 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplementary Explanations for Effective In-Context Learning
Nov 25, 2022Large language models (LLMs) have exhibited remarkable capabilities in learning from explanations in prompts. Yet, there has been limited understanding of what makes explanations effective for in-context learning. This work aims to better understand the mechanisms by which explanations are used for in-context learning. We first study the impact of two different factors on prompting performance when using explanations: the computation trace (the way the solution is decomposed) and the natural language of the prompt. By perturbing explanations on three controlled tasks, we show that both factors contribute to the effectiveness of explanations, indicating that LLMs do faithfully follow the explanations to some extent. We further study how to form maximally effective sets of explanations for solving a given test query. We find that LLMs can benefit from the complementarity of the explanation set as they are able to fuse different reasoning specified by individual exemplars in prompts. Additionally, having relevant exemplars also contributes to more effective prompts. Therefore, we propose a maximal-marginal-relevance-based exemplar selection approach for constructing exemplar sets that are both relevant as well as complementary, which successfully improves the in-context learning performance across three real-world tasks on multiple LLMs.
Improving In-Context Few-Shot Learning via Self-Supervised Training
May 03, 2022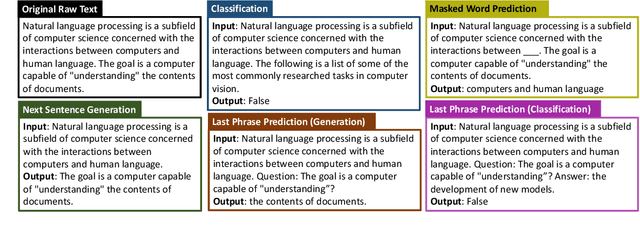

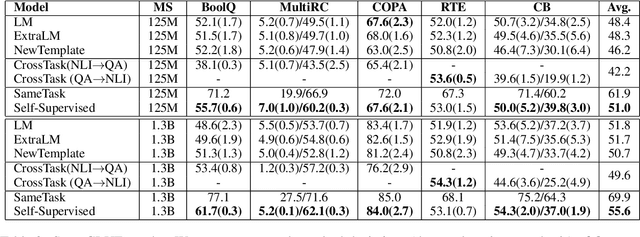

Self-supervised pretraining has made few-shot learning possible for many NLP tasks. But the pretraining objectives are not typically adapted specifically for in-context few-shot learning. In this paper, we propose to use self-supervision in an intermediate training stage between pretraining and downstream few-shot usage with the goal to teach the model to perform in-context few shot learning. We propose and evaluate four self-supervised objectives on two benchmarks. We find that the intermediate self-supervision stage produces models that outperform strong baselines. Ablation study shows that several factors affect the downstream performance, such as the amount of training data and the diversity of the self-supervised objectives. Human-annotated cross-task supervision and self-supervision are complementary. Qualitative analysis suggests that the self-supervised-trained models are better at following task requirements.
Efficient Large Scale Language Modeling with Mixtures of Experts
Dec 20, 2021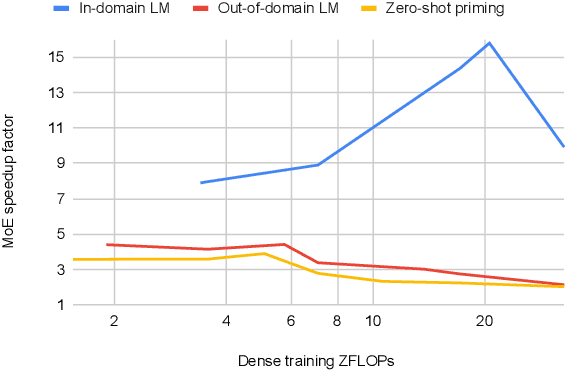
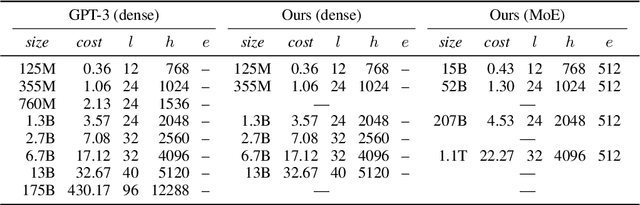
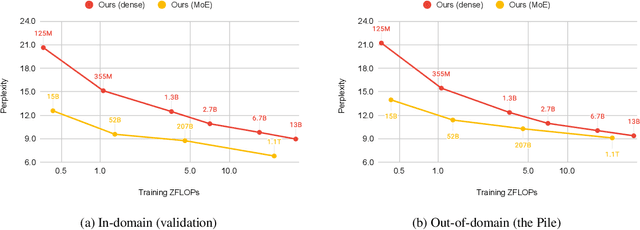
Mixture of Experts layers (MoEs) enable efficient scaling of language models through conditional computation. This paper presents a detailed empirical study of how autoregressive MoE language models scale in comparison with dense models in a wide range of settings: in- and out-of-domain language modeling, zero- and few-shot priming, and full fine-tuning. With the exception of fine-tuning, we find MoEs to be substantially more compute efficient. At more modest training budgets, MoEs can match the performance of dense models using $\sim$4 times less compute. This gap narrows at scale, but our largest MoE model (1.1T parameters) consistently outperforms a compute-equivalent dense model (6.7B parameters). Overall, this performance gap varies greatly across tasks and domains, suggesting that MoE and dense models generalize differently in ways that are worthy of future study. We make our code and models publicly available for research use.
