 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP Guided Image-perceptive Prompt Learning for Image Enhancement
Nov 07, 2023



Image enhancement is a significant research area in the fields of computer vision and image processing. In recent years, many learning-based methods for image enhancement have been developed, where the Look-up-table (LUT) has proven to be an effective tool. In this paper, we delve into the potential of Contrastive Language-Image Pre-Training (CLIP) Guided Prompt Learning, proposing a simple structure called CLIP-LUT for image enhancement. We found that the prior knowledge of CLIP can effectively discern the quality of degraded images, which can provide reliable guidance. To be specific, We initially learn image-perceptive prompts to distinguish between original and target images using CLIP model, in the meanwhile, we introduce a very simple network by incorporating a simple baseline to predict the weights of three different LUT as enhancement network. The obtained prompts are used to steer the enhancement network like a loss function and improve the performance of model. We demonstrate that by simply combining a straightforward method with CLIP, we can obtain satisfactory results.
Unsupervised Domain Adaptation via Domain-Adaptive Diffusion
Aug 26, 2023Unsupervised Domain Adaptation (UDA) is quite challenging due to the large distribution discrepancy between the source domain and the target domain. Inspired by diffusion models which have strong capability to gradually convert data distributions across a large gap, we consider to explore the diffusion technique to handle the challenging UDA task. However, using diffusion models to convert data distribution across different domains is a non-trivial problem as the standard diffusion models generally perform conversion from the Gaussian distribution instead of from a specific domain distribution. Besides, during the conversion, the semantics of the source-domain data needs to be preserved for classification in the target domain. To tackle these problems, we propose a novel Domain-Adaptive Diffusion (DAD) module accompanied by a Mutual Learning Strategy (MLS), which can gradually convert data distribution from the source domain to the target domain while enabling the classification model to learn along the domain transition process. Consequently, our method successfully eases the challenge of UDA by decomposing the large domain gap into small ones and gradually enhancing the capacity of classification model to finally adapt to the target domain. Our method outperforms the current state-of-the-arts by a large margin on three widely used UDA datasets.
Diffusion-based Image Translation with Label Guidance for Domain Adaptive Semantic Segmentation
Aug 23, 2023



Translating images from a source domain to a target domain for learning target models is one of the most common strategies in domain adaptive semantic segmentation (DASS). However, existing methods still struggle to preserve semantically-consistent local details between the original and translated images. In this work, we present an innovative approach that addresses this challenge by using source-domain labels as explicit guidance during image translation. Concretely, we formulate cross-domain image translation as a denoising diffusion process and utilize a novel Semantic Gradient Guidance (SGG) method to constrain the translation process, conditioning it on the pixel-wise source labels. Additionally, a Progressive Translation Learning (PTL) strategy is devised to enable the SGG method to work reliably across domains with large gaps. Extensive experiments demonstrate the superiority of our approach over state-of-the-art methods.
Progressive Channel-Shrinking Network
Apr 01, 2023



Currently, salience-based channel pruning makes continuous breakthroughs in network compression. In the realization, the salience mechanism is used as a metric of channel salience to guide pruning. Therefore, salience-based channel pruning can dynamically adjust the channel width at run-time, which provides a flexible pruning scheme. However, there are two problems emerging: a gating function is often needed to truncate the specific salience entries to zero, which destabilizes the forward propagation; dynamic architecture brings more cost for indexing in inference which bottlenecks the inference speed. In this paper, we propose a Progressive Channel-Shrinking (PCS) method to compress the selected salience entries at run-time instead of roughly approximating them to zero. We also propose a Running Shrinking Policy to provide a testing-static pruning scheme that can reduce the memory access cost for filter indexing. We evaluate our method on ImageNet and CIFAR10 datasets over two prevalent networks: ResNet and VGG, and demonstrate that our PCS outperforms all baselines and achieves state-of-the-art in terms of compression-performance tradeoff. Moreover, we observe a significant and practical acceleration of inference.
GradMDM: Adversarial Attack on Dynamic Networks
Apr 01, 2023



