 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralised Lipschitz Regularisation Equals Distributional Robustness
Feb 11, 2020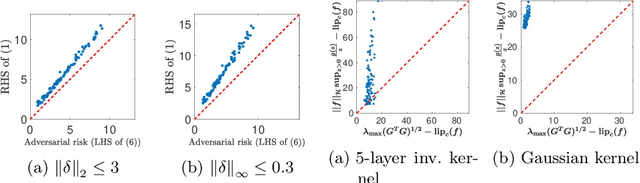
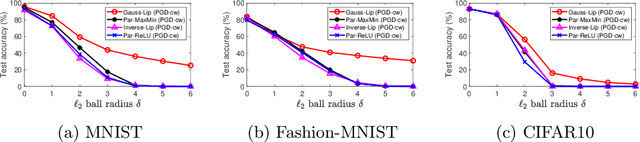
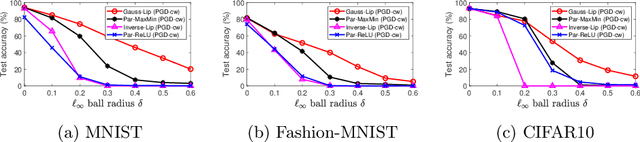
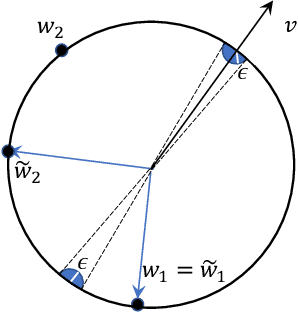
The problem of adversarial examples has highlighted the need for a theory of regularisation that is general enough to apply to exotic function classes, such as universal approximators. In response, we give a very general equality result regarding the relationship between distributional robustness and regularisation, as defined with a transportation cost uncertainty set. The theory allows us to (tightly) certify the robustness properties of a Lipschitz-regularised model with very mild assumptions. As a theoretical application we show a new result explicating the connection between adversarial learning and distributional robustness. We then give new results for how to achieve Lipschitz regularisation of kernel classifiers, which are demonstrated experimentally.
Supervised Learning: No Loss No Cry
Feb 10, 2020
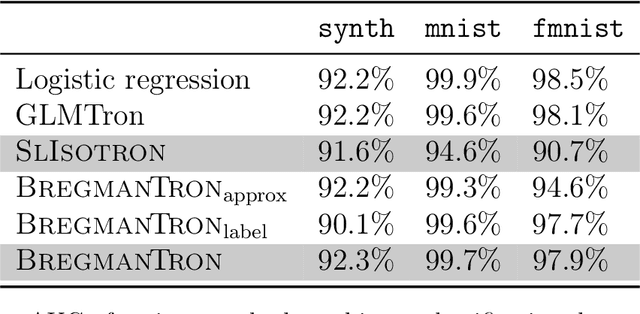

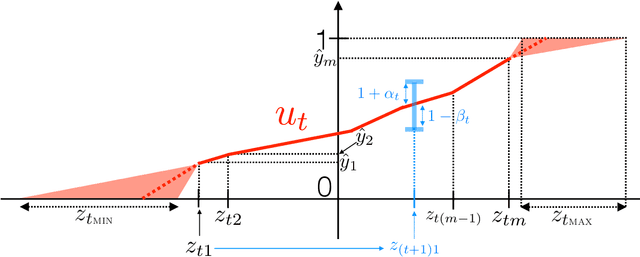
Supervised learning requires the specification of a loss function to minimise. While the theory of admissible losses from both a computational and statistical perspective is well-developed, these offer a panoply of different choices. In practice, this choice is typically made in an \emph{ad hoc} manner. In hopes of making this procedure more principled, the problem of \emph{learning the loss function} for a downstream task (e.g., classification) has garnered recent interest. However, works in this area have been generally empirical in nature. In this paper, we revisit the {\sc SLIsotron} algorithm of Kakade et al. (2011) through a novel lens, derive a generalisation based on Bregman divergences, and show how it provides a principled procedure for learning the loss. In detail, we cast {\sc SLIsotron} as learning a loss from a family of composite square losses. By interpreting this through the lens of \emph{proper losses}, we derive a generalisation of {\sc SLIsotron} based on Bregman divergences. The resulting {\sc BregmanTron} algorithm jointly learns the loss along with the classifier. It comes equipped with a simple guarantee of convergence for the loss it learns, and its set of possible outputs comes with a guarantee of agnostic approximability of Bayes rule. Experiments indicate that the {\sc BregmanTron} substantially outperforms the {\sc SLIsotron}, and that the loss it learns can be minimized by other algorithms for different tasks, thereby opening the interesting problem of \textit{loss transfer} between domains.
