 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Guided Hypergraph Feature Propagation for Semi-supervised Classification with Missing Node Features
Feb 16, 2023



Graph neural networks (GNNs) with missing node features have recently received increasing interest. Such missing node features seriously hurt the performance of the existing GNNs. Some recent methods have been proposed to reconstruct the missing node features by the information propagation among nodes with known and unknown attributes. Although these methods have achieved superior performance, how to exactly exploit the complex data correlations among nodes to reconstruct missing node features is still a great challenge. To solve the above problem, we propose a self-supervised guided hypergraph feature propagation (SGHFP). Specifically, the feature hypergraph is first generated according to the node features with missing information. And then, the reconstructed node features produced by the previous iteration are fed to a two-layer GNNs to construct a pseudo-label hypergraph. Before each iteration, the constructed feature hypergraph and pseudo-label hypergraph are fused effectively, which can better preserve the higher-order data correlations among nodes. After then, we apply the fused hypergraph to the feature propagation for reconstructing missing features. Finally, the reconstructed node features by multi-iteration optimization are applied to the downstream semi-supervised classification task. Extensive experiments demonstrate that the proposed SGHFP outperforms the existing semi-supervised classification with missing node feature methods.
Deep Manifold Hashing: A Divide-and-Conquer Approach for Semi-Paired Unsupervised Cross-Modal Retrieval
Sep 26, 2022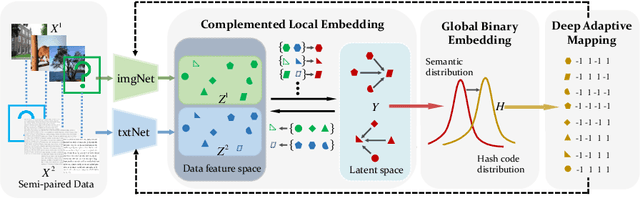
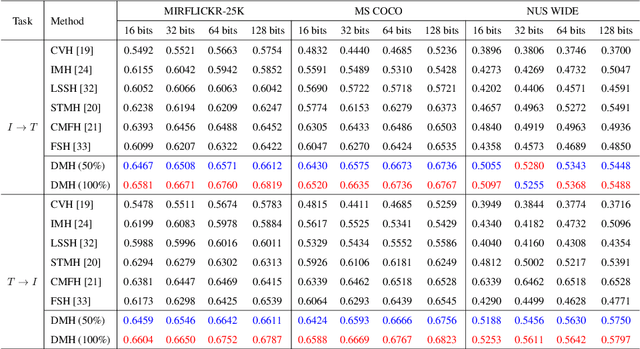
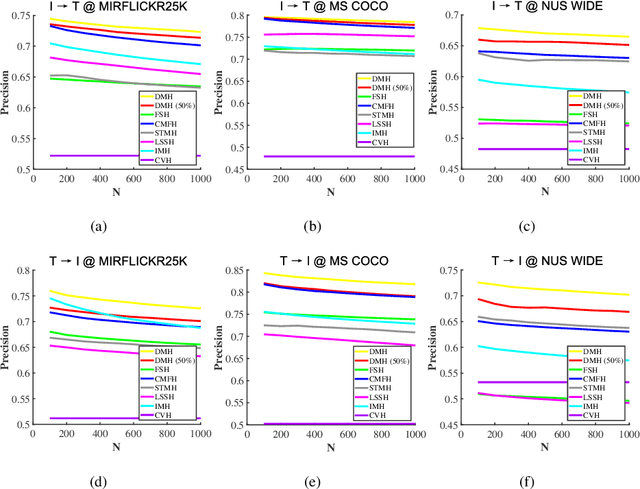
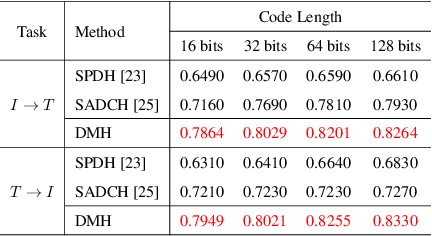
Hashing that projects data into binary codes has shown extraordinary talents in cross-modal retrieval due to its low storage usage and high query speed. Despite their empirical success on some scenarios, existing cross-modal hashing methods usually fail to cross modality gap when fully-paired data with plenty of labeled information is nonexistent. To circumvent this drawback, motivated by the Divide-and-Conquer strategy, we propose Deep Manifold Hashing (DMH), a novel method of dividing the problem of semi-paired unsupervised cross-modal retrieval into three sub-problems and building one simple yet efficiency model for each sub-problem. Specifically, the first model is constructed for obtaining modality-invariant features by complementing semi-paired data based on manifold learning, whereas the second model and the third model aim to learn hash codes and hash functions respectively. Extensive experiments on three benchmarks demonstrate the superiority of our DMH compared with the state-of-the-art fully-paired and semi-paired unsupervised cross-modal hashing methods.
