 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reversible Residual Network: Backpropagation Without Storing Activations
Jul 14, 2017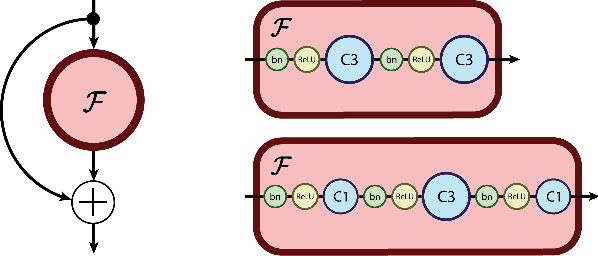
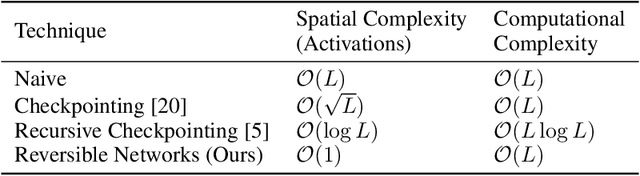
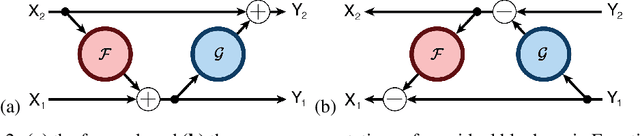
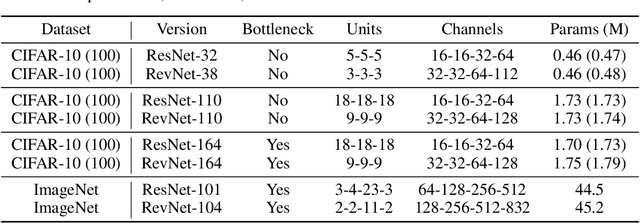
Deep residual networks (ResNets) have significantly pushed forward the state-of-the-art on image classification, increasing in performance as networks grow both deeper and wider. However, memory consumption becomes a bottleneck, as one needs to store the activations in order to calculate gradients using backpropagation. We present the Reversible Residual Network (RevNet), a variant of ResNets where each layer's activations can be reconstructed exactly from the next layer's. Therefore, the activations for most layers need not be stored in memory during backpropagation. We demonstrate the effectiveness of RevNets on CIFAR-10, CIFAR-100, and ImageNet, establishing nearly identical classification accuracy to equally-sized ResNets, even though the activation storage requirements are independent of depth.
Deep Watershed Transform for Instance Segmentation
May 04, 2017
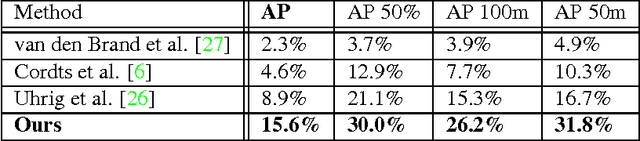
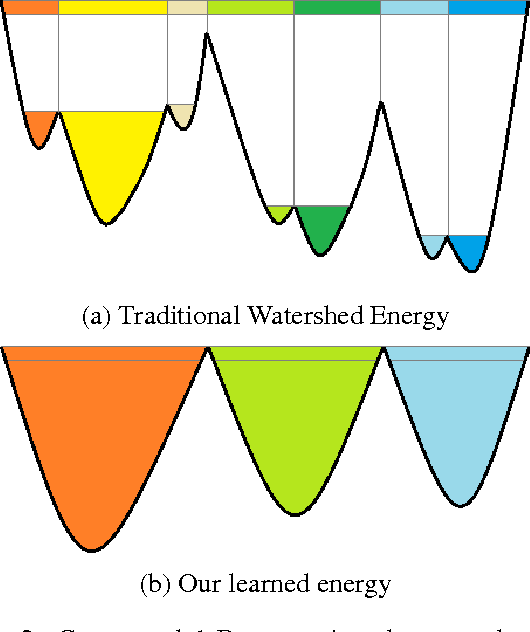

Most contemporary approaches to instance segmentation use complex pipelines involving conditional random fields, recurrent neural networks, object proposals, or template matching schemes. In our paper, we present a simple yet powerful end-to-end convolutional neural network to tackle this task. Our approach combines intuitions from the classical watershed transform and modern deep learning to produce an energy map of the image where object instances are unambiguously represented as basins in the energy map. We then perform a cut at a single energy level to directly yield connected components corresponding to object instances. Our model more than doubles the performance of the state-of-the-art on the challenging Cityscapes Instance Level Segmentation task.
