 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Image Programs for Representation Learning
Nov 29, 2022



Learning image representations using synthetic data allows training neural networks without some of the concerns associated with real images, such as privacy and bias. Existing work focuses on a handful of curated generative processes which require expert knowledge to design, making it hard to scale up. To overcome this, we propose training with a large dataset of twenty-one thousand programs, each one generating a diverse set of synthetic images. These programs are short code snippets, which are easy to modify and fast to execute using OpenGL. The proposed dataset can be used for both supervised and unsupervised representation learning, and reduces the gap between pre-training with real and procedurally generated images by 38%.
* 29 pages, Accepted in the Conference on Neural Information Processing Systems 2022 (NeurIPS 2022)
CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
Nov 23, 2022



Computer vision models suffer from a phenomenon known as catastrophic forgetting when learning novel concepts from continuously shifting training data. Typical solutions for this continual learning problem require extensive rehearsal of previously seen data, which increases memory costs and may violate data privacy. Recently, the emergence of large-scale pre-trained vision transformer models has enabled prompting approaches as an alternative to data-rehearsal. These approaches rely on a key-query mechanism to generate prompts and have been found to be highly resistant to catastrophic forgetting in the well-established rehearsal-free continual learning setting. However, the key mechanism of these methods is not trained end-to-end with the task sequence. Our experiments show that this leads to a reduction in their plasticity, hence sacrificing new task accuracy, and inability to benefit from expanded parameter capacity. We instead propose to learn a set of prompt components which are assembled with input-conditioned weights to produce input-conditioned prompts, resulting in a novel attention-based end-to-end key-query scheme. Our experiments show that we outperform the current SOTA method DualPrompt on established benchmarks by as much as 5.4% in average accuracy. We also outperform the state of art by as much as 6.6% accuracy on a continual learning benchmark which contains both class-incremental and domain-incremental task shifts, corresponding to many practical settings.
Teaching Structured Vision&Language Concepts to Vision&Language Models
Nov 21, 2022



Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, some aspects of complex language understanding still remain a challenge. We introduce the collective notion of Structured Vision&Language Concepts (SVLC) which includes object attributes, relations, and states which are present in the text and visible in the image. Recent studies have shown that even the best VL models struggle with SVLC. A possible way of fixing this issue is by collecting dedicated datasets for teaching each SVLC type, yet this might be expensive and time-consuming. Instead, we propose a more elegant data-driven approach for enhancing VL models' understanding of SVLCs that makes more effective use of existing VL pre-training datasets and does not require any additional data. While automatic understanding of image structure still remains largely unsolved, language structure is much better modeled and understood, allowing for its effective utilization in teaching VL models. In this paper, we propose various techniques based on language structure understanding that can be used to manipulate the textual part of off-the-shelf paired VL datasets. VL models trained with the updated data exhibit a significant improvement of up to 15% in their SVLC understanding with only a mild degradation in their zero-shot capabilities both when training from scratch or fine-tuning a pre-trained model.
ConStruct-VL: Data-Free Continual Structured VL Concepts Learning
Nov 17, 2022



Recently, large-scale pre-trained Vision-and-Language (VL) foundation models have demonstrated remarkable capabilities in many zero-shot downstream tasks, achieving competitive results for recognizing objects defined by as little as short text prompts. However, it has also been shown that VL models are still brittle in Structured VL Concept (SVLC) reasoning, such as the ability to recognize object attributes, states, and inter-object relations. This leads to reasoning mistakes, which need to be corrected as they occur by teaching VL models the missing SVLC skills; often this must be done using private data where the issue was found, which naturally leads to a data-free continual (no task-id) VL learning setting. In this work, we introduce the first Continual Data-Free Structured VL Concepts Learning (ConStruct-VL) benchmark and show it is challenging for many existing data-free CL strategies. We, therefore, propose a data-free method comprised of a new approach of Adversarial Pseudo-Replay (APR) which generates adversarial reminders of past tasks from past task models. To use this method efficiently, we also propose a continual parameter-efficient Layered-LoRA (LaLo) neural architecture allowing no-memory-cost access to all past models at train time. We show this approach outperforms all data-free methods by as much as ~7% while even matching some levels of experience-replay (prohibitive for applications where data-privacy must be preserved).