Deep Supervised Information Bottleneck Hashing for Cross-modal Retrieval based Computer-aided Diagnosis
May 06, 2022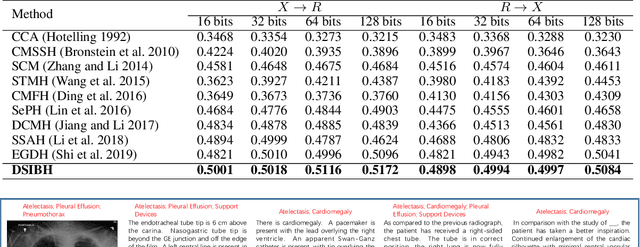
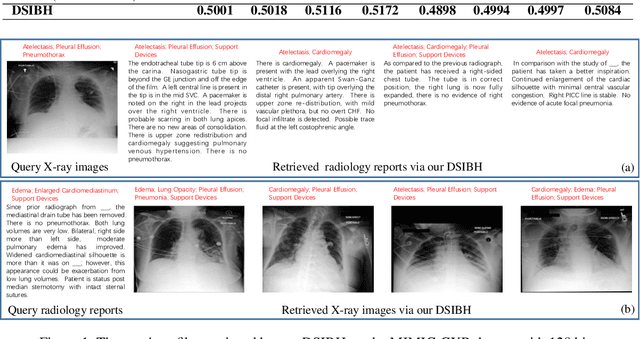
Mapping X-ray images, radiology reports, and other medical data as binary codes in the common space, which can assist clinicians to retrieve pathology-related data from heterogeneous modalities (i.e., hashing-based cross-modal medical data retrieval), provides a new view to promot computeraided diagnosis. Nevertheless, there remains a barrier to boost medical retrieval accuracy: how to reveal the ambiguous semantics of medical data without the distraction of superfluous information. To circumvent this drawback, we propose Deep Supervised Information Bottleneck Hashing (DSIBH), which effectively strengthens the discriminability of hash codes. Specifically, the Deep Deterministic Information Bottleneck (Yu, Yu, and Principe 2021) for single modality is extended to the cross-modal scenario. Benefiting from this, the superfluous information is reduced, which facilitates the discriminability of hash codes. Experimental results demonstrate the superior accuracy of the proposed DSIBH compared with state-of-the-arts in cross-modal medical data retrieval tasks.