3D Object Proposals using Stereo Imagery for Accurate Object Class Detection
Apr 25, 2017
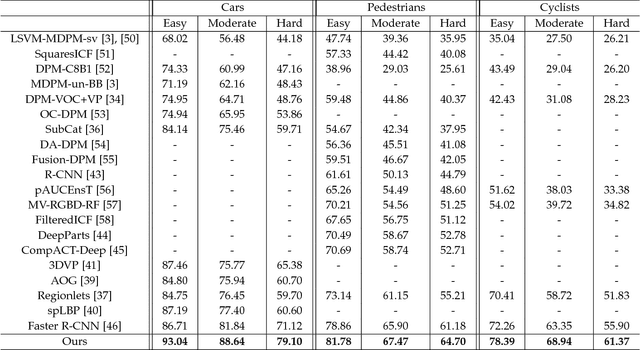
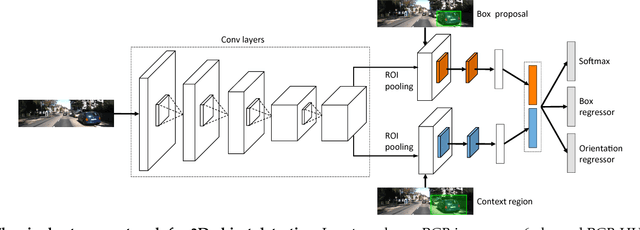
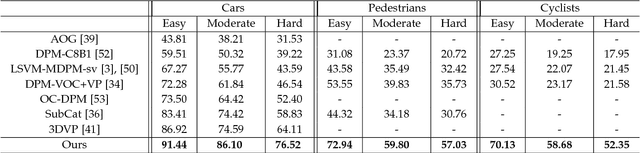
The goal of this paper is to perform 3D object detection in the context of autonomous driving. Our method first aims at generating a set of high-quality 3D object proposals by exploiting stereo imagery. We formulate the problem as minimizing an energy function that encodes object size priors, placement of objects on the ground plane as well as several depth informed features that reason about free space, point cloud densities and distance to the ground. We then exploit a CNN on top of these proposals to perform object detection. In particular, we employ a convolutional neural net (CNN) that exploits context and depth information to jointly regress to 3D bounding box coordinates and object pose. Our experiments show significant performance gains over existing RGB and RGB-D object proposal methods on the challenging KITTI benchmark. When combined with the CNN, our approach outperforms all existing results in object detection and orientation estimation tasks for all three KITTI object classes. Furthermore, we experiment also with the setting where LIDAR information is available, and show that using both LIDAR and stereo leads to the best result.
