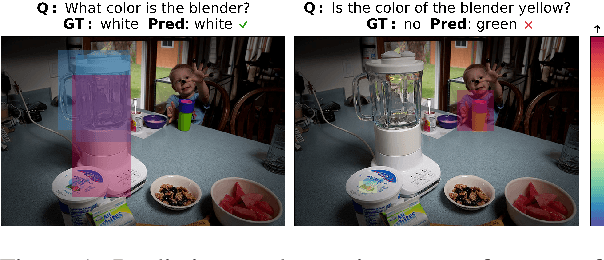

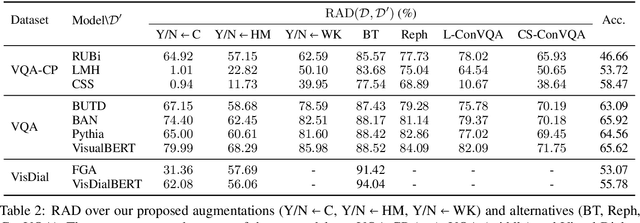
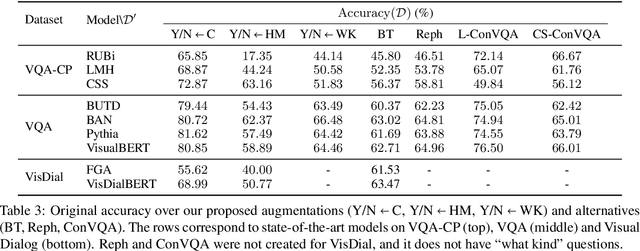
Deep learning algorithms have shown promising results in visual question answering (VQA) tasks, but a more careful look reveals that they often do not understand the rich signal they are being fed with. To understand and better measure the generalization capabilities of VQA systems, we look at their robustness to counterfactually augmented data. Our proposed augmentations are designed to make a focused intervention on a specific property of the question such that the answer changes. Using these augmentations, we propose a new robustness measure, Robustness to Augmented Data (RAD), which measures the consistency of model predictions between original and augmented examples. Through extensive experimentation, we show that RAD, unlike classical accuracy measures, can quantify when state-of-the-art systems are not robust to counterfactuals. We find substantial failure cases which reveal that current VQA systems are still brittle. Finally, we connect between robustness and generalization, demonstrating the predictive power of RAD for performance on unseen augmentations.
Designing an Automatic Agent for Repeated Language based Persuasion Games
May 11, 2021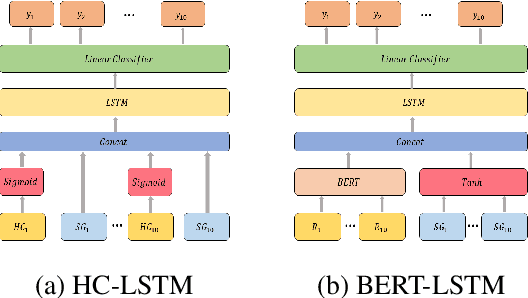
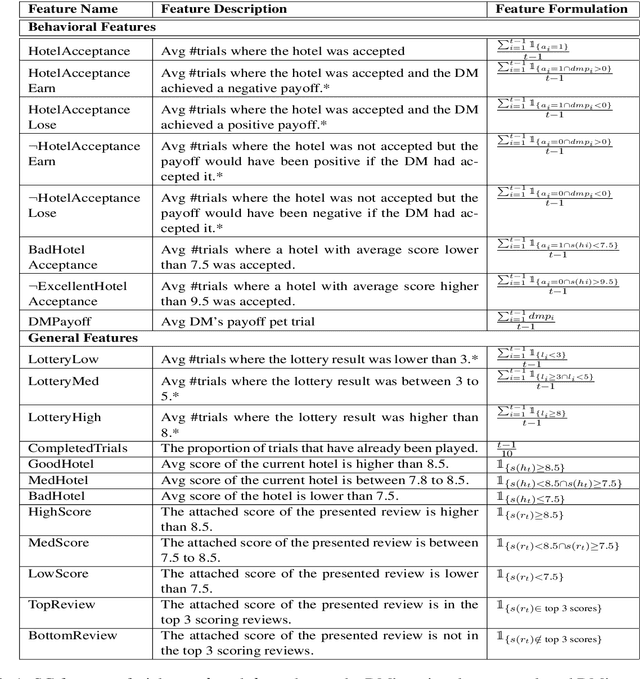
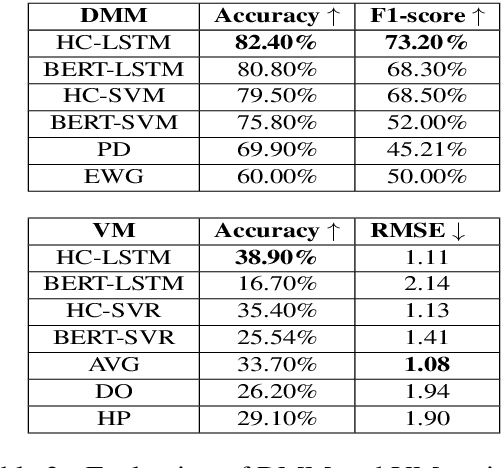
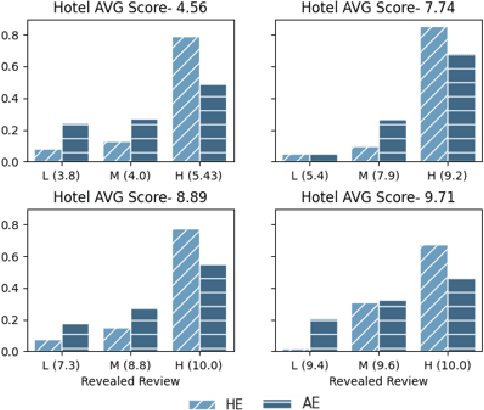
Persuasion games are fundamental in economics and AI research and serve as the basis for important applications. However, work on this setup assumes communication with stylized messages that do not consist of rich human language. In this paper we consider a repeated sender (expert) -- receiver (decision maker) game, where the sender is fully informed about the state of the world and aims to persuade the receiver to accept a deal by sending one of several possible natural language reviews. We design an automatic expert that plays this repeated game, aiming to achieve the maximal payoff. Our expert is implemented within the Monte Carlo Tree Search (MCTS) algorithm, with deep learning models that exploit behavioral and linguistic signals in order to predict the next action of the decision maker, and the future payoff of the expert given the state of the game and a candidate review. We demonstrate the superiority of our expert over strong baselines, its adaptability to different decision makers, and that its selected reviews are nicely adapted to the proposed deal.