* 7 pages, 1 figure
MSDN: Mutually Semantic Distillation Network for Zero-Shot Learning
Mar 07, 2022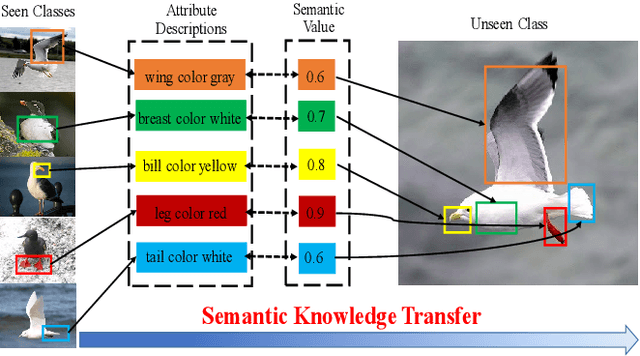
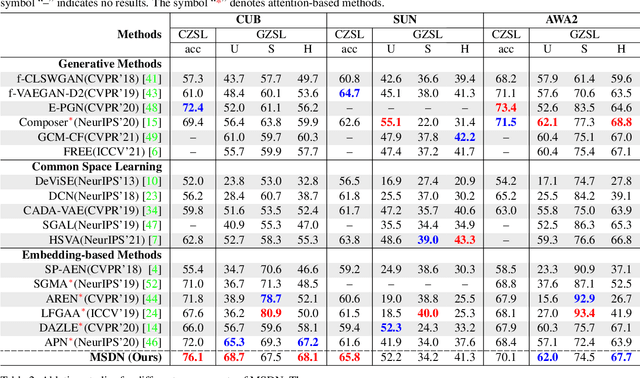

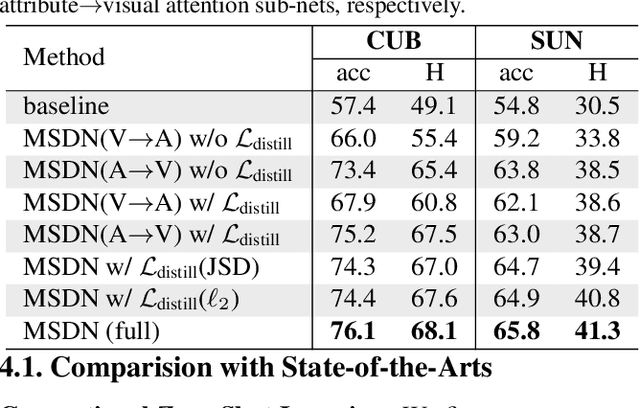
The key challenge of zero-shot learning (ZSL) is how to infer the latent semantic knowledge between visual and attribute features on seen classes, and thus achieving a desirable knowledge transfer to unseen classes. Prior works either simply align the global features of an image with its associated class semantic vector or utilize unidirectional attention to learn the limited latent semantic representations, which could not effectively discover the intrinsic semantic knowledge e.g., attribute semantics) between visual and attribute features. To solve the above dilemma, we propose a Mutually Semantic Distillation Network (MSDN), which progressively distills the intrinsic semantic representations between visual and attribute features for ZSL. MSDN incorporates an attribute$\rightarrow$visual attention sub-net that learns attribute-based visual features, and a visual$\rightarrow$attribute attention sub-net that learns visual-based attribute features. By further introducing a semantic distillation loss, the two mutual attention sub-nets are capable of learning collaboratively and teaching each other throughout the training process. The proposed MSDN yields significant improvements over the strong baselines, leading to new state-of-the-art performances on three popular challenging benchmarks, i.e., CUB, SUN, and AWA2. Our codes have been available at: \url{https://github.com/shiming-chen/MSDN}.
