 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIDE: Goal-Initialized Directional Understanding for End-to-End Visual Navigation
Jun 09, 2026Learning-based visual navigation for legged robots typically relies on continuous goal updates from hierarchical state estimation to provide a persistent directional reference. This reliance incurs additional sensory and computational overhead and deviates from fully end-to-end mobile autonomy. Furthermore, under partial observability, policies are prone to learn myopic behaviors, easily becoming trapped in dead ends and complex structural layouts. To address these limitations, we investigate a goal-initialized navigation setting, where the target is provided only once at the beginning of an episode, requiring the robot to operate based on intrinsic spatial memory without subsequent goal updates from external modules. In this work, we propose GUIDE, a fully end-to-end reinforcement learning framework designed to cultivate internal directional awareness. Specifically, GUIDE incorporates a spatial anchor predictor that leverages multi-frequency proprioceptive history to extract egomotion representations, thereby maintaining a persistent long-horizon spatial context for navigation. Concurrently, it utilizes raw depth streams to perceive local environmental geometry. We evaluate the proposed framework across both simulation and real-world scenarios on a quadruped robot. Experiments show that GUIDE learns reliable egomotion and directional awareness, enabling a fully end-to-end deployed policy to safely navigate through dense clutter and structured mazes without subsequent goal guidance or prior maps.
SSR: Scaling Surefooted and Symmetric Humanoid Traversal to the Open World
May 29, 2026Extending humanoid traversal to the open world is key to practical deployment in human environments, but remains challenging. The robot must use vision to ensure safe and reliable foot placement on heterogeneous terrain under highly dynamic motion, while producing coordinated, natural whole-body behaviors. We propose SSR, an efficient end-to-end framework for egocentric vision-based humanoid traversal that jointly learns these capabilities. SSR introduces imagined foothold guidance, which learns to model forthcoming swing-foot contacts and evaluates their support to guide pre-touchdown swings toward stable regions, reducing edge slips. It further employs equivariant latent-space symmetry augmentation to efficiently induce bilateral coordination under high-dimensional visual observations, and uses terrain-specific multi-discriminator motion priors to encourage human-like behavior across scenes. Extensive experiments show that SSR achieves safe, stable, and high-quality locomotion on diverse real-world terrains, including stairs with varied structures and extreme challenges such as wide gaps and high platforms, while enabling reliable long-horizon traversal in open outdoor environments.
CReF: Cross-modal and Recurrent Fusion for Depth-conditioned Humanoid Locomotion
Apr 01, 2026Stable traversal over geometrically complex terrain increasingly requires exteroceptive perception, yet prior perceptive humanoid locomotion methods often remain tied to explicit geometric abstractions, either by mediating control through robot-centric 2.5D terrain representations or by shaping depth learning with auxiliary geometry-related targets. Such designs inherit the representational bias of the intermediate or supervisory target and can be restrictive for vertical structures, perforated obstacles, and complex real-world clutter. We propose CReF (Cross-modal and Recurrent Fusion), a single-stage depth-conditioned humanoid locomotion framework that learns locomotion-relevant features directly from raw forward-facing depth without explicit geometric intermediates. CReF couples proprioception and depth tokens through proprioception-queried cross-modal attention, fuses the resulting representation with a gated residual fusion block, and performs temporal integration with a Gated Recurrent Unit (GRU) regulated by a highway-style output gate for state-dependent blending of recurrent and feedforward features. To further improve terrain interaction, we introduce a terrain-aware foothold placement reward that extracts supportable foothold candidates from foot-end point-cloud samples and rewards touchdown locations that lie close to the nearest supportable candidate. Experiments in simulation and on a physical humanoid demonstrate robust traversal over diverse terrains and effective zero-shot transfer to real-world scenes containing handrails, hollow pallet assemblies, severe reflective interference, and visually cluttered outdoor surroundings.