Boosted and Differentially Private Ensembles of Decision Trees
Feb 03, 2020
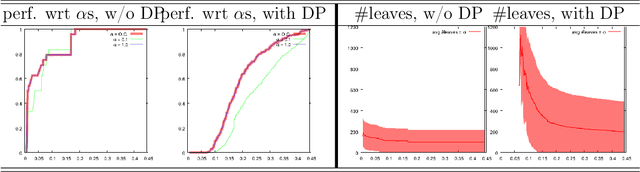
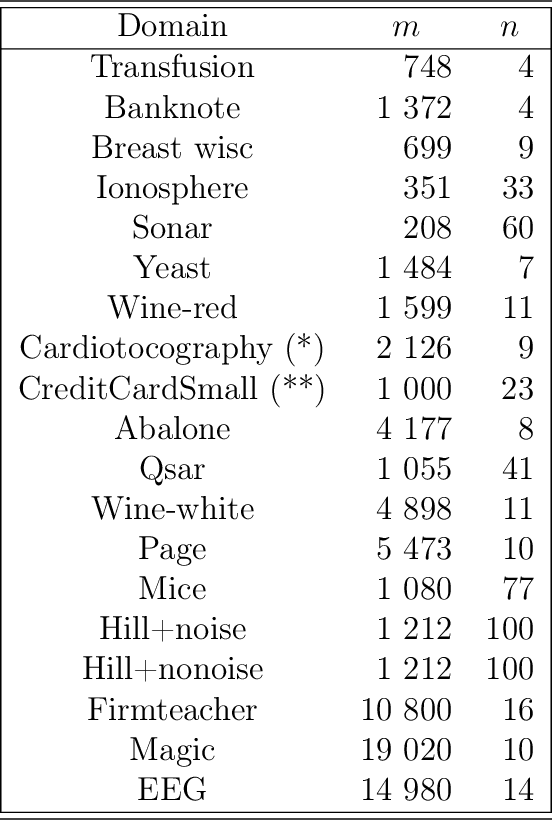
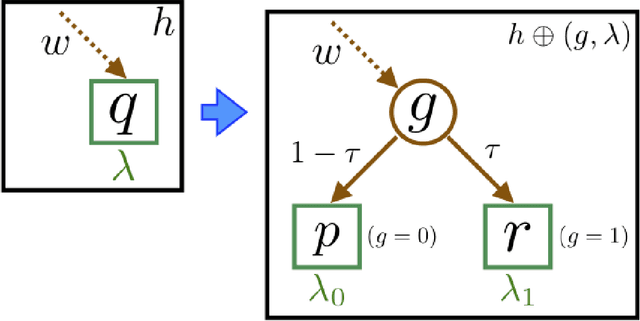
Boosted ensemble of decision tree (DT) classifiers are extremely popular in international competitions, yet to our knowledge nothing is formally known on how to make them \textit{also} differential private (DP), up to the point that random forests currently reign supreme in the DP stage. Our paper starts with the proof that the privacy vs boosting picture for DT involves a notable and general technical tradeoff: the sensitivity tends to increase with the boosting rate of the loss, for any proper loss. DT induction algorithms being fundamentally iterative, our finding implies non-trivial choices to select or tune the loss to balance noise against utility to split nodes. To address this, we craft a new parametererized proper loss, called the M$\alpha$-loss, which, as we show, allows to finely tune the tradeoff in the complete spectrum of sensitivity vs boosting guarantees. We then introduce \textit{objective calibration} as a method to adaptively tune the tradeoff during DT induction to limit the privacy budget spent while formally being able to keep boosting-compliant convergence on limited-depth nodes with high probability. Extensive experiments on 19 UCI domains reveal that objective calibration is highly competitive, even in the DP-free setting. Our approach tends to very significantly beat random forests, in particular on high DP regimes ($\varepsilon \leq 0.1$) and even with boosted ensembles containing ten times less trees, which could be crucial to keep a key feature of DT models under differential privacy: interpretability.