CSCNet: Contextual Semantic Consistency Network for Trajectory Prediction in Crowded Spaces
Feb 17, 2022
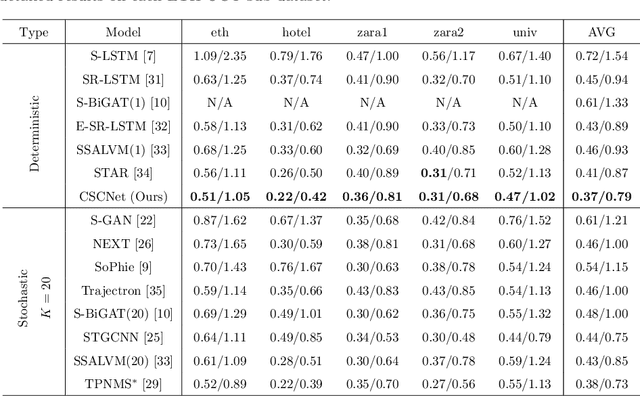
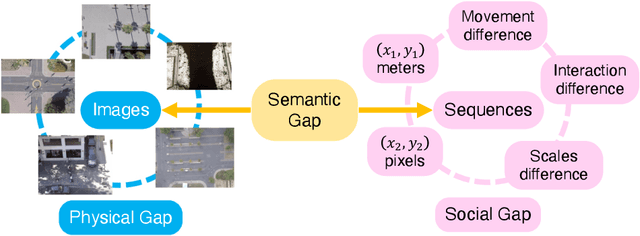
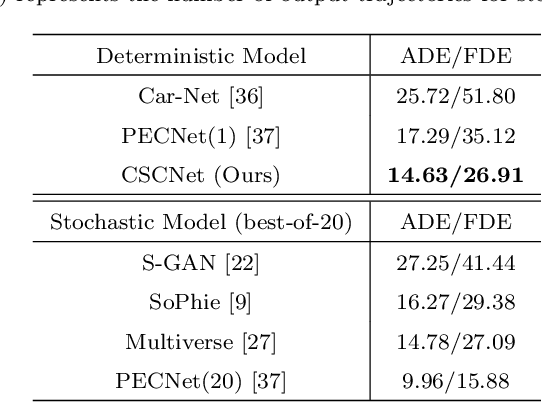
Trajectory prediction aims to predict the movement trend of the agents like pedestrians, bikers, vehicles. It is helpful to analyze and understand human activities in crowded spaces and widely applied in many areas such as surveillance video analysis and autonomous driving systems. Thanks to the success of deep learning, trajectory prediction has made significant progress. The current methods are dedicated to studying the agents' future trajectories under the social interaction and the sceneries' physical constraints. Moreover, how to deal with these factors still catches researchers' attention. However, they ignore the \textbf{Semantic Shift Phenomenon} when modeling these interactions in various prediction sceneries. There exist several kinds of semantic deviations inner or between social and physical interactions, which we call the "\textbf{Gap}". In this paper, we propose a \textbf{C}ontextual \textbf{S}emantic \textbf{C}onsistency \textbf{Net}work (\textbf{CSCNet}) to predict agents' future activities with powerful and efficient context constraints. We utilize a well-designed context-aware transfer to obtain the intermediate representations from the scene images and trajectories. Then we eliminate the differences between social and physical interactions by aligning activity semantics and scene semantics to cross the Gap. Experiments demonstrate that CSCNet performs better than most of the current methods quantitatively and qualitatively.
TransZero: Attribute-guided Transformer for Zero-Shot Learning
Dec 03, 2021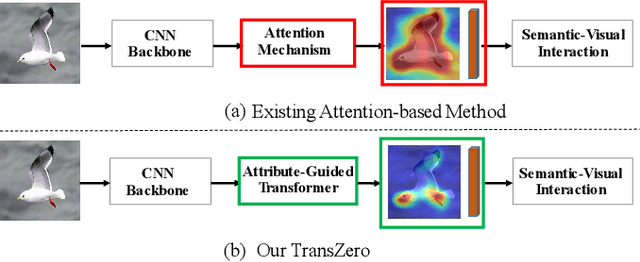
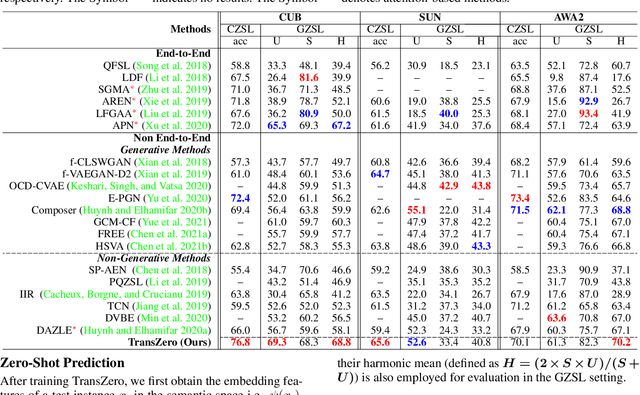
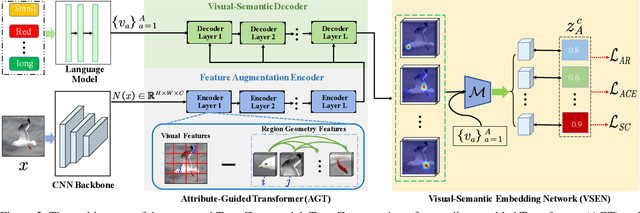
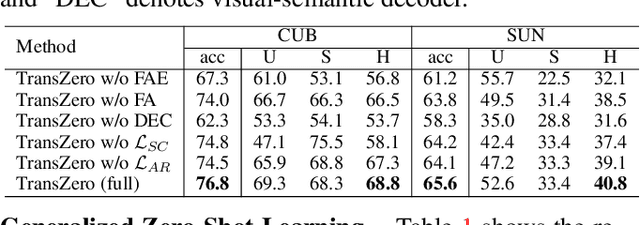