Look Forward to Walk Backward: Efficient Terrain Memory for Backward Locomotion with Forward Vision
Mar 03, 2026Legged robots with egocentric forward-facing depth cameras can couple exteroception and proprioception to achieve robust forward agility on complex terrain. When these robots walk backward, the forward-only field of view provides no preview. Purely proprioceptive controllers can remain stable on moderate ground when moving backward but cannot fully exploit the robot's capabilities on complex terrain and must collide with obstacles. We present Look Forward to Walk Backward (LF2WB), an efficient terrain-memory locomotion framework that uses forward egocentric depth and proprioception to write a compact associative memory during forward motion and to retrieve it for collision-free backward locomotion without rearward vision. The memory backbone employs a delta-rule selective update that softly removes then writes the memory state along the active subspace. Training uses hardware-efficient parallel computation, and deployment runs recurrent, constant-time per-step inference with a constant-size state, making the approach suitable for onboard processors on low-cost robots. Experiments in both simulations and real-world scenarios demonstrate the effectiveness of our method, improving backward agility across complex terrains under limited sensing.
PUMA: Perception-driven Unified Foothold Prior for Mobility Augmented Quadruped Parkour
Jan 22, 2026Parkour tasks for quadrupeds have emerged as a promising benchmark for agile locomotion. While human athletes can effectively perceive environmental characteristics to select appropriate footholds for obstacle traversal, endowing legged robots with similar perceptual reasoning remains a significant challenge. Existing methods often rely on hierarchical controllers that follow pre-computed footholds, thereby constraining the robot's real-time adaptability and the exploratory potential of reinforcement learning. To overcome these challenges, we present PUMA, an end-to-end learning framework that integrates visual perception and foothold priors into a single-stage training process. This approach leverages terrain features to estimate egocentric polar foothold priors, composed of relative distance and heading, guiding the robot in active posture adaptation for parkour tasks. Extensive experiments conducted in simulation and real-world environments across various discrete complex terrains, demonstrate PUMA's exceptional agility and robustness in challenging scenarios.
START: Traversing Sparse Footholds with Terrain Reconstruction
Dec 15, 2025


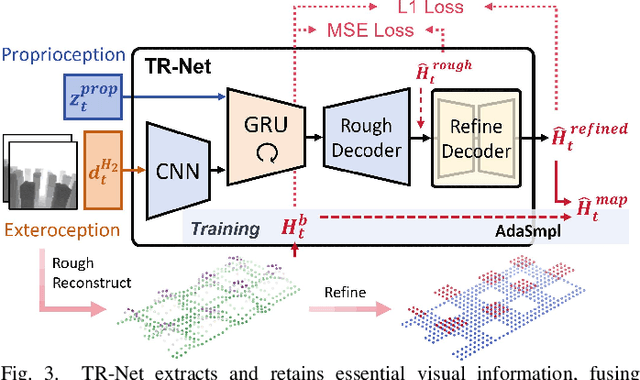
Traversing terrains with sparse footholds like legged animals presents a promising yet challenging task for quadruped robots, as it requires precise environmental perception and agile control to secure safe foot placement while maintaining dynamic stability. Model-based hierarchical controllers excel in laboratory settings, but suffer from limited generalization and overly conservative behaviors. End-to-end learning-based approaches unlock greater flexibility and adaptability, but existing state-of-the-art methods either rely on heightmaps that introduce noise and complex, costly pipelines, or implicitly infer terrain features from egocentric depth images, often missing accurate critical geometric cues and leading to inefficient learning and rigid gaits. To overcome these limitations, we propose START, a single-stage learning framework that enables agile, stable locomotion on highly sparse and randomized footholds. START leverages only low-cost onboard vision and proprioception to accurately reconstruct local terrain heightmap, providing an explicit intermediate representation to convey essential features relevant to sparse foothold regions. This supports comprehensive environmental understanding and precise terrain assessment, reducing exploration cost and accelerating skill acquisition. Experimental results demonstrate that START achieves zero-shot transfer across diverse real-world scenarios, showcasing superior adaptability, precise foothold placement, and robust locomotion.