Annotating Object Instances with a Polygon-RNN
Apr 18, 2017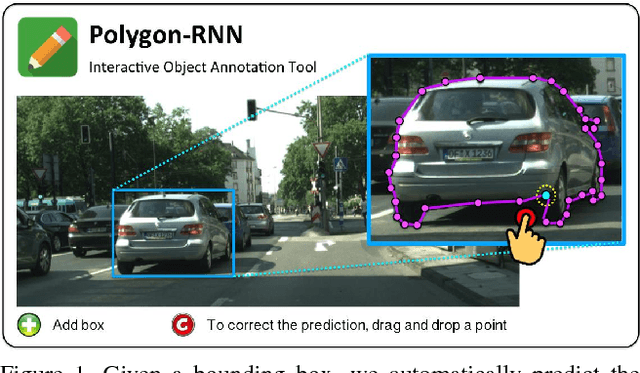
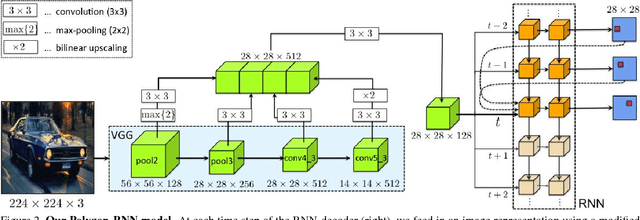
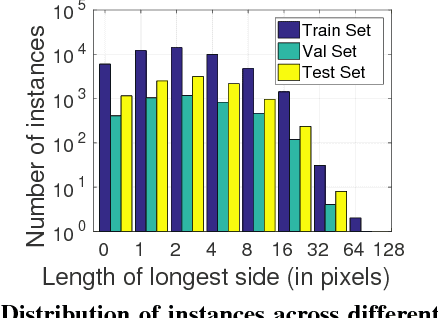
We propose an approach for semi-automatic annotation of object instances. While most current methods treat object segmentation as a pixel-labeling problem, we here cast it as a polygon prediction task, mimicking how most current datasets have been annotated. In particular, our approach takes as input an image crop and sequentially produces vertices of the polygon outlining the object. This allows a human annotator to interfere at any time and correct a vertex if needed, producing as accurate segmentation as desired by the annotator. We show that our approach speeds up the annotation process by a factor of 4.7 across all classes in Cityscapes, while achieving 78.4% agreement in IoU with original ground-truth, matching the typical agreement between human annotators. For cars, our speed-up factor is 7.3 for an agreement of 82.2%. We further show generalization capabilities of our approach to unseen datasets.
Normalizing the Normalizers: Comparing and Extending Network Normalization Schemes
Mar 06, 2017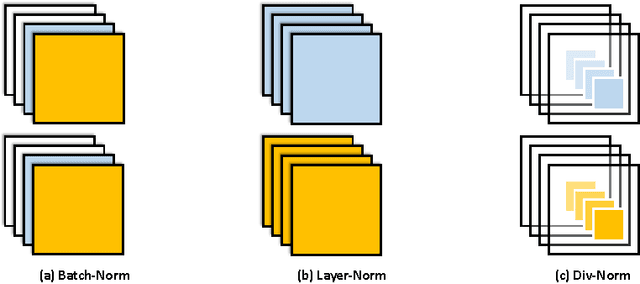
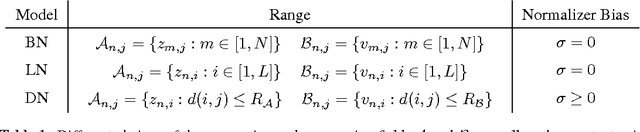
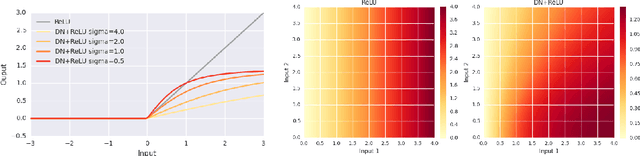
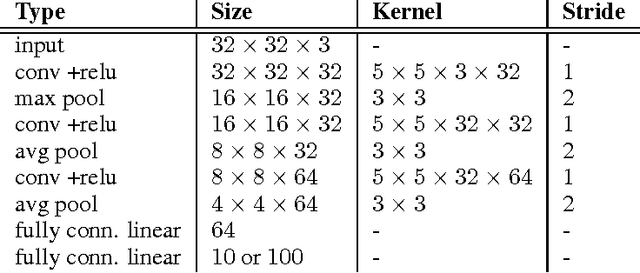
Normalization techniques have only recently begun to be exploited in supervised learning tasks. Batch normalization exploits mini-batch statistics to normalize the activations. This was shown to speed up training and result in better models. However its success has been very limited when dealing with recurrent neural networks. On the other hand, layer normalization normalizes the activations across all activities within a layer. This was shown to work well in the recurrent setting. In this paper we propose a unified view of normalization techniques, as forms of divisive normalization, which includes layer and batch normalization as special cases. Our second contribution is the finding that a small modification to these normalization schemes, in conjunction with a sparse regularizer on the activations, leads to significant benefits over standard normalization techniques. We demonstrate the effectiveness of our unified divisive normalization framework in the context of convolutional neural nets and recurrent neural networks, showing improvements over baselines in image classification, language modeling as well as super-resolution.
Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
Jan 25, 2017
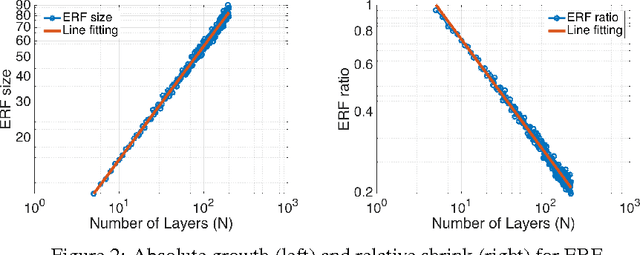
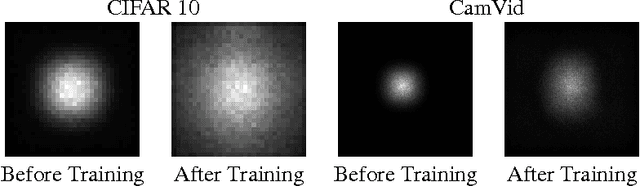
We study characteristics of receptive fields of units in deep convolutional networks. The receptive field size is a crucial issue in many visual tasks, as the output must respond to large enough areas in the image to capture information about large objects. We introduce the notion of an effective receptive field, and show that it both has a Gaussian distribution and only occupies a fraction of the full theoretical receptive field. We analyze the effective receptive field in several architecture designs, and the effect of nonlinear activations, dropout, sub-sampling and skip connections on it. This leads to suggestions for ways to address its tendency to be too small.
TorontoCity: Seeing the World with a Million Eyes
Dec 01, 2016
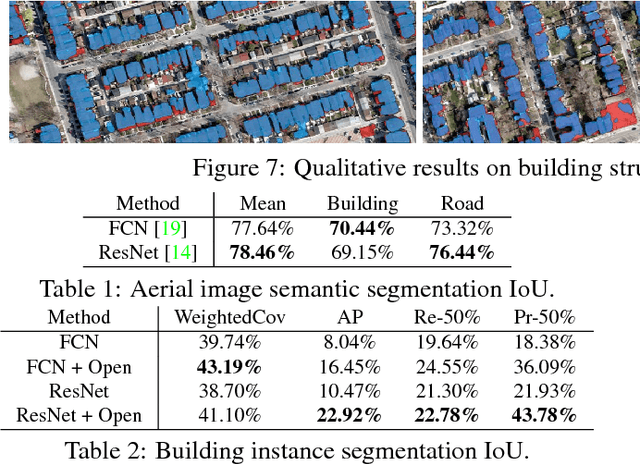
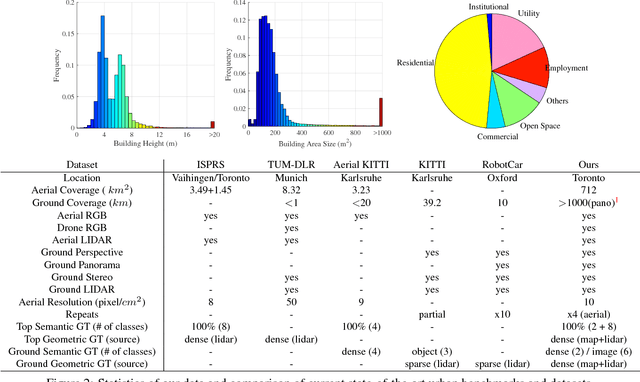

In this paper we introduce the TorontoCity benchmark, which covers the full greater Toronto area (GTA) with 712.5 $km^2$ of land, 8439 $km$ of road and around 400,000 buildings. Our benchmark provides different perspectives of the world captured from airplanes, drones and cars driving around the city. Manually labeling such a large scale dataset is infeasible. Instead, we propose to utilize different sources of high-precision maps to create our ground truth. Towards this goal, we develop algorithms that allow us to align all data sources with the maps while requiring minimal human supervision. We have designed a wide variety of tasks including building height estimation (reconstruction), road centerline and curb extraction, building instance segmentation, building contour extraction (reorganization), semantic labeling and scene type classification (recognition). Our pilot study shows that most of these tasks are still difficult for modern convolutional neural networks.