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen ones. Semantic knowledge is learned from attribute descriptions shared between different classes, which act as strong priors for localizing object attributes that represent discriminative region features, enabling significant visual-semantic interaction. Although some attention-based models have attempted to learn such region features in a single image, the transferability and discriminative attribute localization of visual features are typically neglected. In this paper, we propose an attribute-guided Transformer network, termed TransZero, to refine visual features and learn attribute localization for discriminative visual embedding representations in ZSL. Specifically, TransZero takes a feature augmentation encoder to alleviate the cross-dataset bias between ImageNet and ZSL benchmarks, and improves the transferability of visual features by reducing the entangled relative geometry relationships among region features. To learn locality-augmented visual features, TransZero employs a visual-semantic decoder to localize the image regions most relevant to each attribute in a given image, under the guidance of semantic attribute information. Then, the locality-augmented visual features and semantic vectors are used to conduct effective visual-semantic interaction in a visual-semantic embedding network. Extensive experiments show that TransZero achieves the new state of the art on three ZSL benchmarks. The codes are available at: \url{https://github.com/shiming-chen/TransZero}.
View Vertically: A Hierarchical Network for Trajectory Prediction via Fourier Spectrums
Oct 14, 2021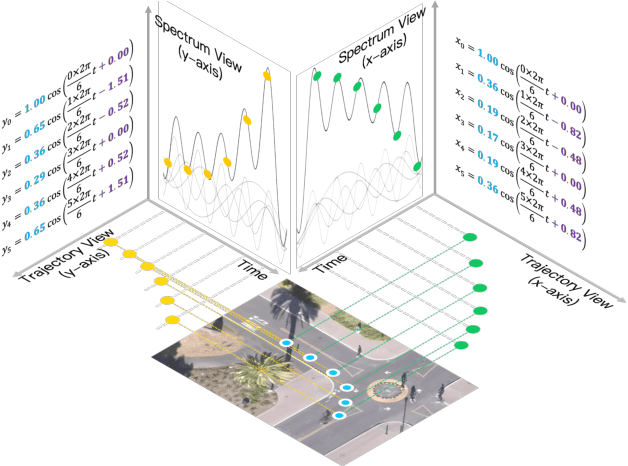
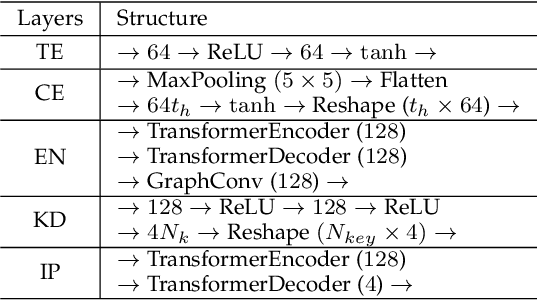
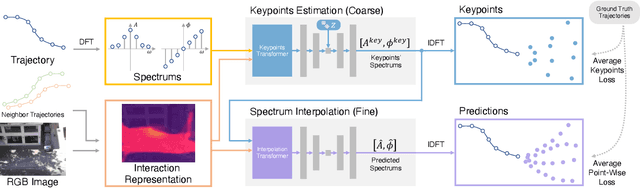
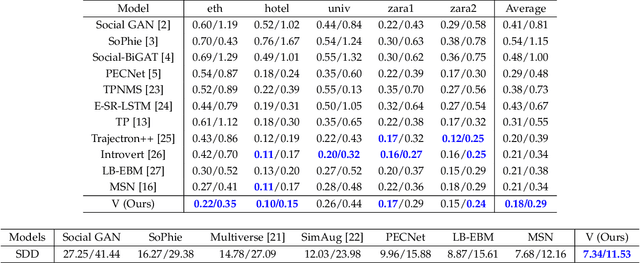
