 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Social Value Orientation Leads to Meaningful Diversity in Sequential Social Dilemmas
May 01, 2023



In social psychology, Social Value Orientation (SVO) describes an individual's propensity to allocate resources between themself and others. In reinforcement learning, SVO has been instantiated as an intrinsic motivation that remaps an agent's rewards based on particular target distributions of group reward. Prior studies show that groups of agents endowed with heterogeneous SVO learn diverse policies in settings that resemble the incentive structure of Prisoner's dilemma. Our work extends this body of results and demonstrates that (1) heterogeneous SVO leads to meaningfully diverse policies across a range of incentive structures in sequential social dilemmas, as measured by task-specific diversity metrics; and (2) learning a best response to such policy diversity leads to better zero-shot generalization in some situations. We show that these best-response agents learn policies that are conditioned on their co-players, which we posit is the reason for improved zero-shot generalization results.
Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.
Stochastic Parallelizable Eigengap Dilation for Large Graph Clustering
Jul 29, 2022

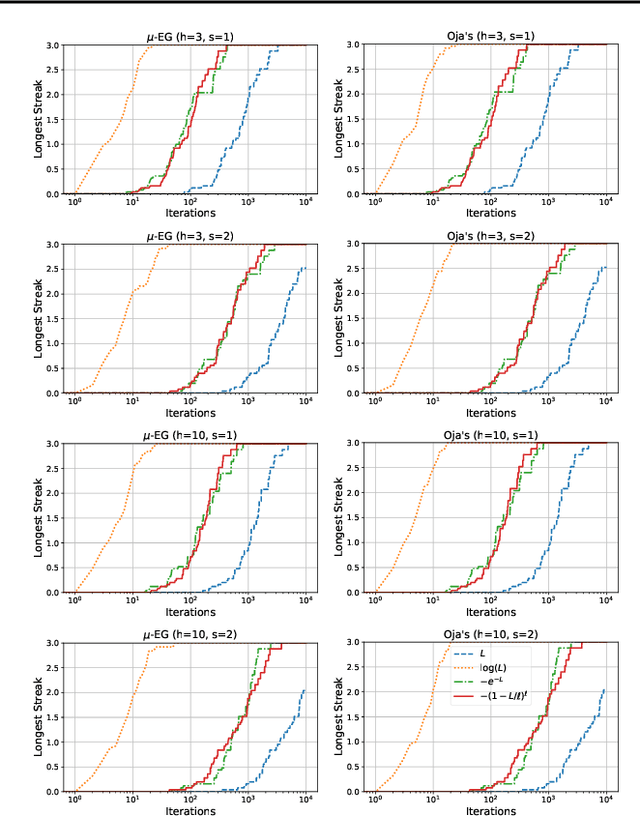
Large graphs commonly appear in social networks, knowledge graphs, recommender systems, life sciences, and decision making problems. Summarizing large graphs by their high level properties is helpful in solving problems in these settings. In spectral clustering, we aim to identify clusters of nodes where most edges fall within clusters and only few edges fall between clusters. This task is important for many downstream applications and exploratory analysis. A core step of spectral clustering is performing an eigendecomposition of the corresponding graph Laplacian matrix (or equivalently, a singular value decomposition, SVD, of the incidence matrix). The convergence of iterative singular value decomposition approaches depends on the eigengaps of the spectrum of the given matrix, i.e., the difference between consecutive eigenvalues. For a graph Laplacian corresponding to a well-clustered graph, the eigenvalues will be non-negative but very small (much less than $1$) slowing convergence. This paper introduces a parallelizable approach to dilating the spectrum in order to accelerate SVD solvers and in turn, spectral clustering. This is accomplished via polynomial approximations to matrix operations that favorably transform the spectrum of a matrix without changing its eigenvectors. Experiments demonstrate that this approach significantly accelerates convergence, and we explain how this transformation can be parallelized and stochastically approximated to scale with available compute.
