 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Disentanglement of Arteriovenous Malformations in Digital Subtraction Angiography
Feb 15, 2024Although Digital Subtraction Angiography (DSA) is the most important imaging for visualizing cerebrovascular anatomy, its interpretation by clinicians remains difficult. This is particularly true when treating arteriovenous malformations (AVMs), where entangled vasculature connecting arteries and veins needs to be carefully identified.The presented method aims to enhance DSA image series by highlighting critical information via automatic classification of vessels using a combination of two learning models: An unsupervised machine learning method based on Independent Component Analysis that decomposes the phases of flow and a convolutional neural network that automatically delineates the vessels in image space. The proposed method was tested on clinical DSA images series and demonstrated efficient differentiation between arteries and veins that provides a viable solution to enhance visualizations for clinical use.
Learning Expected Appearances for Intraoperative Registration during Neurosurgery
Oct 03, 2023We present a novel method for intraoperative patient-to-image registration by learning Expected Appearances. Our method uses preoperative imaging to synthesize patient-specific expected views through a surgical microscope for a predicted range of transformations. Our method estimates the camera pose by minimizing the dissimilarity between the intraoperative 2D view through the optical microscope and the synthesized expected texture. In contrast to conventional methods, our approach transfers the processing tasks to the preoperative stage, reducing thereby the impact of low-resolution, distorted, and noisy intraoperative images, that often degrade the registration accuracy. We applied our method in the context of neuronavigation during brain surgery. We evaluated our approach on synthetic data and on retrospective data from 6 clinical cases. Our method outperformed state-of-the-art methods and achieved accuracies that met current clinical standards.
Unified Brain MR-Ultrasound Synthesis using Multi-Modal Hierarchical Representations
Sep 19, 2023We introduce MHVAE, a deep hierarchical variational auto-encoder (VAE) that synthesizes missing images from various modalities. Extending multi-modal VAEs with a hierarchical latent structure, we introduce a probabilistic formulation for fusing multi-modal images in a common latent representation while having the flexibility to handle incomplete image sets as input. Moreover, adversarial learning is employed to generate sharper images. Extensive experiments are performed on the challenging problem of joint intra-operative ultrasound (iUS) and Magnetic Resonance (MR) synthesis. Our model outperformed multi-modal VAEs, conditional GANs, and the current state-of-the-art unified method (ResViT) for synthesizing missing images, demonstrating the advantage of using a hierarchical latent representation and a principled probabilistic fusion operation. Our code is publicly available \url{https://github.com/ReubenDo/MHVAE}.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
SegMatch: A semi-supervised learning method for surgical instrument segmentation
Aug 09, 2023