Dynamic neural networks can greatly reduce computation redundancy without compromising accuracy by adapting their structures based on the input. In this paper, we explore the robustness of dynamic neural networks against energy-oriented attacks targeted at reducing their efficiency. Specifically, we attack dynamic models with our novel algorithm GradMDM. GradMDM is a technique that adjusts the direction and the magnitude of the gradients to effectively find a small perturbation for each input, that will activate more computational units of dynamic models during inference. We evaluate GradMDM on multiple datasets and dynamic models, where it outperforms previous energy-oriented attack techniques, significantly increasing computation complexity while reducing the perceptibility of the perturbations.
Amodal Intra-class Instance Segmentation: New Dataset and Benchmark
Mar 12, 2023



Images of realistic scenes often contain intra-class objects that are heavily occluded from each other, making the amodal perception task that requires parsing the occluded parts of the objects challenging. Although important for downstream tasks such as robotic grasping systems, the lack of large-scale amodal datasets with detailed annotations makes it difficult to model intra-class occlusions explicitly. This paper introduces a new amodal dataset for image amodal completion tasks, which contains over 255K images of intra-class occlusion scenarios, annotated with multiple masks, amodal bounding boxes, dual order relations and full appearance for instances and background. We also present a point-supervised scheme with layer priors for amodal instance segmentation specifically designed for intra-class occlusion scenarios. Experiments show that our weakly supervised approach outperforms the SOTA fully supervised methods, while our layer priors design exhibits remarkable performance improvements in the case of intra-class occlusion in both synthetic and real images.
DiffPose: Toward More Reliable 3D Pose Estimation
Nov 30, 2022



Monocular 3D human pose estimation is quite challenging due to the inherent ambiguity and occlusion, which often lead to high uncertainty and indeterminacy. On the other hand, diffusion models have recently emerged as an effective tool for generating high-quality images from noise. Inspired by their capability, we explore a novel pose estimation framework (DiffPose) that formulates 3D pose estimation as a reverse diffusion process. We incorporate novel designs into our DiffPose that facilitate the diffusion process for 3D pose estimation: a pose-specific initialization of pose uncertainty distributions, a Gaussian Mixture Model-based forward diffusion process, and a context-conditioned reverse diffusion process. Our proposed DiffPose significantly outperforms existing methods on the widely used pose estimation benchmarks Human3.6M and MPI-INF-3DHP.
Unified Multi-View Orthonormal Non-Negative Graph Based Clustering Framework
Nov 03, 2022