Learning Robust Real-Time Cultural Transmission without Human Data
Mar 01, 2022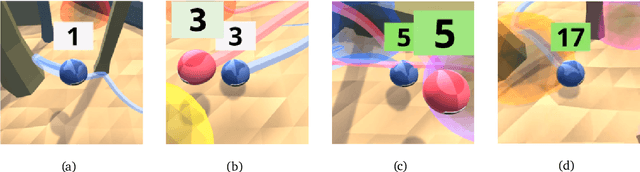
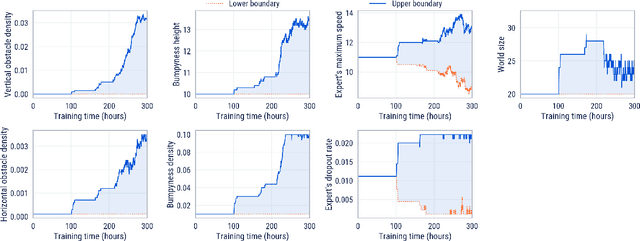
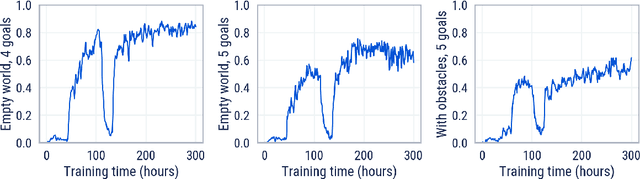
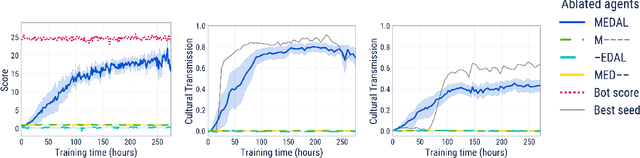
Cultural transmission is the domain-general social skill that allows agents to acquire and use information from each other in real-time with high fidelity and recall. In humans, it is the inheritance process that powers cumulative cultural evolution, expanding our skills, tools and knowledge across generations. We provide a method for generating zero-shot, high recall cultural transmission in artificially intelligent agents. Our agents succeed at real-time cultural transmission from humans in novel contexts without using any pre-collected human data. We identify a surprisingly simple set of ingredients sufficient for generating cultural transmission and develop an evaluation methodology for rigorously assessing it. This paves the way for cultural evolution as an algorithm for developing artificial general intelligence.
Hidden Agenda: a Social Deduction Game with Diverse Learned Equilibria
Jan 05, 2022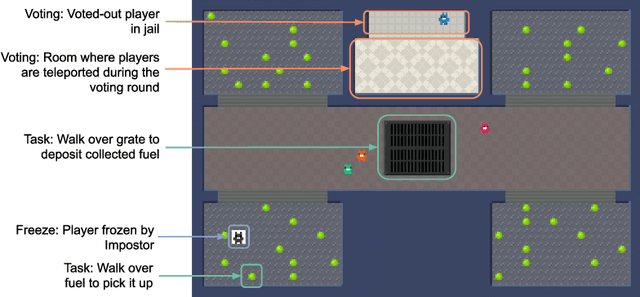

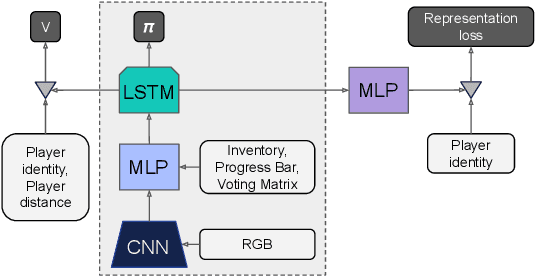
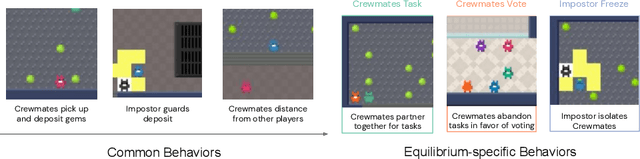
A key challenge in the study of multiagent cooperation is the need for individual agents not only to cooperate effectively, but to decide with whom to cooperate. This is particularly critical in situations when other agents have hidden, possibly misaligned motivations and goals. Social deduction games offer an avenue to study how individuals might learn to synthesize potentially unreliable information about others, and elucidate their true motivations. In this work, we present Hidden Agenda, a two-team social deduction game that provides a 2D environment for studying learning agents in scenarios of unknown team alignment. The environment admits a rich set of strategies for both teams. Reinforcement learning agents trained in Hidden Agenda show that agents can learn a variety of behaviors, including partnering and voting without need for communication in natural language.
