 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised multimodal neuroimaging yields predictive representations for a spectrum of Alzheimer's phenotypes
Sep 07, 2022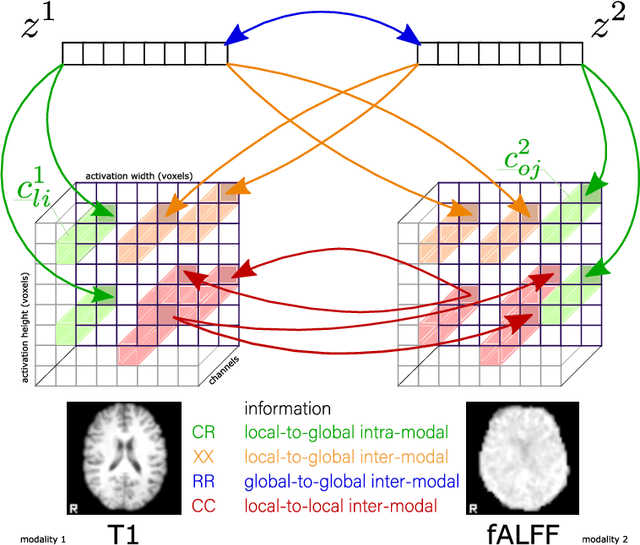
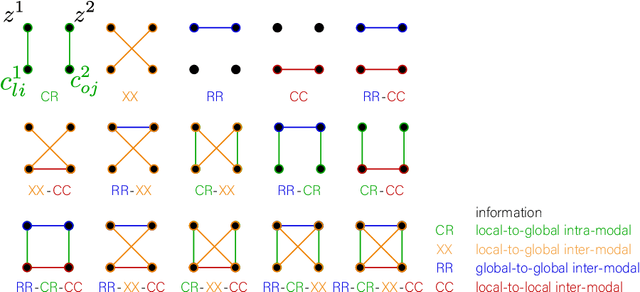

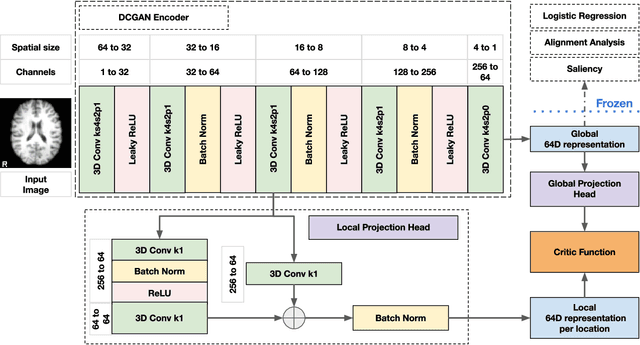
Recent neuroimaging studies that focus on predicting brain disorders via modern machine learning approaches commonly include a single modality and rely on supervised over-parameterized models.However, a single modality provides only a limited view of the highly complex brain. Critically, supervised models in clinical settings lack accurate diagnostic labels for training. Coarse labels do not capture the long-tailed spectrum of brain disorder phenotypes, which leads to a loss of generalizability of the model that makes them less useful in diagnostic settings. This work presents a novel multi-scale coordinated framework for learning multiple representations from multimodal neuroimaging data. We propose a general taxonomy of informative inductive biases to capture unique and joint information in multimodal self-supervised fusion. The taxonomy forms a family of decoder-free models with reduced computational complexity and a propensity to capture multi-scale relationships between local and global representations of the multimodal inputs. We conduct a comprehensive evaluation of the taxonomy using functional and structural magnetic resonance imaging (MRI) data across a spectrum of Alzheimer's disease phenotypes and show that self-supervised models reveal disorder-relevant brain regions and multimodal links without access to the labels during pre-training. The proposed multimodal self-supervised learning yields representations with improved classification performance for both modalities. The concomitant rich and flexible unsupervised deep learning framework captures complex multimodal relationships and provides predictive performance that meets or exceeds that of a more narrow supervised classification analysis. We present elaborate quantitative evidence of how this framework can significantly advance our search for missing links in complex brain disorders.
