 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Potential of Difficulty Prior in RL-based Multimodal Reasoning
May 19, 2025



In this work, we investigate how explicitly modeling problem's difficulty prior information shapes the effectiveness of reinforcement learning based fine-tuning for multimodal reasoning. Our exploration mainly comprises of following three perspective: First, through offline data curation, we analyze the U-shaped difficulty distribution of two given datasets using the base model by multi-round sampling, and then filter out prompts that are either too simple or extremely difficult to provide meaningful gradients and perform subsequent two-stage training. Second, we implement an online advantage differentiation, computing group-wise empirical accuracy as a difficulty proxy to adaptively reweight advantages estimation, providing stronger learning signals for more challenging problems. Finally, we introduce difficulty hints as explicit prompts for more complex samples in the second training stage, encouraging the model to calibrate its reasoning depth and perform reflective validation checks. Our comprehensive approach demonstrates significant performances across various multi-modal mathematical reasoning benchmarks with only 2K+0.6K two-stage training data.
NOFT: Test-Time Noise Finetune via Information Bottleneck for Highly Correlated Asset Creation
May 18, 2025The diffusion model has provided a strong tool for implementing text-to-image (T2I) and image-to-image (I2I) generation. Recently, topology and texture control are popular explorations, e.g., ControlNet, IP-Adapter, Ctrl-X, and DSG. These methods explicitly consider high-fidelity controllable editing based on external signals or diffusion feature manipulations. As for diversity, they directly choose different noise latents. However, the diffused noise is capable of implicitly representing the topological and textural manifold of the corresponding image. Moreover, it's an effective workbench to conduct the trade-off between content preservation and controllable variations. Previous T2I and I2I diffusion works do not explore the information within the compressed contextual latent. In this paper, we first propose a plug-and-play noise finetune NOFT module employed by Stable Diffusion to generate highly correlated and diverse images. We fine-tune seed noise or inverse noise through an optimal-transported (OT) information bottleneck (IB) with around only 14K trainable parameters and 10 minutes of training. Our test-time NOFT is good at producing high-fidelity image variations considering topology and texture alignments. Comprehensive experiments demonstrate that NOFT is a powerful general reimagine approach to efficiently fine-tune the 2D/3D AIGC assets with text or image guidance.
Video-SafetyBench: A Benchmark for Safety Evaluation of Video LVLMs
May 17, 2025The increasing deployment of Large Vision-Language Models (LVLMs) raises safety concerns under potential malicious inputs. However, existing multimodal safety evaluations primarily focus on model vulnerabilities exposed by static image inputs, ignoring the temporal dynamics of video that may induce distinct safety risks. To bridge this gap, we introduce Video-SafetyBench, the first comprehensive benchmark designed to evaluate the safety of LVLMs under video-text attacks. It comprises 2,264 video-text pairs spanning 48 fine-grained unsafe categories, each pairing a synthesized video with either a harmful query, which contains explicit malice, or a benign query, which appears harmless but triggers harmful behavior when interpreted alongside the video. To generate semantically accurate videos for safety evaluation, we design a controllable pipeline that decomposes video semantics into subject images (what is shown) and motion text (how it moves), which jointly guide the synthesis of query-relevant videos. To effectively evaluate uncertain or borderline harmful outputs, we propose RJScore, a novel LLM-based metric that incorporates the confidence of judge models and human-aligned decision threshold calibration. Extensive experiments show that benign-query video composition achieves average attack success rates of 67.2%, revealing consistent vulnerabilities to video-induced attacks. We believe Video-SafetyBench will catalyze future research into video-based safety evaluation and defense strategies.
DiCo: Revitalizing ConvNets for Scalable and Efficient Diffusion Modeling
May 16, 2025Diffusion Transformer (DiT), a promising diffusion model for visual generation, demonstrates impressive performance but incurs significant computational overhead. Intriguingly, analysis of pre-trained DiT models reveals that global self-attention is often redundant, predominantly capturing local patterns-highlighting the potential for more efficient alternatives. In this paper, we revisit convolution as an alternative building block for constructing efficient and expressive diffusion models. However, naively replacing self-attention with convolution typically results in degraded performance. Our investigations attribute this performance gap to the higher channel redundancy in ConvNets compared to Transformers. To resolve this, we introduce a compact channel attention mechanism that promotes the activation of more diverse channels, thereby enhancing feature diversity. This leads to Diffusion ConvNet (DiCo), a family of diffusion models built entirely from standard ConvNet modules, offering strong generative performance with significant efficiency gains. On class-conditional ImageNet benchmarks, DiCo outperforms previous diffusion models in both image quality and generation speed. Notably, DiCo-XL achieves an FID of 2.05 at 256x256 resolution and 2.53 at 512x512, with a 2.7x and 3.1x speedup over DiT-XL/2, respectively. Furthermore, our largest model, DiCo-H, scaled to 1B parameters, reaches an FID of 1.90 on ImageNet 256x256-without any additional supervision during training. Code: https://github.com/shallowdream204/DiCo.
Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory
May 16, 2025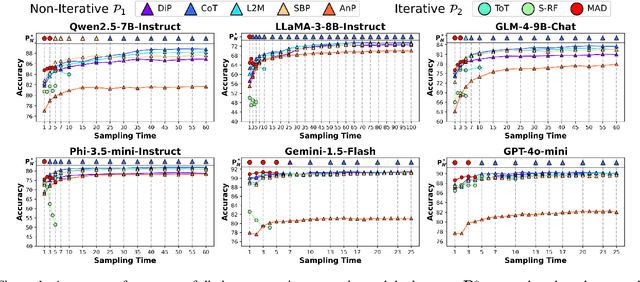


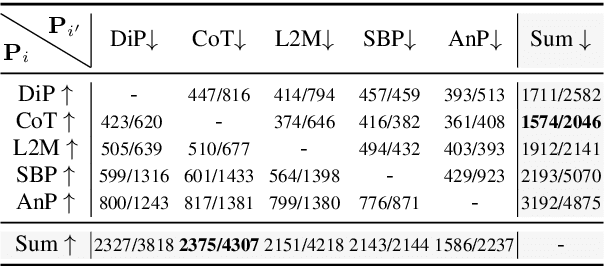
Recently, scaling test-time compute on Large Language Models (LLM) has garnered wide attention. However, there has been limited investigation of how various reasoning prompting strategies perform as scaling. In this paper, we focus on a standard and realistic scaling setting: majority voting. We systematically conduct experiments on 6 LLMs $\times$ 8 prompting strategies $\times$ 6 benchmarks. Experiment results consistently show that as the sampling time and computational overhead increase, complicated prompting strategies with superior initial performance gradually fall behind simple Chain-of-Thought. We analyze this phenomenon and provide theoretical proofs. Additionally, we propose a method according to probability theory to quickly and accurately predict the scaling performance and select the best strategy under large sampling times without extra resource-intensive inference in practice. It can serve as the test-time scaling law for majority voting. Furthermore, we introduce two ways derived from our theoretical analysis to significantly improve the scaling performance. We hope that our research can promote to re-examine the role of complicated prompting, unleash the potential of simple prompting strategies, and provide new insights for enhancing test-time scaling performance.
Visual Watermarking in the Era of Diffusion Models: Advances and Challenges
May 13, 2025As generative artificial intelligence technologies like Stable Diffusion advance, visual content becomes more vulnerable to misuse, raising concerns about copyright infringement. Visual watermarks serve as effective protection mechanisms, asserting ownership and deterring unauthorized use. Traditional deepfake detection methods often rely on passive techniques that struggle with sophisticated manipulations. In contrast, diffusion models enhance detection accuracy by allowing for the effective learning of features, enabling the embedding of imperceptible and robust watermarks. We analyze the strengths and challenges of watermark techniques related to diffusion models, focusing on their robustness and application in watermark generation. By exploring the integration of advanced diffusion models and watermarking security, we aim to advance the discourse on preserving watermark robustness against evolving forgery threats. It emphasizes the critical importance of developing innovative solutions to protect digital content and ensure the preservation of ownership rights in the era of generative AI.