Few-shot Learning with Multilingual Language Models
Dec 20, 2021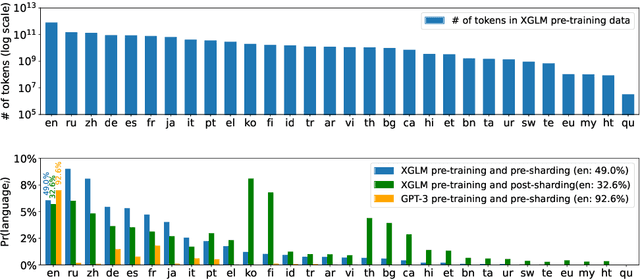
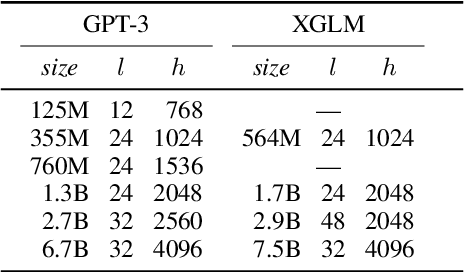
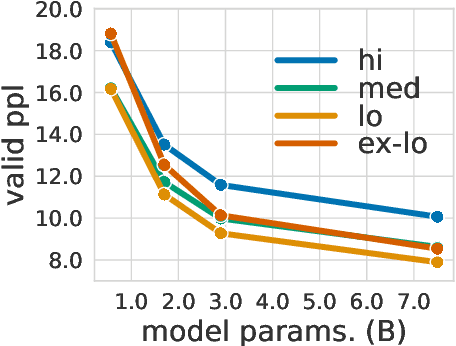

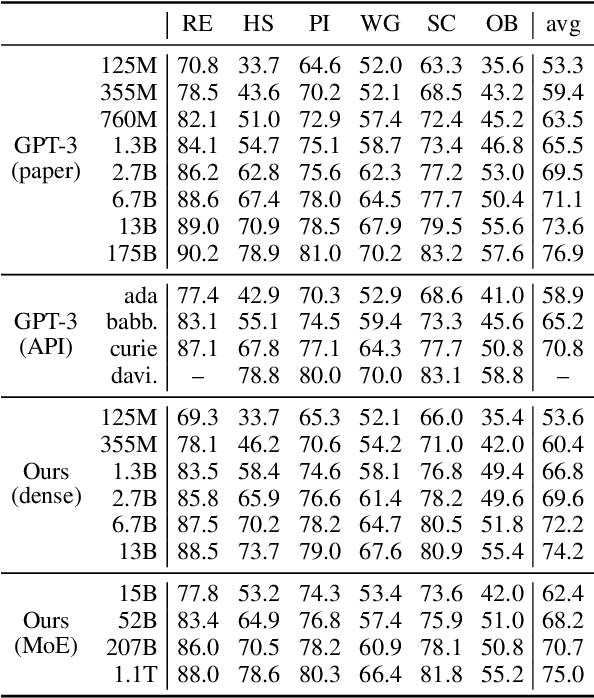
Large-scale autoregressive language models such as GPT-3 are few-shot learners that can perform a wide range of language tasks without fine-tuning. While these models are known to be able to jointly represent many different languages, their training data is dominated by English, potentially limiting their cross-lingual generalization. In this work, we train multilingual autoregressive language models on a balanced corpus covering a diverse set of languages, and study their few- and zero-shot learning capabilities in a wide range of tasks. Our largest model with 7.5 billion parameters sets new state of the art in few-shot learning in more than 20 representative languages, outperforming GPT-3 of comparable size in multilingual commonsense reasoning (with +7.4% absolute accuracy improvement in 0-shot settings and +9.4% in 4-shot settings) and natural language inference (+5.4% in each of 0-shot and 4-shot settings). On the FLORES-101 machine translation benchmark, our model outperforms GPT-3 on 171 out of 182 translation directions with 32 training examples, while surpassing the official supervised baseline in 45 directions. We present a detailed analysis of where the model succeeds and fails, showing in particular that it enables cross-lingual in-context learning on some tasks, while there is still room for improvement on surface form robustness and adaptation to tasks that do not have a natural cloze form. Finally, we evaluate our models in social value tasks such as hate speech detection in five languages and find it has limitations similar to comparable sized GPT-3 models.