C2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Oct 07, 2022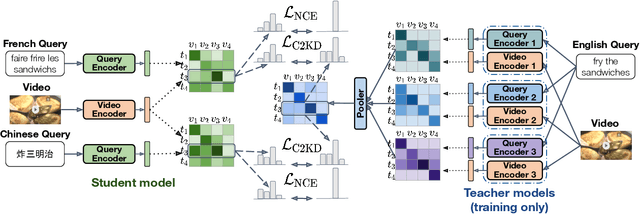
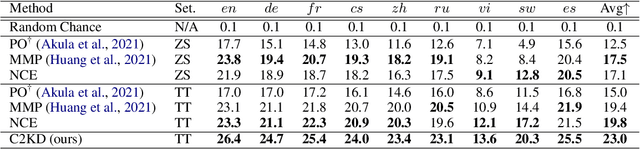

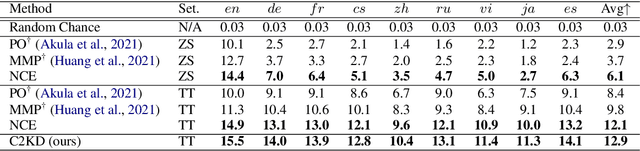
Multilingual text-video retrieval methods have improved significantly in recent years, but the performance for other languages lags behind English. We propose a Cross-Lingual Cross-Modal Knowledge Distillation method to improve multilingual text-video retrieval. Inspired by the fact that English text-video retrieval outperforms other languages, we train a student model using input text in different languages to match the cross-modal predictions from teacher models using input text in English. We propose a cross entropy based objective which forces the distribution over the student's text-video similarity scores to be similar to those of the teacher models. We introduce a new multilingual video dataset, Multi-YouCook2, by translating the English captions in the YouCook2 video dataset to 8 other languages. Our method improves multilingual text-video retrieval performance on Multi-YouCook2 and several other datasets such as Multi-MSRVTT and VATEX. We also conducted an analysis on the effectiveness of different multilingual text models as teachers.
FETA: Towards Specializing Foundation Models for Expert Task Applications
Sep 08, 2022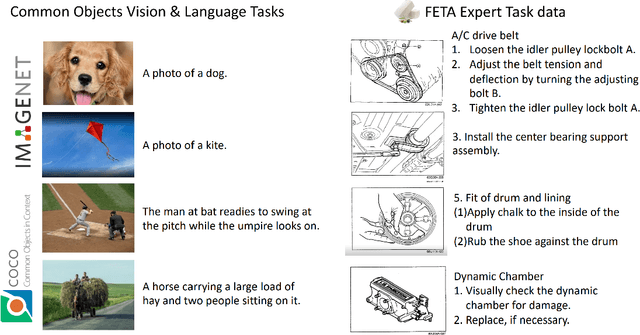

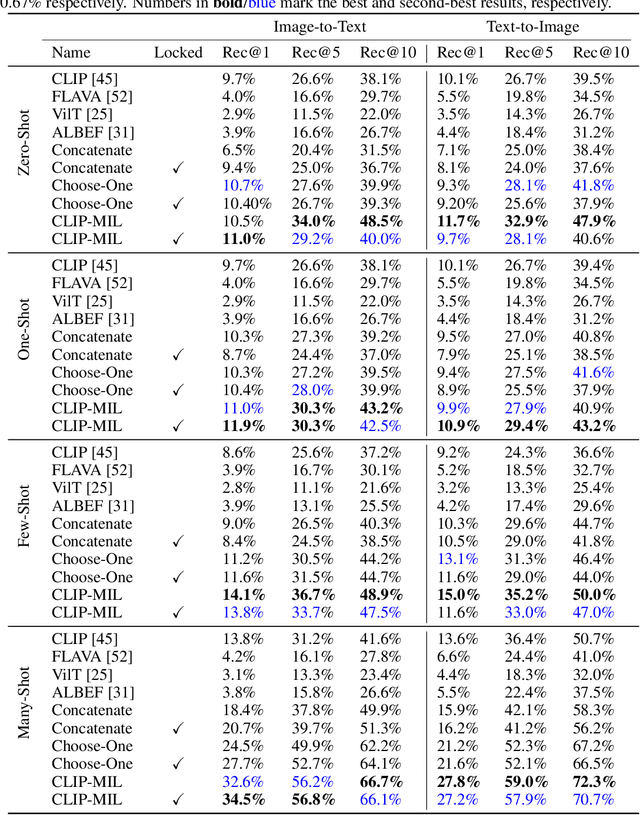
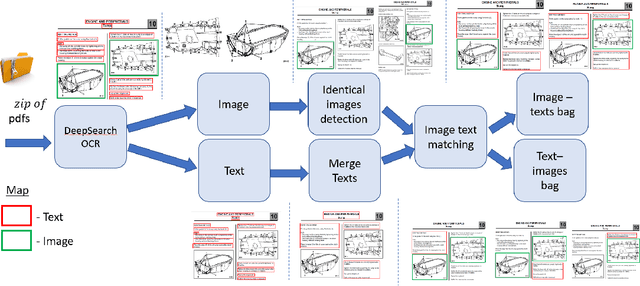
Foundation Models (FMs) have demonstrated unprecedented capabilities including zero-shot learning, high fidelity data synthesis, and out of domain generalization. However, as we show in this paper, FMs still have poor out-of-the-box performance on expert tasks (e.g. retrieval of car manuals technical illustrations from language queries), data for which is either unseen or belonging to a long-tail part of the data distribution of the huge datasets used for FM pre-training. This underlines the necessity to explicitly evaluate and finetune FMs on such expert tasks, arguably ones that appear the most in practical real-world