 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertPrompting: Instructing Large Language Models to be Distinguished Experts
May 24, 2023The answering quality of an aligned large language model (LLM) can be drastically improved if treated with proper crafting of prompts. In this paper, we propose ExpertPrompting to elicit the potential of LLMs to answer as distinguished experts. We first utilize In-Context Learning to automatically synthesize detailed and customized descriptions of the expert identity for each specific instruction, and then ask LLMs to provide answer conditioned on such agent background. Based on this augmented prompting strategy, we produce a new set of instruction-following data using GPT-3.5, and train a competitive open-source chat assistant called ExpertLLaMA. We employ GPT4-based evaluation to show that 1) the expert data is of significantly higher quality than vanilla answers, and 2) ExpertLLaMA outperforms existing open-source opponents and achieves 96\% of the original ChatGPT's capability. All data and the ExpertLLaMA model will be made publicly available at \url{https://github.com/OFA-Sys/ExpertLLaMA}.
Not All Image Regions Matter: Masked Vector Quantization for Autoregressive Image Generation
May 23, 2023Existing autoregressive models follow the two-stage generation paradigm that first learns a codebook in the latent space for image reconstruction and then completes the image generation autoregressively based on the learned codebook. However, existing codebook learning simply models all local region information of images without distinguishing their different perceptual importance, which brings redundancy in the learned codebook that not only limits the next stage's autoregressive model's ability to model important structure but also results in high training cost and slow generation speed. In this study, we borrow the idea of importance perception from classical image coding theory and propose a novel two-stage framework, which consists of Masked Quantization VAE (MQ-VAE) and Stackformer, to relieve the model from modeling redundancy. Specifically, MQ-VAE incorporates an adaptive mask module for masking redundant region features before quantization and an adaptive de-mask module for recovering the original grid image feature map to faithfully reconstruct the original images after quantization. Then, Stackformer learns to predict the combination of the next code and its position in the feature map. Comprehensive experiments on various image generation validate our effectiveness and efficiency. Code will be released at https://github.com/CrossmodalGroup/MaskedVectorQuantization.
Inductive Relation Prediction from Relational Paths and Context with Hierarchical Transformers
Apr 19, 2023Relation prediction on knowledge graphs (KGs) is a key research topic. Dominant embedding-based methods mainly focus on the transductive setting and lack the inductive ability to generalize to new entities for inference. Existing methods for inductive reasoning mostly mine the connections between entities, i.e., relational paths, without considering the nature of head and tail entities contained in the relational context. This paper proposes a novel method that captures both connections between entities and the intrinsic nature of entities, by simultaneously aggregating RElational Paths and cOntext with a unified hieRarchical Transformer framework, namely REPORT. REPORT relies solely on relation semantics and can naturally generalize to the fully-inductive setting, where KGs for training and inference have no common entities. In the experiments, REPORT performs consistently better than all baselines on almost all the eight version subsets of two fully-inductive datasets. Moreover. REPORT is interpretable by providing each element's contribution to the prediction results.
$k$NN Prompting: Beyond-Context Learning with Calibration-Free Nearest Neighbor Inference
Mar 24, 2023In-Context Learning (ICL), which formulates target tasks as prompt completion conditioned on in-context demonstrations, has become the prevailing utilization of LLMs. In this paper, we first disclose an actual predicament for this typical usage that it can not scale up with training data due to context length restriction. Besides, existing works have shown that ICL also suffers from various biases and requires delicate calibration treatment. To address both challenges, we advocate a simple and effective solution, $k$NN Prompting, which first queries LLM with training data for distributed representations, then predicts test instances by simply referring to nearest neighbors. We conduct comprehensive experiments to demonstrate its two-fold superiority: 1) Calibration-Free: $k$NN Prompting does not directly align LLM output distribution with task-specific label space, instead leverages such distribution to align test and training instances. It significantly outperforms state-of-the-art calibration-based methods under comparable few-shot scenario. 2) Beyond-Context: $k$NN Prompting can further scale up effectively with as many training data as are available, continually bringing substantial improvements. The scaling trend holds across 10 orders of magnitude ranging from 2 shots to 1024 shots as well as different LLMs scales ranging from 0.8B to 30B. It successfully bridges data scaling into model scaling, and brings new potentials for the gradient-free paradigm of LLM deployment. Code is publicly available.
* ICLR 2023. Code is available at https://github.com/BenfengXu/KNNPrompting
CGOF++: Controllable 3D Face Synthesis with Conditional Generative Occupancy Fields
Nov 23, 2022