Surgical instrument segmentation is recognised as a key enabler to provide advanced surgical assistance and improve computer assisted interventions. In this work, we propose SegMatch, a semi supervised learning method to reduce the need for expensive annotation for laparoscopic and robotic surgical images. SegMatch builds on FixMatch, a widespread semi supervised classification pipeline combining consistency regularization and pseudo labelling, and adapts it for the purpose of segmentation. In our proposed SegMatch, the unlabelled images are weakly augmented and fed into the segmentation model to generate a pseudo-label to enforce the unsupervised loss against the output of the model for the adversarial augmented image on the pixels with a high confidence score. Our adaptation for segmentation tasks includes carefully considering the equivariance and invariance properties of the augmentation functions we rely on. To increase the relevance of our augmentations, we depart from using only handcrafted augmentations and introduce a trainable adversarial augmentation strategy. Our algorithm was evaluated on the MICCAI Instrument Segmentation Challenge datasets Robust-MIS 2019 and EndoVis 2017. Our results demonstrate that adding unlabelled data for training purposes allows us to surpass the performance of fully supervised approaches which are limited by the availability of training data in these challenges. SegMatch also outperforms a range of state-of-the-art semi-supervised learning semantic segmentation models in different labelled to unlabelled data ratios.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Boundary Distance Loss for Intra-/Extra-meatal Segmentation of Vestibular Schwannoma
Aug 09, 2022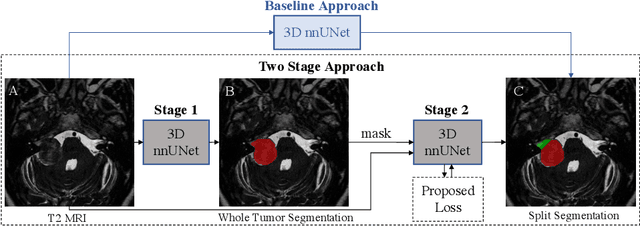
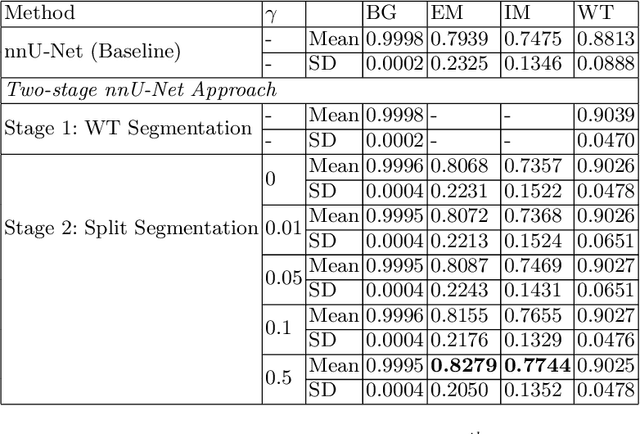
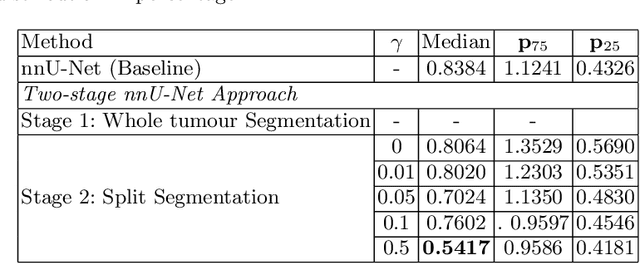
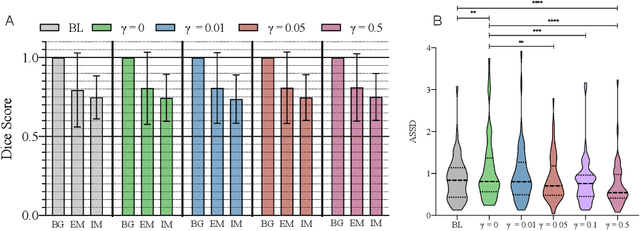
Vestibular Schwannoma (VS) typically grows from the inner ear to the brain. It can be separated into two regions, intrameatal and extrameatal respectively corresponding to being inside or outside the inner ear canal. The growth of the extrameatal regions is a key factor that determines the disease management followed by the clinicians. In this work, a VS segmentation approach with subdivision into intra-/extra-meatal parts is presented. We annotated a dataset consisting of 227 T2 MRI instances, acquired longitudinally on 137 patients, excluding post-operative instances. We propose a staged approach, with the first stage performing the whole tumour segmentation and the second stage performing the intra-/extra-meatal segmentation using the T2 MRI along with the mask obtained from the first stage. To improve on the accuracy of the predicted meatal boundary, we introduce a task-specific loss which we call Boundary Distance Loss. The performance is evaluated in contrast to the direct intrameatal extrameatal segmentation task performance, i.e. the Baseline. Our proposed method, with the two-stage approach and the Boundary Distance Loss, achieved a Dice score of 0.8279+-0.2050 and 0.7744+-0.1352 for extrameatal and intrameatal regions respectively, significantly improving over the Baseline, which gave Dice score of 0.7939+-0.2325 and 0.7475+-0.1346 for the extrameatal and intrameatal regions respectively.