applications. In this paper, we propose a first of its kind FETA benchmark built around the task of teaching FMs to understand technical documentation, via learning to match their graphical illustrations to corresponding language descriptions. Our FETA benchmark focuses on text-to-image and image-to-text retrieval in public car manuals and sales catalogue brochures. FETA is equipped with a procedure for completely automatic annotation extraction (code would be released upon acceptance), allowing easy extension of FETA to more documentation types and application domains in the future. Our automatic annotation leads to an automated performance metric shown to be consistent with metrics computed on human-curated annotations (also released). We provide multiple baselines and analysis of popular FMs on FETA leading to several interesting findings that we believe would be very valuable to the FM community, paving the way towards real-world application of FMs for practical expert tasks currently 'overlooked' by standard benchmarks focusing on common objects.
VALHALLA: Visual Hallucination for Machine Translation
May 31, 2022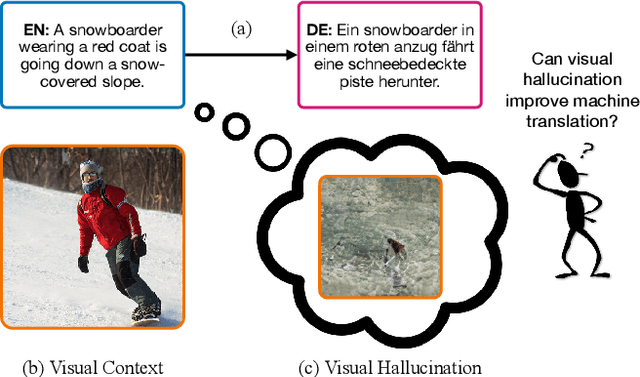
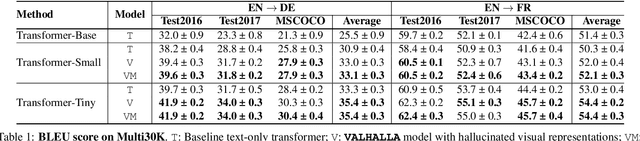
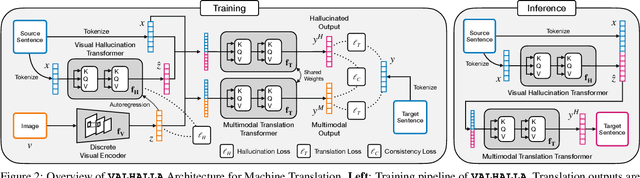
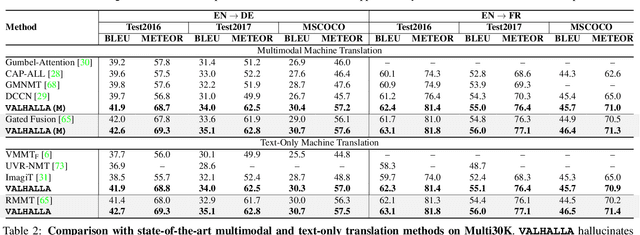
Designing better machine translation systems by considering auxiliary inputs such as images has attracted much attention in recent years. While existing methods show promising performance over the conventional text-only translation systems, they typically require paired text and image as input during inference, which limits their applicability to real-world scenarios. In this paper, we introduce a visual hallucination framework, called VALHALLA, which requires only source sentences at inference time and instead uses hallucinated visual representations for multimodal machine translation. In particular, given a source sentence an autoregressive hallucination transformer is used to predict a discrete visual representation from the input text, and the combined text and hallucinated representations