The Sandbox Environment for Generalizable Agent Research (SEGAR)
Mar 19, 2022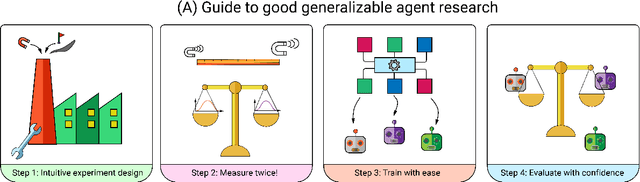
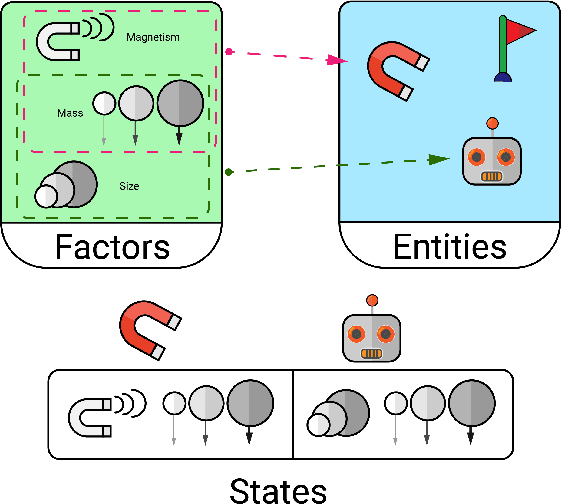
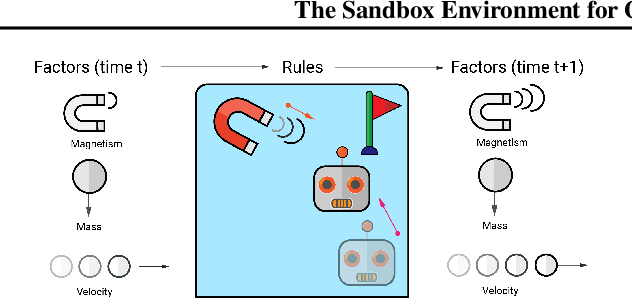
A broad challenge of research on generalization for sequential decision-making tasks in interactive environments is designing benchmarks that clearly landmark progress. While there has been notable headway, current benchmarks either do not provide suitable exposure nor intuitive control of the underlying factors, are not easy-to-implement, customizable, or extensible, or are computationally expensive to run. We built the Sandbox Environment for Generalizable Agent Research (SEGAR) with all of these things in mind. SEGAR improves the ease and accountability of generalization research in RL, as generalization objectives can be easy designed by specifying task distributions, which in turns allows the researcher to measure the nature of the generalization objective. We present an overview of SEGAR and how it contributes to these goals, as well as experiments that demonstrate a few types of research questions SEGAR can help answer.
Robust Contrastive Learning against Noisy Views
Jan 12, 2022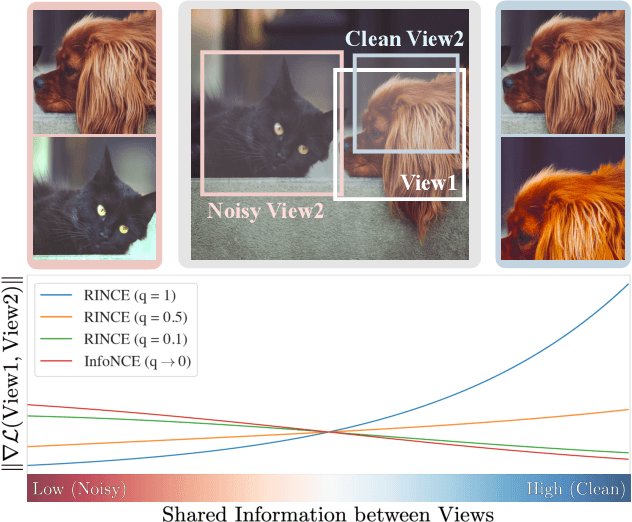
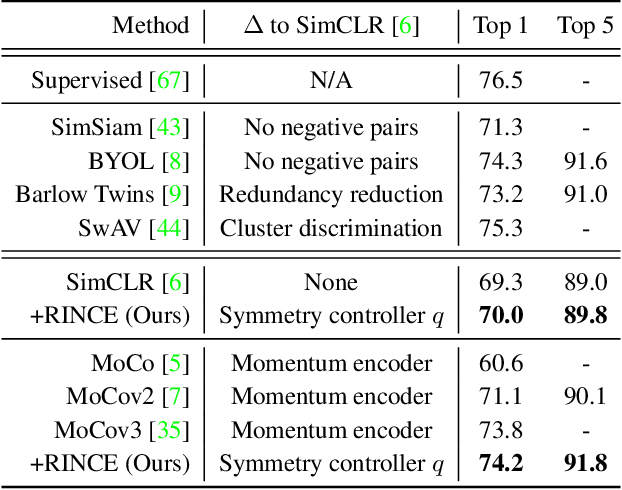

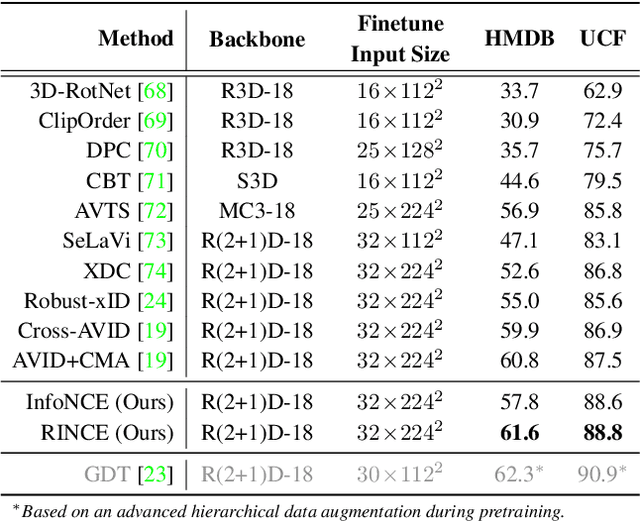
Contrastive learning relies on an assumption that positive pairs contain related views, e.g., patches of an image or co-occurring multimodal signals of a video, that share certain underlying information about an instance. But what if this assumption is violated? The literature suggests that contrastive learning produces suboptimal representations in the presence of noisy views, e.g., false positive pairs with no apparent shared information. In this work, we propose a new contrastive loss function that is robust against noisy views. We provide rigorous theoretical justifications by showing connections to robust symmetric losses for noisy binary classification and by establishing a new contrastive bound for mutual