Song From PI: A Musically Plausible Network for Pop Music Generation
Nov 10, 2016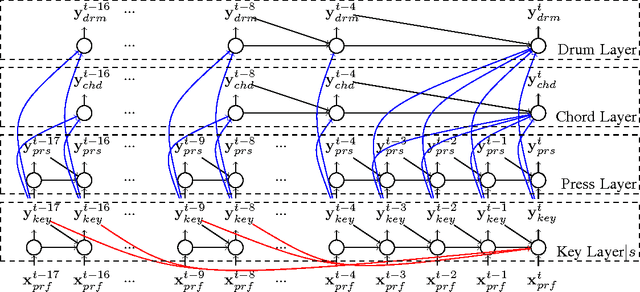


We present a novel framework for generating pop music. Our model is a hierarchical Recurrent Neural Network, where the layers and the structure of the hierarchy encode our prior knowledge about how pop music is composed. In particular, the bottom layers generate the melody, while the higher levels produce the drums and chords. We conduct several human studies that show strong preference of our generated music over that produced by the recent method by Google. We additionally show two applications of our framework: neural dancing and karaoke, as well as neural story singing.
Efficient Summarization with Read-Again and Copy Mechanism
Nov 10, 2016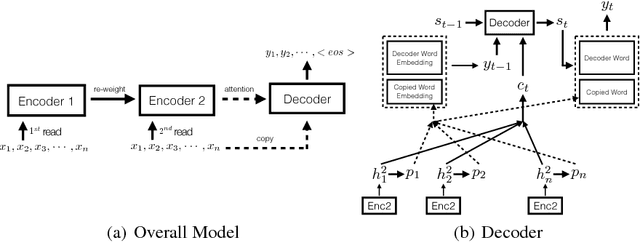
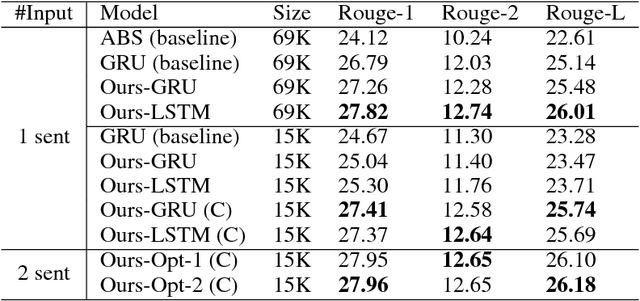
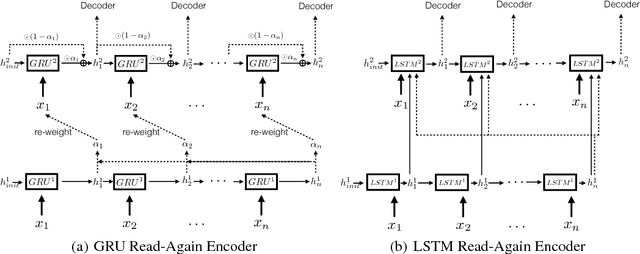
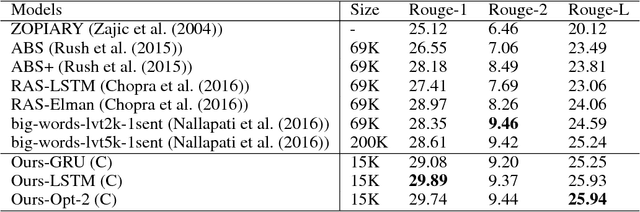
Encoder-decoder models have been widely used to solve sequence to sequence prediction tasks. However current approaches suffer from two shortcomings. First, the encoders compute a representation of each word taking into account only the history of the words it has read so far, yielding suboptimal representations. Second, current decoders utilize large vocabularies in order to minimize the problem of unknown words, resulting in slow decoding times. In this paper we address both shortcomings. Towards this goal, we first introduce a simple mechanism that first reads the input sequence before committing to a representation of each word. Furthermore, we propose a simple copy mechanism that is able to exploit very small vocabularies and handle out-of-vocabulary words. We demonstrate the effectiveness of our approach on the Gigaword dataset and DUC competition outperforming the state-of-the-art.