are utilized to obtain the target translation. We train the hallucination transformer jointly with the translation transformer using standard backpropagation with cross-entropy losses while being guided by an additional loss that encourages consistency between predictions using either ground-truth or hallucinated visual representations. Extensive experiments on three standard translation datasets with a diverse set of language pairs demonstrate the effectiveness of our approach over both text-only baselines and state-of-the-art methods. Project page: http://www.svcl.ucsd.edu/projects/valhalla.
SimVQA: Exploring Simulated Environments for Visual Question Answering
Mar 31, 2022
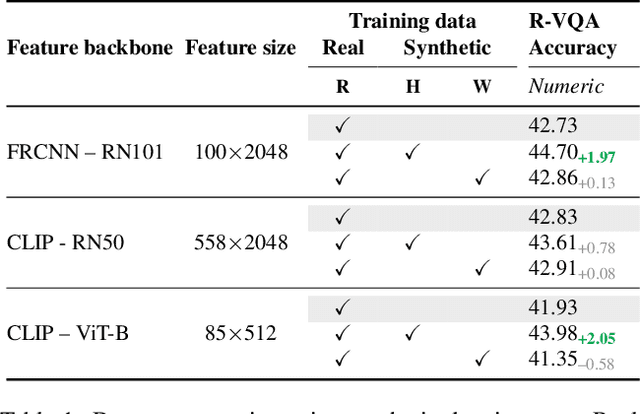
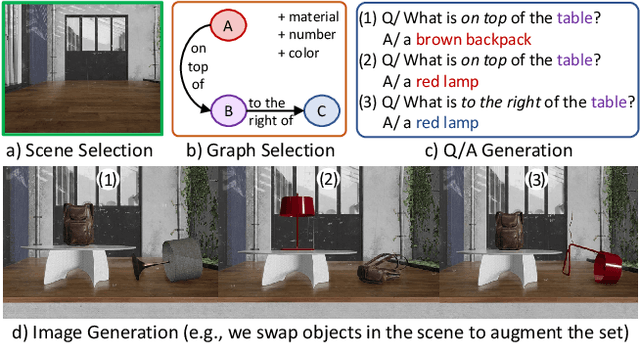
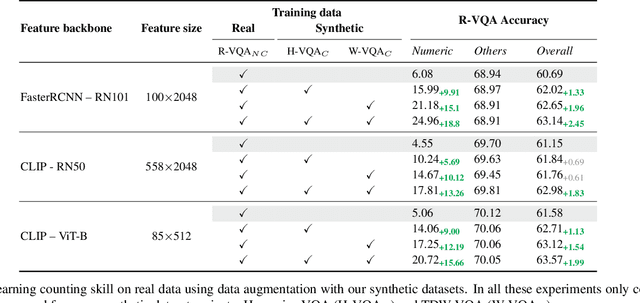
Existing work on VQA explores data augmentation to achieve better generalization by perturbing the images in the dataset or modifying the existing questions and answers. While these methods exhibit good performance, the diversity of the questions and answers are constrained by the available image set. In this work we explore using synthetic computer-generated data to fully control the visual and language space, allowing us to provide more diverse scenarios. We quantify the effect of synthetic data in real-world VQA benchmarks and to which extent it produces results that generalize to real data. By exploiting 3D and physics simulation platforms, we provide a pipeline to generate synthetic data to expand and replace type-specific questions and answers without risking the exposure of sensitive or personal data that might be present in real images. We offer a comprehensive analysis while expanding existing hyper-realistic datasets to be used for VQA. We also propose Feature Swapping (F-SWAP) -- where we randomly switch object-level features during training to make a VQA model more domain invariant. We show that F-SWAP is effective for enhancing a currently existing VQA dataset of real images without compromising on the accuracy to answer existing questions in the dataset.