A Hierarchical Region-Based Approach for Efficient Multi-Robot Exploration
Mar 17, 2025Multi-robot autonomous exploration in an unknown environment is an important application in robotics.Traditional exploration methods only use information around frontier points or viewpoints, ignoring spatial information of unknown areas. Moreover, finding the exact optimal solution for multi-robot task allocation is NP-hard, resulting in significant computational time consumption. To address these issues, we present a hierarchical multi-robot exploration framework using a new modeling method called RegionGraph. The proposed approach makes two main contributions: 1) A new modeling method for unexplored areas that preserves their spatial information across the entire space in a weighted graph called RegionGraph. 2) A hierarchical multi-robot exploration framework that decomposes the global exploration task into smaller subtasks, reducing the frequency of global planning and enabling asynchronous exploration. The proposed method is validated through both simulation and real-world experiments, demonstrating a 20% improvement in efficiency compared to existing methods.
MOVE: Multi-skill Omnidirectional Legged Locomotion with Limited View in 3D Environments
Dec 04, 2024



Legged robots possess inherent advantages in traversing complex 3D terrains. However, previous work on low-cost quadruped robots with egocentric vision systems has been limited by a narrow front-facing view and exteroceptive noise, restricting omnidirectional mobility in such environments. While building a voxel map through a hierarchical structure can refine exteroception processing, it introduces significant computational overhead, noise, and delays. In this paper, we present MOVE, a one-stage end-to-end learning framework capable of multi-skill omnidirectional legged locomotion with limited view in 3D environments, just like what a real animal can do. When movement aligns with the robot's line of sight, exteroceptive perception enhances locomotion, enabling extreme climbing and leaping. When vision is obstructed or the direction of movement lies outside the robot's field of view, the robot relies on proprioception for tasks like crawling and climbing stairs. We integrate all these skills into a single neural network by introducing a pseudo-siamese network structure combining supervised and contrastive learning which helps the robot infer its surroundings beyond its field of view. Experiments in both simulations and real-world scenarios demonstrate the robustness of our method, broadening the operational environments for robotics with egocentric vision.
PIE: Parkour with Implicit-Explicit Learning Framework for Legged Robots
Aug 27, 2024



Parkour presents a highly challenging task for legged robots, requiring them to traverse various terrains with agile and smooth locomotion. This necessitates comprehensive understanding of both the robot's own state and the surrounding terrain, despite the inherent unreliability of robot perception and actuation. Current state-of-the-art methods either rely on complex pre-trained high-level terrain reconstruction modules or limit the maximum potential of robot parkour to avoid failure due to inaccurate perception. In this paper, we propose a one-stage end-to-end learning-based parkour framework: Parkour with Implicit-Explicit learning framework for legged robots (PIE) that leverages dual-level implicit-explicit estimation. With this mechanism, even a low-cost quadruped robot equipped with an unreliable egocentric depth camera can achieve exceptional performance on challenging parkour terrains using a relatively simple training process and reward function. While the training process is conducted entirely in simulation, our real-world validation demonstrates successful zero-shot deployment of our framework, showcasing superior parkour performance on harsh terrains.
Toward Understanding Key Estimation in Learning Robust Humanoid Locomotion
Mar 09, 2024Accurate state estimation plays a critical role in ensuring the robust control of humanoid robots, particularly in the context of learning-based control policies for legged robots. However, there is a notable gap in analytical research concerning estimations. Therefore, we endeavor to further understand how various types of estimations influence the decision-making processes of policies. In this paper, we provide quantitative insight into the effectiveness of learned state estimations, employing saliency analysis to identify key estimation variables and optimize their combination for humanoid locomotion tasks. Evaluations assessing tracking precision and robustness are conducted on comparative groups of policies with varying estimation combinations in both simulated and real-world environments. Results validated that the proposed policy is capable of crossing the sim-to-real gap and demonstrating superior performance relative to alternative policy configurations.