Driving Points Prediction For Abdominal Probabilistic Registration
Aug 05, 2022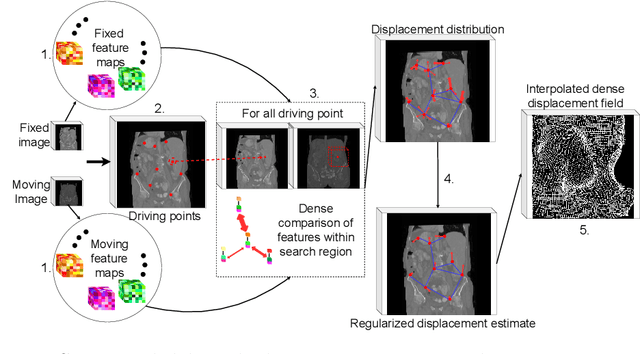
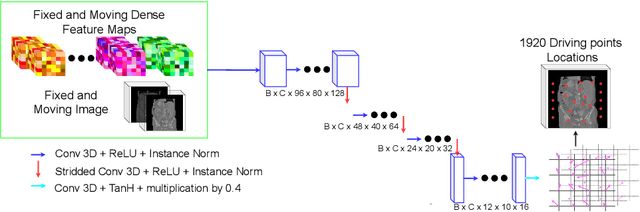
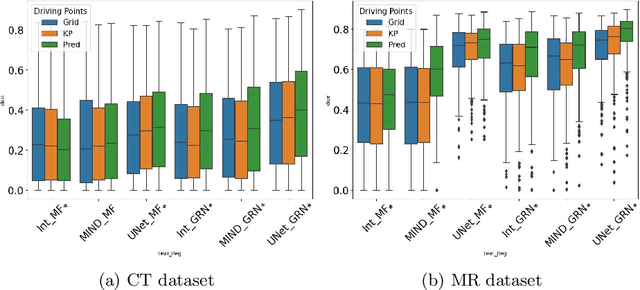
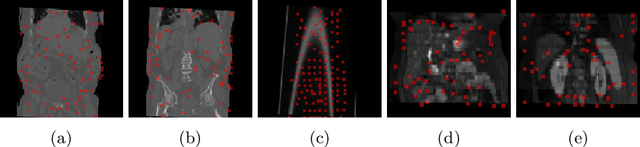
Inter-patient abdominal registration has various applications, from pharmakinematic studies to anatomy modeling. Yet, it remains a challenging application due to the morphological heterogeneity and variability of the human abdomen. Among the various registration methods proposed for this task, probabilistic displacement registration models estimate displacement distribution for a subset of points by comparing feature vectors of points from the two images. These probabilistic models are informative and robust while allowing large displacements by design. As the displacement distributions are typically estimated on a subset of points (which we refer to as driving points), due to computational requirements, we propose in this work to learn a driving points predictor. Compared to previously proposed methods, the driving points predictor is optimized in an end-to-end fashion to infer driving points tailored for a specific registration pipeline. We evaluate the impact of our contribution on two different datasets corresponding to different modalities. Specifically, we compared the performances of 6 different probabilistic displacement registration models when using a driving points predictor or one of 2 other standard driving points selection methods. The proposed method improved performances in 11 out of 12 experiments.
FastGeodis: Fast Generalised Geodesic Distance Transform
Jul 26, 2022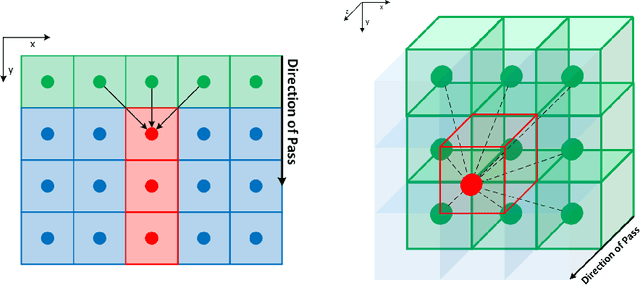
The FastGeodis package provides an efficient implementation for computing Geodesic and Euclidean distance transforms (or a mixture of both) targeting efficient utilisation of CPU and GPU hardwares. In particular, it implements paralellisable raster scan method from Criminisi et al, where elements in row (2D) or plane (3D) can be computed with parallel threads. This package is able to handle 2D as well as 3D data where it achieves up to 15x speed-up on CPU and up to 60x speed-up on GPU as compared to existing open-source libraries, which uses non-parallelisable single-thread CPU implementation. The performance speed-ups reported here were evaluated using 3D volume data on Nvidia GeForce Titan X (12 GB) with 6-Core Intel Xeon E5-1650 CPU. This package is available at: https://github.com/masadcv/FastGeodis