Everything at Once -- Multi-modal Fusion Transformer for Video Retrieval
Dec 08, 2021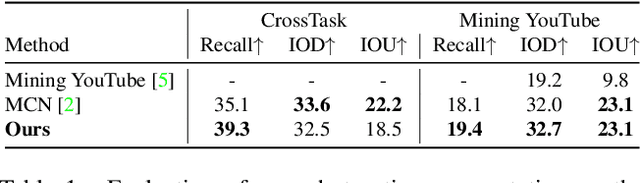

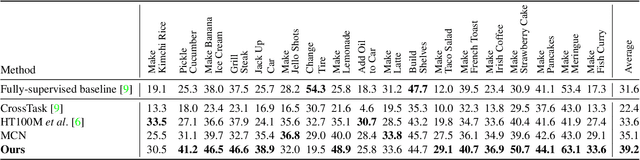
Multi-modal learning from video data has seen increased attention recently as it allows to train semantically meaningful embeddings without human annotation enabling tasks like zero-shot retrieval and classification. In this work, we present a multi-modal, modality agnostic fusion transformer approach that learns to exchange information between multiple modalities, such as video, audio, and text, and integrate them into a joined multi-modal representation to obtain an embedding that aggregates multi-modal temporal information. We propose to train the system with a combinatorial loss on everything at once, single modalities as well as pairs of modalities, explicitly leaving out any add-ons such as position or modality encoding. At test time, the resulting model can process and fuse any number of input modalities. Moreover, the implicit properties of the transformer allow to process inputs of different lengths. To evaluate the proposed approach, we train the model on the large scale HowTo100M dataset and evaluate the resulting embedding space on four challenging benchmark datasets obtaining state-of-the-art results in zero-shot video retrieval and zero-shot video action localization.
Unsupervised Domain Generalization by Learning a Bridge Across Domains
