 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveRAG: A diverse Q&A dataset with varying difficulty level for RAG evaluation
Nov 18, 2025



With Retrieval Augmented Generation (RAG) becoming more and more prominent in generative AI solutions, there is an emerging need for systematically evaluating their effectiveness. We introduce the LiveRAG benchmark, a publicly available dataset of 895 synthetic questions and answers designed to support systematic evaluation of RAG-based Q&A systems. This synthetic benchmark is derived from the one used during the SIGIR'2025 LiveRAG Challenge, where competitors were evaluated under strict time constraints. It is augmented with information that was not made available to competitors during the Challenge, such as the ground-truth answers, together with their associated supporting claims which were used for evaluating competitors' answers. In addition, each question is associated with estimated difficulty and discriminability scores, derived from applying an Item Response Theory model to competitors' responses. Our analysis highlights the benchmark's questions diversity, the wide range of their difficulty levels, and their usefulness in differentiating between system capabilities. The LiveRAG benchmark will hopefully help the community advance RAG research, conduct systematic evaluation, and develop more robust Q&A systems.
Do RAG Systems Suffer From Positional Bias?
May 21, 2025Retrieval Augmented Generation enhances LLM accuracy by adding passages retrieved from an external corpus to the LLM prompt. This paper investigates how positional bias - the tendency of LLMs to weight information differently based on its position in the prompt - affects not only the LLM's capability to capitalize on relevant passages, but also its susceptibility to distracting passages. Through extensive experiments on three benchmarks, we show how state-of-the-art retrieval pipelines, while attempting to retrieve relevant passages, systematically bring highly distracting ones to the top ranks, with over 60% of queries containing at least one highly distracting passage among the top-10 retrieved passages. As a result, the impact of the LLM positional bias, which in controlled settings is often reported as very prominent by related works, is actually marginal in real scenarios since both relevant and distracting passages are, in turn, penalized. Indeed, our findings reveal that sophisticated strategies that attempt to rearrange the passages based on LLM positional preferences do not perform better than random shuffling.
Classification Under Strategic Self-Selection
Feb 23, 2024



When users stand to gain from certain predictions, they are prone to act strategically to obtain favorable predictive outcomes. Whereas most works on strategic classification consider user actions that manifest as feature modifications, we study a novel setting in which users decide -- in response to the learned classifier -- whether to at all participate (or not). For learning approaches of increasing strategic awareness, we study the effects of self-selection on learning, and the implications of learning on the composition of the self-selected population. We then propose a differentiable framework for learning under self-selective behavior, which can be optimized effectively. We conclude with experiments on real data and simulated behavior that both complement our analysis and demonstrate the utility of our approach.
Consistent Text Categorization using Data Augmentation in e-Commerce
May 09, 2023The categorization of massive e-Commerce data is a crucial, well-studied task, which is prevalent in industrial settings. In this work, we aim to improve an existing product categorization model that is already in use by a major web company, serving multiple applications. At its core, the product categorization model is a text classification model that takes a product title as an input and outputs the most suitable category out of thousands of available candidates. Upon a closer inspection, we found inconsistencies in the labeling of similar items. For example, minor modifications of the product title pertaining to colors or measurements majorly impacted the model's output. This phenomenon can negatively affect downstream recommendation or search applications, leading to a sub-optimal user experience. To address this issue, we propose a new framework for consistent text categorization. Our goal is to improve the model's consistency while maintaining its production-level performance. We use a semi-supervised approach for data augmentation and presents two different methods for utilizing unlabeled samples. One method relies directly on existing catalogs, while the other uses a generative model. We compare the pros and cons of each approach and present our experimental results.
Causal Strategic Classification: A Tale of Two Shifts
Feb 13, 2023When users can benefit from certain predictive outcomes, they may be prone to act to achieve those outcome, e.g., by strategically modifying their features. The goal in strategic classification is therefore to train predictive models that are robust to such behavior. However, the conventional framework assumes that changing features does not change actual outcomes, which depicts users as "gaming" the system. Here we remove this assumption, and study learning in a causal strategic setting where true outcomes do change. Focusing on accuracy as our primary objective, we show how strategic behavior and causal effects underlie two complementing forms of distribution shift. We characterize these shifts, and propose a learning algorithm that balances between these two forces and over time, and permits end-to-end training. Experiments on synthetic and semi-synthetic data demonstrate the utility of our approach.
In the Eye of the Beholder: Robust Prediction with Causal User Modeling
Jun 01, 2022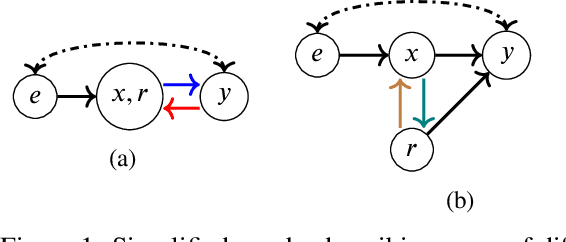

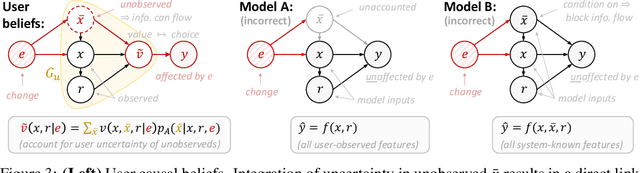
Accurately predicting the relevance of items to users is crucial to the success of many social platforms. Conventional approaches train models on logged historical data; but recommendation systems, media services, and online marketplaces all exhibit a constant influx of new content -- making relevancy a moving target, to which standard predictive models are not robust. In this paper, we propose a learning framework for relevance prediction that is robust to changes in the data distribution. Our key observation is that robustness can be obtained by accounting for how users causally perceive the environment. We model users as boundedly-rational decision makers whose causal beliefs are encoded by a causal graph, and show how minimal information regarding the graph can be used to contend with distributional changes. Experiments in multiple settings demonstrate the effectiveness of our approach.