MovieQA: Understanding Stories in Movies through Question-Answering
Sep 21, 2016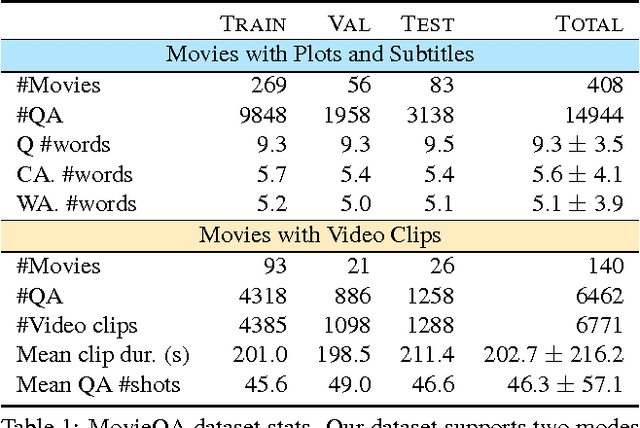

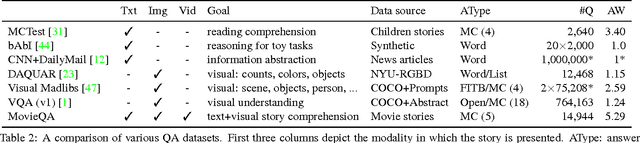
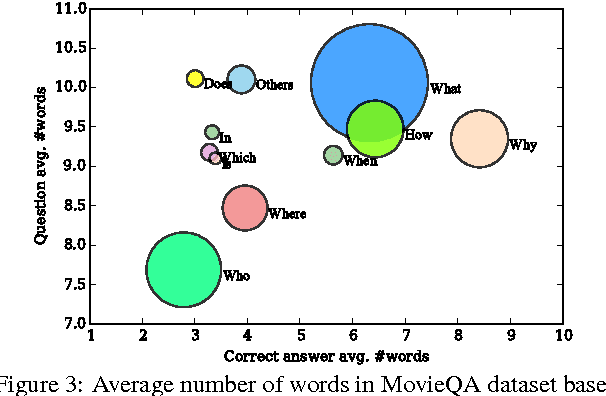
We introduce the MovieQA dataset which aims to evaluate automatic story comprehension from both video and text. The dataset consists of 14,944 questions about 408 movies with high semantic diversity. The questions range from simpler "Who" did "What" to "Whom", to "Why" and "How" certain events occurred. Each question comes with a set of five possible answers; a correct one and four deceiving answers provided by human annotators. Our dataset is unique in that it contains multiple sources of information -- video clips, plots, subtitles, scripts, and DVS. We analyze our data through various statistics and methods. We further extend existing QA techniques to show that question-answering with such open-ended semantics is hard. We make this data set public along with an evaluation benchmark to encourage inspiring work in this challenging domain.