Dec 04, 2021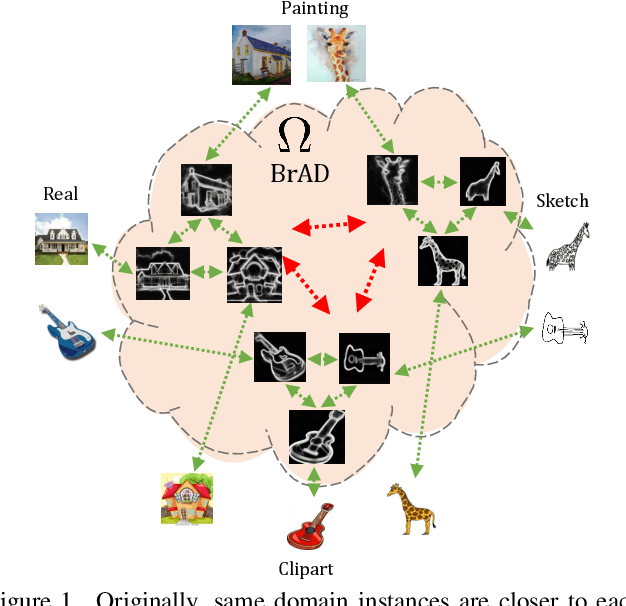
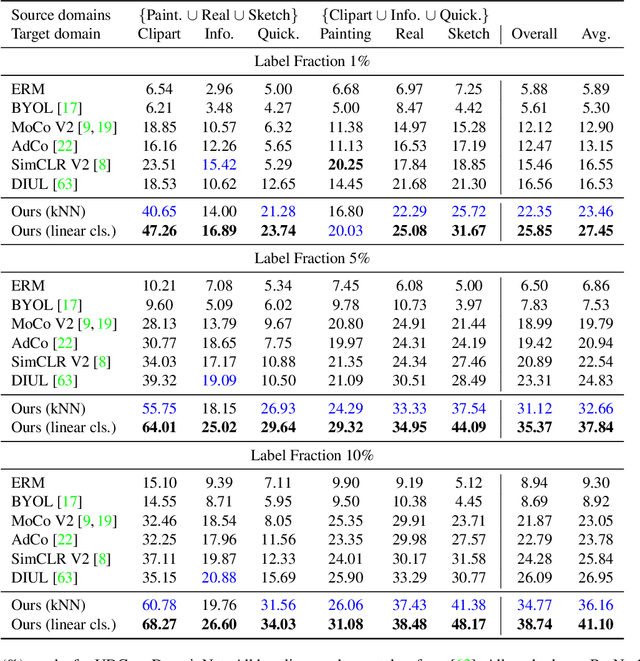
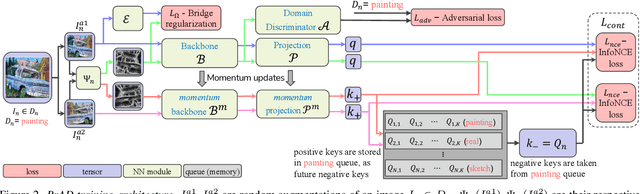
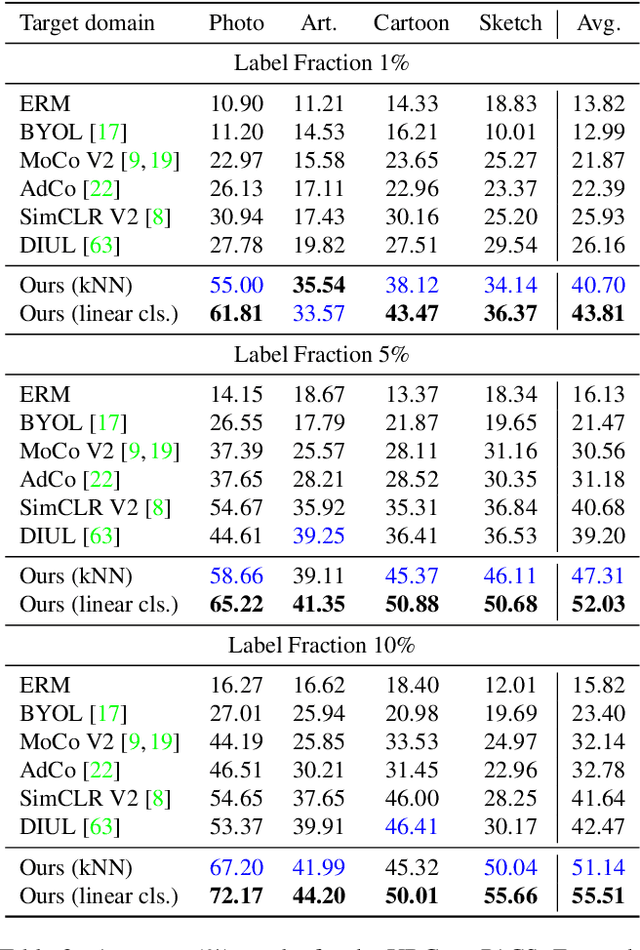
The ability to generalize learned representations across significantly different visual domains, such as between real photos, clipart, paintings, and sketches, is a fundamental capacity of the human visual system. In this paper, different from most cross-domain works that utilize some (or full) source domain supervision, we approach a relatively new and very practical Unsupervised Domain Generalization (UDG) setup of having no training supervision in neither source nor target domains. Our approach is based on self-supervised learning of a Bridge Across Domains (BrAD) - an auxiliary bridge domain accompanied by a set of semantics preserving visual (image-to-image) mappings to BrAD from each of the training domains. The BrAD and mappings to it are learned jointly (end-to-end) with a contrastive self-supervised representation model that semantically aligns each of the domains to its BrAD-projection, and hence implicitly drives all the domains (seen or unseen) to semantically align to each other. In this work, we show how using an edge-regularized BrAD our approach achieves significant gains across multiple benchmarks and a range of tasks, including UDG, Few-shot UDA, and unsupervised generalization across multi-domain datasets (including generalization to unseen domains and classes).