Capitalizing on the recent advances in image generation models, existing controllable face image synthesis methods are able to generate high-fidelity images with some levels of controllability, e.g., controlling the shapes, expressions, textures, and poses of the generated face images. However, previous methods focus on controllable 2D image generative models, which are prone to producing inconsistent face images under large expression and pose changes. In this paper, we propose a new NeRF-based conditional 3D face synthesis framework, which enables 3D controllability over the generated face images by imposing explicit 3D conditions from 3D face priors. At its core is a conditional Generative Occupancy Field (cGOF++) that effectively enforces the shape of the generated face to conform to a given 3D Morphable Model (3DMM) mesh, built on top of EG3D [1], a recent tri-plane-based generative model. To achieve accurate control over fine-grained 3D face shapes of the synthesized images, we additionally incorporate a 3D landmark loss as well as a volume warping loss into our synthesis framework. Experiments validate the effectiveness of the proposed method, which is able to generate high-fidelity face images and shows more precise 3D controllability than state-of-the-art 2D-based controllable face synthesis methods.
Exploring Sequence-to-Sequence Transformer-Transducer Models for Keyword Spotting
Nov 11, 2022



In this paper, we present a novel approach to adapt a sequence-to-sequence Transformer-Transducer ASR system to the keyword spotting (KWS) task. We achieve this by replacing the keyword in the text transcription with a special token <kw> and training the system to detect the <kw> token in an audio stream. At inference time, we create a decision function inspired by conventional KWS approaches, to make our approach more suitable for the KWS task. Furthermore, we introduce a specific keyword spotting loss by adapting the sequence-discriminative Minimum Bayes-Risk training technique. We find that our approach significantly outperforms ASR based KWS systems. When compared with a conventional keyword spotting system, our proposal has similar performance while bringing the advantages and flexibility of sequence-to-sequence training. Additionally, when combined with the conventional KWS system, our approach can improve the performance at any operation point.
Augmenting Transformer-Transducer Based Speaker Change Detection With Token-Level Training Loss
Nov 11, 2022



In this work we propose a novel token-based training strategy that improves Transformer-Transducer (T-T) based speaker change detection (SCD) performance. The conventional T-T based SCD model loss optimizes all output tokens equally. Due to the sparsity of the speaker changes in the training data, the conventional T-T based SCD model loss leads to sub-optimal detection accuracy. To mitigate this issue, we use a customized edit-distance algorithm to estimate the token-level SCD false accept (FA) and false reject (FR) rates during training and optimize model parameters to minimize a weighted combination of the FA and FR, focusing the model on accurately predicting speaker changes. We also propose a set of evaluation metrics that align better with commercial use cases. Experiments on a group of challenging real-world datasets show that the proposed training method can significantly improve the overall performance of the SCD model with the same number of parameters.
Highly Efficient Real-Time Streaming and Fully On-Device Speaker Diarization with Multi-Stage Clustering
Oct 25, 2022



While recent research advances in speaker diarization mostly focus on improving the quality of diarization results, there is also an increasing interest in improving the efficiency of diarization systems. In this paper, we propose a multi-stage clustering strategy, that uses different clustering algorithms for input of different lengths. Specifically, a fallback clusterer is used to handle short-form inputs; a main clusterer is used to handle medium-length inputs; and a pre-clusterer is used to compress long-form inputs before they are processed by the main clusterer. Both the main clusterer and the pre-clusterer can be configured with an upper bound of the computational complexity to adapt to devices with different constraints. This multi-stage clustering strategy is critical for streaming on-device speaker diarization systems, where the budgets of CPU, memory and battery are tight.
A Universally-Deployable ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement, and Voice Separation
Sep 14, 2022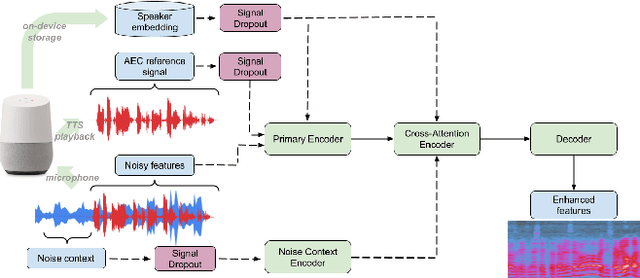