information maximization based on the Wasserstein distance measure. The proposed loss is completely modality-agnostic and a simple drop-in replacement for the InfoNCE loss, which makes it easy to apply to existing contrastive frameworks. We show that our approach provides consistent improvements over the state-of-the-art on image, video, and graph contrastive learning benchmarks that exhibit a variety of real-world noise patterns.
Cross-Trajectory Representation Learning for Zero-Shot Generalization in RL
Jun 04, 2021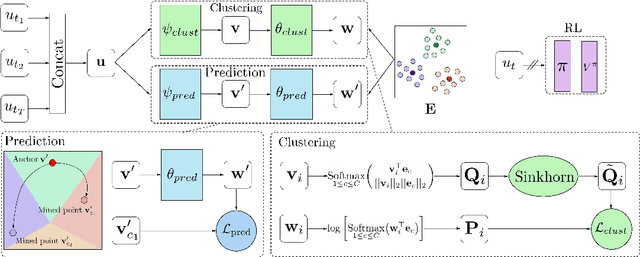
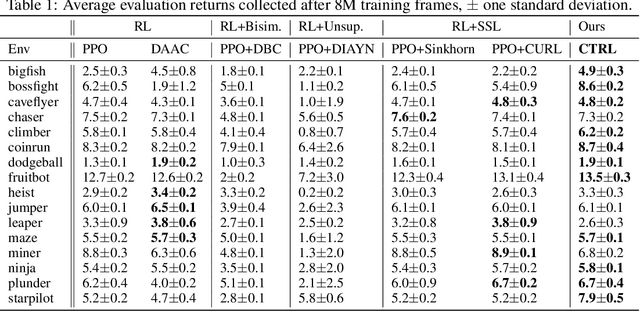
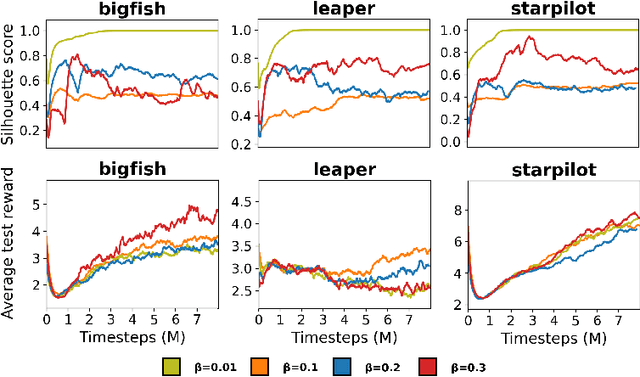

A highly desirable property of a reinforcement learning (RL) agent -- and a major difficulty for deep RL approaches -- is the ability to generalize policies learned on a few tasks over a high-dimensional observation space to similar tasks not seen during training. Many promising approaches to this challenge consider RL as a process of training two functions simultaneously: a complex nonlinear encoder that maps high-dimensional observations to a latent representation space, and a simple linear policy over this space. We posit that a superior encoder for zero-shot generalization in RL can be trained by using solely an auxiliary SSL objective if the training process encourages the encoder to map behaviorally similar observations to similar representations, as reward-based signal can cause overfitting in the encoder (Raileanu et al., 2021). We propose Cross-Trajectory Representation Learning (CTRL), a method that runs within an RL agent and conditions its encoder to recognize behavioral similarity in observations by applying a novel SSL objective to pairs of trajectories from the agent's policies. CTRL can be viewed as having the same effect as inducing a pseudo-bisimulation metric but, crucially, avoids the use of rewards and associated overfitting risks. Our experiments ablate various components of CTRL and demonstrate that in combination with PPO it achieves better generalization performance on the challenging Procgen benchmark suite (Cobbe et al., 2020).