A Proposition-Level Clustering Approach for Multi-Document Summarization
Dec 16, 2021
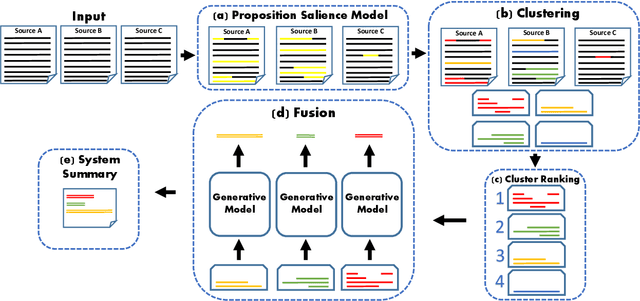

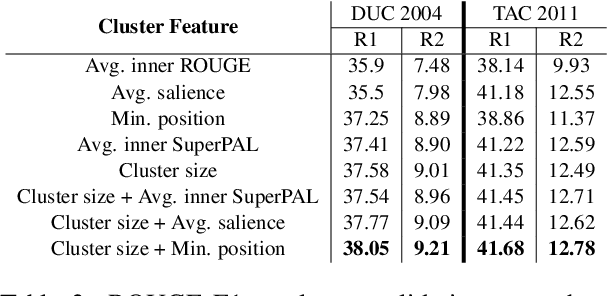
Text clustering methods were traditionally incorporated into multi-document summarization (MDS) as a means for coping with considerable information repetition. Clusters were leveraged to indicate information saliency and to avoid redundancy. These methods focused on clustering sentences, even though closely related sentences also usually contain non-aligning information. In this work, we revisit the clustering approach, grouping together propositions for more precise information alignment. Specifically, our method detects salient propositions, clusters them into paraphrastic clusters, and generates a representative sentence for each cluster by fusing its propositions. Our summarization method improves over the previous state-of-the-art MDS method in the DUC 2004 and TAC 2011 datasets, both in automatic ROUGE scores and human preference.
Multi-Document Keyphrase Extraction: A Literature Review and the First Dataset
Oct 03, 2021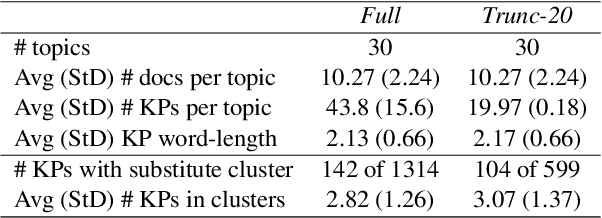
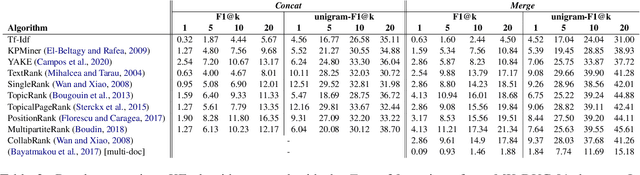
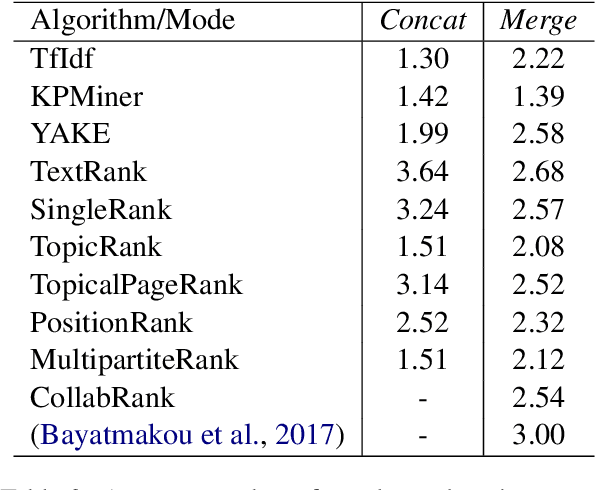
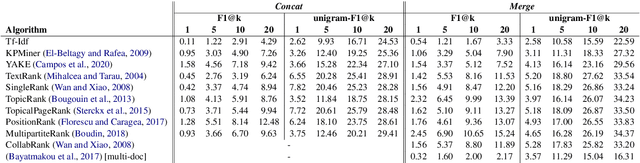
Keyphrase extraction has been comprehensively researched within the single-document setting, with an abundance of methods and a wealth of datasets. In contrast, multi-document keyphrase extraction has been infrequently studied, despite its utility for describing sets of documents, and its use in summarization. Moreover, no dataset existed for multi-document keyphrase extraction, hindering the progress of the task. Recent advances in multi-text processing make the task an even more appealing challenge to pursue. To initiate this pursuit, we present here the first literature review and the first dataset for the task, MK-DUC-01, which can serve as a new benchmark. We test several keyphrase extraction baselines on our data and show their results.
iFacetSum: Coreference-based Interactive Faceted Summarization for Multi-Document Exploration