Learning to understand and predict future motions or behaviors for agents like humans and robots are critical to various autonomous platforms, such as behavior analysis, robot navigation, and self-driving cars. Intrinsic factors such as agents' diversified personalities and decision-making styles bring rich and diverse changes and multi-modal characteristics to their future plannings. Besides, the extrinsic interactive factors have also brought rich and varied changes to their trajectories. Previous methods mostly treat trajectories as time sequences, and reach great prediction performance. In this work, we try to focus on agents' trajectories in another view, i.e., the Fourier spectrums, to explore their future behavior rules in a novel hierarchical way. We propose the Transformer-based V model, which concatenates two continuous keypoints estimation and spectrum interpolation sub-networks, to model and predict agents' trajectories with spectrums in the keypoints and interactions levels respectively. Experimental results show that V outperforms most of current state-of-the-art methods on ETH-UCY and SDD trajectories dataset for about 15\% quantitative improvements, and performs better qualitative results.
HSVA: Hierarchical Semantic-Visual Adaptation for Zero-Shot Learning
Oct 08, 2021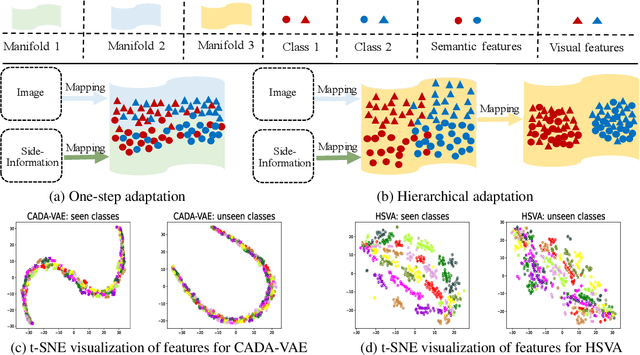

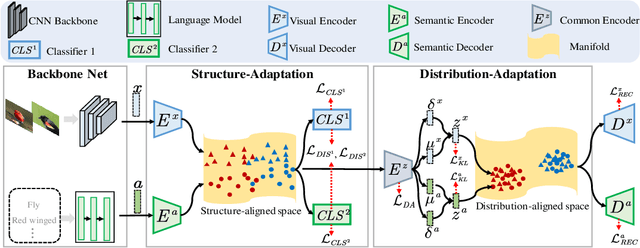
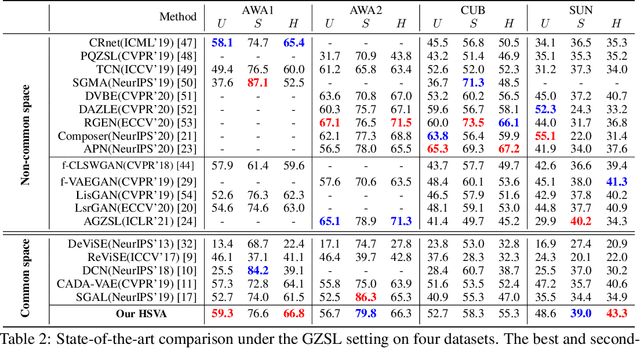
Zero-shot learning (ZSL) tackles the unseen class recognition problem, transferring semantic knowledge from seen classes to unseen ones. Typically, to guarantee desirable knowledge transfer, a common (latent) space is adopted for associating the visual and semantic domains in ZSL. However, existing common space learning methods align the semantic and visual domains by merely mitigating distribution disagreement through one-step adaptation. This strategy is usually ineffective due to the heterogeneous nature of the feature representations in the two domains, which intrinsically contain both distribution and structure variations. To address this and advance ZSL, we propose a novel hierarchical semantic-visual adaptation (HSVA) framework. Specifically, HSVA aligns the semantic and visual domains