Understanding by Understanding Not: Modeling Negation in Language Models
May 07, 2021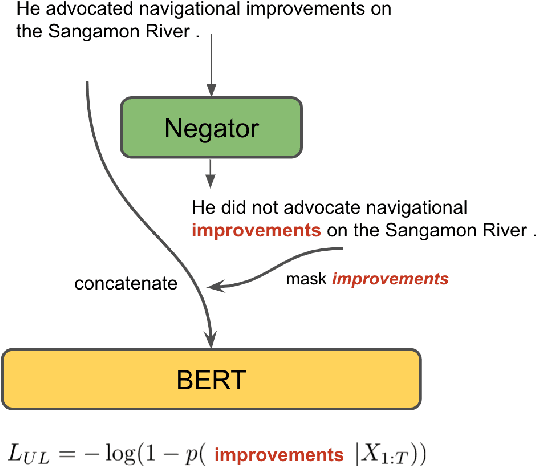



Negation is a core construction in natural language. Despite being very successful on many tasks, state-of-the-art pre-trained language models often handle negation incorrectly. To improve language models in this regard, we propose to augment the language modeling objective with an unlikelihood objective that is based on negated generic sentences from a raw text corpus. By training BERT with the resulting combined objective we reduce the mean top~1 error rate to 4% on the negated LAMA dataset. We also see some improvements on the negated NLI benchmarks.
Zero-Shot Learning from scratch (ZFS): leveraging local compositional representations
Oct 22, 2020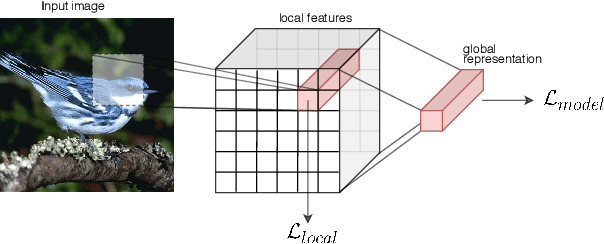
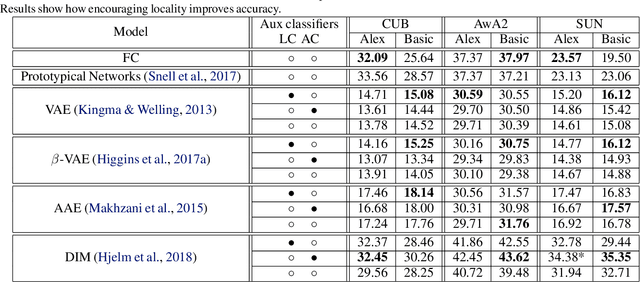
Zero-shot classification is a generalization task where no instance from the target classes is seen during training. To allow for test-time transfer, each class is annotated with semantic information, commonly in the form of attributes or text descriptions. While classical zero-shot learning does not explicitly forbid using information from other datasets, the approaches that achieve the best absolute performance on image benchmarks rely on features extracted from encoders pretrained on Imagenet. This approach relies on hyper-optimized Imagenet-relevant parameters from the supervised classification setting, entangling important questions about the suitability of those parameters and how they were learned with more fundamental questions about representation learning and generalization. To remove these distractors, we propose a more challenging setting: Zero-Shot Learning from scratch (ZFS), which explicitly forbids the use of encoders fine-tuned on other datasets. Our analysis on this setting highlights the importance of local information, and compositional representations.