Collaborating with Humans without Human Data
Oct 15, 2021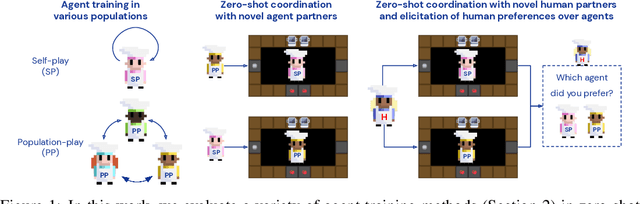

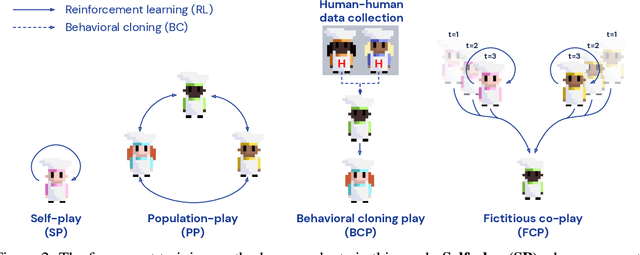
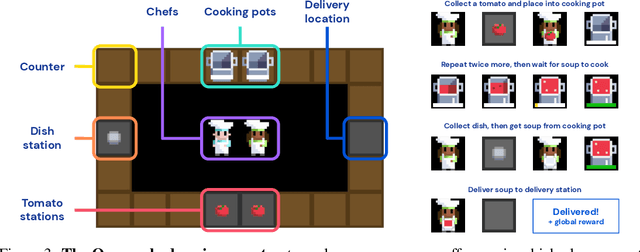
Collaborating with humans requires rapidly adapting to their individual strengths, weaknesses, and preferences. Unfortunately, most standard multi-agent reinforcement learning techniques, such as self-play (SP) or population play (PP), produce agents that overfit to their training partners and do not generalize well to humans. Alternatively, researchers can collect human data, train a human model using behavioral cloning, and then use that model to train "human-aware" agents ("behavioral cloning play", or BCP). While such an approach can improve the generalization of agents to new human co-players, it involves the onerous and expensive step of collecting large amounts of human data first. Here, we study the problem of how to train agents that collaborate well with human partners without using human data. We argue that the crux of the problem is to produce a diverse set of training partners. Drawing inspiration from successful multi-agent approaches in competitive domains, we find that a surprisingly simple approach is highly effective. We train our agent partner as the best response to a population of self-play agents and their past checkpoints taken throughout training, a method we call Fictitious Co-Play (FCP). Our experiments focus on a two-player collaborative cooking simulator that has recently been proposed as a challenge problem for coordination with humans. We find that FCP agents score significantly higher than SP, PP, and BCP when paired with novel agent and human partners. Furthermore, humans also report a strong subjective preference to partnering with FCP agents over all baselines.
Quantifying environment and population diversity in multi-agent reinforcement learning
Feb 16, 2021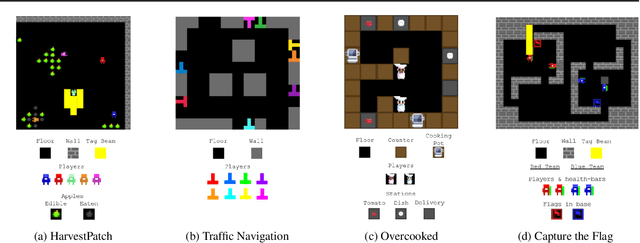

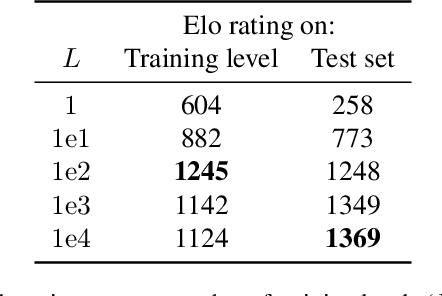
Generalization is a major challenge for multi-agent reinforcement learning. How well does an agent perform when placed in novel environments and in interactions with new co-players? In this paper, we investigate and quantify the relationship between generalization and diversity in the multi-agent domain. Across the range of multi-agent environments considered here, procedurally generating training levels significantly improves agent performance on held-out levels. However, agent performance on the specific levels used in training sometimes declines as a result. To better understand the effects of co-player variation, our experiments introduce a new environment-agnostic measure of behavioral diversity. Results demonstrate that population size and intrinsic motivation are both effective methods of generating greater population diversity. In turn, training with a diverse set of co-players strengthens agent performance in some (but not all) cases.