Sep 23, 2021

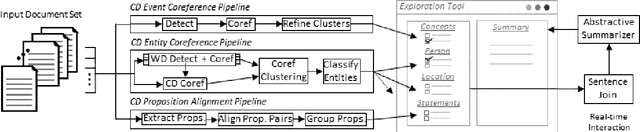
We introduce iFacetSum, a web application for exploring topical document sets. iFacetSum integrates interactive summarization together with faceted search, by providing a novel faceted navigation scheme that yields abstractive summaries for the user's selections. This approach offers both a comprehensive overview as well as concise details regarding subtopics of choice. Fine-grained facets are automatically produced based on cross-document coreference pipelines, rendering generic concepts, entities and statements surfacing in the source texts. We analyze the effectiveness of our application through small-scale user studies, which suggest the usefulness of our approach.
Dual Reinforcement-Based Specification Generation for Image De-Rendering
Mar 02, 2021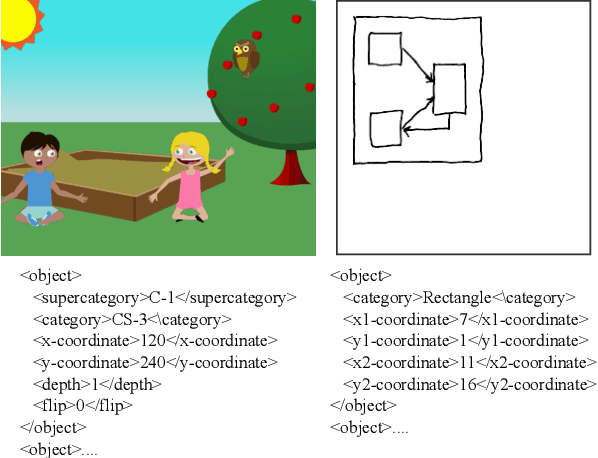
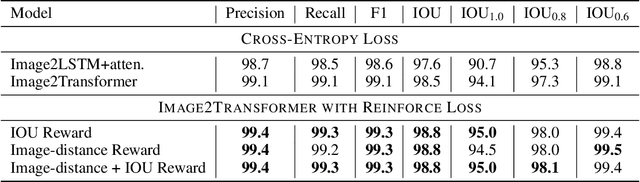

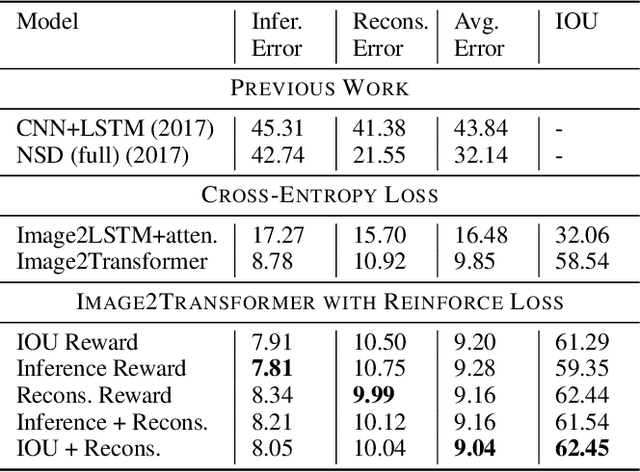
Advances in deep learning have led to promising progress in inferring graphics programs by de-rendering computer-generated images. However, current methods do not explore which decoding methods lead to better inductive bias for inferring graphics programs. In our work, we first explore the effectiveness of LSTM-RNN versus Transformer networks as decoders for order-independent graphics programs. Since these are sequence models, we must choose an ordering of the objects in the graphics programs for likelihood training. We found that the LSTM performance was highly sensitive to the sequence ordering (random order vs. pattern-based order), while Transformer performance was roughly independent of the sequence ordering. Further, we present a policy gradient based reinforcement learning approach for better inductive bias in the decoder via multiple diverse rewards based both on the graphics program specification and the rendered image. We also explore the combination of these complementary rewards. We achieve state-of-the-art results on two graphics program generation datasets.