Implicit Regularization in Deep Learning: A View from Function Space
Aug 03, 2020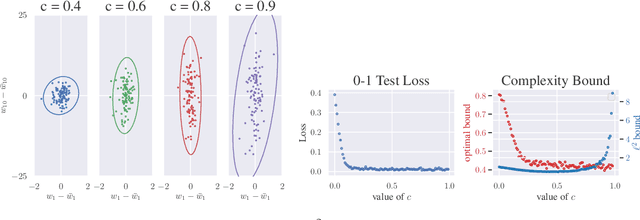
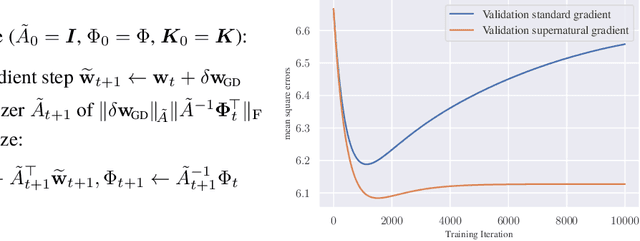
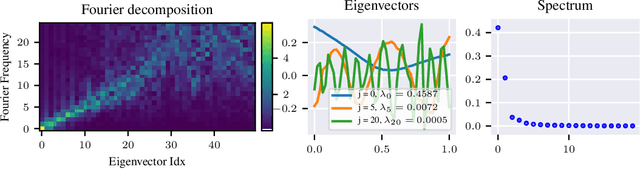
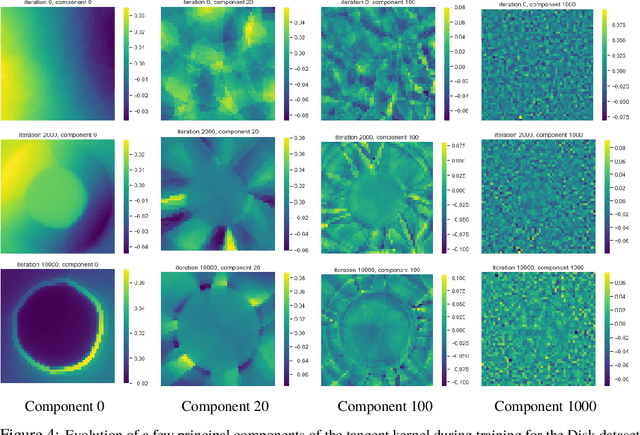
We approach the problem of implicit regularization in deep learning from a geometrical viewpoint. We highlight a possible regularization effect induced by a dynamical alignment of the neural tangent features introduced by Jacot et al, along a small number of task-relevant directions. By extrapolating a new analysis of Rademacher complexity bounds in linear models, we propose and study a new heuristic complexity measure for neural networks which captures this phenomenon, in terms of sequences of tangent kernel classes along in the learning trajectories.