Spectral clustering is an effective methodology for unsupervised learning. Most traditional spectral clustering algorithms involve a separate two-step procedure and apply the transformed new representations for the final clustering results. Recently, much progress has been made to utilize the non-negative feature property in real-world data and to jointly learn the representation and clustering results. However, to our knowledge, no previous work considers a unified model that incorporates the important multi-view information with those properties, which severely limits the performance of existing methods. In this paper, we formulate a novel clustering model, which exploits the non-negative feature property and, more importantly, incorporates the multi-view information into a unified joint learning framework: the unified multi-view orthonormal non-negative graph based clustering framework (Umv-ONGC). Then, we derive an effective three-stage iterative solution for the proposed model and provide analytic solutions for the three sub-problems from the three stages. We also explore, for the first time, the multi-model non-negative graph-based approach to clustering data based on deep features. Extensive experiments on three benchmark data sets demonstrate the effectiveness of the proposed method.
Adaptive Local-Component-aware Graph Convolutional Network for One-shot Skeleton-based Action Recognition
Sep 21, 2022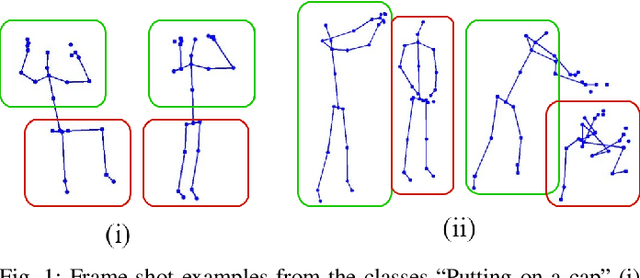
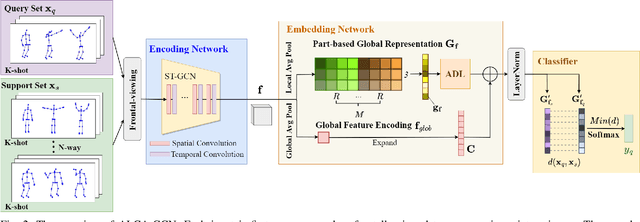
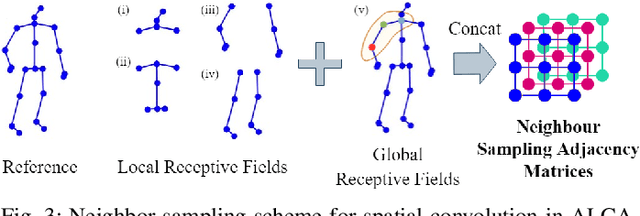
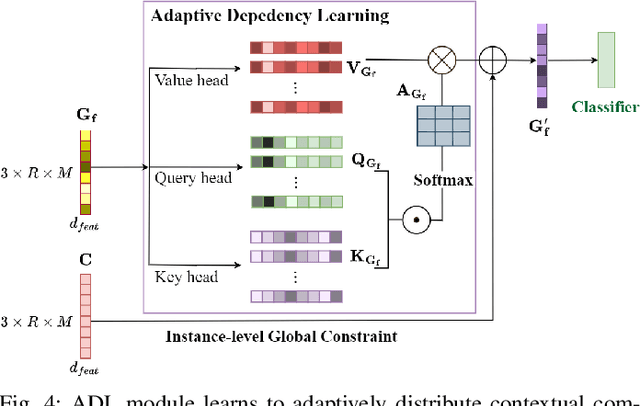
Skeleton-based action recognition receives increasing attention because the skeleton representations reduce the amount of training data by eliminating visual information irrelevant to actions. To further improve the sample efficiency, meta-learning-based one-shot learning solutions were developed for skeleton-based action recognition. These methods find the nearest neighbor according to the similarity between instance-level global average embedding. However, such measurement holds unstable representativity due to inadequate generalized learning on local invariant and noisy features, while intuitively, more fine-grained recognition usually relies on determining key local body movements. To address this limitation, we present the Adaptive Local-Component-aware Graph Convolutional Network, which replaces the comparison metric with a focused sum of similarity measurements on aligned local embedding of action-critical spatial/temporal segments. Comprehensive one-shot experiments on the public benchmark of NTU-RGB+D 120 indicate that our method provides a stronger representation than the global embedding and helps our model reach state-of-the-art.
Dynamic Spatio-Temporal Specialization Learning for Fine-Grained Action Recognition
Sep 03, 2022
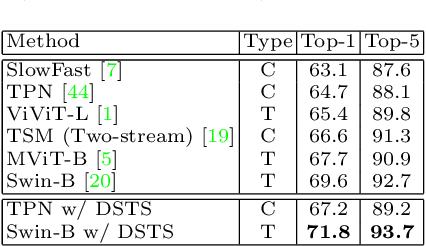
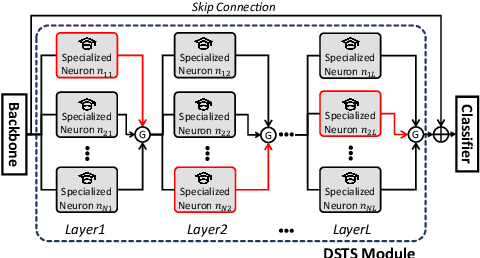
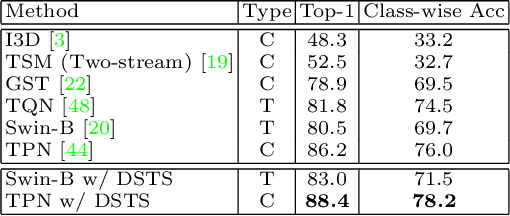
The goal of fine-grained action recognition is to successfully discriminate between action categories with subtle differences. To tackle this, we derive inspiration from the human visual system which contains specialized regions in the brain that are dedicated towards handling specific tasks. We design a novel Dynamic Spatio-Temporal Specialization (DSTS) module, which consists of specialized neurons that are only activated for a subset of samples that are highly similar. During training, the loss forces the specialized neurons to learn discriminative fine-grained differences to distinguish between these similar samples, improving fine-grained recognition. Moreover, a spatio-temporal specialization method further optimizes the architectures of the specialized neurons to capture either more spatial or temporal fine-grained information, to better tackle the large range of spatio-temporal variations in the videos. Lastly, we design an Upstream-Downstream Learning algorithm to optimize our model's dynamic decisions during training, improving the performance of our DSTS module. We obtain state-of-the-art performance on two widely-used fine-grained action recognition datasets.