R-TPT: Improving Adversarial Robustness of Vision-Language Models through Test-Time Prompt Tuning
Apr 15, 2025Vision-language models (VLMs), such as CLIP, have gained significant popularity as foundation models, with numerous fine-tuning methods developed to enhance performance on downstream tasks. However, due to their inherent vulnerability and the common practice of selecting from a limited set of open-source models, VLMs suffer from a higher risk of adversarial attacks than traditional vision models. Existing defense techniques typically rely on adversarial fine-tuning during training, which requires labeled data and lacks of flexibility for downstream tasks. To address these limitations, we propose robust test-time prompt tuning (R-TPT), which mitigates the impact of adversarial attacks during the inference stage. We first reformulate the classic marginal entropy objective by eliminating the term that introduces conflicts under adversarial conditions, retaining only the pointwise entropy minimization. Furthermore, we introduce a plug-and-play reliability-based weighted ensembling strategy, which aggregates useful information from reliable augmented views to strengthen the defense. R-TPT enhances defense against adversarial attacks without requiring labeled training data while offering high flexibility for inference tasks. Extensive experiments on widely used benchmarks with various attacks demonstrate the effectiveness of R-TPT. The code is available in https://github.com/TomSheng21/R-TPT.
Do We Really Need Curated Malicious Data for Safety Alignment in Multi-modal Large Language Models?
Apr 14, 2025Multi-modal large language models (MLLMs) have made significant progress, yet their safety alignment remains limited. Typically, current open-source MLLMs rely on the alignment inherited from their language module to avoid harmful generations. However, the lack of safety measures specifically designed for multi-modal inputs creates an alignment gap, leaving MLLMs vulnerable to vision-domain attacks such as typographic manipulation. Current methods utilize a carefully designed safety dataset to enhance model defense capability, while the specific knowledge or patterns acquired from the high-quality dataset remain unclear. Through comparison experiments, we find that the alignment gap primarily arises from data distribution biases, while image content, response quality, or the contrastive behavior of the dataset makes little contribution to boosting multi-modal safety. To further investigate this and identify the key factors in improving MLLM safety, we propose finetuning MLLMs on a small set of benign instruct-following data with responses replaced by simple, clear rejection sentences. Experiments show that, without the need for labor-intensive collection of high-quality malicious data, model safety can still be significantly improved, as long as a specific fraction of rejection data exists in the finetuning set, indicating the security alignment is not lost but rather obscured during multi-modal pretraining or instruction finetuning. Simply correcting the underlying data bias could narrow the safety gap in the vision domain.
ID-Cloak: Crafting Identity-Specific Cloaks Against Personalized Text-to-Image Generation
Feb 12, 2025Personalized text-to-image models allow users to generate images of new concepts from several reference photos, thereby leading to critical concerns regarding civil privacy. Although several anti-personalization techniques have been developed, these methods typically assume that defenders can afford to design a privacy cloak corresponding to each specific image. However, due to extensive personal images shared online, image-specific methods are limited by real-world practical applications. To address this issue, we are the first to investigate the creation of identity-specific cloaks (ID-Cloak) that safeguard all images belong to a specific identity. Specifically, we first model an identity subspace that preserves personal commonalities and learns diverse contexts to capture the image distribution to be protected. Then, we craft identity-specific cloaks with the proposed novel objective that encourages the cloak to guide the model away from its normal output within the subspace. Extensive experiments show that the generated universal cloak can effectively protect the images. We believe our method, along with the proposed identity-specific cloak setting, marks a notable advance in realistic privacy protection.
Survey on AI-Generated Media Detection: From Non-MLLM to MLLM
Feb 07, 2025The proliferation of AI-generated media poses significant challenges to information authenticity and social trust, making reliable detection methods highly demanded. Methods for detecting AI-generated media have evolved rapidly, paralleling the advancement of Multimodal Large Language Models (MLLMs). Current detection approaches can be categorized into two main groups: Non-MLLM-based and MLLM-based methods. The former employs high-precision, domain-specific detectors powered by deep learning techniques, while the latter utilizes general-purpose detectors based on MLLMs that integrate authenticity verification, explainability, and localization capabilities. Despite significant progress in this field, there remains a gap in literature regarding a comprehensive survey that examines the transition from domain-specific to general-purpose detection methods. This paper addresses this gap by providing a systematic review of both approaches, analyzing them from single-modal and multi-modal perspectives. We present a detailed comparative analysis of these categories, examining their methodological similarities and differences. Through this analysis, we explore potential hybrid approaches and identify key challenges in forgery detection, providing direction for future research. Additionally, as MLLMs become increasingly prevalent in detection tasks, ethical and security considerations have emerged as critical global concerns. We examine the regulatory landscape surrounding Generative AI (GenAI) across various jurisdictions, offering valuable insights for researchers and practitioners in this field.