Advances and Open Problems in Federated Learning
Dec 10, 2019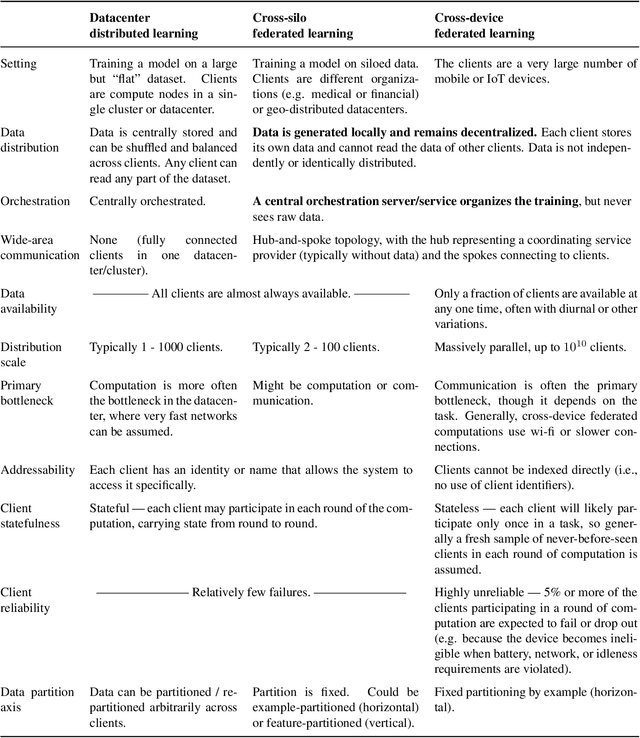
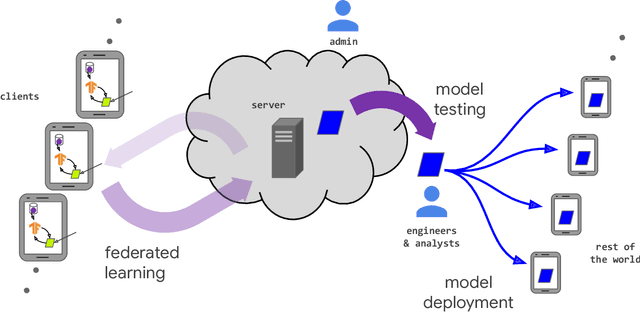
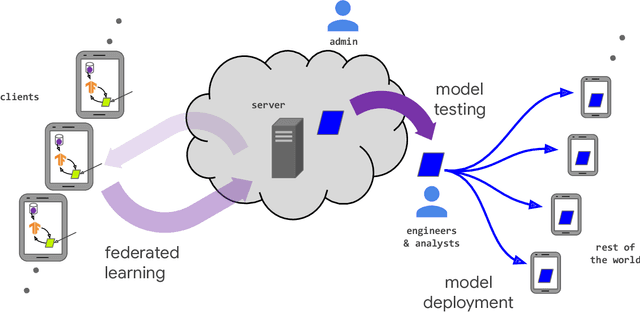

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Proper-Composite Loss Functions in Arbitrary Dimensions
Feb 19, 2019

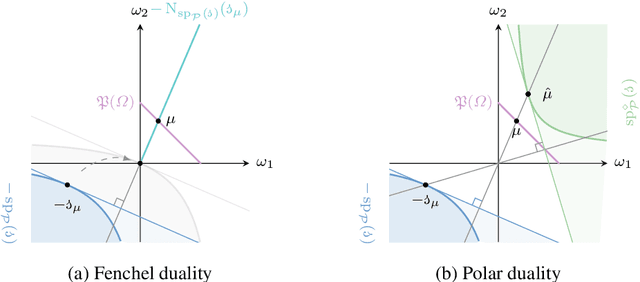
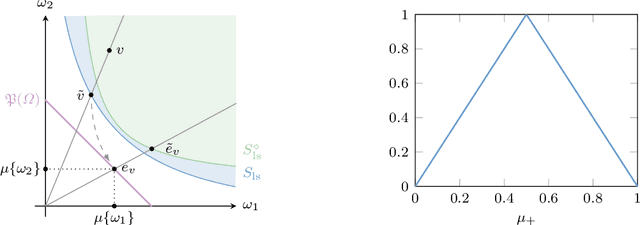
The study of a machine learning problem is in many ways is difficult to separate from the study of the loss function being used. One avenue of inquiry has been to look at these loss functions in terms of their properties as scoring rules via the proper-composite representation, in which predictions are mapped to probability distributions which are then scored via a scoring rule. However, recent research so far has primarily been concerned with analysing the (typically) finite-dimensional conditional risk problem on the output space, leaving aside the larger total risk minimisation. We generalise a number of these results to an infinite dimensional setting and in doing so we are able to exploit the familial resemblance of density and conditional density estimation to provide a simple characterisation of the canonical link.
Adversarial Networks and Autoencoders: The Primal-Dual Relationship and Generalization Bounds
Feb 03, 2019Since the introduction of Generative Adversarial Networks (GANs) and Variational Autoencoders (VAE), the literature on generative modelling has witnessed an overwhelming resurgence. The impressive, yet elusive empirical performance of GANs has lead to the rise of many GAN-VAE hybrids, with the hopes of GAN level performance and additional benefits of VAE, such as an encoder for feature reduction, which is not offered by GANs. Recently, the Wasserstein Autoencoder (WAE) was proposed, achieving performance similar to that of GANs, yet it is still unclear whether the two are fundamentally different or can be further improved into a unified model. In this