by adopting a hierarchical two-step adaptation, i.e., structure adaptation and distribution adaptation. In the structure adaptation step, we take two task-specific encoders to encode the source data (visual domain) and the target data (semantic domain) into a structure-aligned common space. To this end, a supervised adversarial discrepancy (SAD) module is proposed to adversarially minimize the discrepancy between the predictions of two task-specific classifiers, thus making the visual and semantic feature manifolds more closely aligned. In the distribution adaptation step, we directly minimize the Wasserstein distance between the latent multivariate Gaussian distributions to align the visual and semantic distributions using a common encoder. Finally, the structure and distribution adaptation are derived in a unified framework under two partially-aligned variational autoencoders. Extensive experiments on four benchmark datasets demonstrate that HSVA achieves superior performance on both conventional and generalized ZSL. The code is available at \url{https://github.com/shiming-chen/HSVA} .
FREE: Feature Refinement for Generalized Zero-Shot Learning
Jul 29, 2021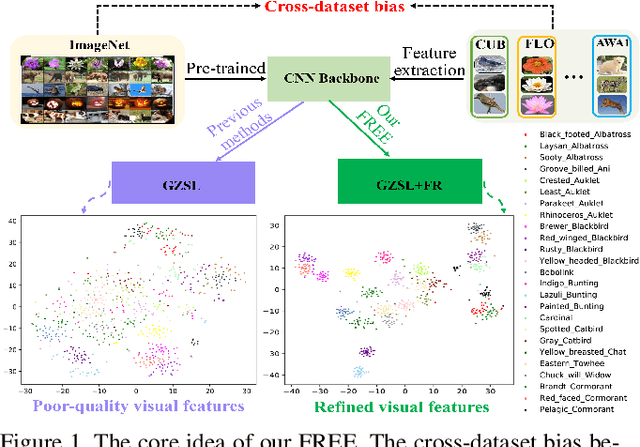
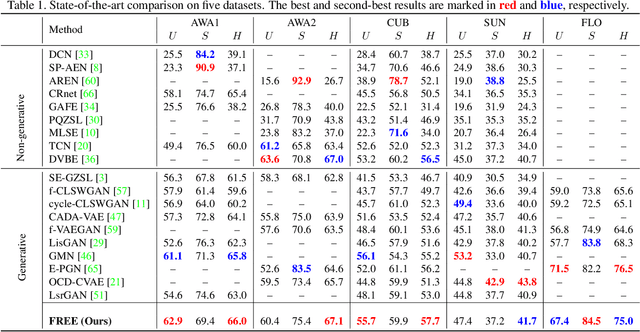
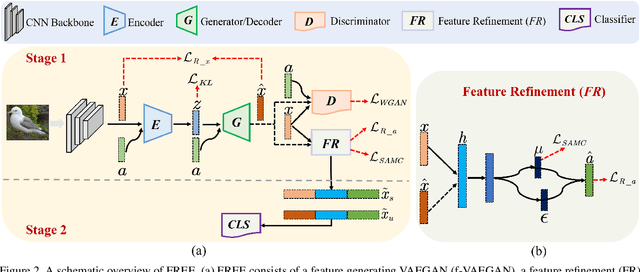
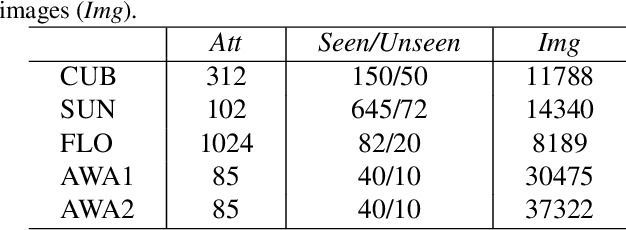
Generalized zero-shot learning (GZSL) has achieved significant progress, with many efforts dedicated to overcoming the problems of visual-semantic domain gap and seen-unseen bias. However, most existing methods directly use feature extraction models trained on ImageNet alone, ignoring the cross-dataset bias between ImageNet and GZSL benchmarks. Such a bias inevitably results in poor-quality visual features for GZSL tasks, which potentially limits the recognition performance on both seen and unseen classes. In this paper, we propose a simple yet effective GZSL method, termed feature refinement for generalized zero-shot learning (FREE), to tackle