Data Augmentation for Abstractive Query-Focused Multi-Document Summarization
Mar 02, 2021
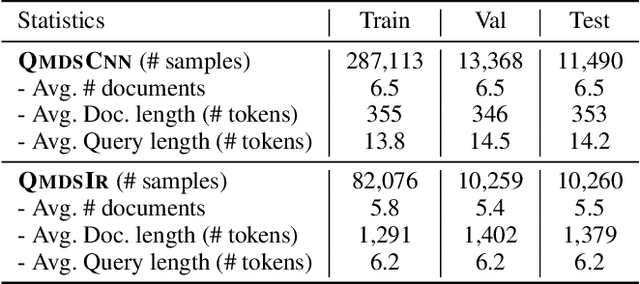
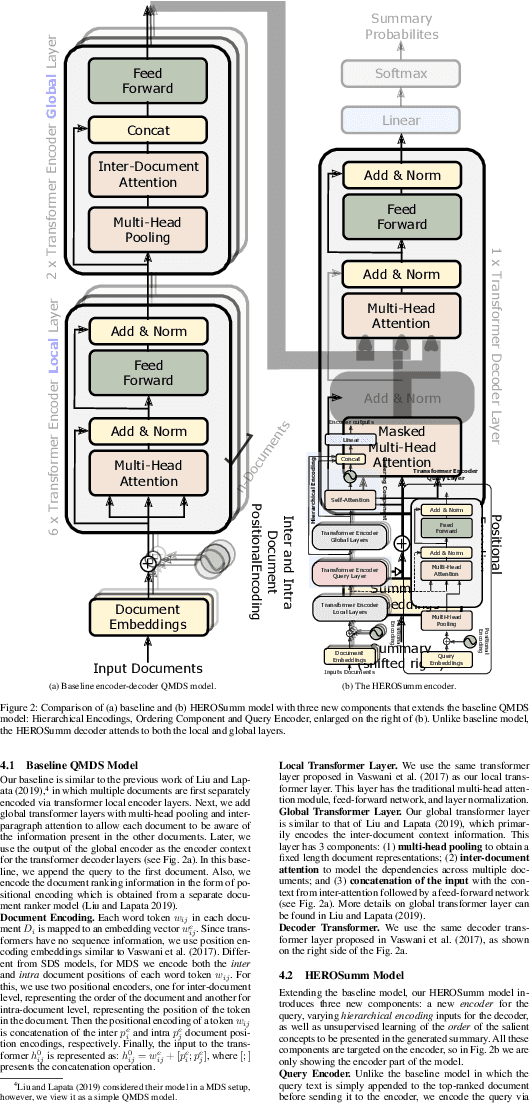
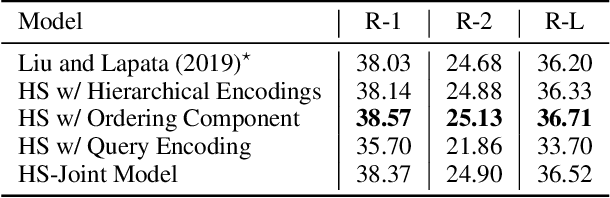
The progress in Query-focused Multi-Document Summarization (QMDS) has been limited by the lack of sufficient largescale high-quality training datasets. We present two QMDS training datasets, which we construct using two data augmentation methods: (1) transferring the commonly used single-document CNN/Daily Mail summarization dataset to create the QMDSCNN dataset, and (2) mining search-query logs to create the QMDSIR dataset. These two datasets have complementary properties, i.e., QMDSCNN has real summaries but queries are simulated, while QMDSIR has real queries but simulated summaries. To cover both these real summary and query aspects, we build abstractive end-to-end neural network models on the combined datasets that yield new state-of-the-art transfer results on DUC datasets. We also introduce new hierarchical encoders that enable a more efficient encoding of the query together with multiple documents. Empirical results demonstrate that our data augmentation and encoding methods outperform baseline models on automatic metrics, as well as on human evaluations along multiple attributes.