Representation Learning with Video Deep InfoMax
Jul 28, 2020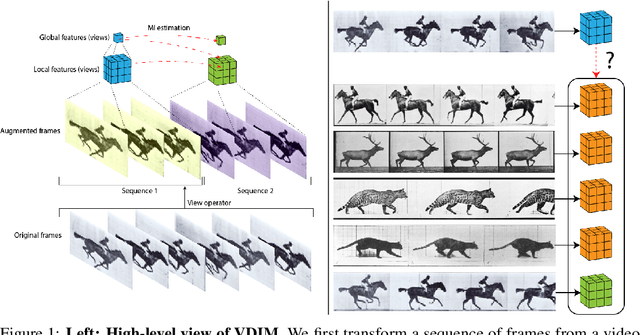
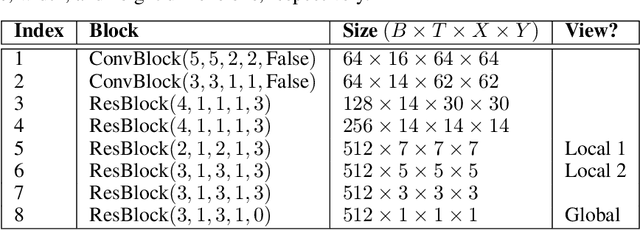
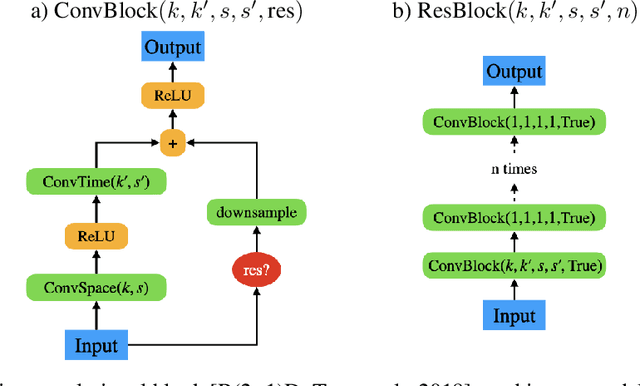
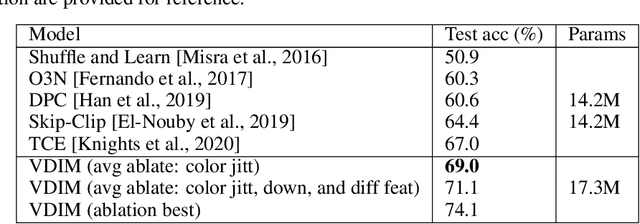
Self-supervised learning has made unsupervised pretraining relevant again for difficult computer vision tasks. The most effective self-supervised methods involve prediction tasks based on features extracted from diverse views of the data. DeepInfoMax (DIM) is a self-supervised method which leverages the internal structure of deep networks to construct such views, forming prediction tasks between local features which depend on small patches in an image and global features which depend on the whole image. In this paper, we extend DIM to the video domain by leveraging similar structure in spatio-temporal networks, producing a method we call Video Deep InfoMax(VDIM). We find that drawing views from both natural-rate sequences and temporally-downsampled sequences yields results on Kinetics-pretrained action recognition tasks which match or outperform prior state-of-the-art methods that use more costly large-time-scale transformer models. We also examine the effects of data augmentation and fine-tuning methods, accomplishingSoTA by a large margin when training only on the UCF-101 dataset.