Modelling Cooperation in Network Games with Spatio-Temporal Complexity
Feb 13, 2021

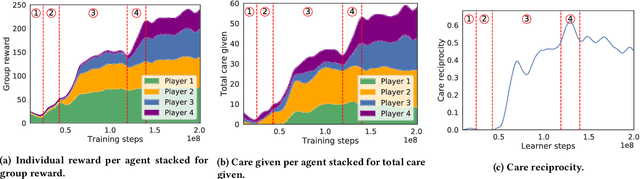
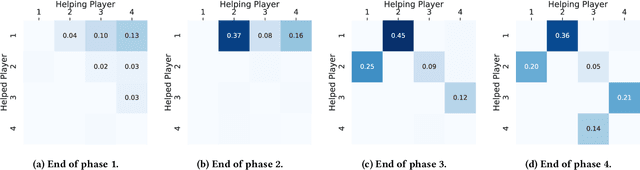
The real world is awash with multi-agent problems that require collective action by self-interested agents, from the routing of packets across a computer network to the management of irrigation systems. Such systems have local incentives for individuals, whose behavior has an impact on the global outcome for the group. Given appropriate mechanisms describing agent interaction, groups may achieve socially beneficial outcomes, even in the face of short-term selfish incentives. In many cases, collective action problems possess an underlying graph structure, whose topology crucially determines the relationship between local decisions and emergent global effects. Such scenarios have received great attention through the lens of network games. However, this abstraction typically collapses important dimensions, such as geometry and time, relevant to the design of mechanisms promoting cooperation. In parallel work, multi-agent deep reinforcement learning has shown great promise in modelling the emergence of self-organized cooperation in complex gridworld domains. Here we apply this paradigm in graph-structured collective action problems. Using multi-agent deep reinforcement learning, we simulate an agent society for a variety of plausible mechanisms, finding clear transitions between different equilibria over time. We define analytic tools inspired by related literatures to measure the social outcomes, and use these to draw conclusions about the efficacy of different environmental interventions. Our methods have implications for mechanism design in both human and artificial agent systems.
Negotiating Team Formation Using Deep Reinforcement Learning
Oct 20, 2020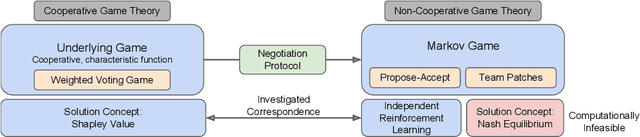
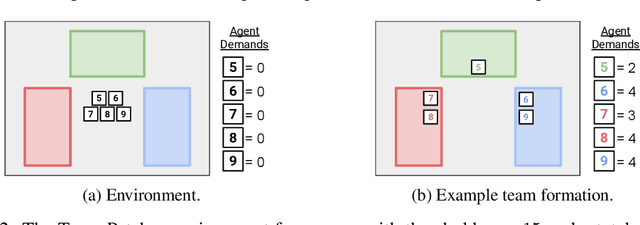
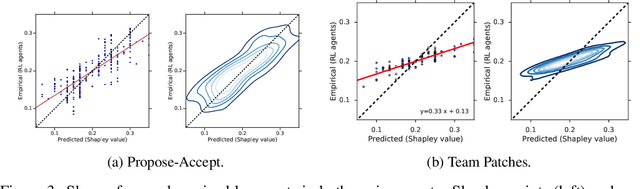
When autonomous agents interact in the same environment, they must often cooperate to achieve their goals. One way for agents to cooperate effectively is to form a team, make a binding agreement on a joint plan, and execute it. However, when agents are self-interested, the gains from team formation must be allocated appropriately to incentivize agreement. Various approaches for multi-agent negotiation have been proposed, but typically only work for particular negotiation protocols. More general methods usually require human input or domain-specific data, and so do not scale. To address this, we propose a framework for training agents to negotiate and form teams using deep reinforcement learning. Importantly, our method makes no assumptions about the specific negotiation protocol, and is instead completely experience driven. We evaluate our approach on both non-spatial and spatially extended team-formation negotiation environments, demonstrating that our agents beat hand-crafted bots and reach negotiation outcomes consistent with fair solutions predicted by cooperative game theory. Additionally, we investigate how the physical location of agents influences negotiation outcomes.