DORB: Dynamically Optimizing Multiple Rewards with Bandits
Nov 15, 2020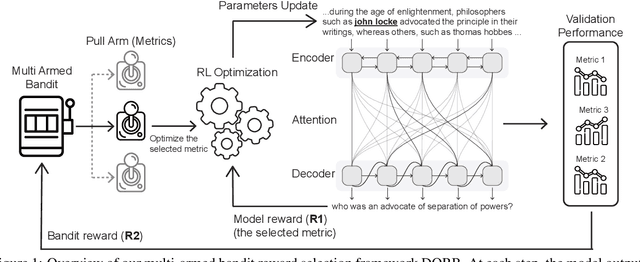
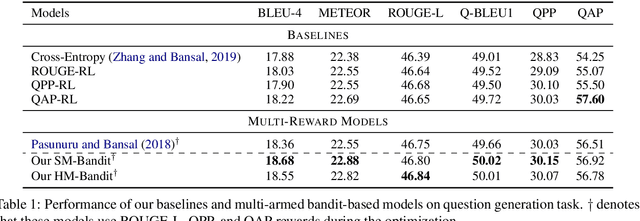
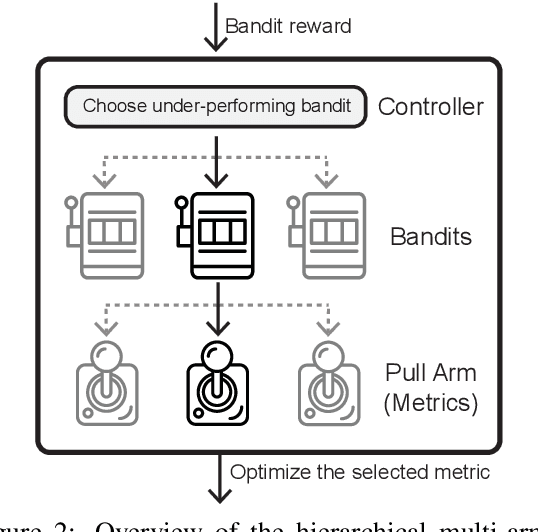
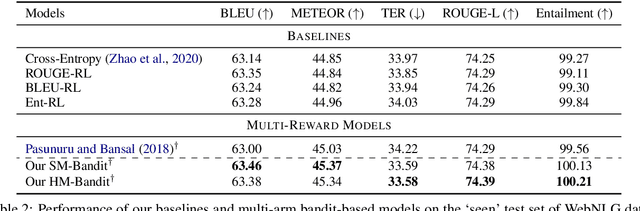
Policy gradients-based reinforcement learning has proven to be a promising approach for directly optimizing non-differentiable evaluation metrics for language generation tasks. However, optimizing for a specific metric reward leads to improvements in mostly that metric only, suggesting that the model is gaming the formulation of that metric in a particular way without often achieving real qualitative improvements. Hence, it is more beneficial to make the model optimize multiple diverse metric rewards jointly. While appealing, this is challenging because one needs to manually decide the importance and scaling weights of these metric rewards. Further, it is important to consider using a dynamic combination and curriculum of metric rewards that flexibly changes over time. Considering the above aspects, in our work, we automate the optimization of multiple metric rewards simultaneously via a multi-armed bandit approach (DORB), where at each round, the bandit chooses which metric reward to optimize next, based on expected arm gains. We use the Exp3 algorithm for bandits and formulate two approaches for bandit rewards: (1) Single Multi-reward Bandit (SM-Bandit); (2) Hierarchical Multi-reward Bandit (HM-Bandit). We empirically show the effectiveness of our approaches via various automatic metrics and human evaluation on two important NLG tasks: question generation and data-to-text generation, including on an unseen-test transfer setup. Finally, we present interpretable analyses of the learned bandit curriculum over the optimized rewards.