Data-Efficient Reinforcement Learning with Momentum Predictive Representations
Jul 12, 2020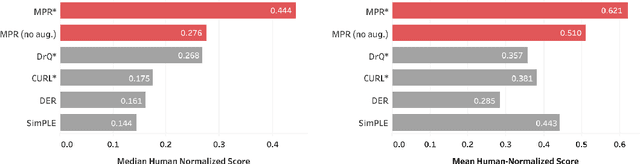
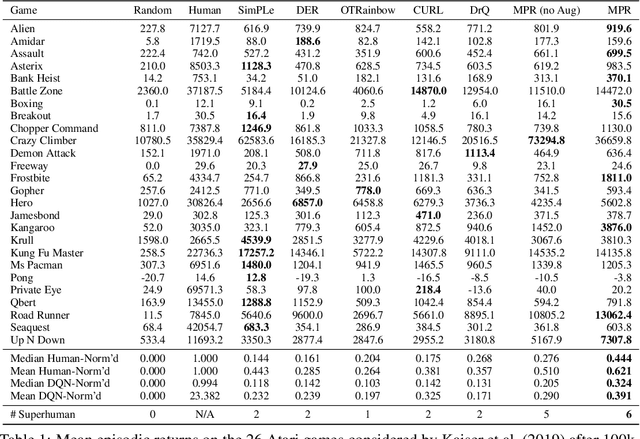
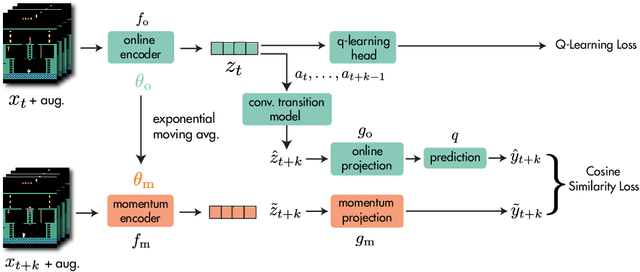

While deep reinforcement learning excels at solving tasks where large amounts of data can be collected through virtually unlimited interaction with the environment, learning from limited interaction remains a key challenge. We posit that an agent can learn more efficiently if we augment reward maximization with self-supervised objectives based on structure in its visual input and sequential interaction with the environment. Our method, Momentum Predictive Representations (MPR), trains an agent to predict its own latent state representations multiple steps into the future. We compute target representations for future states using an encoder which is an exponential moving average of the agent's parameters, and we make predictions using a learned transition model. On its own, this future prediction objective outperforms prior methods for sample-efficient deep RL from pixels. We further improve performance by adding data augmentation to the future prediction loss, which forces the agent's representations to be consistent across multiple views of an observation. Our full self-supervised objective, which combines future prediction and data augmentation, achieves a median human-normalized score of 0.444 on Atari in a setting limited to 100K steps of environment interaction, which is a 66% relative improvement over the previous state-of-the-art. Moreover, even in this limited data regime, MPR exceeds expert human scores on 6 out of 26 games.
Deep Reinforcement and InfoMax Learning
Jun 12, 2020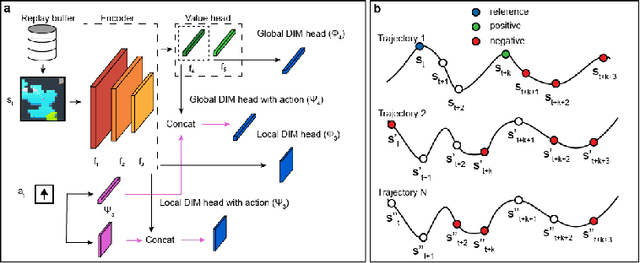
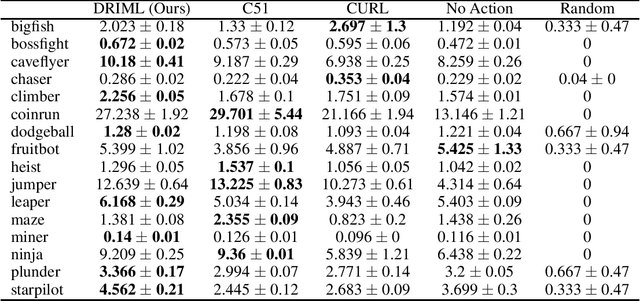
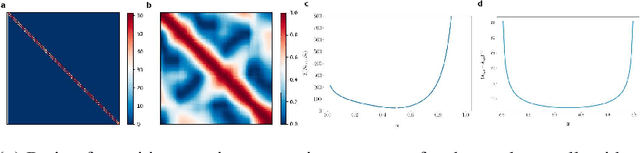

Our work is based on the hypothesis that a model-free agent whose representations are predictive of properties of future states (beyond expected rewards) will be more capable of solving and adapting to new RL problems. To test that hypothesis, we introduce an objective based on Deep InfoMax (DIM) which trains the agent to predict the future by maximizing the mutual information between its internal representation of successive timesteps. We provide an intuitive analysis of the convergence properties of our approach from the perspective of Markov chain mixing times and argue that convergence of the lower bound on mutual information is related to the inverse absolute spectral gap of the transition model. We test our approach in several synthetic settings, where it successfully learns representations that are predictive of the future. Finally, we augment C51, a strong RL baseline, with our temporal DIM objective and demonstrate improved performance on a continual learning task and on the recently introduced Procgen environment.