work, we study the $f$-GAN and WAE models and make two main discoveries. First, we find that the $f$-GAN objective is equivalent to an autoencoder-like objective, which has close links, and is in some cases equivalent to the WAE objective - we refer to this as the $f$-WAE. This equivalence allows us to explicate the success of WAE. Second, the equivalence result allows us to, for the first time, prove generalization bounds for Autoencoder models (WAE and $f$-WAE), which is a pertinent problem when it comes to theoretical analyses of generative models. Furthermore, we show that the $f$-WAE objective is related to other statistical quantities such as the $f$-divergence and in particular, upper bounded by the Wasserstein distance, which then allows us to tap into existing efficient (regularized) OT solvers to minimize $f$-WAE. Our findings thus recommend the $f$-WAE as a tighter alternative to WAE, comment on generalization abilities and make a step towards unifying these models.
New Tricks for Estimating Gradients of Expectations
Jan 31, 2019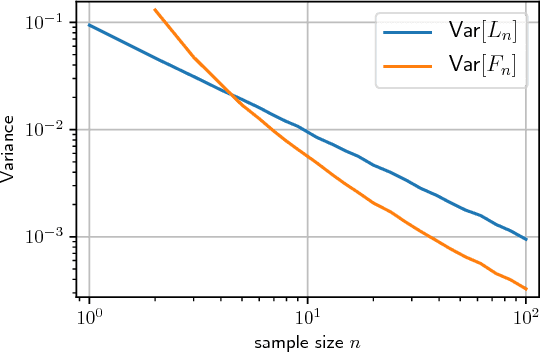

We derive a family of Monte Carlo estimators for gradients of expectations of univariate distributions, which is related to the log-derivative trick, but involves pairwise interactions between samples. The first of these comes from either a) introducing and approximating an integral representation based on the fundamental theorem of calculus, or b) applying the reparameterisation trick to an implicit parameterisation under infinitesimal perturbation of the parameters. From the former perspective we generalise to a reproducing kernel Hilbert space representation, giving rise to locality parameter in the pairwise interactions mentioned above. The resulting estimators are unbiased and shown to offer an independent component of useful information in comparison with the log-derivative estimator. Promising analytical and numerical examples confirm the intuitions behind the new estimators.