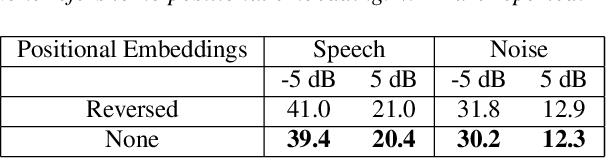
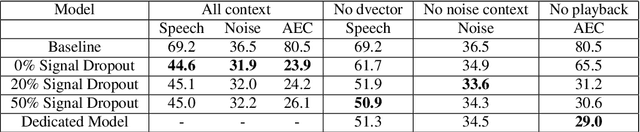
Recent work has shown that it is possible to train a single model to perform joint acoustic echo cancellation (AEC), speech enhancement, and voice separation, thereby serving as a unified frontend for robust automatic speech recognition (ASR). The joint model uses contextual information, such as a reference of the playback audio, noise context, and speaker embedding. In this work, we propose a number of novel improvements to such a model. First, we improve the architecture of the Cross-Attention Conformer that is used to ingest noise context into the model. Second, we generalize the model to be able to handle varying lengths of noise context. Third, we propose Signal Dropout, a novel strategy that models missing contextual information. In the absence of one or more signals, the proposed model performs nearly as well as task-specific models trained without these signals; and when such signals are present, our system compares well against systems that require all context signals. Over the baseline, the final model retains a relative word error rate reduction of 25.0% on background speech when speaker embedding is absent, and 61.2% on AEC when device playback is absent.
Compact and Robust Deep Learning Architecture for Fluorescence Lifetime Imaging and FPGA Implementation
Sep 09, 2022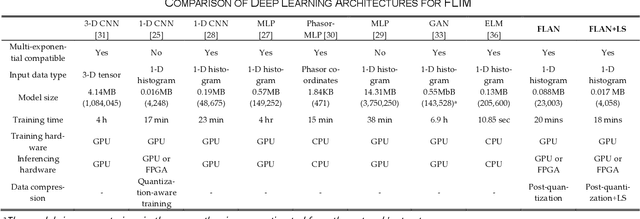
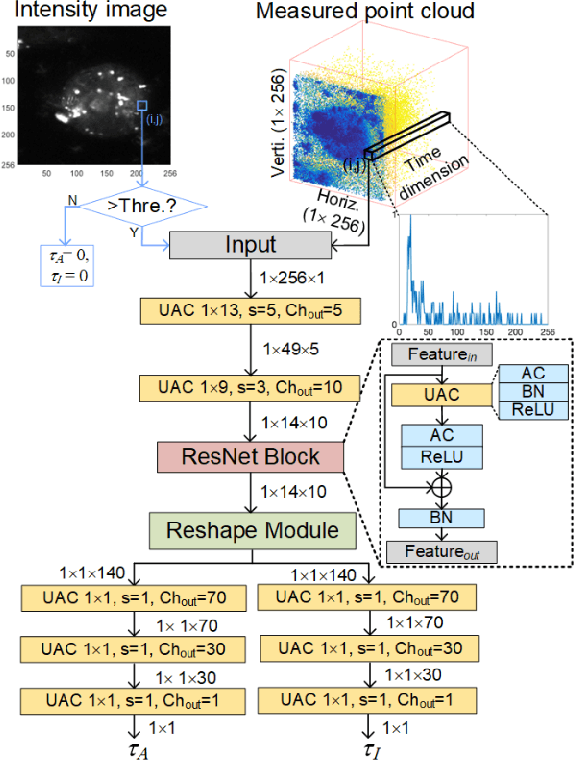
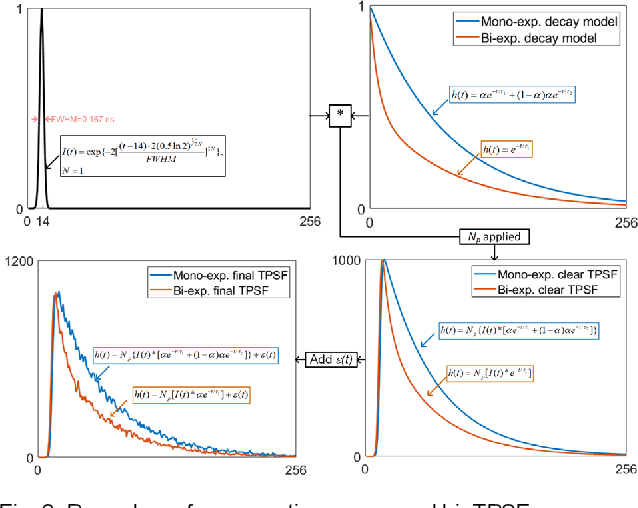
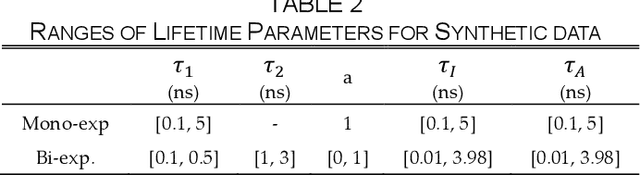
This paper reported a bespoke adder-based deep learning network for time-domain fluorescence lifetime imaging (FLIM). By leveraging the l1-norm extraction method, we propose a 1-D Fluorescence Lifetime AdderNet (FLAN) without multiplication-based convolutions to reduce the computational complexity. Further, we compressed fluorescence decays in temporal dimension using a log-scale merging technique to discard redundant temporal information derived as log-scaling FLAN (FLAN+LS). FLAN+LS achieves 0.11 and 0.23 compression ratios compared with FLAN and a conventional 1-D convolutional neural network (1-D CNN) while maintaining high accuracy in retrieving lifetimes. We extensively evaluated FLAN and FLAN+LS using synthetic and real data. A traditional fitting method and other non-fitting, high-accuracy algorithms were compared with our networks for synthetic data. Our networks attained a minor reconstruction error in different photon-count scenarios. For real data, we used fluorescent beads' data acquired by a confocal microscope to validate the effectiveness of real fluorophores, and our networks can differentiate beads with different lifetimes. Additionally, we implemented the network architecture on a field-programmable gate array (FPGA) with a post-quantization technique to shorten the bit-width, thereby improving computing efficiency. FLAN+LS on hardware achieves the highest computing efficiency compared to 1-D CNN and FLAN. We also discussed the applicability of our network and hardware architecture for other time-resolved biomedical applications using photon-efficient, time-resolved sensors.