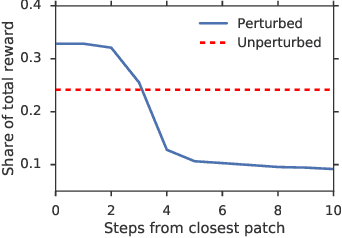
Learning to Play No-Press Diplomacy with Best Response Policy Iteration
Jun 17, 2020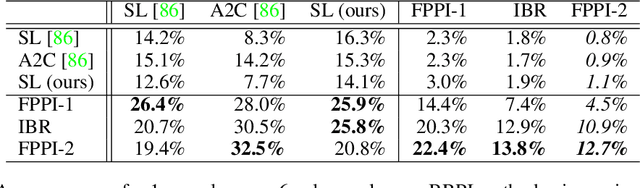
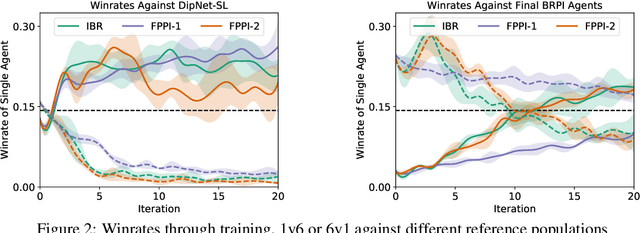
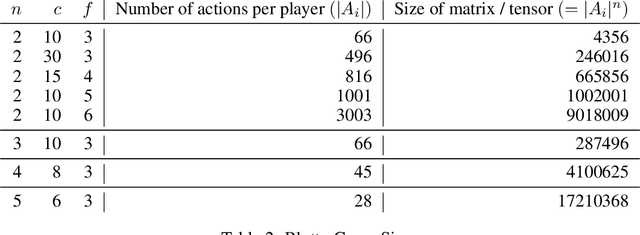
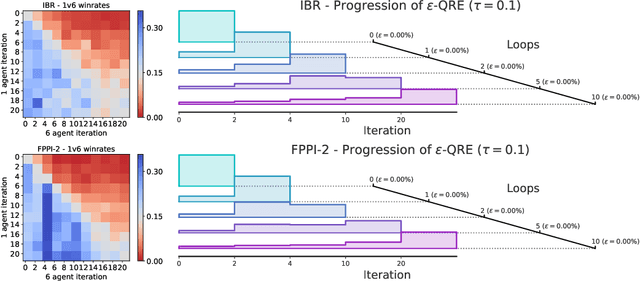
Recent advances in deep reinforcement learning (RL) have led to considerable progress in many 2-player zero-sum games, such as Go, Poker and Starcraft. The purely adversarial nature of such games allows for conceptually simple and principled application of RL methods. However real-world settings are many-agent, and agent interactions are complex mixtures of common-interest and competitive aspects. We consider Diplomacy, a 7-player board game designed to accentuate dilemmas resulting from many-agent interactions. It also features a large combinatorial action space and simultaneous moves, which are challenging for RL algorithms. We propose a simple yet effective approximate best response operator, designed to handle large combinatorial action spaces and simultaneous moves. We also introduce a family of policy iteration methods that approximate fictitious play. With these methods, we successfully apply RL to Diplomacy: we show that our agents convincingly outperform the previous state-of-the-art, and game theoretic equilibrium analysis shows that the new process yields consistent improvements.