 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantile Propagation for Wasserstein-Approximate Gaussian Processes
Feb 08, 2020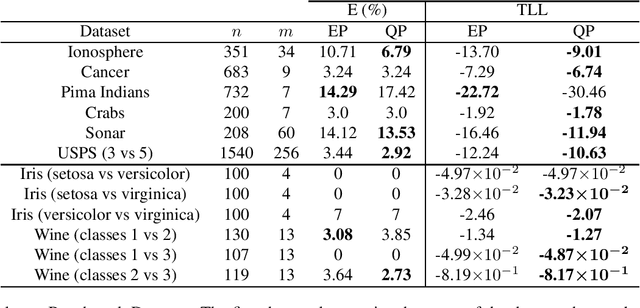
We develop a new approximate Bayesian inference method for Gaussian process models with factorized non-Gaussian likelihoods. Our method---dubbed Quantile Propagation (QP)---is similar to expectation propagation (EP) but minimizes the L_2 Wasserstein distance rather than the Kullback-Leibler (KL) divergence. We consider the case where likelihood factors are approximated by a Gaussian form. We show that QP matches quantile functions rather than moments as in EP and has the same mean update but a smaller variance update than EP, thereby alleviating the over-estimation of the posterior variance exhibited by EP. Crucially, QP has the same favorable locality property as EP, and thereby admits an efficient algorithm. Experiments on classification and Poisson regression tasks demonstrate that QP outperforms both EP and variational Bayes.
New Tricks for Estimating Gradients of Expectations
Jan 31, 2019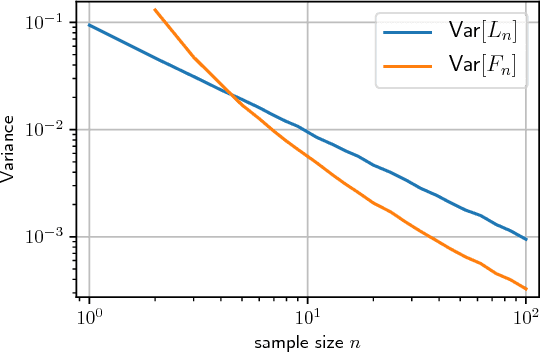

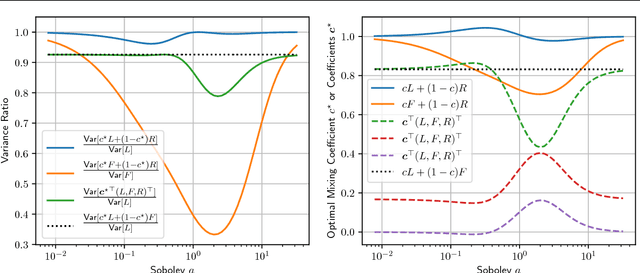
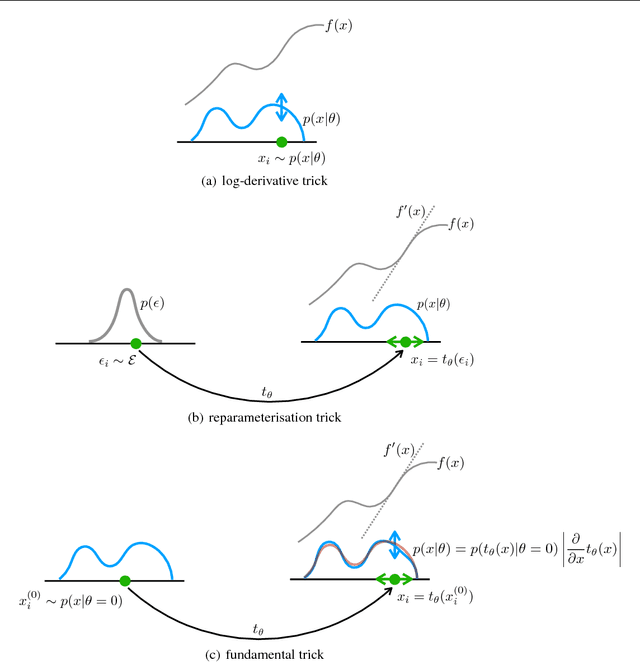
We derive a family of Monte Carlo estimators for gradients of expectations of univariate distributions, which is related to the log-derivative trick, but involves pairwise interactions between samples. The first of these comes from either a) introducing and approximating an integral representation based on the fundamental theorem of calculus, or b) applying the reparameterisation trick to an implicit parameterisation under infinitesimal perturbation of the parameters. From the former perspective we generalise to a reproducing kernel Hilbert space representation, giving rise to locality parameter in the pairwise interactions mentioned above. The resulting estimators are unbiased and shown to offer an independent component of useful information in comparison with the log-derivative estimator. Promising analytical and numerical examples confirm the intuitions behind the new estimators.
Neural Dynamic Programming for Musical Self Similarity
Aug 29, 2018
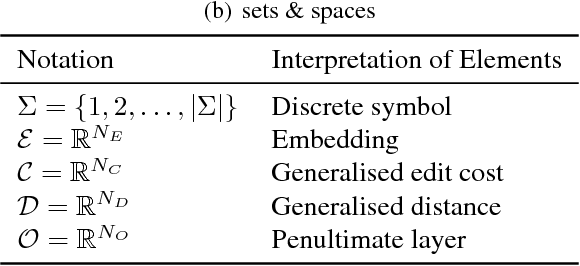
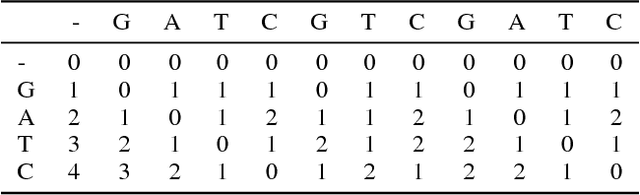
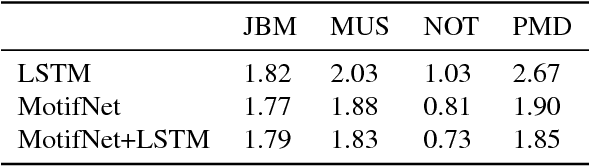
We present a neural sequence model designed specifically for symbolic music. The model is based on a learned edit distance mechanism which generalises a classic recursion from computer sci- ence, leading to a neural dynamic program. Re- peated motifs are detected by learning the transfor- mations between them. We represent the arising computational dependencies using a novel data structure, the edit tree; this perspective suggests natural approximations which afford the scaling up of our otherwise cubic time algorithm. We demonstrate our model on real and synthetic data; in all cases it out-performs a strong stacked long short-term memory benchmark.