The Bregman chord divergence
Oct 22, 2018
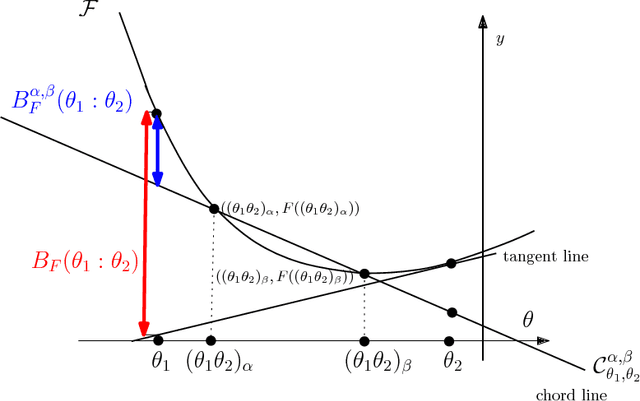
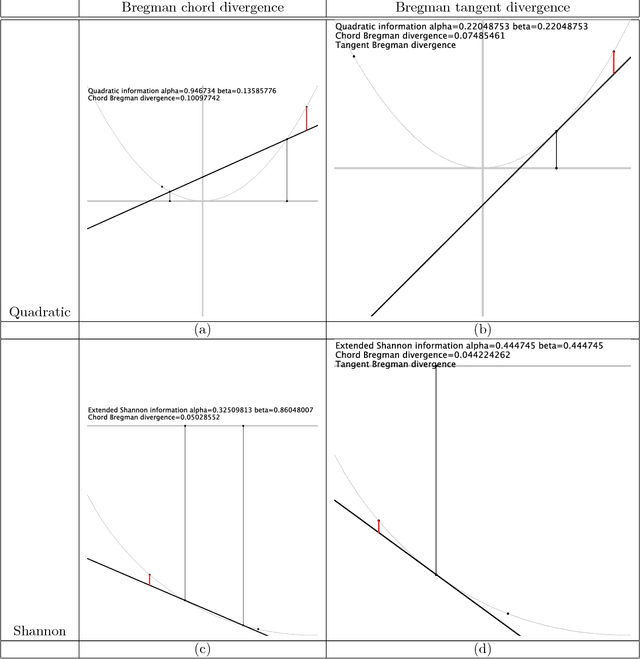
Distances are fundamental primitives whose choice significantly impacts the performances of algorithms in machine learning and signal processing. However selecting the most appropriate distance for a given task is an endeavor. Instead of testing one by one the entries of an ever-expanding dictionary of {\em ad hoc} distances, one rather prefers to consider parametric classes of distances that are exhaustively characterized by axioms derived from first principles. Bregman divergences are such a class. However fine-tuning a Bregman divergence is delicate since it requires to smoothly adjust a functional generator. In this work, we propose an extension of Bregman divergences called the Bregman chord divergences. This new class of distances does not require gradient calculations, uses two scalar parameters that can be easily tailored in applications, and generalizes asymptotically Bregman divergences.