the above problem. FREE employs a feature refinement (FR) module that incorporates \textit{semantic$\rightarrow$visual} mapping into a unified generative model to refine the visual features of seen and unseen class samples. Furthermore, we propose a self-adaptive margin center loss (SAMC-loss) that cooperates with a semantic cycle-consistency loss to guide FR to learn class- and semantically-relevant representations, and concatenate the features in FR to extract the fully refined features. Extensive experiments on five benchmark datasets demonstrate the significant performance gain of FREE over its baseline and current state-of-the-art methods. Our codes are available at https://github.com/shiming-chen/FREE .
MSN: Multi-Style Network for Trajectory Prediction
Jul 02, 2021
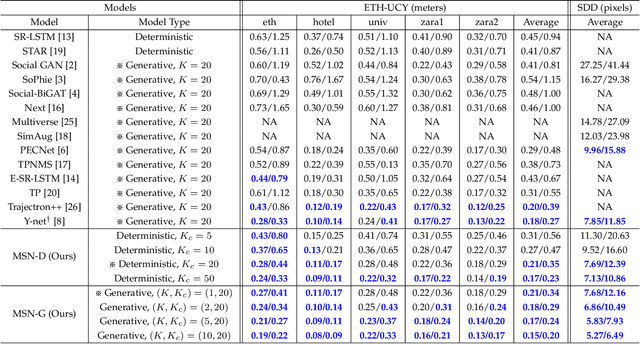
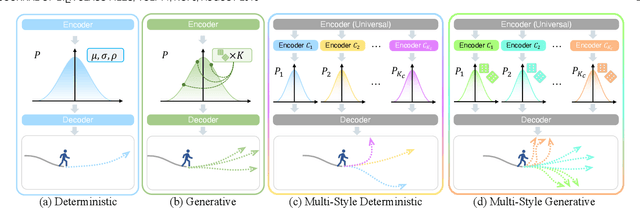

It is essential but challenging to predict future trajectories of various agents in complex scenes. Whether it is internal personality factors of agents, interactive behavior of the neighborhood, or the influence of surroundings, it will have an impact on their future behavior styles. It means that even for the same physical type of agents, there are huge differences in their behavior preferences. Although recent works have made significant progress in studying agents' multi-modal plannings, most of them still apply the same prediction strategy to all agents, which makes them difficult to fully show the multiple styles of vast agents. In this paper, we propose the Multi-Style Network (MSN) to focus on this problem by divide agents' preference styles into several hidden behavior categories adaptively and train each category's prediction network separately, therefore giving agents all styles of predictions simultaneously. Experiments demonstrate that our deterministic MSN-D and generative MSN-G outperform many recent state-of-the-art methods and show better multi-style characteristics in the visualized results.