Hyperparameter Learning for Conditional Mean Embeddings with Rademacher Complexity Bounds
Sep 19, 2018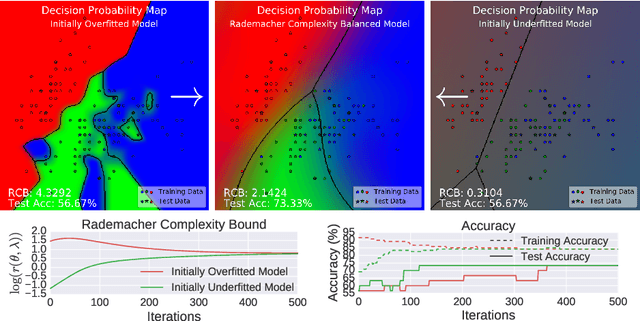

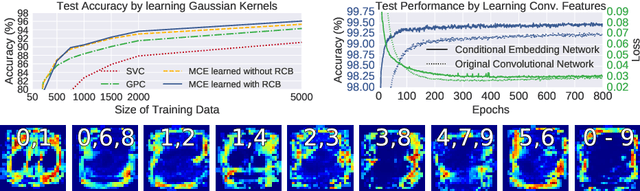

Conditional mean embeddings are nonparametric models that encode conditional expectations in a reproducing kernel Hilbert space. While they provide a flexible and powerful framework for probabilistic inference, their performance is highly dependent on the choice of kernel and regularization hyperparameters. Nevertheless, current hyperparameter tuning methods predominantly rely on expensive cross validation or heuristics that is not optimized for the inference task. For conditional mean embeddings with categorical targets and arbitrary inputs, we propose a hyperparameter learning framework based on Rademacher complexity bounds to prevent overfitting by balancing data fit against model complexity. Our approach only requires batch updates, allowing scalable kernel hyperparameter tuning without invoking kernel approximations. Experiments demonstrate that our learning framework outperforms competing methods, and can be further extended to incorporate and learn deep neural network weights to improve generalization.
Monge beats Bayes: Hardness Results for Adversarial Training
Sep 12, 2018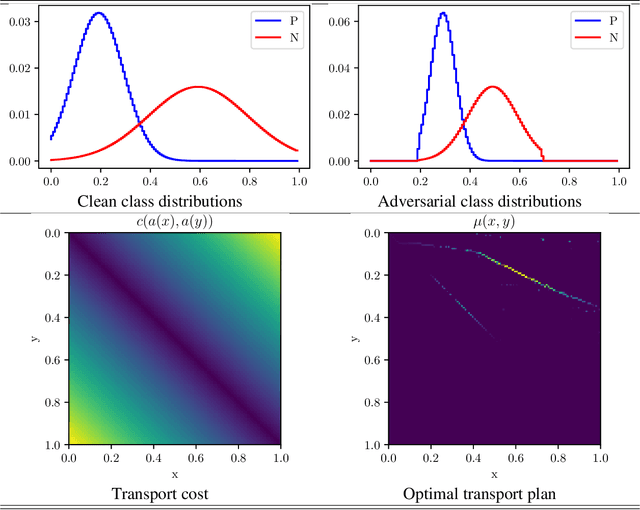
The last few years have seen extensive empirical study of the robustness of neural networks, with a concerning conclusion: several state-of-the-art approaches are highly sensitive to adversarial perturbations of their inputs. There has been an accompanying surge of interest in learning including defense mechanisms against specific adversaries, known as adversarial training. Despite some impressive advances, little remains known on how to best frame a resource-bounded adversary so that it can be severely detrimental to learning, a non-trivial problem which entails at a minimum the choice of loss and classifiers. We suggest here a formal answer to this question, and pin down a simple sufficient property for any given class of adversaries to be detrimental to learning. This property involves a central measure of `harmfulness' which generalizes the well-known class of integral probability metrics. A key feature of our result is that it holds for \textit{all} proper losses, and for a popular subset of these, the optimisation of this central measure appears to be independent of the loss. We show how weakly contractive adversaries for a RKHS can be self-combined to build a maximally detrimental adversary, we show that some implemented existing adversaries involve proxies of our optimal transport adversaries and finally provide a toy experiment assessing such adversaries in a simple context, displaying that additional robustness on testing can be granted through adversarial training.